 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Recurrent Flow: Conditional Generation of Longitudinal Samples with Applications to Neuroimaging
Dec 11, 2018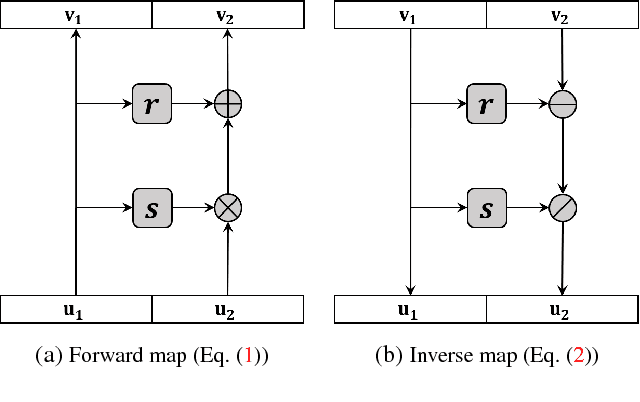
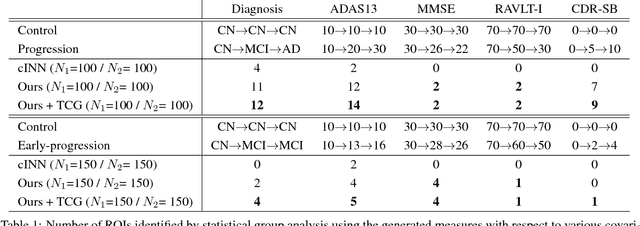
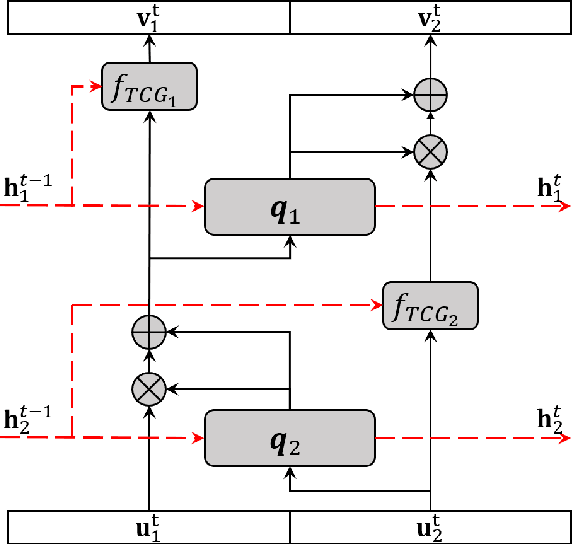

Generative models using neural network have opened a door to large-scale studies for various application domains, especially for studies that suffer from lack of real samples to obtain statistically robust inference. Typically, these generative models would train on existing data to learn the underlying distribution of the measurements (e.g., images) in latent spaces conditioned on covariates (e.g., image labels), and generate independent samples that are identically distributed in the latent space. Such models may work for cross-sectional studies, however, they are not suitable to generate data for longitudinal studies that focus on "progressive" behavior in a sequence of data. In practice, this is a quite common case in various neuroimaging studies whose goal is to characterize a trajectory of pathologies of a specific disease even from early stages. This may be too ambitious especially when the sample size is small (e.g., up to a few hundreds). Motivated from the setup above, we seek to develop a conditional generative model for longitudinal data generation by designing an invertable neural network. Inspired by recurrent nature of longitudinal data, we propose a novel neural network that incorporates recurrent subnetwork and context gating to include smooth transition in a sequence of generated data. Our model is validated on a video sequence dataset and a longitudinal AD dataset with various experimental settings for qualitative and quantitative evaluations of the generated samples. The results with the AD dataset captures AD specific group differences with sufficiently generated longitudinal samples that are consistent with existing literature, which implies a great potential to be applicable to other disease studies.
A Statistical Recurrent Model on the Manifold of Symmetric Positive Definite Matrices
Oct 27, 2018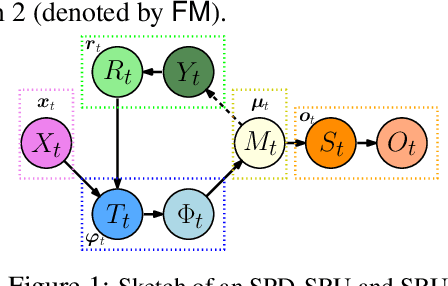
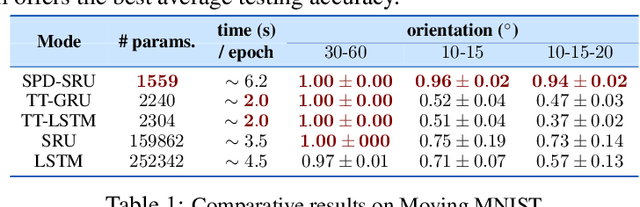
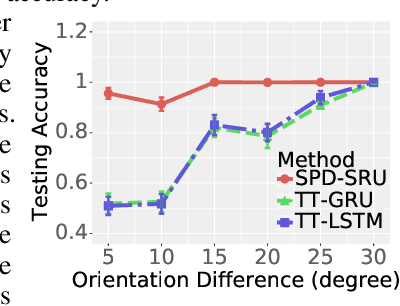
In a number of disciplines, the data (e.g., graphs, manifolds) to be analyzed are non-Euclidean in nature. Geometric deep learning corresponds to techniques that generalize deep neural network models to such non-Euclidean spaces. Several recent papers have shown how convolutional neural networks (CNNs) can be extended to learn with graph-based data. In this work, we study the setting where the data (or measurements) are ordered, longitudinal or temporal in nature and live on a Riemannian manifold -- this setting is common in a variety of problems in statistical machine learning, vision and medical imaging. We show how recurrent statistical recurrent network models can be defined in such spaces. We give an efficient algorithm and conduct a rigorous analysis of its statistical properties. We perform extensive numerical experiments demonstrating competitive performance with state of the art methods but with significantly less number of parameters. We also show applications to a statistical analysis task in brain imaging, a regime where deep neural network models have only been utilized in limited ways.
Sampling-free Uncertainty Estimation in Gated Recurrent Units with Exponential Families
Sep 02, 2018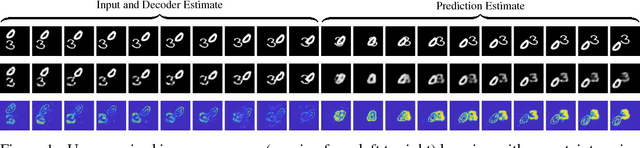
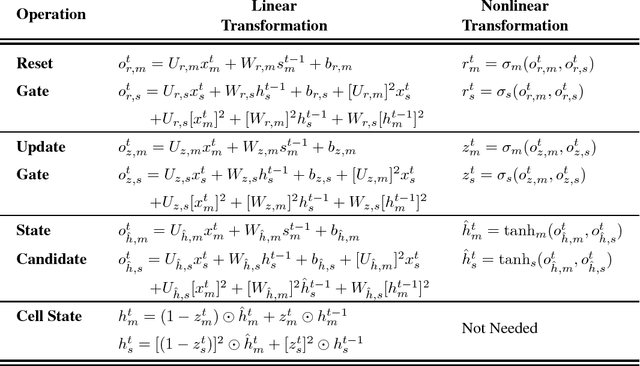

There has recently been a concerted effort to derive mechanisms in vision and machine learning systems to offer uncertainty estimates of the predictions they make. Clearly, there are enormous benefits to a system that is not only accurate but also has a sense for when it is not sure. Existing proposals center around Bayesian interpretations of modern deep architectures -- these are effective but can often be computationally demanding. We show how classical ideas in the literature on exponential families on probabilistic networks provide an excellent starting point to derive uncertainty estimates in Gated Recurrent Units (GRU). Our proposal directly quantifies uncertainty deterministically, without the need for costly sampling-based estimation. We demonstrate how our model can be used to quantitatively and qualitatively measure uncertainty in unsupervised image sequence prediction. To our knowledge, this is the first result describing sampling-free uncertainty estimation for powerful sequential models such as GRUs.
Building Bayesian Neural Networks with Blocks: On Structure, Interpretability and Uncertainty
Jun 10, 2018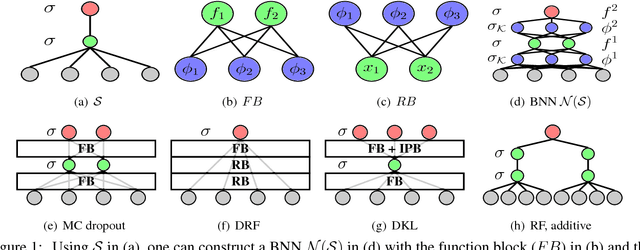
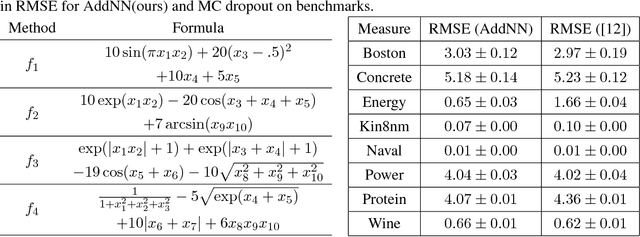
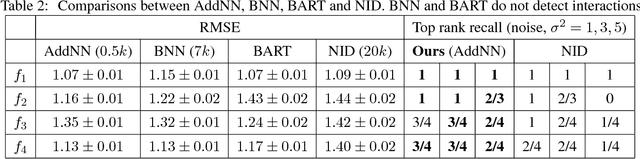
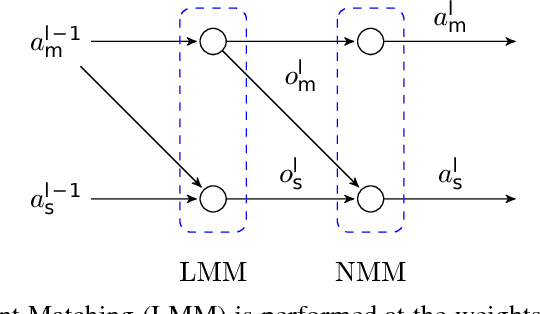
We provide simple schemes to build Bayesian Neural Networks (BNNs), block by block, inspired by a recent idea of computation skeletons. We show how by adjusting the types of blocks that are used within the computation skeleton, we can identify interesting relationships with Deep Gaussian Processes (DGPs), deep kernel learning (DKL), random features type approximation and other topics. We give strategies to approximate the posterior via doubly stochastic variational inference for such models which yield uncertainty estimates. We give a detailed theoretical analysis and point out extensions that may be of independent interest. As a special case, we instantiate our procedure to define a Bayesian {\em additive} Neural network -- a promising strategy to identify statistical interactions and has direct benefits for obtaining interpretable models.
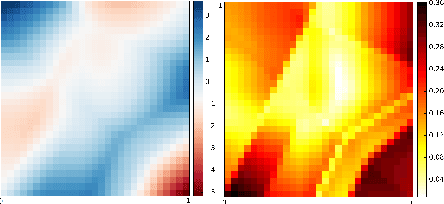
Robust Blind Deconvolution via Mirror Descent
Mar 21, 2018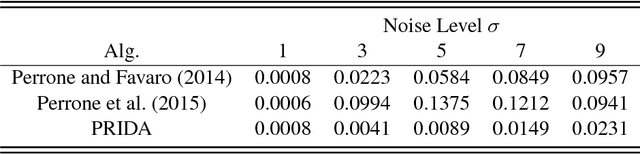
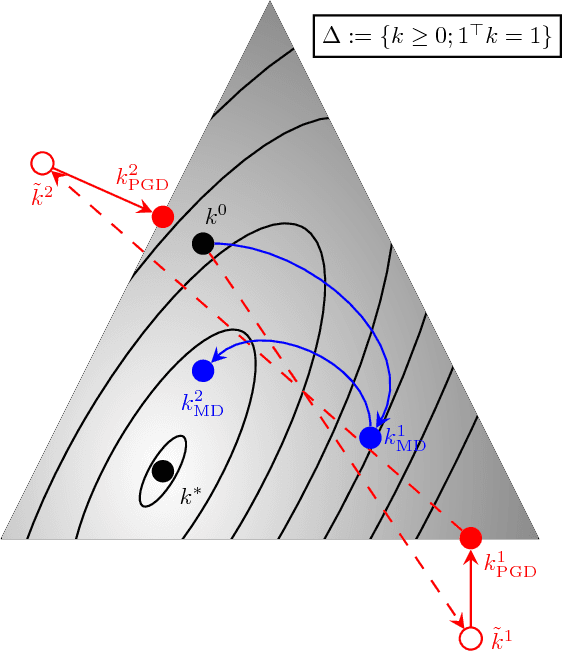
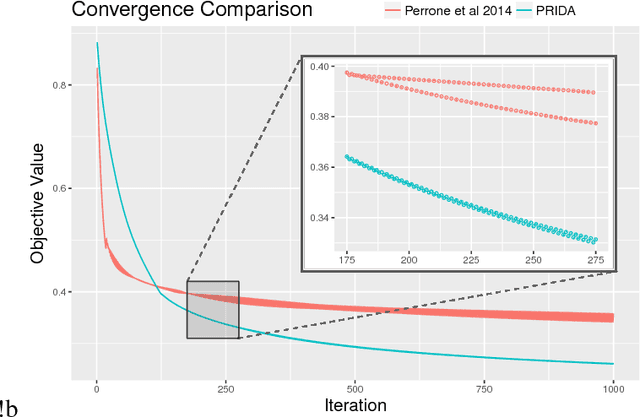

We revisit the Blind Deconvolution problem with a focus on understanding its robustness and convergence properties. Provable robustness to noise and other perturbations is receiving recent interest in vision, from obtaining immunity to adversarial attacks to assessing and describing failure modes of algorithms in mission critical applications. Further, many blind deconvolution methods based on deep architectures internally make use of or optimize the basic formulation, so a clearer understanding of how this sub-module behaves, when it can be solved, and what noise injection it can tolerate is a first order requirement. We derive new insights into the theoretical underpinnings of blind deconvolution. The algorithm that emerges has nice convergence guarantees and is provably robust in a sense we formalize in the paper. Interestingly, these technical results play out very well in practice, where on standard datasets our algorithm yields results competitive with or superior to the state of the art. Keywords: blind deconvolution, robust continuous optimization
Constrained Deep Learning using Conditional Gradient and Applications in Computer Vision
Mar 17, 2018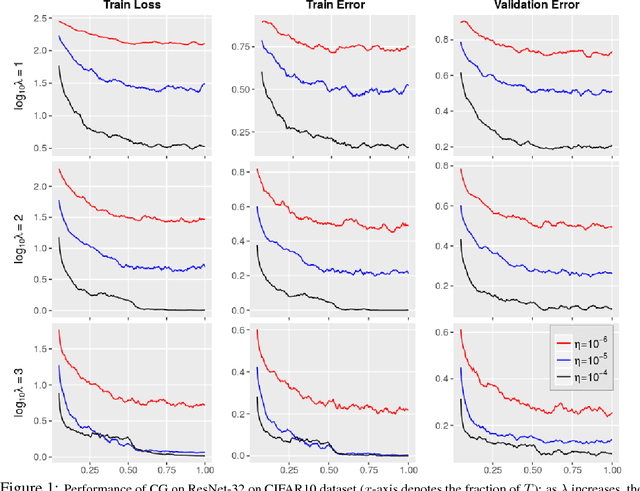
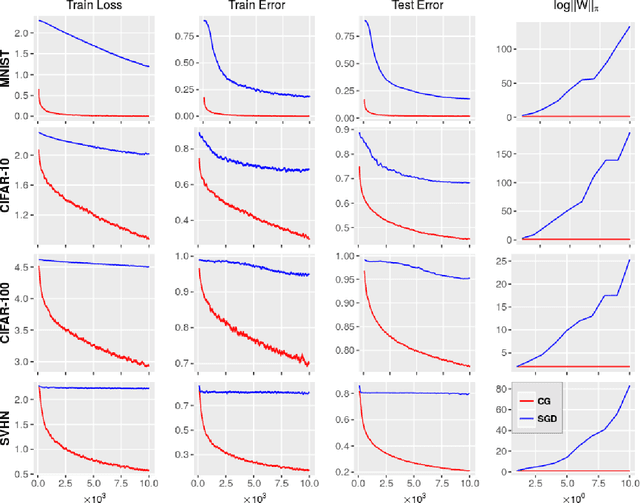
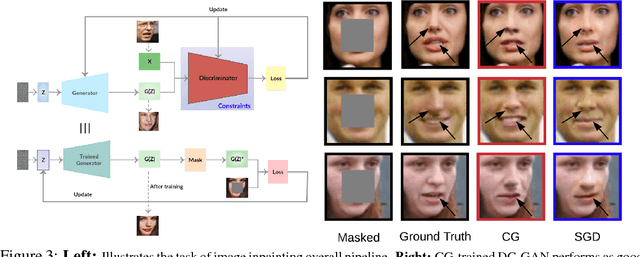
A number of results have recently demonstrated the benefits of incorporating various constraints when training deep architectures in vision and machine learning. The advantages range from guarantees for statistical generalization to better accuracy to compression. But support for general constraints within widely used libraries remains scarce and their broader deployment within many applications that can benefit from them remains under-explored. Part of the reason is that Stochastic gradient descent (SGD), the workhorse for training deep neural networks, does not natively deal with constraints with global scope very well. In this paper, we revisit a classical first order scheme from numerical optimization, Conditional Gradients (CG), that has, thus far had limited applicability in training deep models. We show via rigorous analysis how various constraints can be naturally handled by modifications of this algorithm. We provide convergence guarantees and show a suite of immediate benefits that are possible -- from training ResNets with fewer layers but better accuracy simply by substituting in our version of CG to faster training of GANs with 50% fewer epochs in image inpainting applications to provably better generalization guarantees using efficiently implementable forms of recently proposed regularizers.
Finding Differentially Covarying Needles in a Temporally Evolving Haystack: A Scan Statistics Perspective
Nov 20, 2017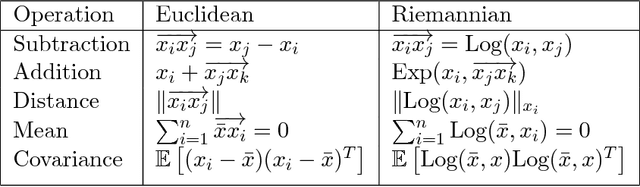

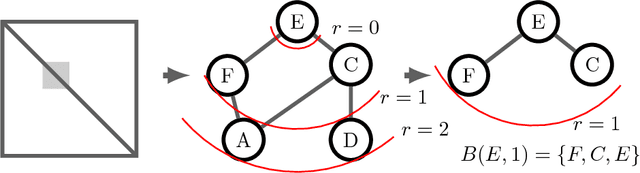
Recent results in coupled or temporal graphical models offer schemes for estimating the relationship structure between features when the data come from related (but distinct) longitudinal sources. A novel application of these ideas is for analyzing group-level differences, i.e., in identifying if trends of estimated objects (e.g., covariance or precision matrices) are different across disparate conditions (e.g., gender or disease). Often, poor effect sizes make detecting the differential signal over the full set of features difficult: for example, dependencies between only a subset of features may manifest differently across groups. In this work, we first give a parametric model for estimating trends in the space of SPD matrices as a function of one or more covariates. We then generalize scan statistics to graph structures, to search over distinct subsets of features (graph partitions) whose temporal dependency structure may show statistically significant group-wise differences. We theoretically analyze the Family Wise Error Rate (FWER) and bounds on Type 1 and Type 2 error. On a cohort of individuals with risk factors for Alzheimer's disease (but otherwise cognitively healthy), we find scientifically interesting group differences where the default analysis, i.e., models estimated on the full graph, do not survive reasonable significance thresholds.
A Deterministic Nonsmooth Frank Wolfe Algorithm with Coreset Guarantees
Aug 22, 2017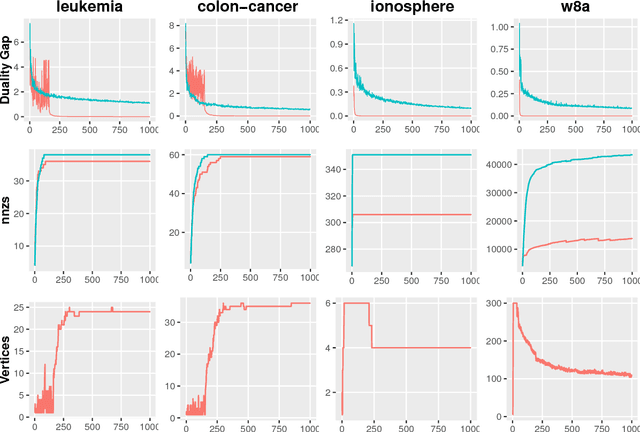

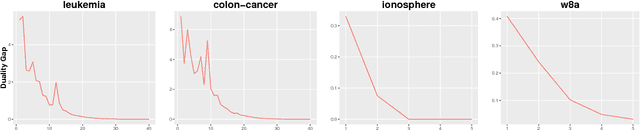
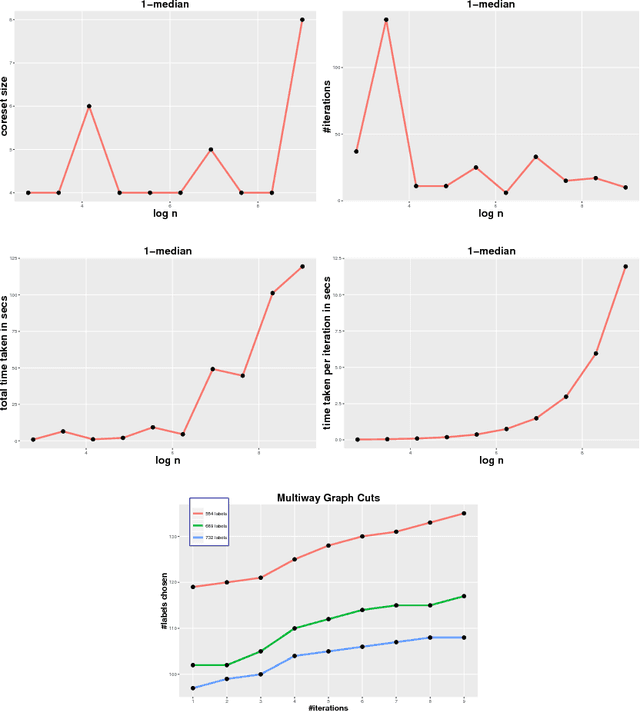
We present a new Frank-Wolfe (FW) type algorithm that is applicable to minimization problems with a nonsmooth convex objective. We provide convergence bounds and show that the scheme yields so-called coreset results for various Machine Learning problems including 1-median, Balanced Development, Sparse PCA, Graph Cuts, and the $\ell_1$-norm-regularized Support Vector Machine (SVM) among others. This means that the algorithm provides approximate solutions to these problems in time complexity bounds that are not dependent on the size of the input problem. Our framework, motivated by a growing body of work on sublinear algorithms for various data analysis problems, is entirely deterministic and makes no use of smoothing or proximal operators. Apart from these theoretical results, we show experimentally that the algorithm is very practical and in some cases also offers significant computational advantages on large problem instances. We provide an open source implementation that can be adapted for other problems that fit the overall structure.
Accelerating Permutation Testing in Voxel-wise Analysis through Subspace Tracking: A new plugin for SnPM
Jul 24, 2017
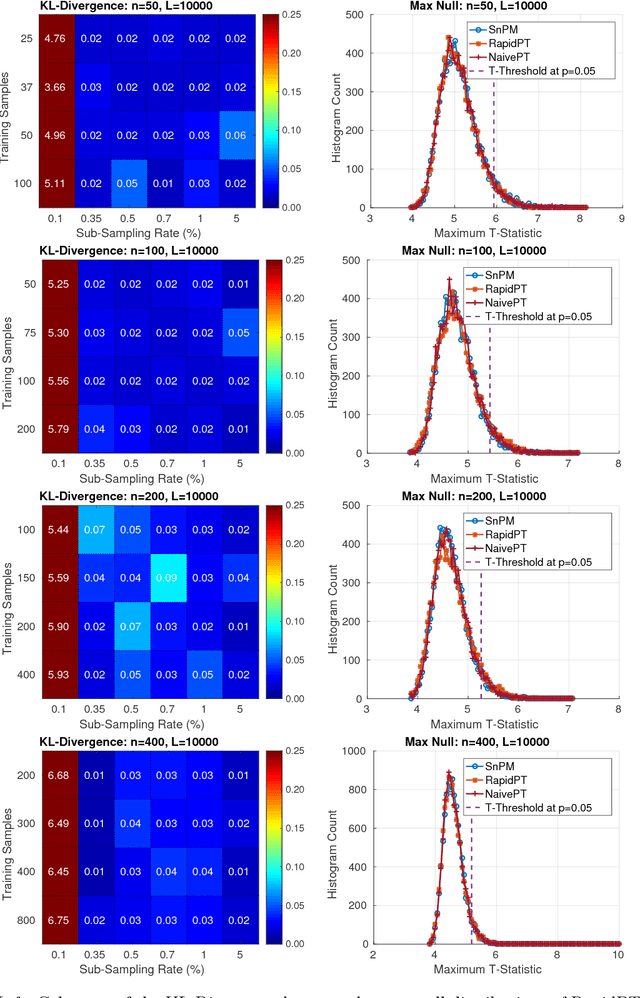

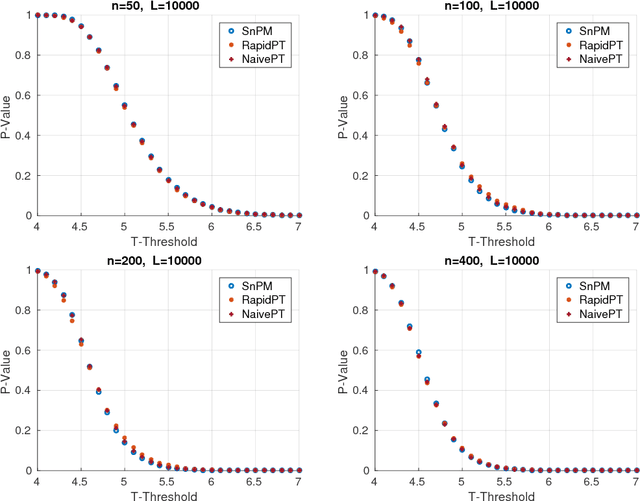
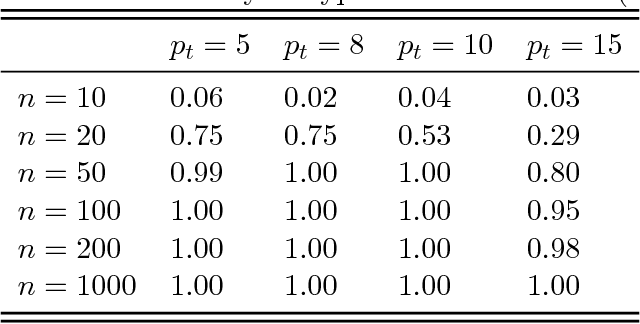
Permutation testing is a non-parametric method for obtaining the max null distribution used to compute corrected $p$-values that provide strong control of false positives. In neuroimaging, however, the computational burden of running such an algorithm can be significant. We find that by viewing the permutation testing procedure as the construction of a very large permutation testing matrix, $T$, one can exploit structural properties derived from the data and the test statistics to reduce the runtime under certain conditions. In particular, we see that $T$ is low-rank plus a low-variance residual. This makes $T$ a good candidate for low-rank matrix completion, where only a very small number of entries of $T$ ($\sim0.35\%$ of all entries in our experiments) have to be computed to obtain a good estimate. Based on this observation, we present RapidPT, an algorithm that efficiently recovers the max null distribution commonly obtained through regular permutation testing in voxel-wise analysis. We present an extensive validation on a synthetic dataset and four varying sized datasets against two baselines: Statistical NonParametric Mapping (SnPM13) and a standard permutation testing implementation (referred as NaivePT). We find that RapidPT achieves its best runtime performance on medium sized datasets ($50 \leq n \leq 200$), with speedups of 1.5x - 38x (vs. SnPM13) and 20x-1000x (vs. NaivePT). For larger datasets ($n \geq 200$) RapidPT outperforms NaivePT (6x - 200x) on all datasets, and provides large speedups over SnPM13 when more than 10000 permutations (2x - 15x) are needed. The implementation is a standalone toolbox and also integrated within SnPM13, able to leverage multi-core architectures when available.
The Incremental Multiresolution Matrix Factorization Algorithm
May 16, 2017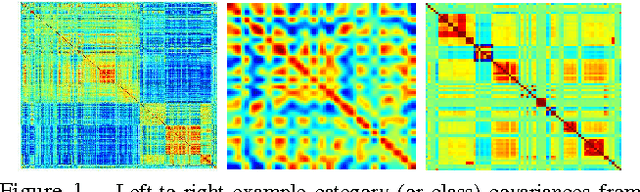
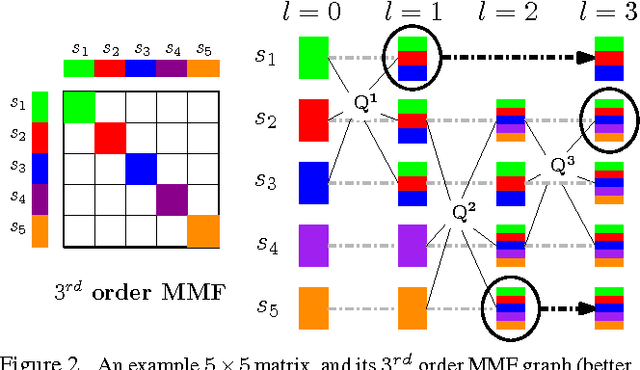
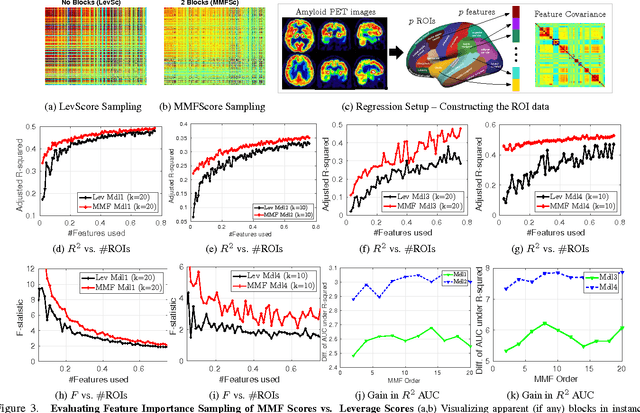
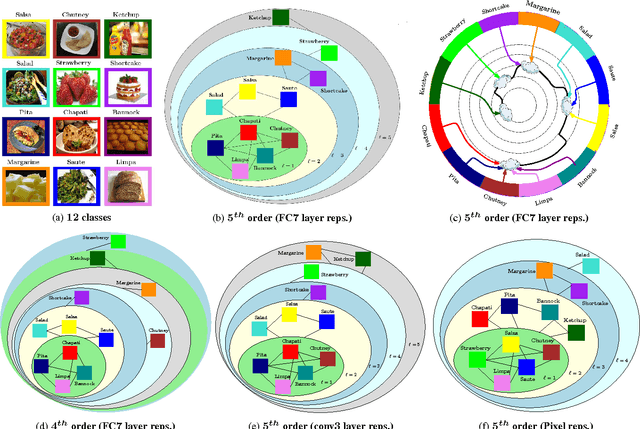
Multiresolution analysis and matrix factorization are foundational tools in computer vision. In this work, we study the interface between these two distinct topics and obtain techniques to uncover hierarchical block structure in symmetric matrices -- an important aspect in the success of many vision problems. Our new algorithm, the incremental multiresolution matrix factorization, uncovers such structure one feature at a time, and hence scales well to large matrices. We describe how this multiscale analysis goes much farther than what a direct global factorization of the data can identify. We evaluate the efficacy of the resulting factorizations for relative leveraging within regression tasks using medical imaging data. We also use the factorization on representations learned by popular deep networks, providing evidence of their ability to infer semantic relationships even when they are not explicitly trained to do so. We show that this algorithm can be used as an exploratory tool to improve the network architecture, and within numerous other settings in vision.