 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Parametric Efficient Policy Learning with Continuous Actions
May 24, 2019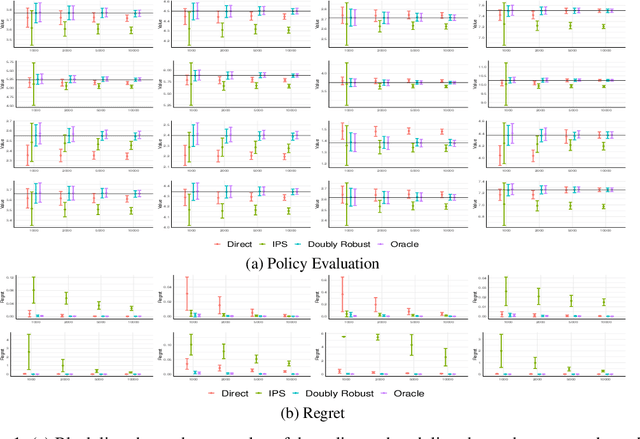
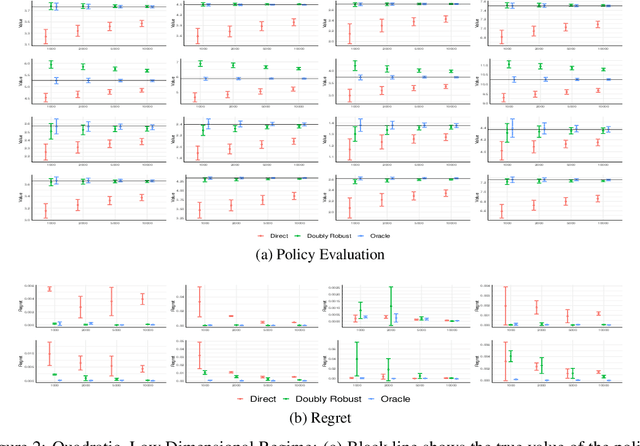
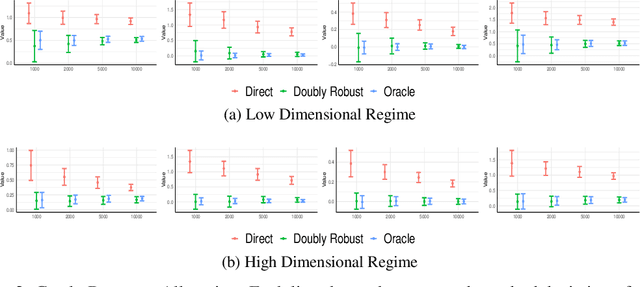
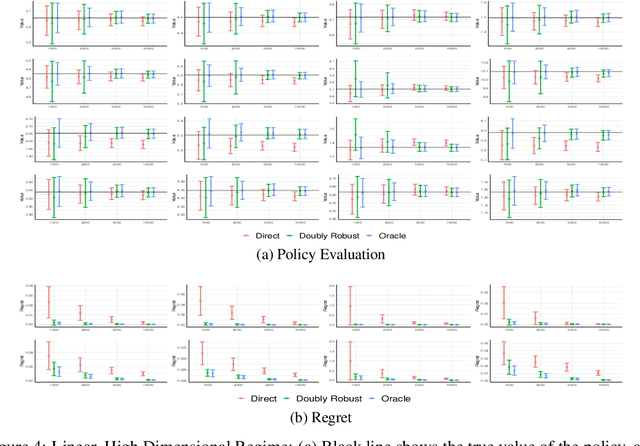
We consider off-policy evaluation and optimization with continuous action spaces. We focus on observational data where the data collection policy is unknown and needs to be estimated. We take a semi-parametric approach where the value function takes a known parametric form in the treatment, but we are agnostic on how it depends on the observed contexts. We propose a doubly robust off-policy estimate for this setting and show that off-policy optimization based on this estimate is robust to estimation errors of the policy function or the regression model. Our results also apply if the model does not satisfy our semi-parametric form, but rather we measure regret in terms of the best projection of the true value function to this functional space. Our work extends prior approaches of policy optimization from observational data that only considered discrete actions. We provide an experimental evaluation of our method in a synthetic data example motivated by optimal personalized pricing and costly resource allocation.
Orthogonal Statistical Learning
Jan 25, 2019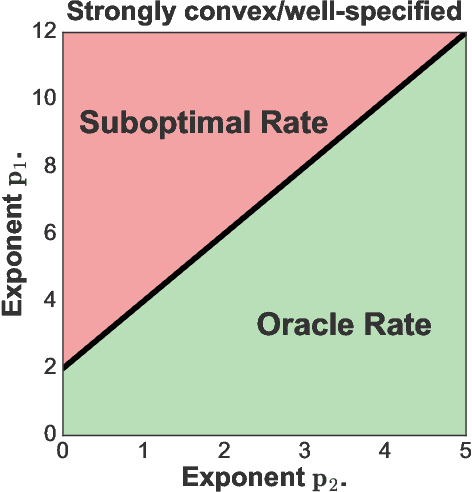
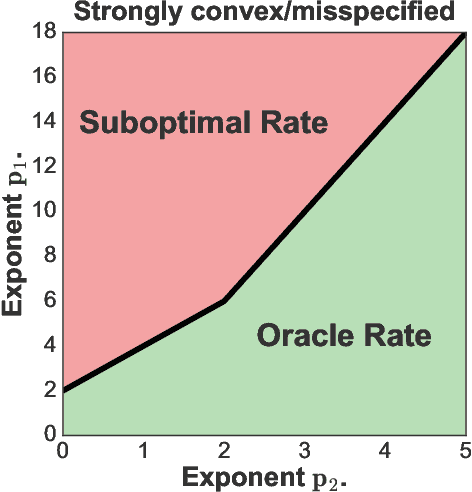
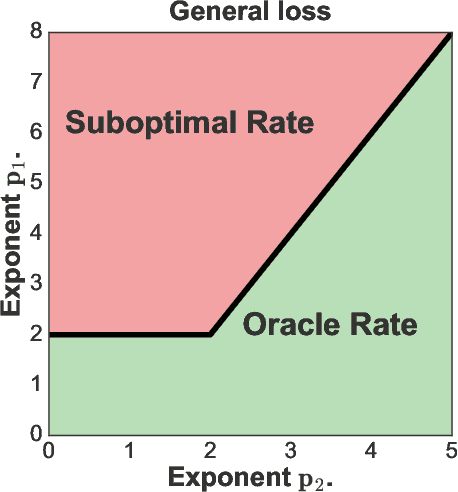
We provide excess risk guarantees for statistical learning in the presence of an unknown nuisance component. We analyze a two-stage sample splitting meta-algorithm that takes as input two arbitrary estimation algorithms: one for the target model and one for the nuisance model. We show that if the population risk satisfies a condition called Neyman orthogonality, the impact of the first stage error on the excess risk bound achieved by the meta-algorithm is of second order. Our general theorem is agnostic to the particular algorithms used for the target and nuisance and only makes an assumption on their individual performance. This enables the use of a plethora of existing results from statistical learning and machine learning literature to give new guarantees for learning with a nuisance component. Moreover, by focusing on excess risk rather than parameter estimation, we can give guarantees under weaker assumptions than in previous works and accommodate the case where the target parameter belongs to a complex nonparametric class. When the nuisance and target parameters belong to arbitrary classes, we characterize conditions on the metric entropy such that oracle rates---rates of the same order as if we knew the nuisance model---are achieved. We also analyze the rates achieved by specific estimation algorithms such as variance-penalized empirical risk minimization, neural network estimation and sparse high-dimensional linear model estimation. We highlight the applicability of our results via four applications of primary importance: 1) heterogeneous treatment effect estimation, 2) offline policy optimization, 3) domain adaptation, and 4) learning with missing data.
Non-Parametric Inference Adaptive to Intrinsic Dimension
Jan 11, 2019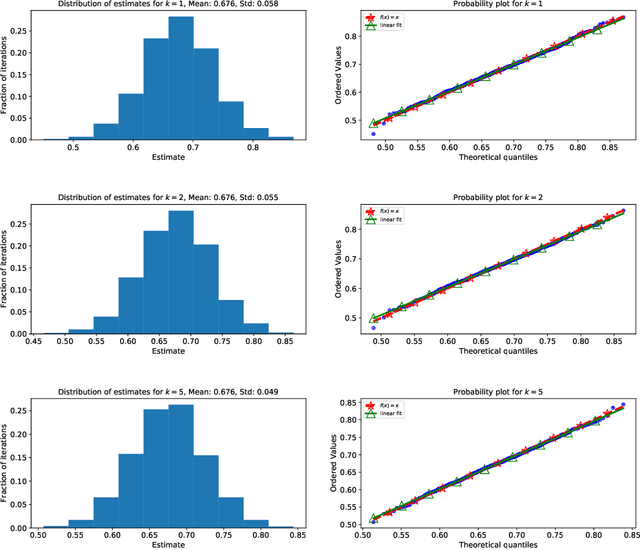
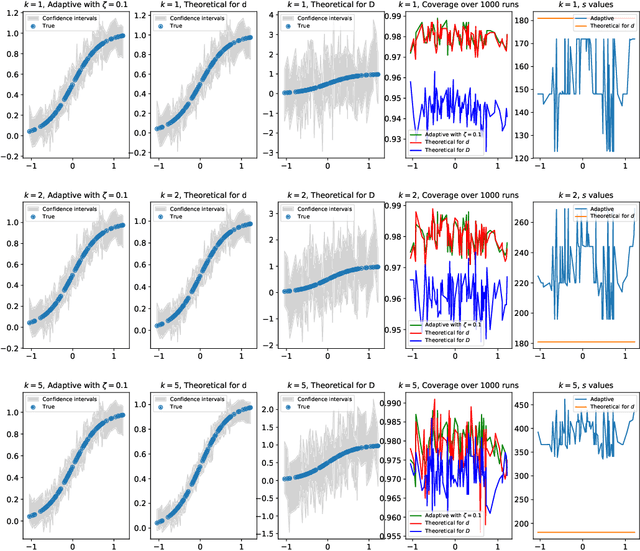
We consider non-parametric estimation and inference of conditional moment models in high dimensions. We show that even when the dimension $D$ of the conditioning variable is larger than the sample size $n$, estimation and inference is feasible as long as the distribution of the conditioning variable has small intrinsic dimension $d$, as measured by the doubling dimension. Our estimation is based on a sub-sampled ensemble of the $k$-nearest neighbors $Z$-estimator. We show that if the intrinsic dimension of the co-variate distribution is equal to $d$, then the finite sample estimation error of our estimator is of order $n^{-1/(d+2)}$ and our estimate is $n^{1/(d+2)}$-asymptotically normal, irrespective of $D$. We discuss extensions and applications to heterogeneous treatment effect estimation.
Orthogonal Machine Learning: Power and Limitations
Aug 01, 2018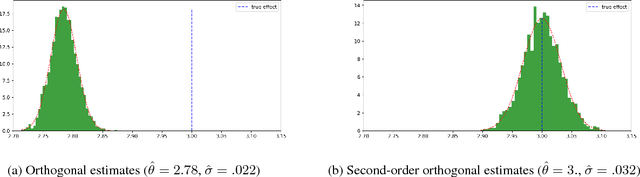
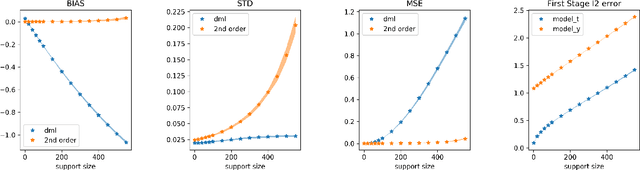
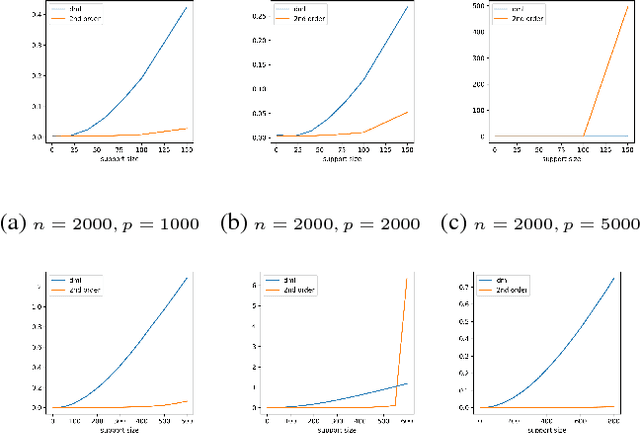
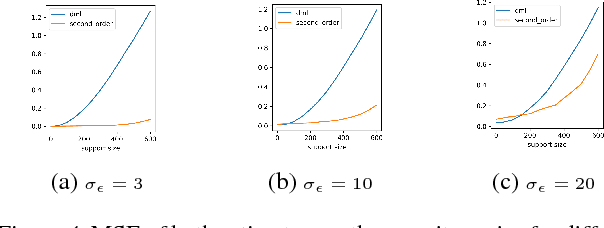
Double machine learning provides $\sqrt{n}$-consistent estimates of parameters of interest even when high-dimensional or nonparametric nuisance parameters are estimated at an $n^{-1/4}$ rate. The key is to employ Neyman-orthogonal moment equations which are first-order insensitive to perturbations in the nuisance parameters. We show that the $n^{-1/4}$ requirement can be improved to $n^{-1/(2k+2)}$ by employing a $k$-th order notion of orthogonality that grants robustness to more complex or higher-dimensional nuisance parameters. In the partially linear regression setting popular in causal inference, we show that we can construct second-order orthogonal moments if and only if the treatment residual is not normally distributed. Our proof relies on Stein's lemma and may be of independent interest. We conclude by demonstrating the robustness benefits of an explicit doubly-orthogonal estimation procedure for treatment effect.
Semiparametric Contextual Bandits
Jul 16, 2018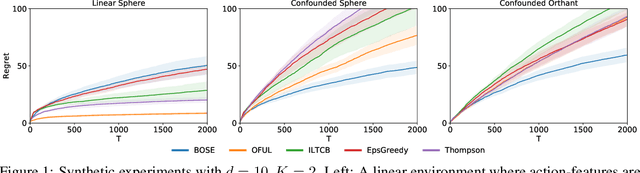
This paper studies semiparametric contextual bandits, a generalization of the linear stochastic bandit problem where the reward for an action is modeled as a linear function of known action features confounded by an non-linear action-independent term. We design new algorithms that achieve $\tilde{O}(d\sqrt{T})$ regret over $T$ rounds, when the linear function is $d$-dimensional, which matches the best known bounds for the simpler unconfounded case and improves on a recent result of Greenewald et al. (2017). Via an empirical evaluation, we show that our algorithms outperform prior approaches when there are non-linear confounding effects on the rewards. Technically, our algorithms use a new reward estimator inspired by doubly-robust approaches and our proofs require new concentration inequalities for self-normalized martingales.
Orthogonal Random Forest for Heterogeneous Treatment Effect Estimation
Jul 12, 2018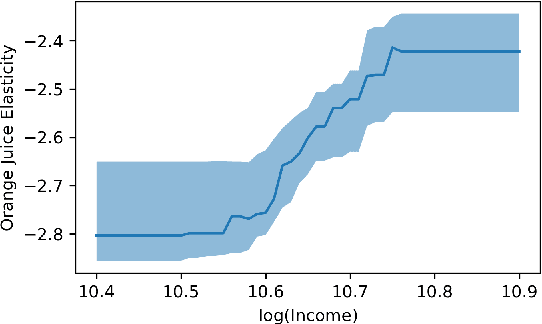
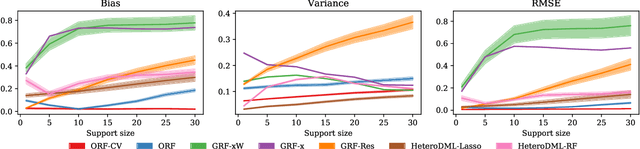
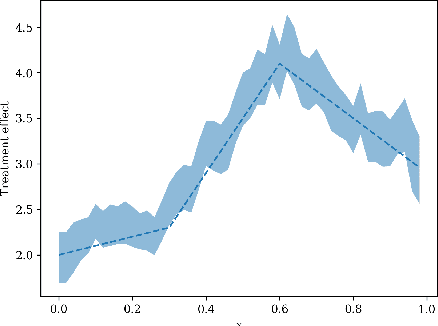
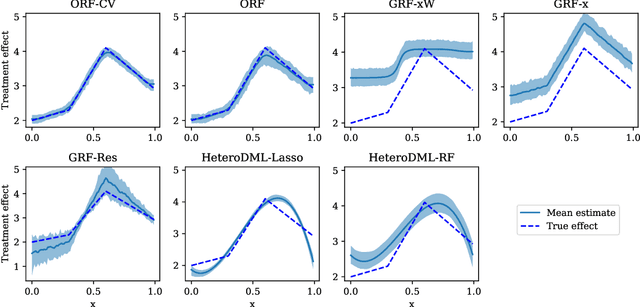
We study the problem of estimating heterogeneous treatment effects from observational data, where the treatment policy on the collected data was determined by potentially many confounding observable variables. We propose orthogonal random forest, an algorithm that combines orthogonalization, a technique that effectively removes the confounding effect in two-stage estimation, with generalized random forests [Athey et al., 2017], a flexible method for estimating treatment effect heterogeneity. We prove a consistency rate result of our estimator in the partially linear regression model, and en route we provide a consistency analysis for a general framework of performing generalized method of moments (GMM) estimation. We also provide a comprehensive empirical evaluation of our algorithms, and show that they consistently outperform baseline approaches.
Bayesian Exploration: Incentivizing Exploration in Bayesian Games
Jul 01, 2018We consider a ubiquitous scenario in the Internet economy when individual decision-makers (henceforth, agents) both produce and consume information as they make strategic choices in an uncertain environment. This creates a three-way tradeoff between exploration (trying out insufficiently explored alternatives to help others in the future), exploitation (making optimal decisions given the information discovered by other agents), and incentives of the agents (who are myopically interested in exploitation, while preferring the others to explore). We posit a principal who controls the flow of information from agents that came before, and strives to coordinate the agents towards a socially optimal balance between exploration and exploitation, not using any monetary transfers. The goal is to design a recommendation policy for the principal which respects agents' incentives and minimizes a suitable notion of regret. We extend prior work in this direction to allow the agents to interact with one another in a shared environment: at each time step, multiple agents arrive to play a Bayesian game, receive recommendations, choose their actions, receive their payoffs, and then leave the game forever. The agents now face two sources of uncertainty: the actions of the other agents and the parameters of the uncertain game environment. Our main contribution is to show that the principal can achieve constant regret when the utilities are deterministic (where the constant depends on the prior distribution, but not on the time horizon), and logarithmic regret when the utilities are stochastic. As a key technical tool, we introduce the concept of explorable actions, the actions which some incentive-compatible policy can recommend with non-zero probability. We show how the principal can identify (and explore) all explorable actions, and use the revealed information to perform optimally.
Plug-in Regularized Estimation of High-Dimensional Parameters in Nonlinear Semiparametric Models
Jun 30, 2018
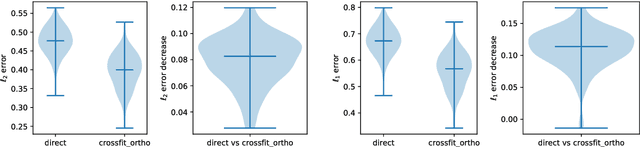
We develop a theory for estimation of a high-dimensional sparse parameter $\theta$ defined as a minimizer of a population loss function $L_D(\theta,g_0)$ which, in addition to $\theta$, depends on a, potentially infinite dimensional, nuisance parameter $g_0$. Our approach is based on estimating $\theta$ via an $\ell_1$-regularized minimization of a sample analog of $L_S(\theta, \hat{g})$, plugging in a first-stage estimate $\hat{g}$, computed on a hold-out sample. We define a population loss to be (Neyman) orthogonal if the gradient of the loss with respect to $\theta$, has pathwise derivative with respect to $g$ equal to zero, when evaluated at the true parameter and nuisance component. We show that orthogonality implies a second-order impact of the first stage nuisance error on the second stage target parameter estimate. Our approach applies to both convex and non-convex losses, albeit the latter case requires a small adaptation of our method with a preliminary estimation step of the target parameter. Our result enables oracle convergence rates for $\theta$ under assumptions on the first stage rates, typically of the order of $n^{-1/4}$. We show how such an orthogonal loss can be constructed via a novel orthogonalization process for a general model defined by conditional moment restrictions. We apply our theory to high-dimensional versions of standard estimation problems in statistics and econometrics, such as: estimation of conditional moment models with missing data, estimation of structural utilities in games of incomplete information and estimation of treatment effects in regression models with non-linear link functions.
Accurate Inference for Adaptive Linear Models
Jun 20, 2018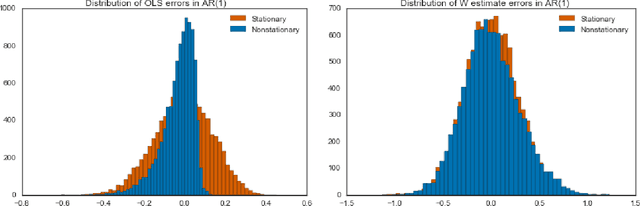
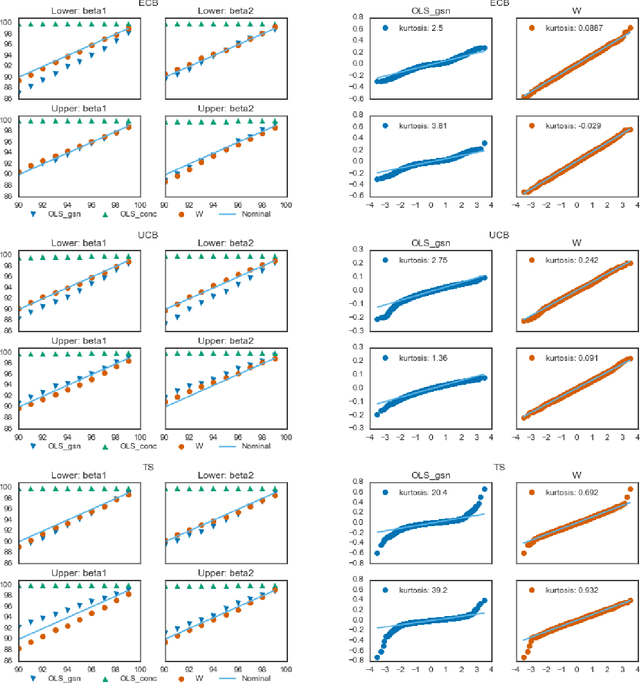
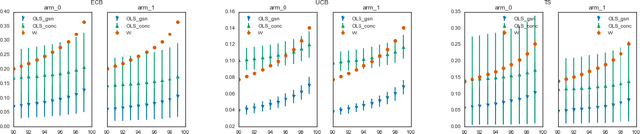
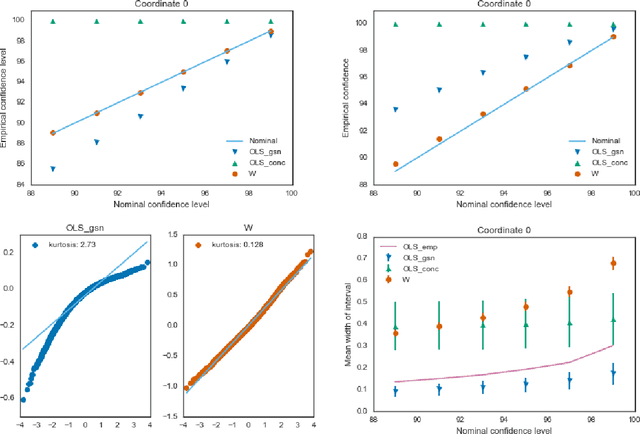
Estimators computed from adaptively collected data do not behave like their non-adaptive brethren. Rather, the sequential dependence of the collection policy can lead to severe distributional biases that persist even in the infinite data limit. We develop a general method -- $\mathbf{W}$-decorrelation -- for transforming the bias of adaptive linear regression estimators into variance. The method uses only coarse-grained information about the data collection policy and does not need access to propensity scores or exact knowledge of the policy. We bound the finite-sample bias and variance of the $\mathbf{W}$-estimator and develop asymptotically correct confidence intervals based on a novel martingale central limit theorem. We then demonstrate the empirical benefits of the generic $\mathbf{W}$-decorrelation procedure in two different adaptive data settings: the multi-armed bandit and the autoregressive time series.
Learning to Bid Without Knowing your Value
Jun 01, 2018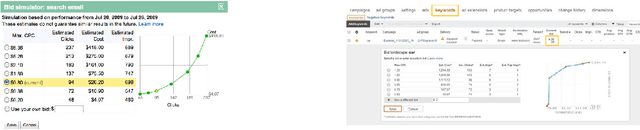
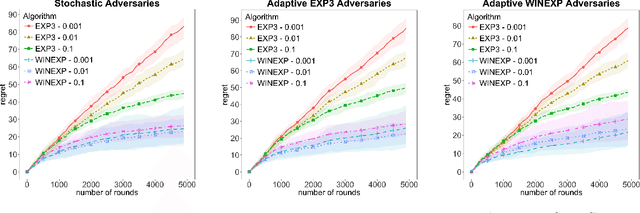
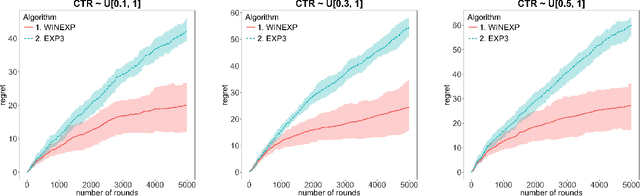
We address online learning in complex auction settings, such as sponsored search auctions, where the value of the bidder is unknown to her, evolving in an arbitrary manner and observed only if the bidder wins an allocation. We leverage the structure of the utility of the bidder and the partial feedback that bidders typically receive in auctions, in order to provide algorithms with regret rates against the best fixed bid in hindsight, that are exponentially faster in convergence in terms of dependence on the action space, than what would have been derived by applying a generic bandit algorithm and almost equivalent to what would have been achieved in the full information setting. Our results are enabled by analyzing a new online learning setting with outcome-based feedback, which generalizes learning with feedback graphs. We provide an online learning algorithm for this setting, of independent interest, with regret that grows only logarithmically with the number of actions and linearly only in the number of potential outcomes (the latter being very small in most auction settings). Last but not least, we show that our algorithm outperforms the bandit approach experimentally and that this performance is robust to dropping some of our theoretical assumptions or introducing noise in the feedback that the bidder receives.