 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVELOCITI: Can Video-Language Models Bind Semantic Concepts through Time?
Jun 16, 2024Compositionality is a fundamental aspect of vision-language understanding and is especially required for videos since they contain multiple entities (e.g. persons, actions, and scenes) interacting dynamically over time. Existing benchmarks focus primarily on perception capabilities. However, they do not study binding, the ability of a model to associate entities through appropriate relationships. To this end, we propose VELOCITI, a new benchmark building on complex movie clips and dense semantic role label annotations to test perception and binding in video language models (contrastive and Video-LLMs). Our perception-based tests require discriminating video-caption pairs that share similar entities, and the binding tests require models to associate the correct entity to a given situation while ignoring the different yet plausible entities that also appear in the same video. While current state-of-the-art models perform moderately well on perception tests, accuracy is near random when both entities are present in the same video, indicating that they fail at binding tests. Even the powerful Gemini 1.5 Flash has a substantial gap (16-28%) with respect to human accuracy in such binding tests.
SARI: Simplistic Average and Robust Identification based Noisy Partial Label Learning
Feb 07, 2024



Partial label learning (PLL) is a weakly-supervised learning paradigm where each training instance is paired with a set of candidate labels (partial label), one of which is the true label. Noisy PLL (NPLL) relaxes this constraint by allowing some partial labels to not contain the true label, enhancing the practicality of the problem. Our work centers on NPLL and presents a minimalistic framework called SARI that initially assigns pseudo-labels to images by exploiting the noisy partial labels through a weighted nearest neighbour algorithm. These pseudo-label and image pairs are then used to train a deep neural network classifier with label smoothing and standard regularization techniques. The classifier's features and predictions are subsequently employed to refine and enhance the accuracy of pseudo-labels. SARI combines the strengths of Average Based Strategies (in pseudo labelling) and Identification Based Strategies (in classifier training) from the literature. We perform thorough experiments on seven datasets and compare SARI against nine NPLL and PLL methods from the prior art. SARI achieves state-of-the-art results in almost all studied settings, obtaining substantial gains in fine-grained classification and extreme noise settings.
Real Time GAZED: Online Shot Selection and Editing of Virtual Cameras from Wide-Angle Monocular Video Recordings
Nov 27, 2023



Eliminating time-consuming post-production processes and delivering high-quality videos in today's fast-paced digital landscape are the key advantages of real-time approaches. To address these needs, we present Real Time GAZED: a real-time adaptation of the GAZED framework integrated with CineFilter, a novel real-time camera trajectory stabilization approach. It enables users to create professionally edited videos in real-time. Comparative evaluations against baseline methods, including the non-real-time GAZED, demonstrate that Real Time GAZED achieves similar editing results, ensuring high-quality video output. Furthermore, a user study confirms the aesthetic quality of the video edits produced by the Real Time GAZED approach. With these advancements in real-time camera trajectory optimization and video editing presented, the demand for immediate and dynamic content creation in industries such as live broadcasting, sports coverage, news reporting, and social media content creation can be met more efficiently.
RobustL2S: Speaker-Specific Lip-to-Speech Synthesis exploiting Self-Supervised Representations
Jul 03, 2023



Significant progress has been made in speaker dependent Lip-to-Speech synthesis, which aims to generate speech from silent videos of talking faces. Current state-of-the-art approaches primarily employ non-autoregressive sequence-to-sequence architectures to directly predict mel-spectrograms or audio waveforms from lip representations. We hypothesize that the direct mel-prediction hampers training/model efficiency due to the entanglement of speech content with ambient information and speaker characteristics. To this end, we propose RobustL2S, a modularized framework for Lip-to-Speech synthesis. First, a non-autoregressive sequence-to-sequence model maps self-supervised visual features to a representation of disentangled speech content. A vocoder then converts the speech features into raw waveforms. Extensive evaluations confirm the effectiveness of our setup, achieving state-of-the-art performance on the unconstrained Lip2Wav dataset and the constrained GRID and TCD-TIMIT datasets. Speech samples from RobustL2S can be found at https://neha-sherin.github.io/RobustL2S/
Instance-Level Semantic Maps for Vision Language Navigation
May 23, 2023



Humans have a natural ability to perform semantic associations with the surrounding objects in the environment. This allows them to create a mental map of the environment which helps them to navigate on-demand when given a linguistic instruction. A natural goal in Vision Language Navigation (VLN) research is to impart autonomous agents with similar capabilities. Recently introduced VL Maps \cite{huang23vlmaps} take a step towards this goal by creating a semantic spatial map representation of the environment without any labelled data. However, their representations are limited for practical applicability as they do not distinguish between different instances of the same object. In this work, we address this limitation by integrating instance-level information into spatial map representation using a community detection algorithm and by utilizing word ontology learned by large language models (LLMs) to perform open-set semantic associations in the mapping representation. The resulting map representation improves the navigation performance by two-fold (233\%) on realistic language commands with instance-specific descriptions compared to VL Maps. We validate the practicality and effectiveness of our approach through extensive qualitative and quantitative experiments.
MParrotTTS: Multilingual Multi-speaker Text to Speech Synthesis in Low Resource Setting
May 19, 2023



We present MParrotTTS, a unified multilingual, multi-speaker text-to-speech (TTS) synthesis model that can produce high-quality speech. Benefiting from a modularized training paradigm exploiting self-supervised speech representations, MParrotTTS adapts to a new language with minimal supervised data and generalizes to languages not seen while training the self-supervised backbone. Moreover, without training on any bilingual or parallel examples, MParrotTTS can transfer voices across languages while preserving the speaker-specific characteristics, e.g., synthesizing fluent Hindi speech using a French speaker's voice and accent. We present extensive results on six languages in terms of speech naturalness and speaker similarity in parallel and cross-lingual synthesis. The proposed model outperforms the state-of-the-art multilingual TTS models and baselines, using only a small fraction of supervised training data. Speech samples from our model can be found at https://paper2438.github.io/tts/
ParrotTTS: Text-to-Speech synthesis by exploiting self-supervised representations
Mar 01, 2023



Text-to-speech (TTS) systems are modelled as mel-synthesizers followed by speech-vocoders since the era of statistical TTS that is carried forward into neural designs. We propose an alternative approach to TTS modelling referred to as ParrotTTS borrowing from self-supervised learning (SSL) methods. ParrotTTS takes a two-step approach by initially training a speech-to-speech model on unlabelled data that is abundantly available, followed by a text-to-embedding model that leverages speech with aligned transcriptions to extend it to TTS. ParrotTTS achieves competitive mean opinion scores on naturalness compared to traditional TTS models but significantly improves over the latter's data efficiency of transcribed pairs and speaker adaptation without transcriptions. This further paves the path to training TTS models on generically trained SSL speech models.
Test-Time Amendment with a Coarse Classifier for Fine-Grained Classification
Feb 01, 2023We investigate the problem of reducing mistake severity for fine-grained classification. Fine-grained classification can be challenging, mainly due to the requirement of knowledge or domain expertise for accurate annotation. However, humans are particularly adept at performing coarse classification as it requires relatively low levels of expertise. To this end, we present a novel approach for Post-Hoc Correction called Hierarchical Ensembles (HiE) that utilizes label hierarchy to improve the performance of fine-grained classification at test-time using the coarse-grained predictions. By only requiring the parents of leaf nodes, our method significantly reduces avg. mistake severity while improving top-1 accuracy on the iNaturalist-19 and tieredImageNet-H datasets, achieving a new state-of-the-art on both benchmarks. We also investigate the efficacy of our approach in the semi-supervised setting. Our approach brings notable gains in top-1 accuracy while significantly decreasing the severity of mistakes as training data decreases for the fine-grained classes. The simplicity and post-hoc nature of HiE render it practical to be used with any off-the-shelf trained model to improve its predictions further.
Ground then Navigate: Language-guided Navigation in Dynamic Scenes
Sep 24, 2022

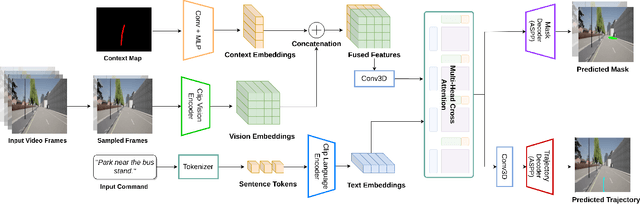
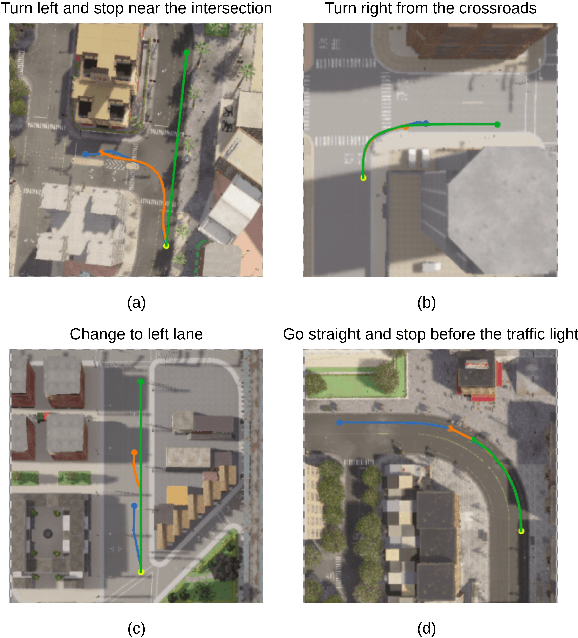
We investigate the Vision-and-Language Navigation (VLN) problem in the context of autonomous driving in outdoor settings. We solve the problem by explicitly grounding the navigable regions corresponding to the textual command. At each timestamp, the model predicts a segmentation mask corresponding to the intermediate or the final navigable region. Our work contrasts with existing efforts in VLN, which pose this task as a node selection problem, given a discrete connected graph corresponding to the environment. We do not assume the availability of such a discretised map. Our work moves towards continuity in action space, provides interpretability through visual feedback and allows VLN on commands requiring finer manoeuvres like "park between the two cars". Furthermore, we propose a novel meta-dataset CARLA-NAV to allow efficient training and validation. The dataset comprises pre-recorded training sequences and a live environment for validation and testing. We provide extensive qualitative and quantitive empirical results to validate the efficacy of the proposed approach.
Grounding Linguistic Commands to Navigable Regions
Dec 24, 2021
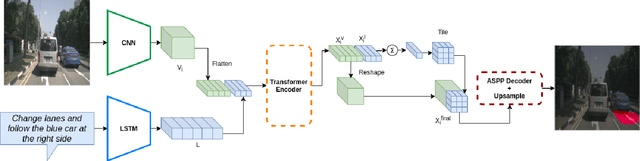


Humans have a natural ability to effortlessly comprehend linguistic commands such as "park next to the yellow sedan" and instinctively know which region of the road the vehicle should navigate. Extending this ability to autonomous vehicles is the next step towards creating fully autonomous agents that respond and act according to human commands. To this end, we propose the novel task of Referring Navigable Regions (RNR), i.e., grounding regions of interest for navigation based on the linguistic command. RNR is different from Referring Image Segmentation (RIS), which focuses on grounding an object referred to by the natural language expression instead of grounding a navigable region. For example, for a command "park next to the yellow sedan," RIS will aim to segment the referred sedan, and RNR aims to segment the suggested parking region on the road. We introduce a new dataset, Talk2Car-RegSeg, which extends the existing Talk2car dataset with segmentation masks for the regions described by the linguistic commands. A separate test split with concise manoeuvre-oriented commands is provided to assess the practicality of our dataset. We benchmark the proposed dataset using a novel transformer-based architecture. We present extensive ablations and show superior performance over baselines on multiple evaluation metrics. A downstream path planner generating trajectories based on RNR outputs confirms the efficacy of the proposed framework.