 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMakeupMirror: Improving Facial Attribute Preservation in Diffusion Models for Makeup Transfer
Jun 18, 2026Makeup transfer models enable fun augmented reality (AR) experiences as well as virtual try-on (VTO) for online makeup shopping. While recent state-of-the-art diffusion based solutions such as Stable-Makeup dramatically improve the accuracy and realism of makeup transfer, they still face limitations in identity and skin color preservation, making production-level VTO for makeup shopping unrealistic. In this work, we propose MakeupMirror, a diffusion-based approach to makeup transfer that makes significant progress towards preserving facial features and skin tone. We introduce several technical innovations over Stable-Makeup: (1) integration of facial geometry conditioning with ControlNets to maintain facial fidelity; (2) region-specific makeup transfer control to enable precise makeup application across facial regions such as skin, eyes and lips; (3) skin tone-based makeup transfer modulation that prevent skin tone alteration in cross-subject transfer scenarios; and (4) integration of a Levenberg-Marquardt Langevin sampler to speed up inference while maintaining generation quality. Our experiments on CPM-Real, Makeup Wild, and (herein newly collected, more diverse) MakeupSelfies datasets show that MakeupMirror improves relative facial recognition similarity by +60%, reduces relative skin tone difference by -50% over Stable-Makeup, with a latency of 0.7s, while achieving expert acceptance rate of 94% across core facial identity preservation criteria.
BodyMetric: Evaluating the Realism of Human Bodies in Text-to-Image Generation
Dec 06, 2024



Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
BodyMetric: Evaluating the Realism of HumanBodies in Text-to-Image Generation
Dec 05, 2024Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
LEAD: Latent Realignment for Human Motion Diffusion
Oct 18, 2024



Our goal is to generate realistic human motion from natural language. Modern methods often face a trade-off between model expressiveness and text-to-motion alignment. Some align text and motion latent spaces but sacrifice expressiveness; others rely on diffusion models producing impressive motions, but lacking semantic meaning in their latent space. This may compromise realism, diversity, and applicability. Here, we address this by combining latent diffusion with a realignment mechanism, producing a novel, semantically structured space that encodes the semantics of language. Leveraging this capability, we introduce the task of textual motion inversion to capture novel motion concepts from a few examples. For motion synthesis, we evaluate LEAD on HumanML3D and KIT-ML and show comparable performance to the state-of-the-art in terms of realism, diversity, and text-motion consistency. Our qualitative analysis and user study reveal that our synthesized motions are sharper, more human-like and comply better with the text compared to modern methods. For motion textual inversion, our method demonstrates improved capacity in capturing out-of-distribution characteristics in comparison to traditional VAEs.
Analysis of Classifier-Free Guidance Weight Schedulers
Apr 19, 2024Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. It operates by combining the conditional and unconditional predictions using a fixed weight. However, recent works vary the weights throughout the diffusion process, reporting superior results but without providing any rationale or analysis. By conducting comprehensive experiments, this paper provides insights into CFG weight schedulers. Our findings suggest that simple, monotonically increasing weight schedulers consistently lead to improved performances, requiring merely a single line of code. In addition, more complex parametrized schedulers can be optimized for further improvement, but do not generalize across different models and tasks.
A Hierarchy-Aware Pose Representation for Deep Character Animation
Nov 27, 2021
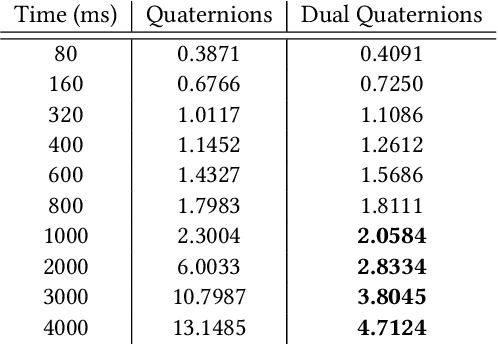
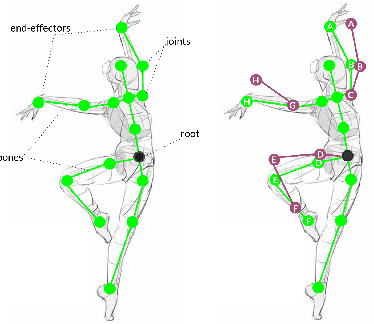

Data-driven character animation techniques rely on the existence of a properly established model of motion, capable of describing its rich context. However, commonly used motion representations often fail to accurately encode the full articulation of motion, or present artifacts. In this work, we address the fundamental problem of finding a robust pose representation for motion modeling, suitable for deep character animation, one that can better constrain poses and faithfully capture nuances correlated with skeletal characteristics. Our representation is based on dual quaternions, the mathematical abstractions with well-defined operations, which simultaneously encode rotational and positional orientation, enabling a hierarchy-aware encoding, centered around the root. We demonstrate that our representation overcomes common motion artifacts, and assess its performance compared to other popular representations. We conduct an ablation study to evaluate the impact of various losses that can be incorporated during learning. Leveraging the fact that our representation implicitly encodes skeletal motion attributes, we train a network on a dataset comprising of skeletons with different proportions, without the need to retarget them first to a universal skeleton, which causes subtle motion elements to be missed. We show that smooth and natural poses can be achieved, paving the way for fascinating applications.