 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Riemannian PCA for Stochastic Canonical Correlation Analysis
Jun 08, 2021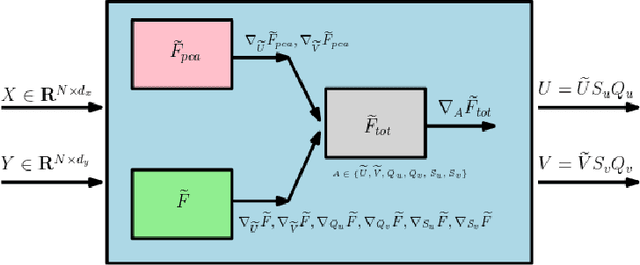
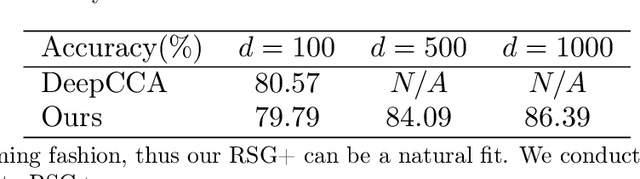
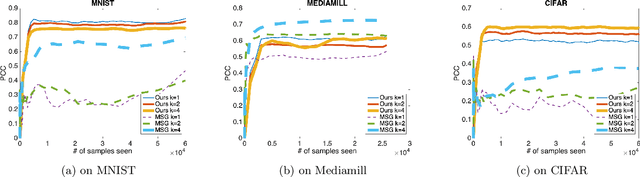
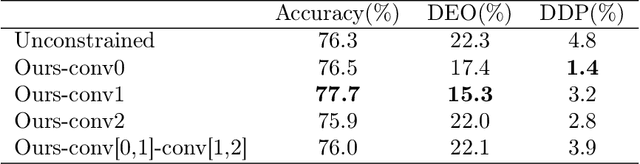
We present an efficient stochastic algorithm (RSG+) for canonical correlation analysis (CCA) using a reparametrization of the projection matrices. We show how this reparametrization (into structured matrices), simple in hindsight, directly presents an opportunity to repurpose/adjust mature techniques for numerical optimization on Riemannian manifolds. Our developments nicely complement existing methods for this problem which either require $O(d^3)$ time complexity per iteration with $O(\frac{1}{\sqrt{t}})$ convergence rate (where $d$ is the dimensionality) or only extract the top $1$ component with $O(\frac{1}{t})$ convergence rate. In contrast, our algorithm offers a strict improvement for this classical problem: it achieves $O(d^2k)$ runtime complexity per iteration for extracting the top $k$ canonical components with $O(\frac{1}{t})$ convergence rate. While the paper primarily focuses on the formulation and technical analysis of its properties, our experiments show that the empirical behavior on common datasets is quite promising. We also explore a potential application in training fair models where the label of protected attribute is missing or otherwise unavailable.
Connecting What to Say With Where to Look by Modeling Human Attention Traces
May 12, 2021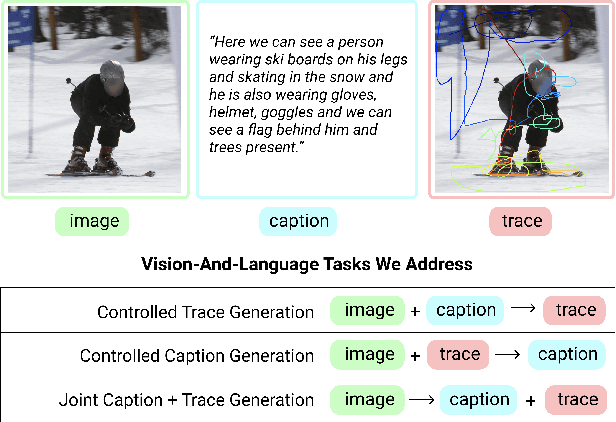

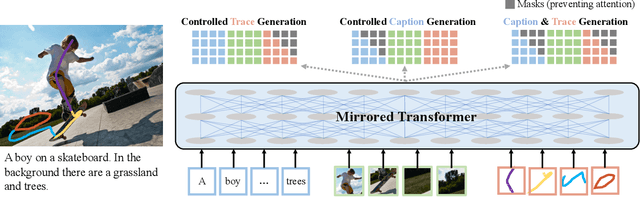
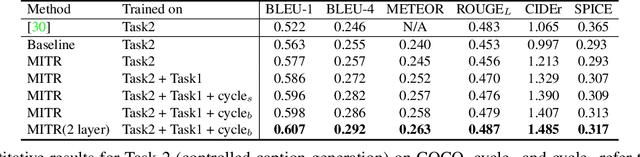
We introduce a unified framework to jointly model images, text, and human attention traces. Our work is built on top of the recent Localized Narratives annotation framework [30], where each word of a given caption is paired with a mouse trace segment. We propose two novel tasks: (1) predict a trace given an image and caption (i.e., visual grounding), and (2) predict a caption and a trace given only an image. Learning the grounding of each word is challenging, due to noise in the human-provided traces and the presence of words that cannot be meaningfully visually grounded. We present a novel model architecture that is jointly trained on dual tasks (controlled trace generation and controlled caption generation). To evaluate the quality of the generated traces, we propose a local bipartite matching (LBM) distance metric which allows the comparison of two traces of different lengths. Extensive experiments show our model is robust to the imperfect training data and outperforms the baselines by a clear margin. Moreover, we demonstrate that our model pre-trained on the proposed tasks can be also beneficial to the downstream task of COCO's guided image captioning. Our code and project page are publicly available.
Simpler Certified Radius Maximization by Propagating Covariances
Apr 13, 2021


One strategy for adversarially training a robust model is to maximize its certified radius -- the neighborhood around a given training sample for which the model's prediction remains unchanged. The scheme typically involves analyzing a "smoothed" classifier where one estimates the prediction corresponding to Gaussian samples in the neighborhood of each sample in the mini-batch, accomplished in practice by Monte Carlo sampling. In this paper, we investigate the hypothesis that this sampling bottleneck can potentially be mitigated by identifying ways to directly propagate the covariance matrix of the smoothed distribution through the network. To this end, we find that other than certain adjustments to the network, propagating the covariances must also be accompanied by additional accounting that keeps track of how the distributional moments transform and interact at each stage in the network. We show how satisfying these criteria yields an algorithm for maximizing the certified radius on datasets including Cifar-10, ImageNet, and Places365 while offering runtime savings on networks with moderate depth, with a small compromise in overall accuracy. We describe the details of the key modifications that enable practical use. Via various experiments, we evaluate when our simplifications are sensible, and what the key benefits and limitations are.
Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention
Mar 05, 2021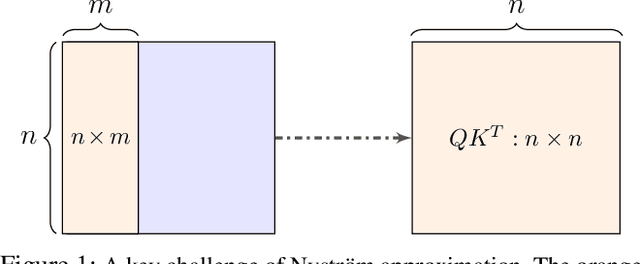

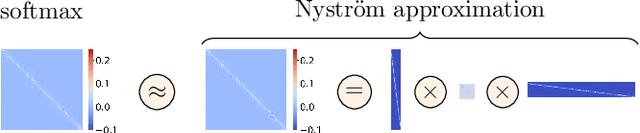

Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the input sequence length has limited its application to longer sequences -- a topic being actively studied in the community. To address this limitation, we propose Nystr\"{o}mformer -- a model that exhibits favorable scalability as a function of sequence length. Our idea is based on adapting the Nystr\"{o}m method to approximate standard self-attention with $O(n)$ complexity. The scalability of Nystr\"{o}mformer enables application to longer sequences with thousands of tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard sequence length, and find that our Nystr\"{o}mformer performs comparably, or in a few cases, even slightly better, than standard self-attention. On longer sequence tasks in the Long Range Arena (LRA) benchmark, Nystr\"{o}mformer performs favorably relative to other efficient self-attention methods. Our code is available at https://github.com/mlpen/Nystromformer.
Learning Invariant Representations using Inverse Contrastive Loss
Feb 16, 2021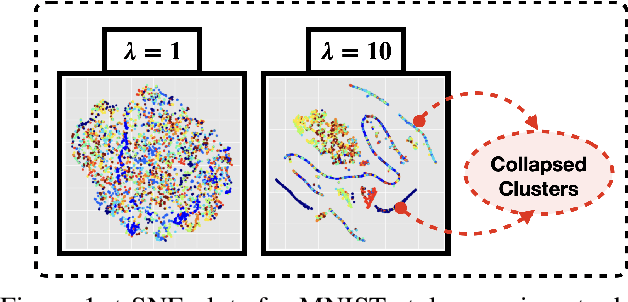
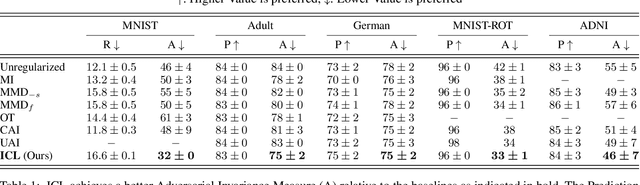
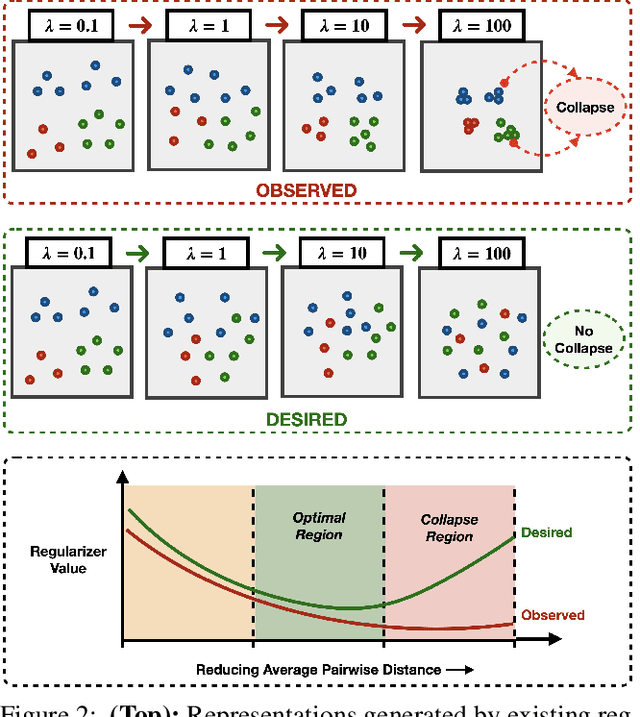
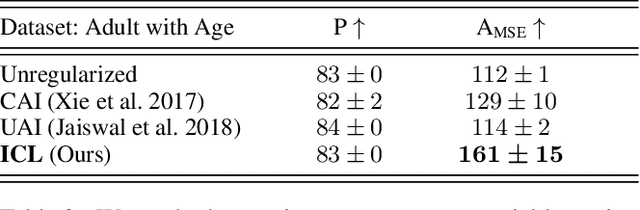
Learning invariant representations is a critical first step in a number of machine learning tasks. A common approach corresponds to the so-called information bottleneck principle in which an application dependent function of mutual information is carefully chosen and optimized. Unfortunately, in practice, these functions are not suitable for optimization purposes since these losses are agnostic of the metric structure of the parameters of the model. We introduce a class of losses for learning representations that are invariant to some extraneous variable of interest by inverting the class of contrastive losses, i.e., inverse contrastive loss (ICL). We show that if the extraneous variable is binary, then optimizing ICL is equivalent to optimizing a regularized MMD divergence. More generally, we also show that if we are provided a metric on the sample space, our formulation of ICL can be decomposed into a sum of convex functions of the given distance metric. Our experimental results indicate that models obtained by optimizing ICL achieve significantly better invariance to the extraneous variable for a fixed desired level of accuracy. In a variety of experimental settings, we show applicability of ICL for learning invariant representations for both continuous and discrete extraneous variables.
Flow-based Generative Models for Learning Manifold to Manifold Mappings
Dec 18, 2020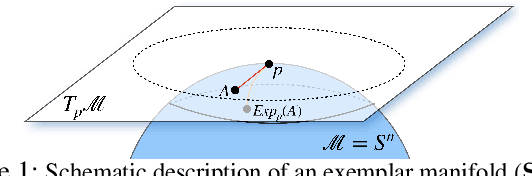
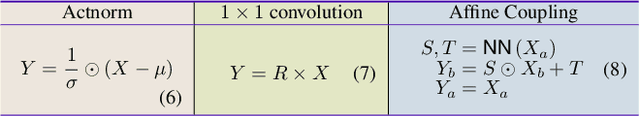
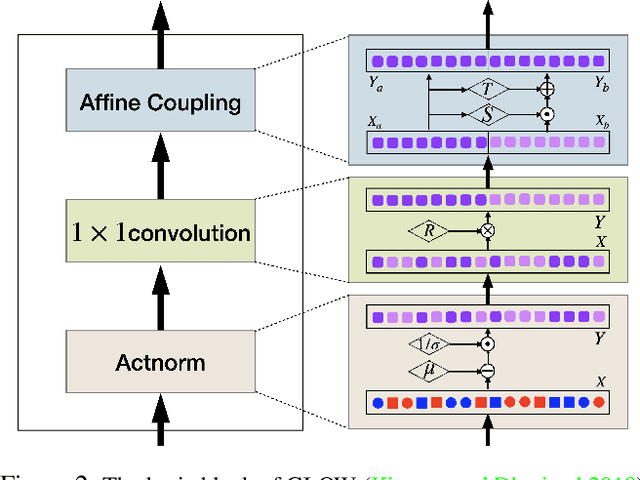

Many measurements or observations in computer vision and machine learning manifest as non-Euclidean data. While recent proposals (like spherical CNN) have extended a number of deep neural network architectures to manifold-valued data, and this has often provided strong improvements in performance, the literature on generative models for manifold data is quite sparse. Partly due to this gap, there are also no modality transfer/translation models for manifold-valued data whereas numerous such methods based on generative models are available for natural images. This paper addresses this gap, motivated by a need in brain imaging -- in doing so, we expand the operating range of certain generative models (as well as generative models for modality transfer) from natural images to images with manifold-valued measurements. Our main result is the design of a two-stream version of GLOW (flow-based invertible generative models) that can synthesize information of a field of one type of manifold-valued measurements given another. On the theoretical side, we introduce three kinds of invertible layers for manifold-valued data, which are not only analogous to their functionality in flow-based generative models (e.g., GLOW) but also preserve the key benefits (determinants of the Jacobian are easy to calculate). For experiments, on a large dataset from the Human Connectome Project (HCP), we show promising results where we can reliably and accurately reconstruct brain images of a field of orientation distribution functions (ODF) from diffusion tensor images (DTI), where the latter has a $5\times$ faster acquisition time but at the expense of worse angular resolution.
A Bayesian Approach with Type-2 Student-tMembership Function for T-S Model Identification
Sep 02, 2020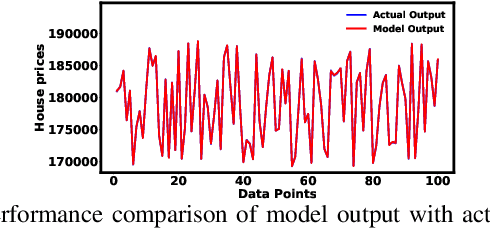
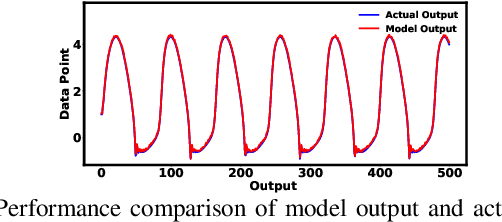

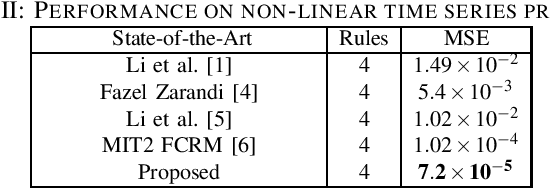
Clustering techniques have been proved highly suc-cessful for Takagi-Sugeno (T-S) fuzzy model identification. Inparticular, fuzzyc-regression clustering based on type-2 fuzzyset has been shown the remarkable results on non-sparse databut their performance degraded on sparse data. In this paper, aninnovative architecture for fuzzyc-regression model is presentedand a novel student-tdistribution based membership functionis designed for sparse data modelling. To avoid the overfitting,we have adopted a Bayesian approach for incorporating aGaussian prior on the regression coefficients. Additional noveltyof our approach lies in type-reduction where the final output iscomputed using Karnik Mendel algorithm and the consequentparameters of the model are optimized using Stochastic GradientDescent method. As detailed experimentation, the result showsthat proposed approach outperforms on standard datasets incomparison of various state-of-the-art methods.
Online Graph Completion: Multivariate Signal Recovery in Computer Vision
Aug 12, 2020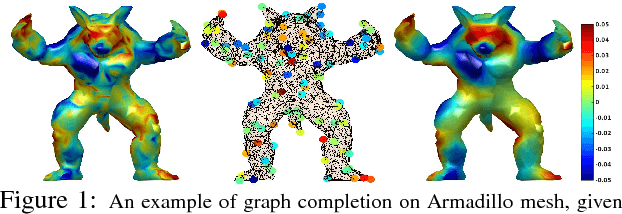
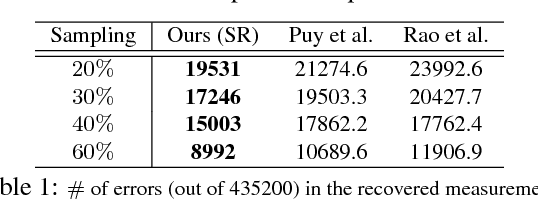
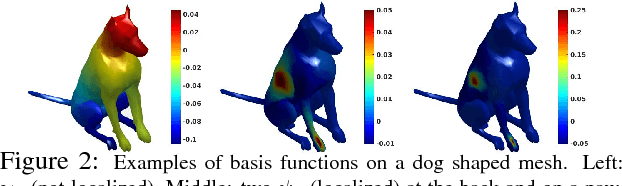
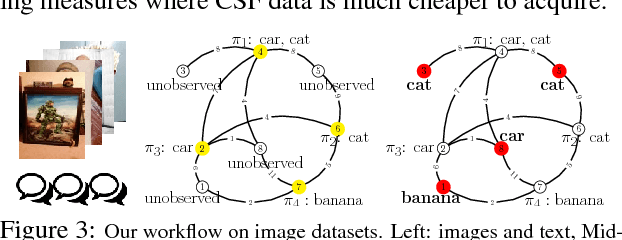
The adoption of "human-in-the-loop" paradigms in computer vision and machine learning is leading to various applications where the actual data acquisition (e.g., human supervision) and the underlying inference algorithms are closely interwined. While classical work in active learning provides effective solutions when the learning module involves classification and regression tasks, many practical issues such as partially observed measurements, financial constraints and even additional distributional or structural aspects of the data typically fall outside the scope of this treatment. For instance, with sequential acquisition of partial measurements of data that manifest as a matrix (or tensor), novel strategies for completion (or collaborative filtering) of the remaining entries have only been studied recently. Motivated by vision problems where we seek to annotate a large dataset of images via a crowdsourced platform or alternatively, complement results from a state-of-the-art object detector using human feedback, we study the "completion" problem defined on graphs, where requests for additional measurements must be made sequentially. We design the optimization model in the Fourier domain of the graph describing how ideas based on adaptive submodularity provide algorithms that work well in practice. On a large set of images collected from Imgur, we see promising results on images that are otherwise difficult to categorize. We also show applications to an experimental design problem in neuroimaging.
Improved Adaptive Type-2 Fuzzy Filter with Exclusively Two Fuzzy Membership Function for Filtering Salt and Pepper Noise
Aug 10, 2020
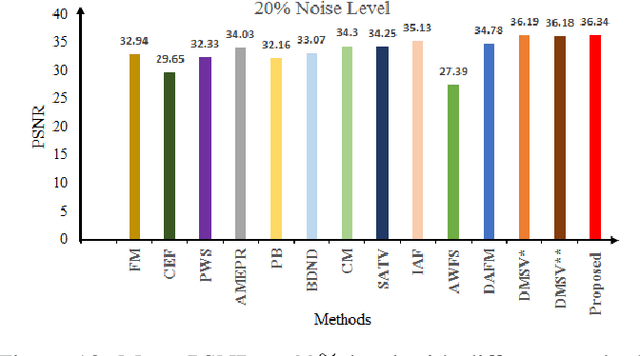
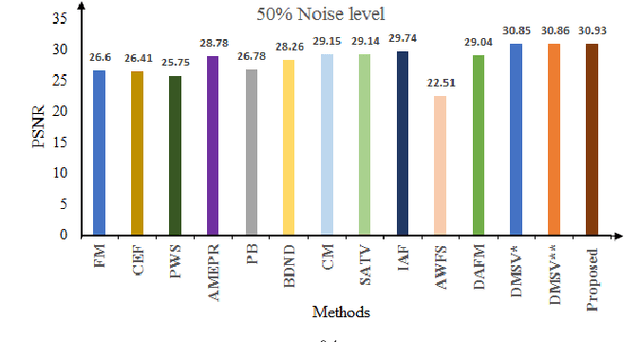
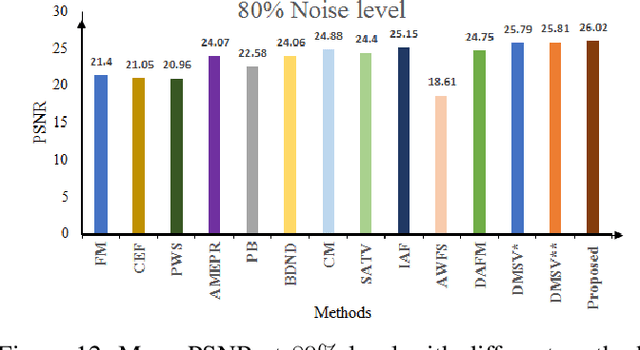
Image denoising is one of the preliminary steps in image processing methods in which the presence of noise can deteriorate the image quality. To overcome this limitation, in this paper a improved two-stage fuzzy filter is proposed for filtering salt and pepper noise from the images. In the first-stage, the pixels in the image are categorized as good or noisy based on adaptive thresholding using type-2 fuzzy logic with exclusively two different membership functions in the filter window. In the second-stage, the noisy pixels are denoised using modified ordinary fuzzy logic in the respective filter window. The proposed filter is validated on standard images with various noise levels. The proposed filter removes the noise and preserves useful image characteristics, i.e., edges and corners at higher noise level. The performance of the proposed filter is compared with the various state-of-the-art methods in terms of peak signal-to-noise ratio and computation time. To show the effectiveness of filter statistical tests, i.e., Friedman test and Bonferroni-Dunn (BD) test are also carried out which clearly ascertain that the proposed filter outperforms in comparison of various filtering approaches.
Physarum Powered Differentiable Linear Programming Layers and Applications
Apr 30, 2020

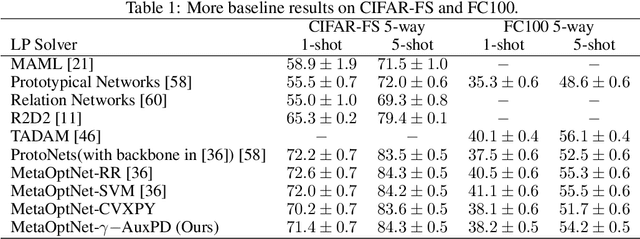
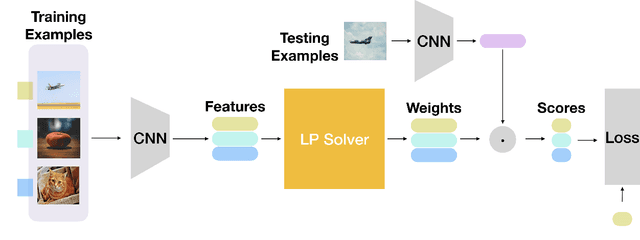
Consider a learning algorithm, which involves an internal call to an optimization routine such as a generalized eigenvalue problem, a cone programming problem or even sorting. Integrating such a method as layers within a trainable deep network in a numerically stable way is not simple -- for instance, only recently, strategies have emerged for eigendecomposition and differentiable sorting. We propose an efficient and differentiable solver for general linear programming problems which can be used in a plug and play manner within deep neural networks as a layer. Our development is inspired by a fascinating but not widely used link between dynamics of slime mold (physarum) and mathematical optimization schemes such as steepest descent. We describe our development and demonstrate the use of our solver in a video object segmentation task and meta-learning for few-shot learning. We review the relevant known results and provide a technical analysis describing its applicability for our use cases. Our solver performs comparably with a customized projected gradient descent method on the first task and outperforms the very recently proposed differentiable CVXPY solver on the second task. Experiments show that our solver converges quickly without the need for a feasible initial point. Interestingly, our scheme is easy to implement and can easily serve as layers whenever a learning procedure needs a fast approximate solution to a LP, within a larger network.