 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vessel-Segmentation-Based CycleGAN for Unpaired Multi-modal Retinal Image Synthesis
Jun 05, 2023Unpaired image-to-image translation of retinal images can efficiently increase the training dataset for deep-learning-based multi-modal retinal registration methods. Our method integrates a vessel segmentation network into the image-to-image translation task by extending the CycleGAN framework. The segmentation network is inserted prior to a UNet vision transformer generator network and serves as a shared representation between both domains. We reformulate the original identity loss to learn the direct mapping between the vessel segmentation and the real image. Additionally, we add a segmentation loss term to ensure shared vessel locations between fake and real images. In the experiments, our method shows a visually realistic look and preserves the vessel structures, which is a prerequisite for generating multi-modal training data for image registration.
* Accepted to BVM 2023
Combining OCR Models for Reading Early Modern Printed Books
May 11, 2023In this paper, we investigate the usage of fine-grained font recognition on OCR for books printed from the 15th to the 18th century. We used a newly created dataset for OCR of early printed books for which fonts are labeled with bounding boxes. We know not only the font group used for each character, but the locations of font changes as well. In books of this period, we frequently find font group changes mid-line or even mid-word that indicate changes in language. We consider 8 different font groups present in our corpus and investigate 13 different subsets: the whole dataset and text lines with a single font, multiple fonts, Roman fonts, Gothic fonts, and each of the considered fonts, respectively. We show that OCR performance is strongly impacted by font style and that selecting fine-tuned models with font group recognition has a very positive impact on the results. Moreover, we developed a system using local font group recognition in order to combine the output of multiple font recognition models, and show that while slower, this approach performs better not only on text lines composed of multiple fonts but on the ones containing a single font only as well.
WordStylist: Styled Verbatim Handwritten Text Generation with Latent Diffusion Models
Mar 29, 2023



Text-to-Image synthesis is the task of generating an image according to a specific text description. Generative Adversarial Networks have been considered the standard method for image synthesis virtually since their introduction; today, Denoising Diffusion Probabilistic Models are recently setting a new baseline, with remarkable results in Text-to-Image synthesis, among other fields. Aside its usefulness per se, it can also be particularly relevant as a tool for data augmentation to aid training models for other document image processing tasks. In this work, we present a latent diffusion-based method for styled text-to-text-content-image generation on word-level. Our proposed method manages to generate realistic word image samples from different writer styles, by using class index styles and text content prompts without the need of adversarial training, writer recognition, or text recognition. We gauge system performance with Frechet Inception Distance, writer recognition accuracy, and writer retrieval. We show that the proposed model produces samples that are aesthetically pleasing, help boosting text recognition performance, and gets similar writer retrieval score as real data.
AMD-HookNet for Glacier Front Segmentation
Feb 06, 2023



Knowledge on changes in glacier calving front positions is important for assessing the status of glaciers. Remote sensing imagery provides the ideal database for monitoring calving front positions, however, it is not feasible to perform this task manually for all calving glaciers globally due to time-constraints. Deep learning-based methods have shown great potential for glacier calving front delineation from optical and radar satellite imagery. The calving front is represented as a single thin line between the ocean and the glacier, which makes the task vulnerable to inaccurate predictions. The limited availability of annotated glacier imagery leads to a lack of data diversity (not all possible combinations of different weather conditions, terminus shapes, sensors, etc. are present in the data), which exacerbates the difficulty of accurate segmentation. In this paper, we propose Attention-Multi-hooking-Deep-supervision HookNet (AMD-HookNet), a novel glacier calving front segmentation framework for synthetic aperture radar (SAR) images. The proposed method aims to enhance the feature representation capability through multiple information interactions between low-resolution and high-resolution inputs based on a two-branch U-Net. The attention mechanism, integrated into the two branch U-Net, aims to interact between the corresponding coarse and fine-grained feature maps. This allows the network to automatically adjust feature relationships, resulting in accurate pixel-classification predictions. Extensive experiments and comparisons on the challenging glacier segmentation benchmark dataset CaFFe show that our AMD-HookNet achieves a mean distance error of 438 m to the ground truth outperforming the current state of the art by 42%, which validates its effectiveness.
Transfer Learning for Olfactory Object Detection
Jan 24, 2023We investigate the effect of style and category similarity in multiple datasets used for object detection pretraining. We find that including an additional stage of object-detection pretraining can increase the detection performance considerably. While our experiments suggest that style similarities between pre-training and target datasets are less important than matching categories, further experiments are needed to verify this hypothesis.
* 6 pages, 4 figures
ODOR: The ICPR2022 ODeuropa Challenge on Olfactory Object Recognition
Jan 24, 2023The Odeuropa Challenge on Olfactory Object Recognition aims to foster the development of object detection in the visual arts and to promote an olfactory perspective on digital heritage. Object detection in historical artworks is particularly challenging due to varying styles and artistic periods. Moreover, the task is complicated due to the particularity and historical variance of predefined target objects, which exhibit a large intra-class variance, and the long tail distribution of the dataset labels, with some objects having only very few training examples. These challenges should encourage participants to create innovative approaches using domain adaptation or few-shot learning. We provide a dataset of 2647 artworks annotated with 20 120 tightly fit bounding boxes that are split into a training and validation set (public). A test set containing 1140 artworks and 15 480 annotations is kept private for the challenge evaluation.
* 6 pages, 6 figures
Writer Retrieval and Writer Identification in Greek Papyri
Dec 15, 2022The analysis of digitized historical manuscripts is typically addressed by paleographic experts. Writer identification refers to the classification of known writers while writer retrieval seeks to find the writer by means of image similarity in a dataset of images. While automatic writer identification/retrieval methods already provide promising results for many historical document types, papyri data is very challenging due to the fiber structures and severe artifacts. Thus, an important step for an improved writer identification is the preprocessing and feature sampling process. We investigate several methods and show that a good binarization is key to an improved writer identification in papyri writings. We focus mainly on writer retrieval using unsupervised feature methods based on traditional or self-supervised-based methods. It is, however, also comparable to the state of the art supervised deep learning-based method in the case of writer classification/re-identification.
ArtFacePoints: High-resolution Facial Landmark Detection in Paintings and Prints
Oct 17, 2022
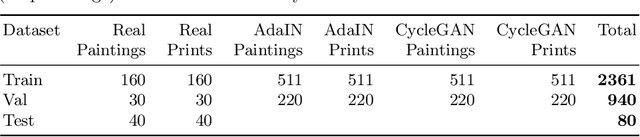

Facial landmark detection plays an important role for the similarity analysis in artworks to compare portraits of the same or similar artists. With facial landmarks, portraits of different genres, such as paintings and prints, can be automatically aligned using control-point-based image registration. We propose a deep-learning-based method for facial landmark detection in high-resolution images of paintings and prints. It divides the task into a global network for coarse landmark prediction and multiple region networks for precise landmark refinement in regions of the eyes, nose, and mouth that are automatically determined based on the predicted global landmark coordinates. We created a synthetically augmented facial landmark art dataset including artistic style transfer and geometric landmark shifts. Our method demonstrates an accurate detection of the inner facial landmarks for our high-resolution dataset of artworks while being comparable for a public low-resolution artwork dataset in comparison to competing methods.
A Multi-modal Registration and Visualization Software Tool for Artworks using CraquelureNet
Aug 18, 2022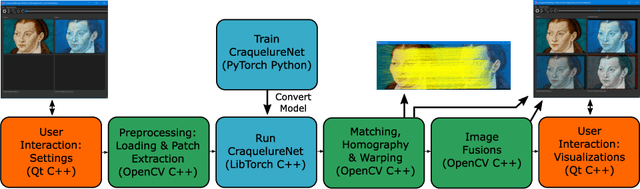
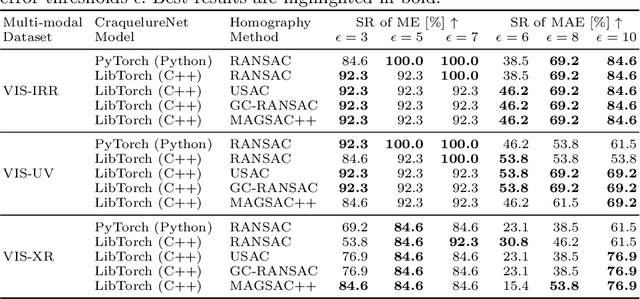
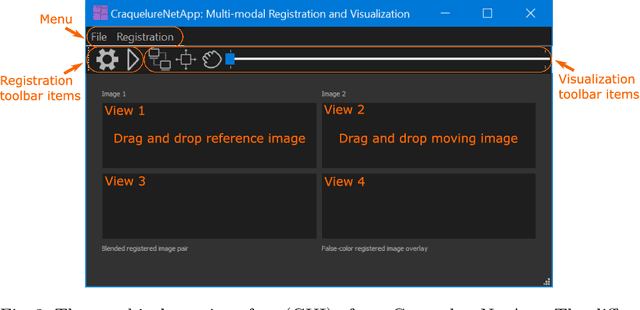
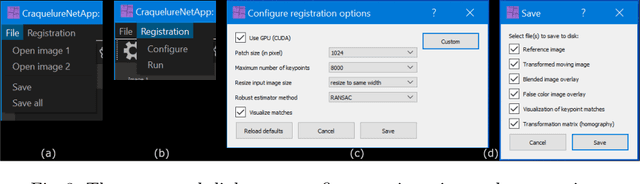
For art investigations of paintings, multiple imaging technologies, such as visual light photography, infrared reflectography, ultraviolet fluorescence photography, and x-radiography are often used. For a pixel-wise comparison, the multi-modal images have to be registered. We present a registration and visualization software tool, that embeds a convolutional neural network to extract cross-modal features of the crack structures in historical paintings for automatic registration. The graphical user interface processes the user's input to configure the registration parameters and to interactively adapt the image views with the registered pair and image overlays, such as by individual or synchronized zoom or movements of the views. In the evaluation, we qualitatively and quantitatively show the effectiveness of our software tool in terms of registration performance and short inference time on multi-modal paintings and its transferability by applying our method to historical prints.
Multi-modal Retinal Image Registration Using a Keypoint-Based Vessel Structure Aligning Network
Jul 21, 2022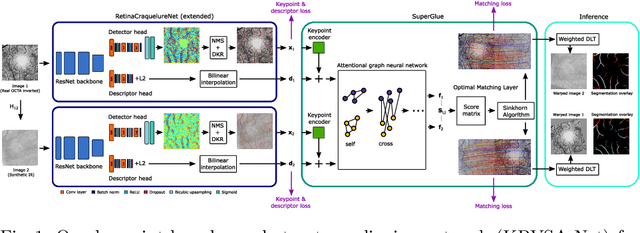
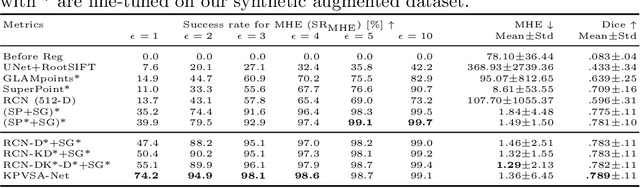

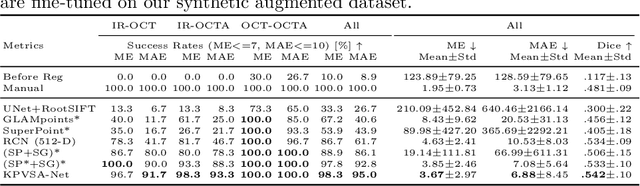
In ophthalmological imaging, multiple imaging systems, such as color fundus, infrared, fluorescein angiography, optical coherence tomography (OCT) or OCT angiography, are often involved to make a diagnosis of retinal disease. Multi-modal retinal registration techniques can assist ophthalmologists by providing a pixel-based comparison of aligned vessel structures in images from different modalities or acquisition times. To this end, we propose an end-to-end trainable deep learning method for multi-modal retinal image registration. Our method extracts convolutional features from the vessel structure for keypoint detection and description and uses a graph neural network for feature matching. The keypoint detection and description network and graph neural network are jointly trained in a self-supervised manner using synthetic multi-modal image pairs and are guided by synthetically sampled ground truth homographies. Our method demonstrates higher registration accuracy as competing methods for our synthetic retinal dataset and generalizes well for our real macula dataset and a public fundus dataset.