 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLung-R1: A Knowledge Graph-Guided LLM for Pulmonary Diagnostic Reasoning
Jun 10, 2026Diagnosing pulmonary diseases requires integrating heterogeneous evidence amid phenotypic variability and cross-disease overlap. Although large language models (LLMs) have shown progress on pulmonary knowledge question answering (QA) and information-processing tasks, reliable pulmonary diagnosis requires patient-specific, relation-aware reasoning over electronic medical record (EMR) evidence rather than isolated knowledge recall. We define this gap between pulmonary knowledge and case-level diagnostic reasoning as the Pulmonary Knowledge-to-Diagnosis Gap. To address it, we introduce LungKG, the first structured pulmonary knowledge graph for diagnostic knowledge organization and record-grounded reasoning. LungKG contains 59,038 nodes and 164,308 edges across 15 entity types and 112 relation types, serving as both a reusable pulmonary knowledge resource and the foundation for LungKG-guided model adaptation. Built on LungKG, we propose Lung-R1, a LungKG-guided pulmonary LLM trained through KG-constrained reasoning-chain construction and KG-guided reinforcement learning. In a 20-system evaluation, Lung-R1-14B achieves state-of-the-art performance across Choice, Pulmonary-QA, and EMR Diagnosis, reaching an EMR Diagnosis score of 4.3583 and surpassing the strongest non-Lung-R1 baseline by 0.1476 points. These results demonstrate the value of LungKG-guided training for EMR-based pulmonary diagnosis.
ReasonTabQA: A Comprehensive Benchmark for Table Question Answering from Real World Industrial Scenarios
Jan 12, 2026Recent advancements in Large Language Models (LLMs) have significantly catalyzed table-based question answering (TableQA). However, existing TableQA benchmarks often overlook the intricacies of industrial scenarios, which are characterized by multi-table structures, nested headers, and massive scales. These environments demand robust table reasoning through deep structured inference, presenting a significant challenge that remains inadequately addressed by current methodologies. To bridge this gap, we present ReasonTabQA, a large-scale bilingual benchmark encompassing 1,932 tables across 30 industry domains such as energy and automotive. ReasonTabQA provides high-quality annotations for both final answers and explicit reasoning chains, supporting both thinking and no-thinking paradigms. Furthermore, we introduce TabCodeRL, a reinforcement learning method that leverages table-aware verifiable rewards to guide the generation of logical reasoning paths. Extensive experiments on ReasonTabQA and 4 TableQA datasets demonstrate that while TabCodeRL yields substantial performance gains on open-source LLMs, the persistent performance gap on ReasonTabQA underscores the inherent complexity of real-world industrial TableQA.
Training GANs with Optimism
Feb 13, 2018

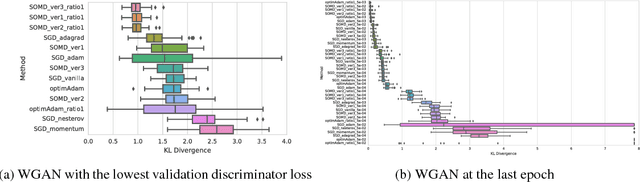
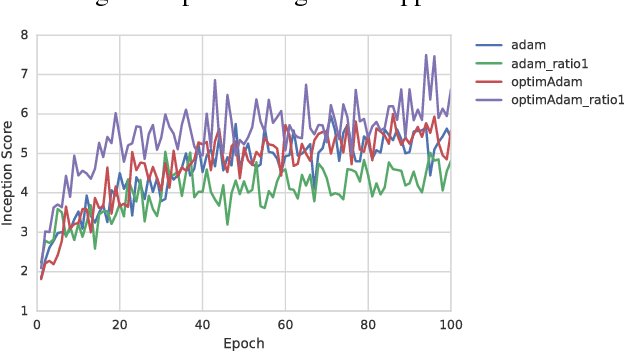
We address the issue of limit cycling behavior in training Generative Adversarial Networks and propose the use of Optimistic Mirror Decent (OMD) for training Wasserstein GANs. Recent theoretical results have shown that optimistic mirror decent (OMD) can enjoy faster regret rates in the context of zero-sum games. WGANs is exactly a context of solving a zero-sum game with simultaneous no-regret dynamics. Moreover, we show that optimistic mirror decent addresses the limit cycling problem in training WGANs. We formally show that in the case of bi-linear zero-sum games the last iterate of OMD dynamics converges to an equilibrium, in contrast to GD dynamics which are bound to cycle. We also portray the huge qualitative difference between GD and OMD dynamics with toy examples, even when GD is modified with many adaptations proposed in the recent literature, such as gradient penalty or momentum. We apply OMD WGAN training to a bioinformatics problem of generating DNA sequences. We observe that models trained with OMD achieve consistently smaller KL divergence with respect to the true underlying distribution, than models trained with GD variants. Finally, we introduce a new algorithm, Optimistic Adam, which is an optimistic variant of Adam. We apply it to WGAN training on CIFAR10 and observe improved performance in terms of inception score as compared to Adam.