 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning interacting particle systems from unlabeled data
Apr 02, 2026Learning the potentials of interacting particle systems is a fundamental task across various scientific disciplines. A major challenge is that unlabeled data collected at discrete time points lack trajectory information due to limitations in data collection methods or privacy constraints. We address this challenge by introducing a trajectory-free self-test loss function that leverages the weak-form stochastic evolution equation of the empirical distribution. The loss function is quadratic in potentials, supporting parametric and nonparametric regression algorithms for robust estimation that scale to large, high-dimensional systems with big data. Systematic numerical tests show that our method outperforms baseline methods that regress on trajectories recovered via label matching, tolerating large observation time steps. We establish the convergence of parametric estimators as the sample size increases, providing a theoretical foundation for the proposed approach.
Generalization from Low- to Moderate-Resolution Spectra with Neural Networks for Stellar Parameter Estimation: A Case Study with DESI
Feb 16, 2026Cross-survey generalization is a critical challenge in stellar spectral analysis, particularly in cases such as transferring from low- to moderate-resolution surveys. We investigate this problem using pre-trained models, focusing on simple neural networks such as multilayer perceptrons (MLPs), with a case study transferring from LAMOST low-resolution spectra (LRS) to DESI medium-resolution spectra (MRS). Specifically, we pre-train MLPs on either LRS or their embeddings and fine-tune them for application to DESI stellar spectra. We compare MLPs trained directly on spectra with those trained on embeddings derived from transformer-based models (self-supervised foundation models pre-trained for multiple downstream tasks). We also evaluate different fine-tuning strategies, including residual-head adapters, LoRA, and full fine-tuning. We find that MLPs pre-trained on LAMOST LRS achieve strong performance, even without fine-tuning, and that modest fine-tuning with DESI spectra further improves the results. For iron abundance, embeddings from a transformer-based model yield advantages in the metal-rich ([Fe/H] > -1.0) regime, but underperform in the metal-poor regime compared to MLPs trained directly on LRS. We also show that the optimal fine-tuning strategy depends on the specific stellar parameter under consideration. These results highlight that simple pre-trained MLPs can provide competitive cross-survey generalization, while the role of spectral foundation models for cross-survey stellar parameter estimation requires further exploration.
Sketch and Scale: Geo-distributed tSNE and UMAP
Nov 11, 2020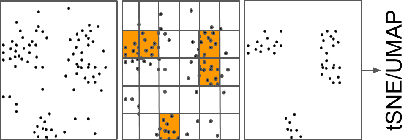
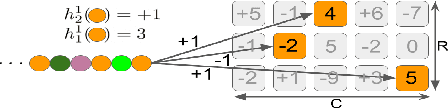
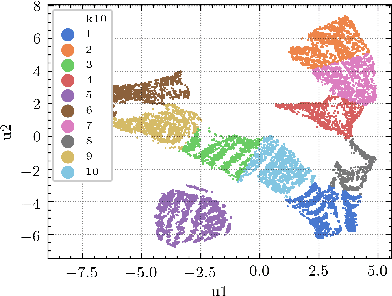

Running machine learning analytics over geographically distributed datasets is a rapidly arising problem in the world of data management policies ensuring privacy and data security. Visualizing high dimensional data using tools such as t-distributed Stochastic Neighbor Embedding (tSNE) and Uniform Manifold Approximation and Projection (UMAP) became common practice for data scientists. Both tools scale poorly in time and memory. While recent optimizations showed successful handling of 10,000 data points, scaling beyond million points is still challenging. We introduce a novel framework: Sketch and Scale (SnS). It leverages a Count Sketch data structure to compress the data on the edge nodes, aggregates the reduced size sketches on the master node, and runs vanilla tSNE or UMAP on the summary, representing the densest areas, extracted from the aggregated sketch. We show this technique to be fully parallel, scale linearly in time, logarithmically in memory, and communication, making it possible to analyze datasets with many millions, potentially billions of data points, spread across several data centers around the globe. We demonstrate the power of our method on two mid-size datasets: cancer data with 52 million 35-band pixels from multiple images of tumor biopsies; and astrophysics data of 100 million stars with multi-color photometry from the Sloan Digital Sky Survey (SDSS).