 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of Being Smoothly Calibrated
Mar 16, 2026Recent work has highlighted the centrality of smooth calibration [Kakade and Foster, 2008] as a robust measure of calibration error. We generalize, unify, and extend previous results on smooth calibration, both as a robust calibration measure, and as a step towards omniprediction, which enables predictions with low regret for downstream decision makers seeking to optimize some proper loss unknown to the predictor. We present a new omniprediction guarantee for smoothly calibrated predictors, for the class of all bounded proper losses. We smooth the predictor by adding some noise to it, and compete against smoothed versions of any benchmark predictor on the space, where we add some noise to the predictor and then post-process it arbitrarily. The omniprediction error is bounded by the smooth calibration error of the predictor and the earth mover's distance from the benchmark. We exhibit instances showing that this dependence cannot, in general, be improved. We show how this unifies and extends prior results [Foster and Vohra, 1998; Hartline, Wu, and Yang, 2025] on omniprediction from smooth calibration. We present a crisp new characterization of smooth calibration in terms of the earth mover's distance to the closest perfectly calibrated joint distribution of predictions and labels. This also yields a simpler proof of the relation to the lower distance to calibration from [Blasiok, Gopalan, Hu, and Nakkiran, 2023]. We use this to show that the upper distance to calibration cannot be estimated within a quadratic factor with sample complexity independent of the support size of the predictions. This is in contrast to the distance to calibration, where the corresponding problem was known to be information-theoretically impossible: no finite number of samples suffice [Blasiok, Gopalan, Hu, and Nakkiran, 2023].
Sandwiching Polynomials for Geometric Concepts with Low Intrinsic Dimension
Feb 27, 2026Recent work has shown the surprising power of low-degree sandwiching polynomial approximators in the context of challenging learning settings such as learning with distribution shift, testable learning, and learning with contamination. A pair of sandwiching polynomials approximate a target function in expectation while also providing pointwise upper and lower bounds on the function's values. In this paper, we give a new method for constructing low-degree sandwiching polynomials that yield greatly improved degree bounds for several fundamental function classes and marginal distributions. In particular, we obtain degree $\mathrm{poly}(k)$ sandwiching polynomials for functions of $k$ halfspaces under the Gaussian distribution, improving exponentially over the prior $2^{O(k)}$ bound. More broadly, our approach applies to function classes that are low-dimensional and have smooth boundary. In contrast to prior work, our proof is relatively simple and directly uses the smoothness of the target function's boundary to construct sandwiching Lipschitz functions, which are amenable to results from high-dimensional approximation theory. For low-dimensional polynomial threshold functions (PTFs) with respect to Gaussians, we obtain doubly exponential improvements without applying the FT-mollification method of Kane used in the best previous result.
Efficient Calibration for Decision Making
Nov 17, 2025A decision-theoretic characterization of perfect calibration is that an agent seeking to minimize a proper loss in expectation cannot improve their outcome by post-processing a perfectly calibrated predictor. Hu and Wu (FOCS'24) use this to define an approximate calibration measure called calibration decision loss ($\mathsf{CDL}$), which measures the maximal improvement achievable by any post-processing over any proper loss. Unfortunately, $\mathsf{CDL}$ turns out to be intractable to even weakly approximate in the offline setting, given black-box access to the predictions and labels. We suggest circumventing this by restricting attention to structured families of post-processing functions $K$. We define the calibration decision loss relative to $K$, denoted $\mathsf{CDL}_K$ where we consider all proper losses but restrict post-processings to a structured family $K$. We develop a comprehensive theory of when $\mathsf{CDL}_K$ is information-theoretically and computationally tractable, and use it to prove both upper and lower bounds for natural classes $K$. In addition to introducing new definitions and algorithmic techniques to the theory of calibration for decision making, our results give rigorous guarantees for some widely used recalibration procedures in machine learning.
A Fully Polynomial-Time Algorithm for Robustly Learning Halfspaces over the Hypercube
Nov 10, 2025We give the first fully polynomial-time algorithm for learning halfspaces with respect to the uniform distribution on the hypercube in the presence of contamination, where an adversary may corrupt some fraction of examples and labels arbitrarily. We achieve an error guarantee of $η^{O(1)}+ε$ where $η$ is the noise rate. Such a result was not known even in the agnostic setting, where only labels can be adversarially corrupted. All prior work over the last two decades has a superpolynomial dependence in $1/ε$ or succeeds only with respect to continuous marginals (such as log-concave densities). Previous analyses rely heavily on various structural properties of continuous distributions such as anti-concentration. Our approach avoids these requirements and makes use of a new algorithm for learning Generalized Linear Models (GLMs) with only a polylogarithmic dependence on the activation function's Lipschitz constant. More generally, our framework shows that supervised learning with respect to discrete distributions is not as difficult as previously thought.
Sparse Linear Regression is Easy on Random Supports
Nov 09, 2025Sparse linear regression is one of the most basic questions in machine learning and statistics. Here, we are given as input a design matrix $X \in \mathbb{R}^{N \times d}$ and measurements or labels ${y} \in \mathbb{R}^N$ where ${y} = {X} {w}^* + ξ$, and $ξ$ is the noise in the measurements. Importantly, we have the additional constraint that the unknown signal vector ${w}^*$ is sparse: it has $k$ non-zero entries where $k$ is much smaller than the ambient dimension. Our goal is to output a prediction vector $\widehat{w}$ that has small prediction error: $\frac{1}{N}\cdot \|{X} {w}^* - {X} \widehat{w}\|^2_2$. Information-theoretically, we know what is best possible in terms of measurements: under most natural noise distributions, we can get prediction error at most $ε$ with roughly $N = O(k \log d/ε)$ samples. Computationally, this currently needs $d^{Ω(k)}$ run-time. Alternately, with $N = O(d)$, we can get polynomial-time. Thus, there is an exponential gap (in the dependence on $d$) between the two and we do not know if it is possible to get $d^{o(k)}$ run-time and $o(d)$ samples. We give the first generic positive result for worst-case design matrices ${X}$: For any ${X}$, we show that if the support of ${w}^*$ is chosen at random, we can get prediction error $ε$ with $N = \text{poly}(k, \log d, 1/ε)$ samples and run-time $\text{poly}(d,N)$. This run-time holds for any design matrix ${X}$ with condition number up to $2^{\text{poly}(d)}$. Previously, such results were known for worst-case ${w}^*$, but only for random design matrices from well-behaved families, matrices that have a very low condition number ($\text{poly}(\log d)$; e.g., as studied in compressed sensing), or those with special structural properties.
The Power of Iterative Filtering for Supervised Learning with (Heavy) Contamination
May 26, 2025



Inspired by recent work on learning with distribution shift, we give a general outlier removal algorithm called iterative polynomial filtering and show a number of striking applications for supervised learning with contamination: (1) We show that any function class that can be approximated by low-degree polynomials with respect to a hypercontractive distribution can be efficiently learned under bounded contamination (also known as nasty noise). This is a surprising resolution to a longstanding gap between the complexity of agnostic learning and learning with contamination, as it was widely believed that low-degree approximators only implied tolerance to label noise. (2) For any function class that admits the (stronger) notion of sandwiching approximators, we obtain near-optimal learning guarantees even with respect to heavy additive contamination, where far more than $1/2$ of the training set may be added adversarially. Prior related work held only for regression and in a list-decodable setting. (3) We obtain the first efficient algorithms for tolerant testable learning of functions of halfspaces with respect to any fixed log-concave distribution. Even the non-tolerant case for a single halfspace in this setting had remained open. These results significantly advance our understanding of efficient supervised learning under contamination, a setting that has been much less studied than its unsupervised counterpart.
Learning Neural Networks with Distribution Shift: Efficiently Certifiable Guarantees
Feb 22, 2025We give the first provably efficient algorithms for learning neural networks with distribution shift. We work in the Testable Learning with Distribution Shift framework (TDS learning) of Klivans et al. (2024), where the learner receives labeled examples from a training distribution and unlabeled examples from a test distribution and must either output a hypothesis with low test error or reject if distribution shift is detected. No assumptions are made on the test distribution. All prior work in TDS learning focuses on classification, while here we must handle the setting of nonconvex regression. Our results apply to real-valued networks with arbitrary Lipschitz activations and work whenever the training distribution has strictly sub-exponential tails. For training distributions that are bounded and hypercontractive, we give a fully polynomial-time algorithm for TDS learning one hidden-layer networks with sigmoid activations. We achieve this by importing classical kernel methods into the TDS framework using data-dependent feature maps and a type of kernel matrix that couples samples from both train and test distributions.
Testing Noise Assumptions of Learning Algorithms
Jan 15, 2025


We pose a fundamental question in computational learning theory: can we efficiently test whether a training set satisfies the assumptions of a given noise model? This question has remained unaddressed despite decades of research on learning in the presence of noise. In this work, we show that this task is tractable and present the first efficient algorithm to test various noise assumptions on the training data. To model this question, we extend the recently proposed testable learning framework of Rubinfeld and Vasilyan (2023) and require a learner to run an associated test that satisfies the following two conditions: (1) whenever the test accepts, the learner outputs a classifier along with a certificate of optimality, and (2) the test must pass for any dataset drawn according to a specified modeling assumption on both the marginal distribution and the noise model. We then consider the problem of learning halfspaces over Gaussian marginals with Massart noise (where each label can be flipped with probability less than $1/2$ depending on the input features), and give a fully-polynomial time testable learning algorithm. We also show a separation between the classical setting of learning in the presence of structured noise and testable learning. In fact, for the simple case of random classification noise (where each label is flipped with fixed probability $\eta = 1/2$), we show that testable learning requires super-polynomial time while classical learning is trivial.
Learning Constant-Depth Circuits in Malicious Noise Models
Nov 06, 2024
The seminal work of Linial, Mansour, and Nisan gave a quasipolynomial-time algorithm for learning constant-depth circuits ($\mathsf{AC}^0$) with respect to the uniform distribution on the hypercube. Extending their algorithm to the setting of malicious noise, where both covariates and labels can be adversarially corrupted, has remained open. Here we achieve such a result, inspired by recent work on learning with distribution shift. Our running time essentially matches their algorithm, which is known to be optimal assuming various cryptographic primitives. Our proof uses a simple outlier-removal method combined with Braverman's theorem for fooling constant-depth circuits. We attain the best possible dependence on the noise rate and succeed in the harshest possible noise model (i.e., contamination or so-called "nasty noise").
Smoothed Analysis for Learning Concepts with Low Intrinsic Dimension
Jul 01, 2024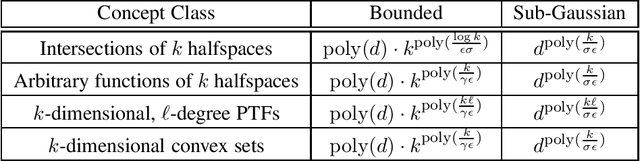
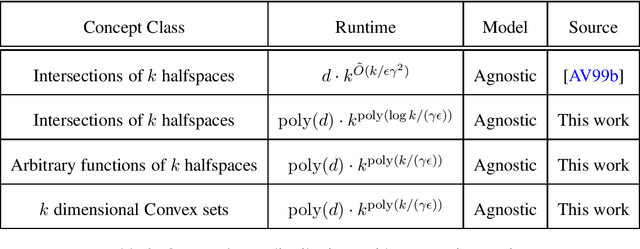

In traditional models of supervised learning, the goal of a learner -- given examples from an arbitrary joint distribution on $\mathbb{R}^d \times \{\pm 1\}$ -- is to output a hypothesis that is competitive (to within $\epsilon$) of the best fitting concept from some class. In order to escape strong hardness results for learning even simple concept classes, we introduce a smoothed-analysis framework that requires a learner to compete only with the best classifier that is robust to small random Gaussian perturbation. This subtle change allows us to give a wide array of learning results for any concept that (1) depends on a low-dimensional subspace (aka multi-index model) and (2) has a bounded Gaussian surface area. This class includes functions of halfspaces and (low-dimensional) convex sets, cases that are only known to be learnable in non-smoothed settings with respect to highly structured distributions such as Gaussians. Surprisingly, our analysis also yields new results for traditional non-smoothed frameworks such as learning with margin. In particular, we obtain the first algorithm for agnostically learning intersections of $k$-halfspaces in time $k^{poly(\frac{\log k}{\epsilon \gamma}) }$ where $\gamma$ is the margin parameter. Before our work, the best-known runtime was exponential in $k$ (Arriaga and Vempala, 1999).