 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Head Reenactment with Latent Pose Descriptors
Apr 24, 2020
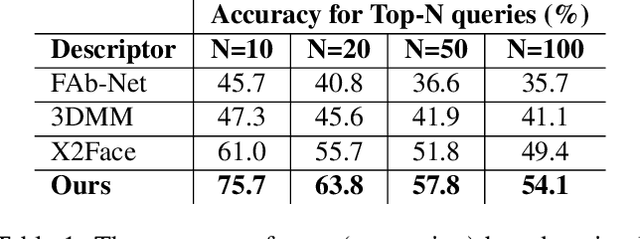
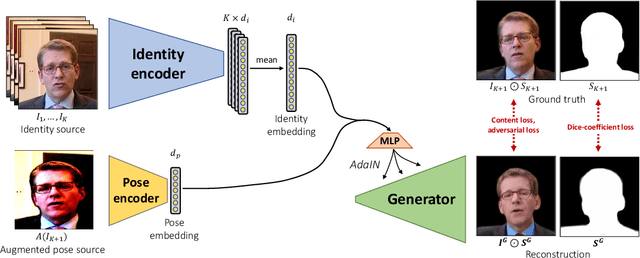

We propose a neural head reenactment system, which is driven by a latent pose representation and is capable of predicting the foreground segmentation alongside the RGB image. The latent pose representation is learned as a part of the entire reenactment system, and the learning process is based solely on image reconstruction losses. We show that despite its simplicity, with a large and diverse enough training dataset, such learning successfully decomposes pose from identity. The resulting system can then reproduce mimics of the driving person and, furthermore, can perform cross-person reenactment. Additionally, we show that the learned descriptors are useful for other pose-related tasks, such as keypoint prediction and pose-based retrieval.
High-Resolution Daytime Translation Without Domain Labels
Mar 23, 2020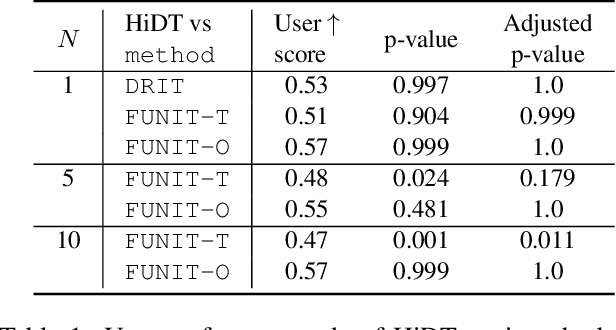
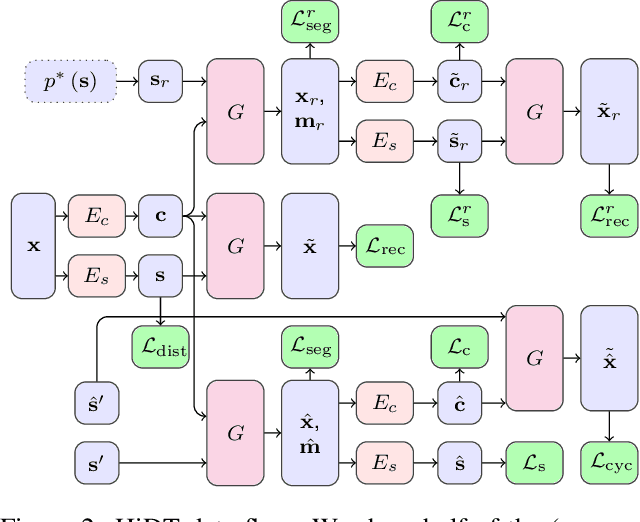
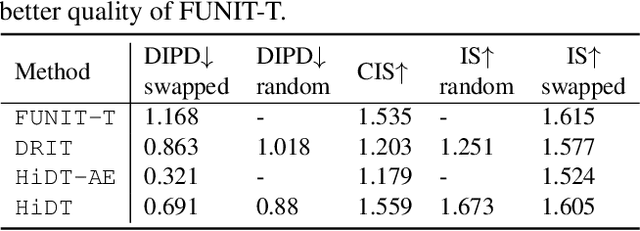
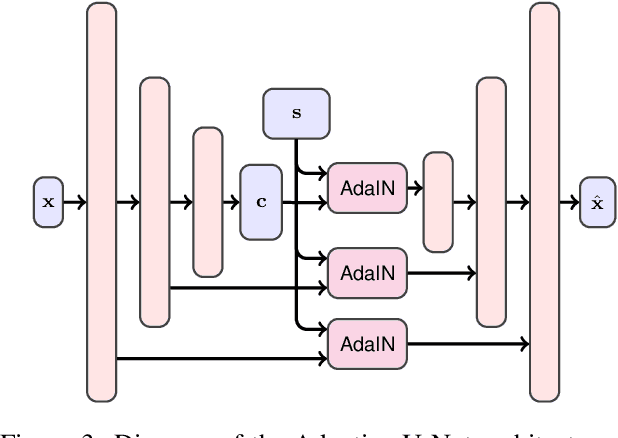
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.
Neural Point-Based Graphics
Jul 16, 2019
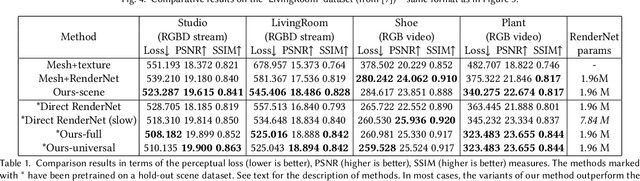


We present a new point-based approach for modeling complex scenes. The approach uses a raw point cloud as the geometric representation of a scene, and augments each point with a learnable neural descriptor that encodes local geometry and appearance. A deep rendering network is learned in parallel with the descriptors, so that new views of the scene can be obtained by passing the rasterizations of a point cloud from new viewpoints through this network. The input rasterizations use the learned descriptors as point pseudo-colors. We show that the proposed approach can be used for modeling complex scenes and obtaining their photorealistic views, while avoiding explicit surface estimation and meshing. In particular, compelling results are obtained for scene scanned using hand-held commodity RGB-D sensors as well as standard RGB cameras even in the presence of objects that are challenging for standard mesh-based modeling.
Stereo relative pose from line and point feature triplets
Jun 29, 2019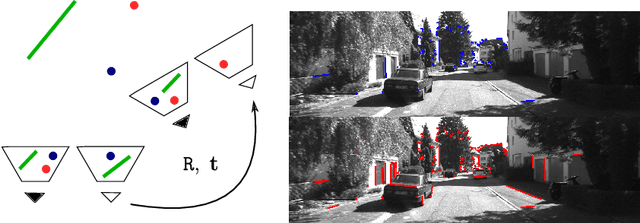
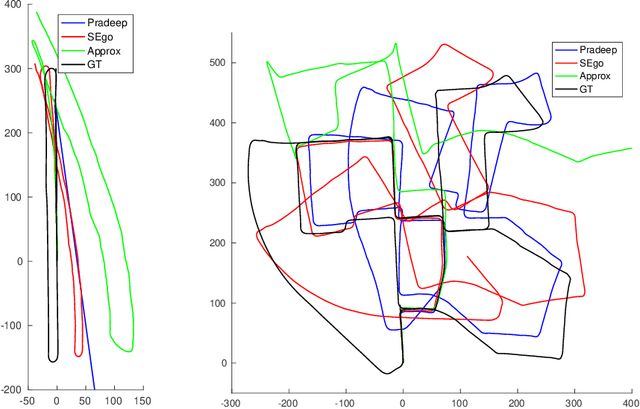
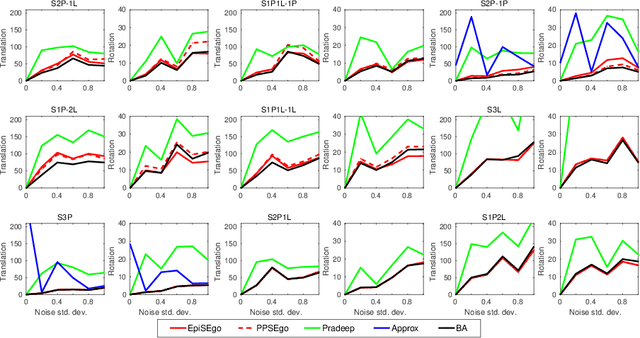
Stereo relative pose problem lies at the core of stereo visual odometry systems that are used in many applications. In this work, we present two minimal solvers for the stereo relative pose. We specifically consider the case when a minimal set consists of three point or line features and each of them has three known projections on two stereo cameras. We validate the importance of this formulation for practical purposes in our experiments with motion estimation. We then present a complete classification of minimal cases with three point or line correspondences each having three projections, and present two new solvers that can handle all such cases. We demonstrate a considerable effect from the integration of the new solvers into a visual SLAM system.
Textured Neural Avatars
May 21, 2019
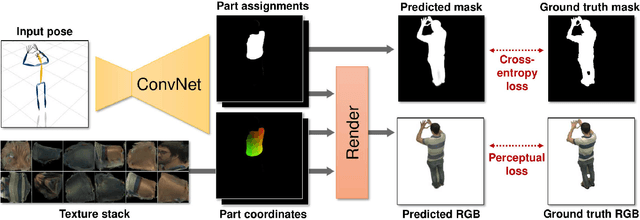


We present a system for learning full-body neural avatars, i.e. deep networks that produce full-body renderings of a person for varying body pose and camera position. Our system takes the middle path between the classical graphics pipeline and the recent deep learning approaches that generate images of humans using image-to-image translation. In particular, our system estimates an explicit two-dimensional texture map of the model surface. At the same time, it abstains from explicit shape modeling in 3D. Instead, at test time, the system uses a fully-convolutional network to directly map the configuration of body feature points w.r.t. the camera to the 2D texture coordinates of individual pixels in the image frame. We show that such a system is capable of learning to generate realistic renderings while being trained on videos annotated with 3D poses and foreground masks. We also demonstrate that maintaining an explicit texture representation helps our system to achieve better generalization compared to systems that use direct image-to-image translation.
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
May 20, 2019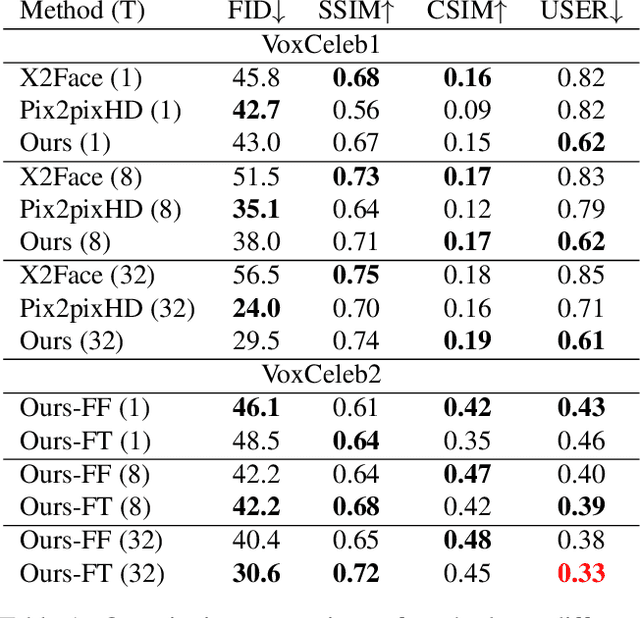
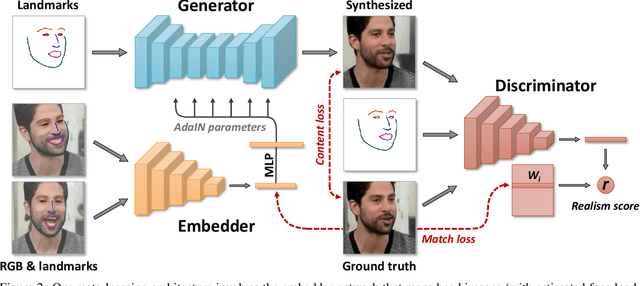
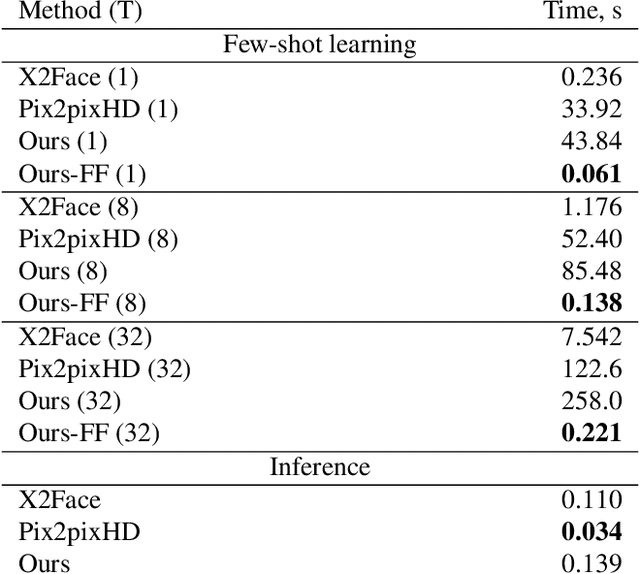

Several recent works have shown how highly realistic human head images can be obtained by training convolutional neural networks to generate them. In order to create a personalized talking head model, these works require training on a large dataset of images of a single person. However, in many practical scenarios, such personalized talking head models need to be learned from a few image views of a person, potentially even a single image. Here, we present a system with such few-shot capability. It performs lengthy meta-learning on a large dataset of videos, and after that is able to frame few- and one-shot learning of neural talking head models of previously unseen people as adversarial training problems with high capacity generators and discriminators. Crucially, the system is able to initialize the parameters of both the generator and the discriminator in a person-specific way, so that training can be based on just a few images and done quickly, despite the need to tune tens of millions of parameters. We show that such an approach is able to learn highly realistic and personalized talking head models of new people and even portrait paintings.
Learnable Triangulation of Human Pose
May 14, 2019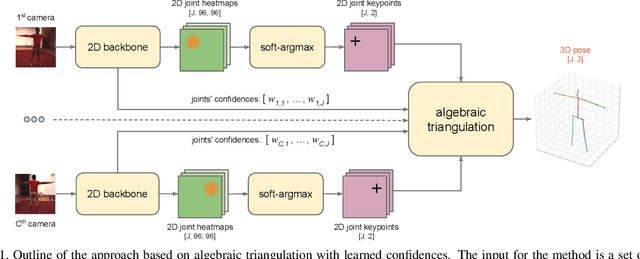
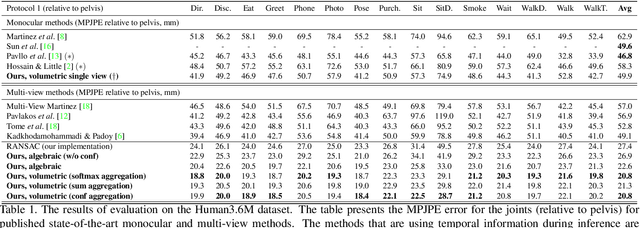
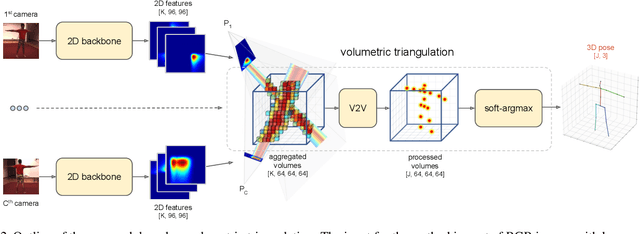

We present two novel solutions for multi-view 3D human pose estimation based on new learnable triangulation methods that combine 3D information from multiple 2D views. The first (baseline) solution is a basic differentiable algebraic triangulation with an addition of confidence weights estimated from the input images. The second solution is based on a novel method of volumetric aggregation from intermediate 2D backbone feature maps. The aggregated volume is then refined via 3D convolutions that produce final 3D joint heatmaps and allow modelling a human pose prior. Crucially, both approaches are end-to-end differentiable, which allows us to directly optimize the target metric. We demonstrate transferability of the solutions across datasets and considerably improve the multi-view state of the art on the Human3.6M dataset. Video demonstration, annotations and additional materials will be posted on our project page (https://saic-violet.github.io/learnable-triangulation).
Instance Segmentation of Biological Images Using Harmonic Embeddings
Apr 10, 2019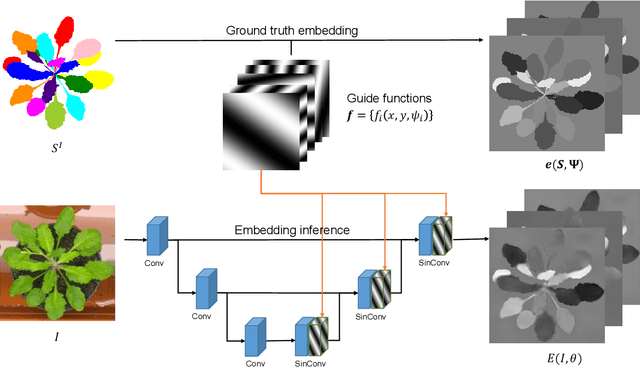
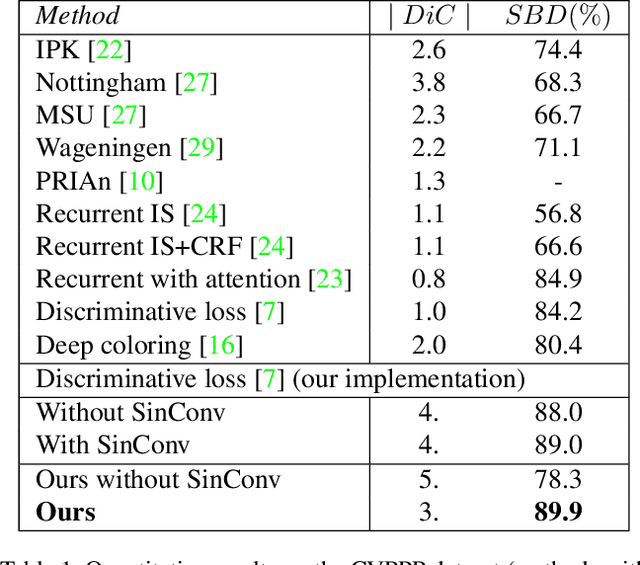


We present a new instance segmentation approach tailored to biological images, where instances may correspond to individual cells, organisms or plant parts. Unlike instance segmentation for user photographs or road scenes, in biological data object instances may be particularly densely packed, the appearance variation may be particularly low, the processing power may be restricted, while, on the other hand, the variability of sizes of individual instances may be limited. These peculiarities are successfully addressed and exploited by the proposed approach. Our approach describes each object instance using an expectation of a limited number of sine waves with frequencies and phases adjusted to particular object sizes and densities. At train time, a fully-convolutional network is learned to predict the object embeddings at each pixel using a simple pixelwise regression loss, while at test time the instances are recovered using clustering in the embeddings space. In the experiments, we show that our approach outperforms previous embedding-based instance segmentation approaches on a number of biological datasets, achieving state-of-the-art on a popular CVPPP benchmark. Notably, this excellent performance is combined with computational efficiency that is needed for deployment to domain specialists. The source code is publicly available at Github: https://github.com/kulikovv/harmonic
Hyperbolic Image Embeddings
Apr 03, 2019
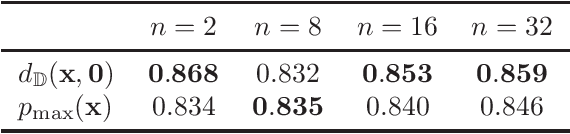
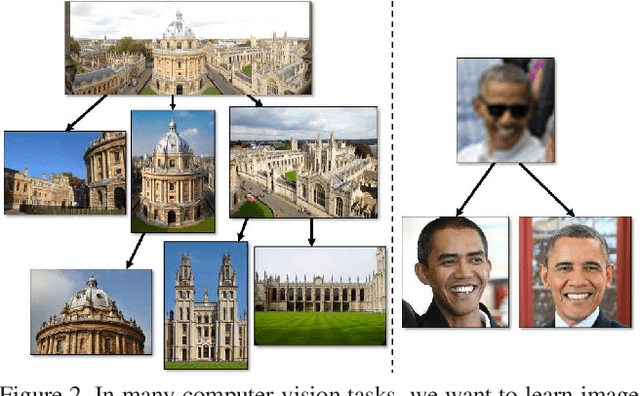
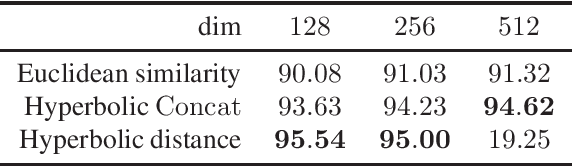
Computer vision tasks such as image classification, image retrieval and few-shot learning are currently dominated by Euclidean and spherical embeddings, so that the final decisions about class belongings or the degree of similarity are made using linear hyperplanes, Euclidean distances, or spherical geodesic distances (cosine similarity). In this work, we demonstrate that in many practical scenarios hyperbolic embeddings provide a better alternative.
Coordinate-based Texture Inpainting for Pose-Guided Image Generation
Nov 28, 2018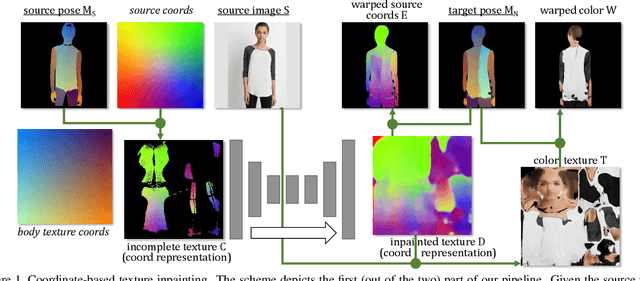



We present a new deep learning approach to pose-guided resynthesis of human photographs. At the heart of the new approach is the estimation of the complete body surface texture based on a single photograph. Since the input photograph always observes only a part of the surface, we suggest a new inpainting method that completes the texture of the human body. Rather than working directly with colors of texture elements, the inpainting network estimates an appropriate source location in the input image for each element of the body surface. This correspondence field between the input image and the texture is then further warped into the target image coordinate frame based on the desired pose, effectively establishing the correspondence between the source and the target view even when the pose change is drastic. The final convolutional network then uses the established correspondence and all other available information to synthesize the output image using a fully-convolutional architecture with deformable convolutions. We show the state-of-the-art result for pose-guided image synthesis. Additionally, we demonstrate the performance of our system for garment transfer and pose-guided face resynthesis.