 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Instrumental Variable Regression and $L_2$ Convergence Guarantees without Identification or Closedness
Feb 10, 2023
In this paper, we study nonparametric estimation of instrumental variable (IV) regressions. Recently, many flexible machine learning methods have been developed for instrumental variable estimation. However, these methods have at least one of the following limitations: (1) restricting the IV regression to be uniquely identified; (2) only obtaining estimation error rates in terms of pseudometrics (\emph{e.g.,} projected norm) rather than valid metrics (\emph{e.g.,} $L_2$ norm); or (3) imposing the so-called closedness condition that requires a certain conditional expectation operator to be sufficiently smooth. In this paper, we present the first method and analysis that can avoid all three limitations, while still permitting general function approximation. Specifically, we propose a new penalized minimax estimator that can converge to a fixed IV solution even when there are multiple solutions, and we derive a strong $L_2$ error rate for our estimator under lax conditions. Notably, this guarantee only needs a widely-used source condition and realizability assumptions, but not the so-called closedness condition. We argue that the source condition and the closedness condition are inherently conflicting, so relaxing the latter significantly improves upon the existing literature that requires both conditions. Our estimator can achieve this improvement because it builds on a novel formulation of the IV estimation problem as a constrained optimization problem.
Empirical Analysis of Model Selection for Heterogenous Causal Effect Estimation
Nov 03, 2022



We study the problem of model selection in causal inference, specifically for the case of conditional average treatment effect (CATE) estimation under binary treatments. Unlike model selection in machine learning, we cannot use the technique of cross-validation here as we do not observe the counterfactual potential outcome for any data point. Hence, we need to design model selection techniques that do not explicitly rely on counterfactual data. As an alternative to cross-validation, there have been a variety of proxy metrics proposed in the literature, that depend on auxiliary nuisance models also estimated from the data (propensity score model, outcome regression model). However, the effectiveness of these metrics has only been studied on synthetic datasets as we can observe the counterfactual data for them. We conduct an extensive empirical analysis to judge the performance of these metrics, where we utilize the latest advances in generative modeling to incorporate multiple realistic datasets. We evaluate 9 metrics on 144 datasets for selecting between 415 estimators per dataset, including datasets that closely mimic real-world datasets. Further, we use the latest techniques from AutoML to ensure consistent hyperparameter selection for nuisance models for a fair comparison across metrics.
Partial Identification of Treatment Effects with Implicit Generative Models
Oct 14, 2022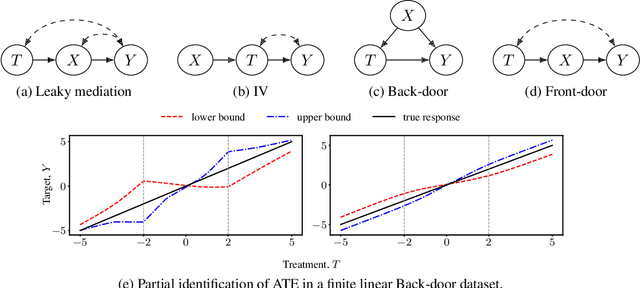

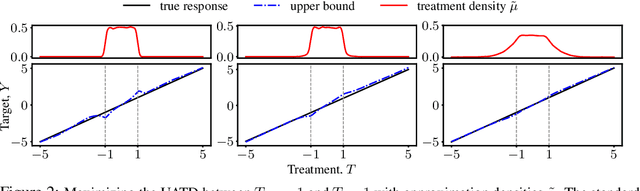
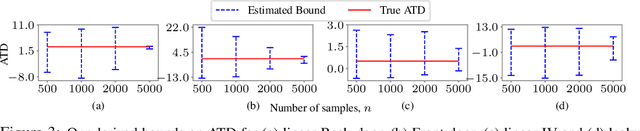
We consider the problem of partial identification, the estimation of bounds on the treatment effects from observational data. Although studied using discrete treatment variables or in specific causal graphs (e.g., instrumental variables), partial identification has been recently explored using tools from deep generative modeling. We propose a new method for partial identification of average treatment effects(ATEs) in general causal graphs using implicit generative models comprising continuous and discrete random variables. Since ATE with continuous treatment is generally non-regular, we leverage the partial derivatives of response functions to define a regular approximation of ATE, a quantity we call uniform average treatment derivative (UATD). We prove that our algorithm converges to tight bounds on ATE in linear structural causal models (SCMs). For nonlinear SCMs, we empirically show that using UATD leads to tighter and more stable bounds than methods that directly optimize the ATE.
Debiased Machine Learning without Sample-Splitting for Stable Estimators
Jun 03, 2022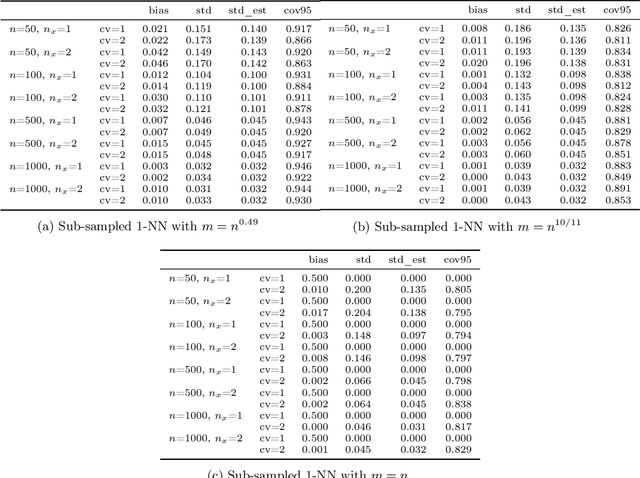
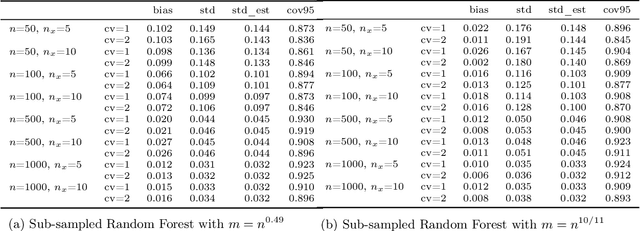
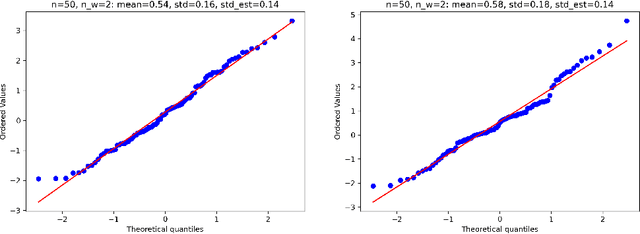
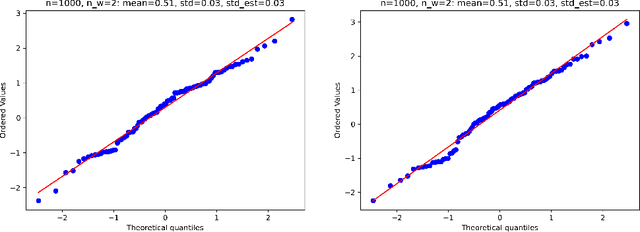
Estimation and inference on causal parameters is typically reduced to a generalized method of moments problem, which involves auxiliary functions that correspond to solutions to a regression or classification problem. Recent line of work on debiased machine learning shows how one can use generic machine learning estimators for these auxiliary problems, while maintaining asymptotic normality and root-$n$ consistency of the target parameter of interest, while only requiring mean-squared-error guarantees from the auxiliary estimation algorithms. The literature typically requires that these auxiliary problems are fitted on a separate sample or in a cross-fitting manner. We show that when these auxiliary estimation algorithms satisfy natural leave-one-out stability properties, then sample splitting is not required. This allows for sample re-use, which can be beneficial in moderately sized sample regimes. For instance, we show that the stability properties that we propose are satisfied for ensemble bagged estimators, built via sub-sampling without replacement, a popular technique in machine learning practice.
Towards efficient representation identification in supervised learning
Apr 10, 2022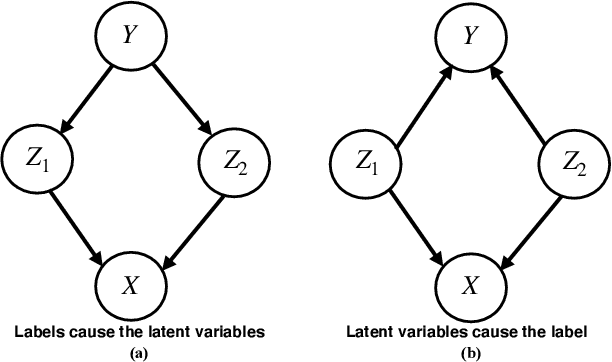
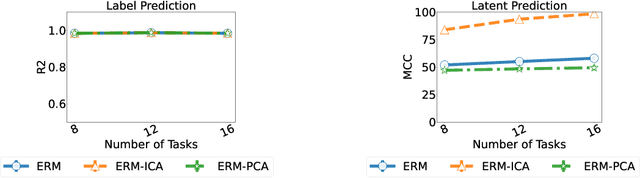
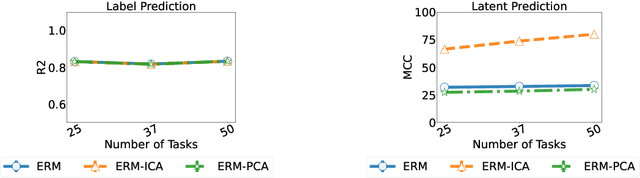
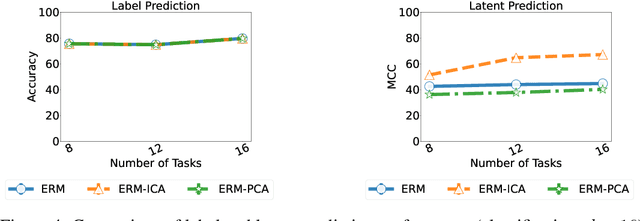
Humans have a remarkable ability to disentangle complex sensory inputs (e.g., image, text) into simple factors of variation (e.g., shape, color) without much supervision. This ability has inspired many works that attempt to solve the following question: how do we invert the data generation process to extract those factors with minimal or no supervision? Several works in the literature on non-linear independent component analysis have established this negative result; without some knowledge of the data generation process or appropriate inductive biases, it is impossible to perform this inversion. In recent years, a lot of progress has been made on disentanglement under structural assumptions, e.g., when we have access to auxiliary information that makes the factors of variation conditionally independent. However, existing work requires a lot of auxiliary information, e.g., in supervised classification, it prescribes that the number of label classes should be at least equal to the total dimension of all factors of variation. In this work, we depart from these assumptions and ask: a) How can we get disentanglement when the auxiliary information does not provide conditional independence over the factors of variation? b) Can we reduce the amount of auxiliary information required for disentanglement? For a class of models where auxiliary information does not ensure conditional independence, we show theoretically and experimentally that disentanglement (to a large extent) is possible even when the auxiliary information dimension is much less than the dimension of the true latent representation.
Automatic Debiased Machine Learning for Dynamic Treatment Effects
Apr 09, 2022

We extend the idea of automated debiased machine learning to the dynamic treatment regime. We show that the multiply robust formula for the dynamic treatment regime with discrete treatments can be re-stated in terms of a recursive Riesz representer characterization of nested mean regressions. We then apply a recursive Riesz representer estimation learning algorithm that estimates de-biasing corrections without the need to characterize how the correction terms look like, such as for instance, products of inverse probability weighting terms, as is done in prior work on doubly robust estimation in the dynamic regime. Our approach defines a sequence of loss minimization problems, whose minimizers are the mulitpliers of the de-biasing correction, hence circumventing the need for solving auxiliary propensity models and directly optimizing for the mean squared error of the target de-biasing correction.
Omitted Variable Bias in Machine Learned Causal Models
Dec 29, 2021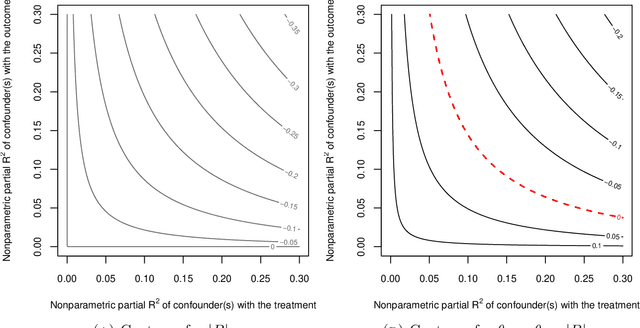
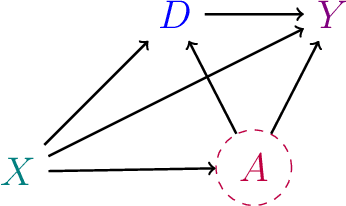
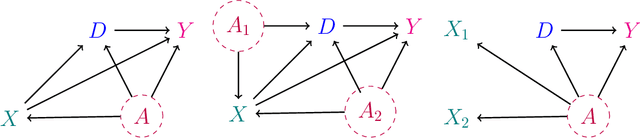
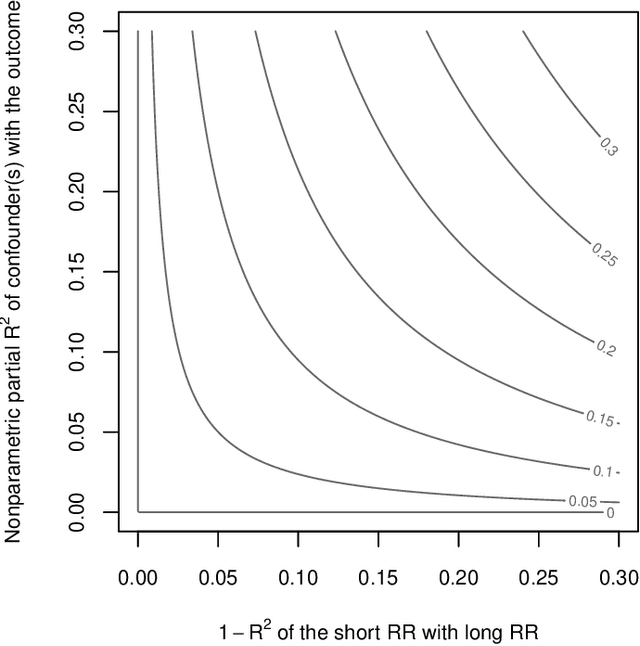
We derive general, yet simple, sharp bounds on the size of the omitted variable bias for a broad class of causal parameters that can be identified as linear functionals of the conditional expectation function of the outcome. Such functionals encompass many of the traditional targets of investigation in causal inference studies, such as, for example, (weighted) average of potential outcomes, average treatment effects (including subgroup effects, such as the effect on the treated), (weighted) average derivatives, and policy effects from shifts in covariate distribution -- all for general, nonparametric causal models. Our construction relies on the Riesz-Frechet representation of the target functional. Specifically, we show how the bound on the bias depends only on the additional variation that the latent variables create both in the outcome and in the Riesz representer for the parameter of interest. Moreover, in many important cases (e.g, average treatment effects in partially linear models, or in nonseparable models with a binary treatment) the bound is shown to depend on two easily interpretable quantities: the nonparametric partial $R^2$ (Pearson's "correlation ratio") of the unobserved variables with the treatment and with the outcome. Therefore, simple plausibility judgments on the maximum explanatory power of omitted variables (in explaining treatment and outcome variation) are sufficient to place overall bounds on the size of the bias. Finally, leveraging debiased machine learning, we provide flexible and efficient statistical inference methods to estimate the components of the bounds that are identifiable from the observed distribution.
Robust Generalized Method of Moments: A Finite Sample Viewpoint
Oct 13, 2021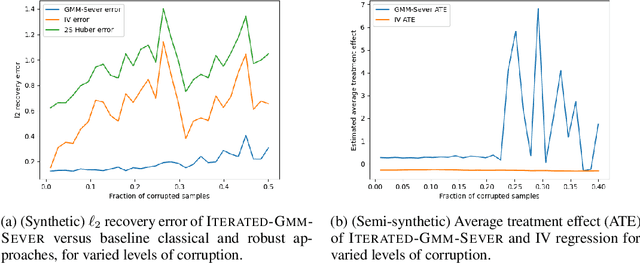
For many inference problems in statistics and econometrics, the unknown parameter is identified by a set of moment conditions. A generic method of solving moment conditions is the Generalized Method of Moments (GMM). However, classical GMM estimation is potentially very sensitive to outliers. Robustified GMM estimators have been developed in the past, but suffer from several drawbacks: computational intractability, poor dimension-dependence, and no quantitative recovery guarantees in the presence of a constant fraction of outliers. In this work, we develop the first computationally efficient GMM estimator (under intuitive assumptions) that can tolerate a constant $\epsilon$ fraction of adversarially corrupted samples, and that has an $\ell_2$ recovery guarantee of $O(\sqrt{\epsilon})$. To achieve this, we draw upon and extend a recent line of work on algorithmic robust statistics for related but simpler problems such as mean estimation, linear regression and stochastic optimization. As two examples of the generality of our algorithm, we show how our estimation algorithm and assumptions apply to instrumental variables linear and logistic regression. Moreover, we experimentally validate that our estimator outperforms classical IV regression and two-stage Huber regression on synthetic and semi-synthetic datasets with corruption.
RieszNet and ForestRiesz: Automatic Debiased Machine Learning with Neural Nets and Random Forests
Oct 12, 2021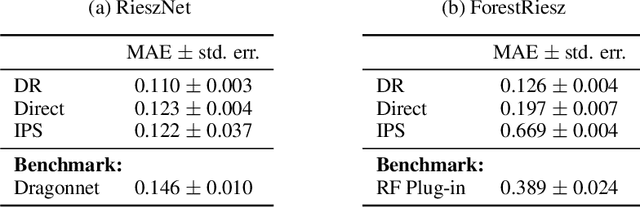
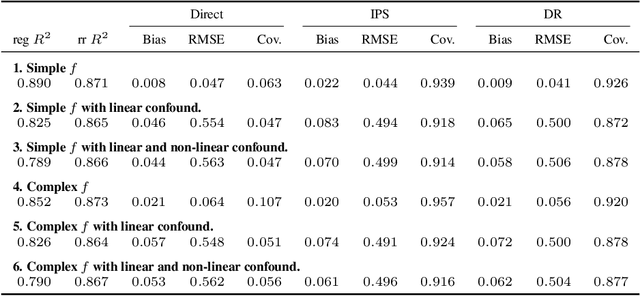
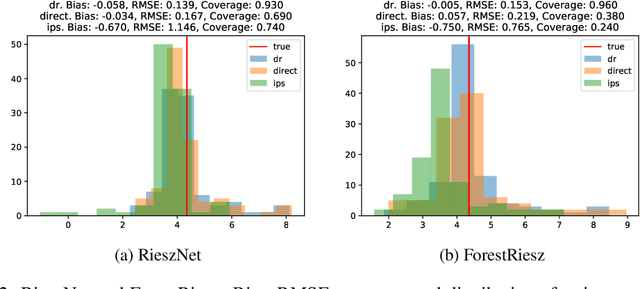
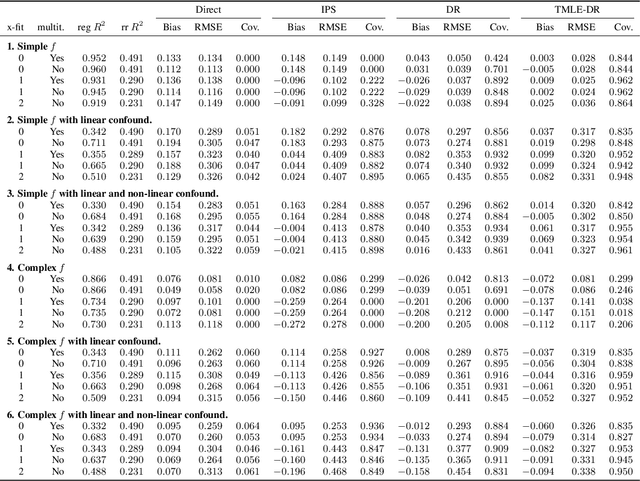
Many causal and policy effects of interest are defined by linear functionals of high-dimensional or non-parametric regression functions. $\sqrt{n}$-consistent and asymptotically normal estimation of the object of interest requires debiasing to reduce the effects of regularization and/or model selection on the object of interest. Debiasing is typically achieved by adding a correction term to the plug-in estimator of the functional, that is derived based on a functional-specific theoretical derivation of what is known as the influence function and which leads to properties such as double robustness and Neyman orthogonality. We instead implement an automatic debiasing procedure based on automatically learning the Riesz representation of the linear functional using Neural Nets and Random Forests. Our method solely requires value query oracle access to the linear functional. We propose a multi-tasking Neural Net debiasing method with stochastic gradient descent minimization of a combined Riesz representer and regression loss, while sharing representation layers for the two functions. We also propose a Random Forest method which learns a locally linear representation of the Riesz function. Even though our methodology applies to arbitrary functionals, we experimentally find that it beats state of the art performance of the prior neural net based estimator of Shi et al. (2019) for the case of the average treatment effect functional. We also evaluate our method on the more challenging problem of estimating average marginal effects with continuous treatments, using semi-synthetic data of gasoline price changes on gasoline demand.
DoWhy: Addressing Challenges in Expressing and Validating Causal Assumptions
Aug 27, 2021
Estimation of causal effects involves crucial assumptions about the data-generating process, such as directionality of effect, presence of instrumental variables or mediators, and whether all relevant confounders are observed. Violation of any of these assumptions leads to significant error in the effect estimate. However, unlike cross-validation for predictive models, there is no global validator method for a causal estimate. As a result, expressing different causal assumptions formally and validating them (to the extent possible) becomes critical for any analysis. We present DoWhy, a framework that allows explicit declaration of assumptions through a causal graph and provides multiple validation tests to check a subset of these assumptions. Our experience with DoWhy highlights a number of open questions for future research: developing new ways beyond causal graphs to express assumptions, the role of causal discovery in learning relevant parts of the graph, and developing validation tests that can better detect errors, both for average and conditional treatment effects. DoWhy is available at https://github.com/microsoft/dowhy.