 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Contrastive Learning for Pre-trained Language Model Fine-tuning
Nov 12, 2020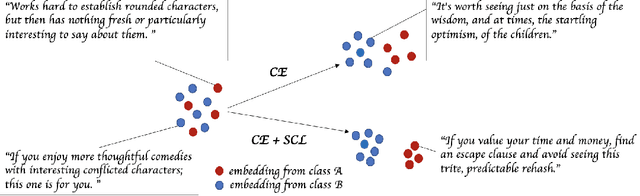


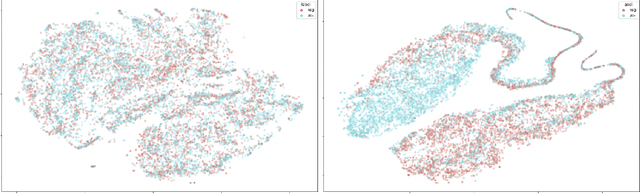
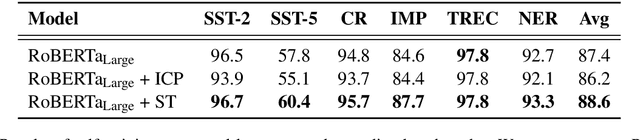
State-of-the-art natural language understanding classification models follow two-stages: pre-training a large language model on an auxiliary task, and then fine-tuning the model on a task-specific labeled dataset using cross-entropy loss. Cross-entropy loss has several shortcomings that can lead to sub-optimal generalization and instability. Driven by the intuition that good generalization requires capturing the similarity between examples in one class and contrasting them with examples in other classes, we propose a supervised contrastive learning (SCL) objective for the fine-tuning stage. Combined with cross-entropy, the SCL loss we propose obtains improvements over a strong RoBERTa-Large baseline on multiple datasets of the GLUE benchmark in both the high-data and low-data regimes, and it does not require any specialized architecture, data augmentation of any kind, memory banks, or additional unsupervised data. We also demonstrate that the new objective leads to models that are more robust to different levels of noise in the training data, and can generalize better to related tasks with limited labeled task data.
Self-training Improves Pre-training for Natural Language Understanding
Oct 05, 2020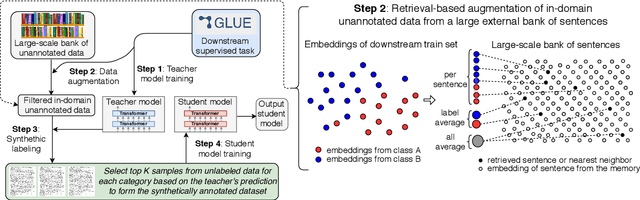
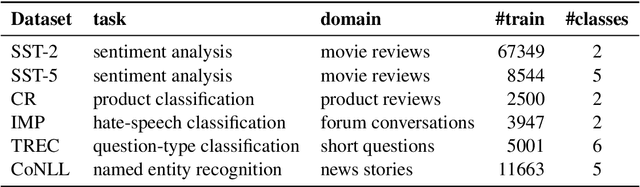

Unsupervised pre-training has led to much recent progress in natural language understanding. In this paper, we study self-training as another way to leverage unlabeled data through semi-supervised learning. To obtain additional data for a specific task, we introduce SentAugment, a data augmentation method which computes task-specific query embeddings from labeled data to retrieve sentences from a bank of billions of unlabeled sentences crawled from the web. Unlike previous semi-supervised methods, our approach does not require in-domain unlabeled data and is therefore more generally applicable. Experiments show that self-training is complementary to strong RoBERTa baselines on a variety of tasks. Our augmentation approach leads to scalable and effective self-training with improvements of up to 2.6% on standard text classification benchmarks. Finally, we also show strong gains on knowledge-distillation and few-shot learning.
Conversational Semantic Parsing
Sep 28, 2020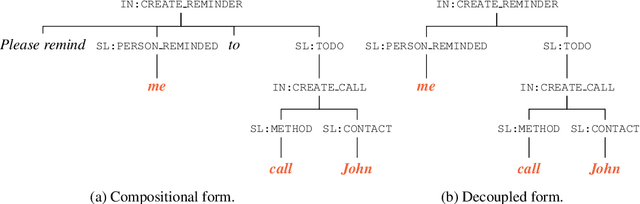
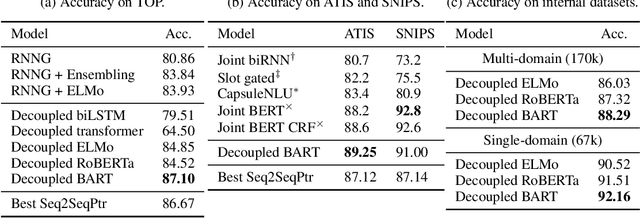
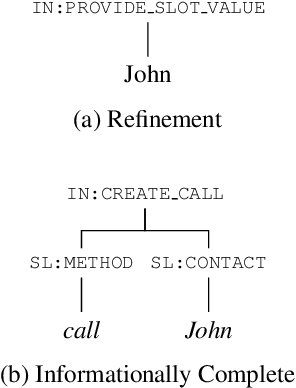
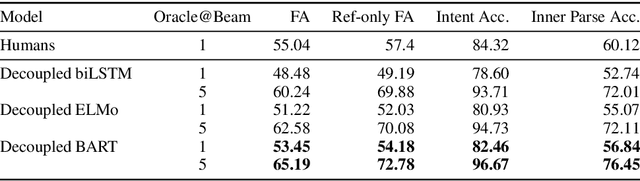
The structured representation for semantic parsing in task-oriented assistant systems is geared towards simple understanding of one-turn queries. Due to the limitations of the representation, the session-based properties such as co-reference resolution and context carryover are processed downstream in a pipelined system. In this paper, we propose a semantic representation for such task-oriented conversational systems that can represent concepts such as co-reference and context carryover, enabling comprehensive understanding of queries in a session. We release a new session-based, compositional task-oriented parsing dataset of 20k sessions consisting of 60k utterances. Unlike Dialog State Tracking Challenges, the queries in the dataset have compositional forms. We propose a new family of Seq2Seq models for the session-based parsing above, which achieve better or comparable performance to the current state-of-the-art on ATIS, SNIPS, TOP and DSTC2. Notably, we improve the best known results on DSTC2 by up to 5 points for slot-carryover.
Preserving Integrity in Online Social Networks
Sep 25, 2020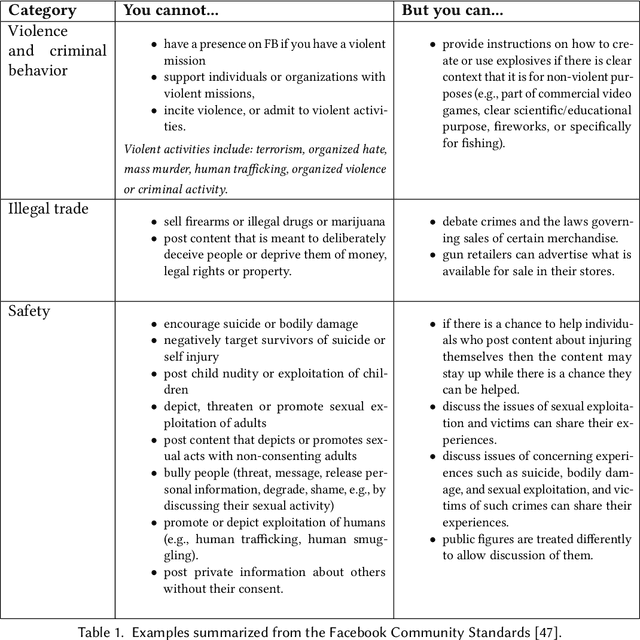
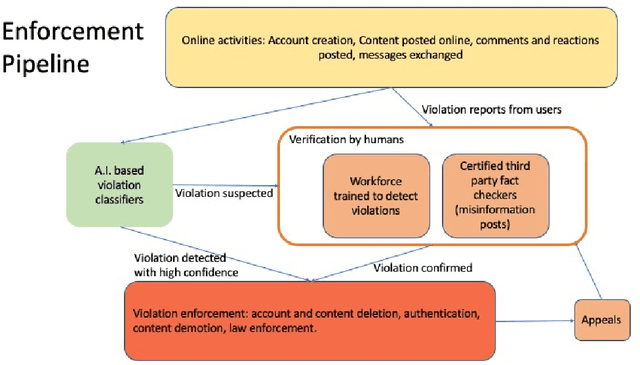
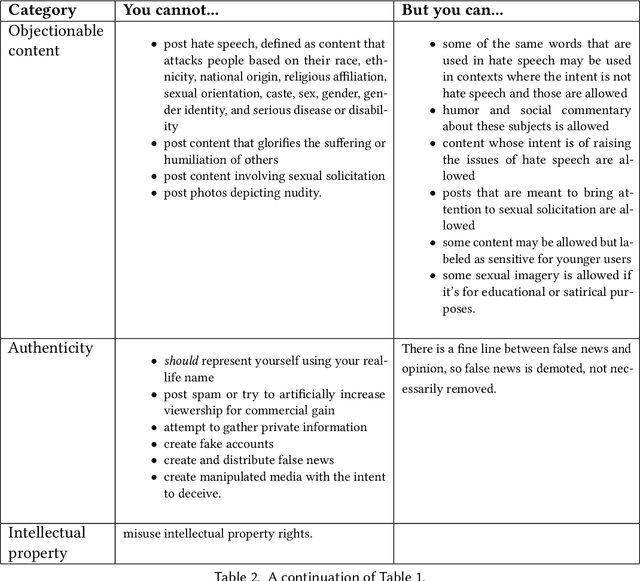
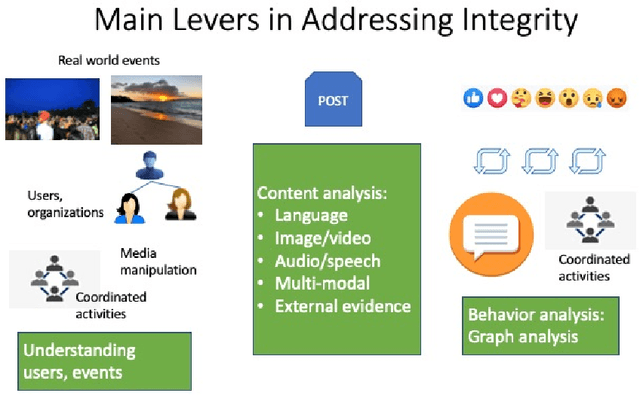
Online social networks provide a platform for sharing information and free expression. However, these networks are also used for malicious purposes, such as distributing misinformation and hate speech, selling illegal drugs, and coordinating sex trafficking or child exploitation. This paper surveys the state of the art in keeping online platforms and their users safe from such harm, also known as the problem of preserving integrity. This survey comes from the perspective of having to combat a broad spectrum of integrity violations at Facebook. We highlight the techniques that have been proven useful in practice and that deserve additional attention from the academic community. Instead of discussing the many individual violation types, we identify key aspects of the social-media eco-system, each of which is common to a wide variety violation types. Furthermore, each of these components represents an area for research and development, and the innovations that are found can be applied widely.
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Oct 29, 2019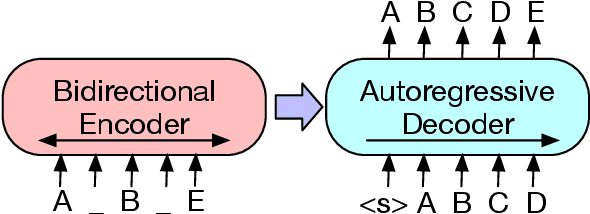
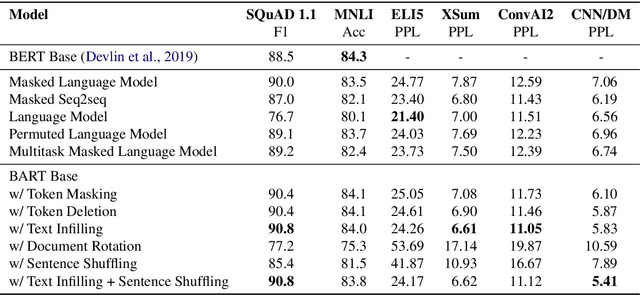
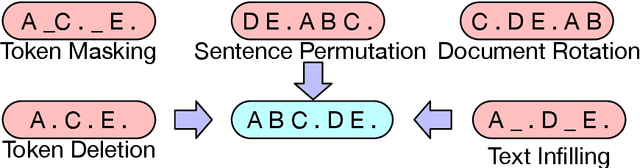
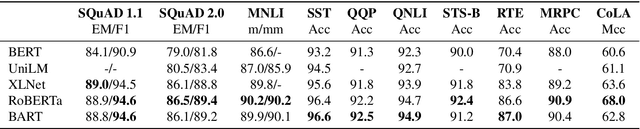
We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pretraining schemes. We evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE. BART also provides a 1.1 BLEU increase over a back-translation system for machine translation, with only target language pretraining. We also report ablation experiments that replicate other pretraining schemes within the BART framework, to better measure which factors most influence end-task performance.