 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Class-aware Optimal Transport Approach with Higher-Order Moment Matching for Unsupervised Domain Adaptation
Jan 29, 2024Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. In this paper, we introduce a novel approach called class-aware optimal transport (OT), which measures the OT distance between a distribution over the source class-conditional distributions and a mixture of source and target data distribution. Our class-aware OT leverages a cost function that determines the matching extent between a given data example and a source class-conditional distribution. By optimizing this cost function, we find the optimal matching between target examples and source class-conditional distributions, effectively addressing the data and label shifts that occur between the two domains. To handle the class-aware OT efficiently, we propose an amortization solution that employs deep neural networks to formulate the transportation probabilities and the cost function. Additionally, we propose minimizing class-aware Higher-order Moment Matching (HMM) to align the corresponding class regions on the source and target domains. The class-aware HMM component offers an economical computational approach for accurately evaluating the HMM distance between the two distributions. Extensive experiments on benchmark datasets demonstrate that our proposed method significantly outperforms existing state-of-the-art baselines.
Learning to Quantize Vulnerability Patterns and Match to Locate Statement-Level Vulnerabilities
May 26, 2023



Deep learning (DL) models have become increasingly popular in identifying software vulnerabilities. Prior studies found that vulnerabilities across different vulnerable programs may exhibit similar vulnerable scopes, implicitly forming discernible vulnerability patterns that can be learned by DL models through supervised training. However, vulnerable scopes still manifest in various spatial locations and formats within a program, posing challenges for models to accurately identify vulnerable statements. Despite this challenge, state-of-the-art vulnerability detection approaches fail to exploit the vulnerability patterns that arise in vulnerable programs. To take full advantage of vulnerability patterns and unleash the ability of DL models, we propose a novel vulnerability-matching approach in this paper, drawing inspiration from program analysis tools that locate vulnerabilities based on pre-defined patterns. Specifically, a vulnerability codebook is learned, which consists of quantized vectors representing various vulnerability patterns. During inference, the codebook is iterated to match all learned patterns and predict the presence of potential vulnerabilities within a given program. Our approach was extensively evaluated on a real-world dataset comprising more than 188,000 C/C++ functions. The evaluation results show that our approach achieves an F1-score of 94% (6% higher than the previous best) and 82% (19% higher than the previous best) for function and statement-level vulnerability identification, respectively. These substantial enhancements highlight the effectiveness of our approach to identifying vulnerabilities. The training code and pre-trained models are available at https://github.com/optimatch/optimatch.
Toward the Automated Construction of Probabilistic Knowledge Graphs for the Maritime Domain
May 04, 2023



International maritime crime is becoming increasingly sophisticated, often associated with wider criminal networks. Detecting maritime threats by means of fusing data purely related to physical movement (i.e., those generated by physical sensors, or hard data) is not sufficient. This has led to research and development efforts aimed at combining hard data with other types of data (especially human-generated or soft data). Existing work often assumes that input soft data is available in a structured format, or is focused on extracting certain relevant entities or concepts to accompany or annotate hard data. Much less attention has been given to extracting the rich knowledge about the situations of interest implicitly embedded in the large amount of soft data existing in unstructured formats (such as intelligence reports and news articles). In order to exploit the potentially useful and rich information from such sources, it is necessary to extract not only the relevant entities and concepts but also their semantic relations, together with the uncertainty associated with the extracted knowledge (i.e., in the form of probabilistic knowledge graphs). This will increase the accuracy of and confidence in, the extracted knowledge and facilitate subsequent reasoning and learning. To this end, we propose Maritime DeepDive, an initial prototype for the automated construction of probabilistic knowledge graphs from natural language data for the maritime domain. In this paper, we report on the current implementation of Maritime DeepDive, together with preliminary results on extracting probabilistic events from maritime piracy incidents. This pipeline was evaluated on a manually crafted gold standard, yielding promising results.
Few-shot Domain-Adaptive Visually-fused Event Detection from Text
May 04, 2023



Incorporating auxiliary modalities such as images into event detection models has attracted increasing interest over the last few years. The complexity of natural language in describing situations has motivated researchers to leverage the related visual context to improve event detection performance. However, current approaches in this area suffer from data scarcity, where a large amount of labelled text-image pairs are required for model training. Furthermore, limited access to the visual context at inference time negatively impacts the performance of such models, which makes them practically ineffective in real-world scenarios. In this paper, we present a novel domain-adaptive visually-fused event detection approach that can be trained on a few labelled image-text paired data points. Specifically, we introduce a visual imaginator method that synthesises images from text in the absence of visual context. Moreover, the imaginator can be customised to a specific domain. In doing so, our model can leverage the capabilities of pre-trained vision-language models and can be trained in a few-shot setting. This also allows for effective inference where only single-modality data (i.e. text) is available. The experimental evaluation on the benchmark M2E2 dataset shows that our model outperforms existing state-of-the-art models, by up to 11 points.
Self-supervised Activity Representation Learning with Incremental Data: An Empirical Study
May 01, 2023



In the context of mobile sensing environments, various sensors on mobile devices continually generate a vast amount of data. Analyzing this ever-increasing data presents several challenges, including limited access to annotated data and a constantly changing environment. Recent advancements in self-supervised learning have been utilized as a pre-training step to enhance the performance of conventional supervised models to address the absence of labelled datasets. This research examines the impact of using a self-supervised representation learning model for time series classification tasks in which data is incrementally available. We proposed and evaluated a workflow in which a model learns to extract informative features using a corpus of unlabeled time series data and then conducts classification on labelled data using features extracted by the model. We analyzed the effect of varying the size, distribution, and source of the unlabeled data on the final classification performance across four public datasets, including various types of sensors in diverse applications.
Application of Knowledge Distillation to Multi-task Speech Representation Learning
Oct 29, 2022Model architectures such as wav2vec 2.0 and HuBERT have been proposed to learn speech representations from audio waveforms in a self-supervised manner. When these models are combined with downstream tasks such as speech recognition, they have been shown to provide state-of-the-art performance. However, these models use a large number of parameters, the smallest version of which has about 95 million parameters. This constitutes a challenge for edge AI device deployments. In this paper, we use knowledge distillation to reduce the original model size by about 75% while maintaining similar performance levels. Moreover, we use wav2vec 2.0 and HuBERT models for distillation and present a comprehensive performance analysis through our experiments where we fine-tune the distilled models on single task and multi-task frameworks separately. In particular, our experiments show that fine-tuning the distilled models on keyword spotting and speaker verification tasks result in only 0.1% accuracy and 0.9% equal error rate degradations, respectively.
Learning to Counter: Stochastic Feature-based Learning for Diverse Counterfactual Explanations
Sep 27, 2022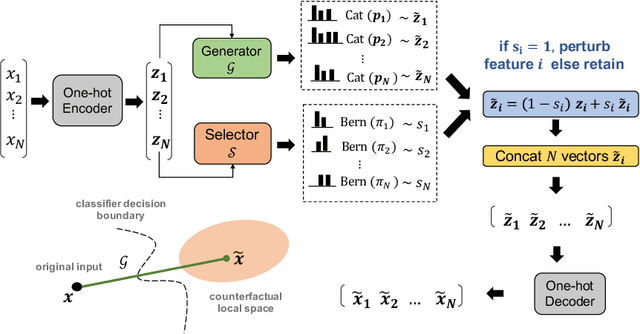

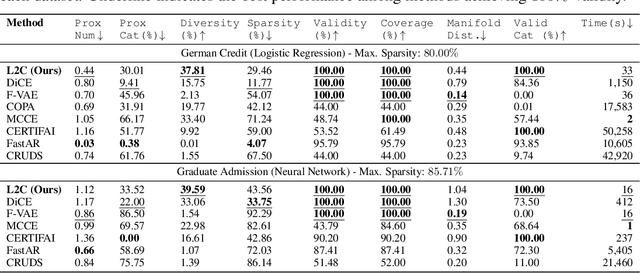
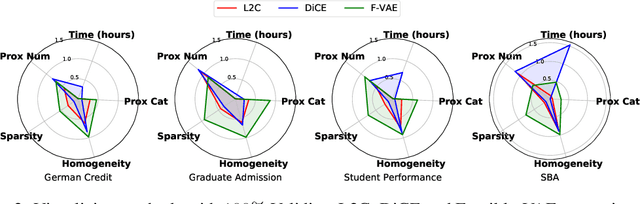
Interpretable machine learning seeks to understand the reasoning process of complex black-box systems that are long notorious for lack of explainability. One growing interpreting approach is through counterfactual explanations, which go beyond why a system arrives at a certain decision to further provide suggestions on what a user can do to alter the outcome. A counterfactual example must be able to counter the original prediction from the black-box classifier, while also satisfying various constraints for practical applications. These constraints exist at trade-offs between one and another presenting radical challenges to existing works. To this end, we propose a stochastic learning-based framework that effectively balances the counterfactual trade-offs. The framework consists of a generation and a feature selection module with complementary roles: the former aims to model the distribution of valid counterfactuals whereas the latter serves to enforce additional constraints in a way that allows for differentiable training and amortized optimization. We demonstrate the effectiveness of our method in generating actionable and plausible counterfactuals that are more diverse than the existing methods and particularly in a more efficient manner than counterparts of the same capacity.
An Information-Theoretic and Contrastive Learning-based Approach for Identifying Code Statements Causing Software Vulnerability
Sep 20, 2022
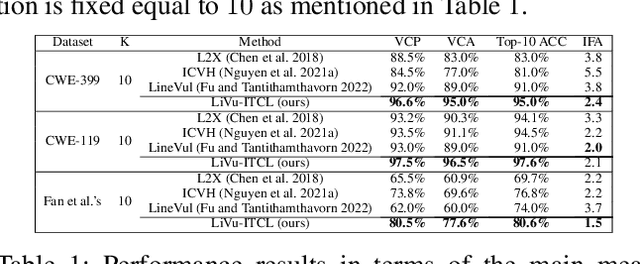
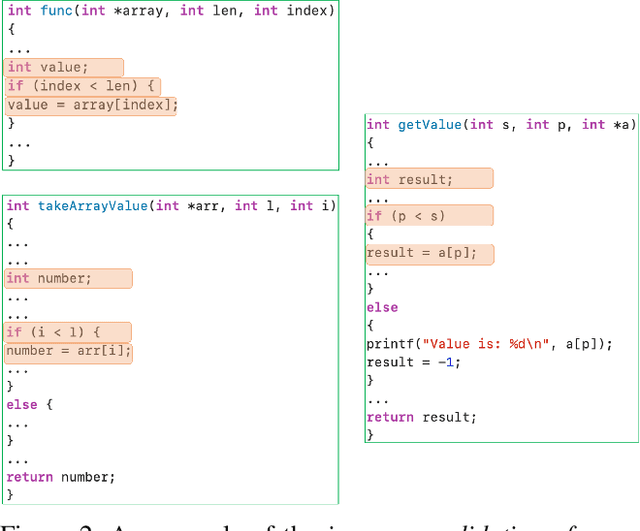
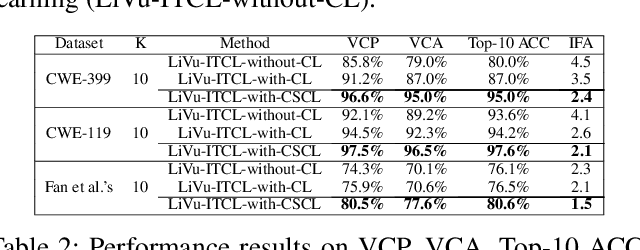
Software vulnerabilities existing in a program or function of computer systems are a serious and crucial concern. Typically, in a program or function consisting of hundreds or thousands of source code statements, there are only few statements causing the corresponding vulnerabilities. Vulnerability labeling is currently done on a function or program level by experts with the assistance of machine learning tools. Extending this approach to the code statement level is much more costly and time-consuming and remains an open problem. In this paper we propose a novel end-to-end deep learning-based approach to identify the vulnerability-relevant code statements of a specific function. Inspired by the specific structures observed in real world vulnerable code, we first leverage mutual information for learning a set of latent variables representing the relevance of the source code statements to the corresponding function's vulnerability. We then propose novel clustered spatial contrastive learning in order to further improve the representation learning and the robust selection process of vulnerability-relevant code statements. Experimental results on real-world datasets of 200k+ C/C++ functions show the superiority of our method over other state-of-the-art baselines. In general, our method obtains a higher performance in VCP, VCA, and Top-10 ACC measures of between 3\% to 14\% over the baselines when running on real-world datasets in an unsupervised setting. Our released source code samples are publicly available at \href{https://github.com/vannguyennd/livuitcl}{https://github.com/vannguyennd/livuitcl.}
Cross Project Software Vulnerability Detection via Domain Adaptation and Max-Margin Principle
Sep 19, 2022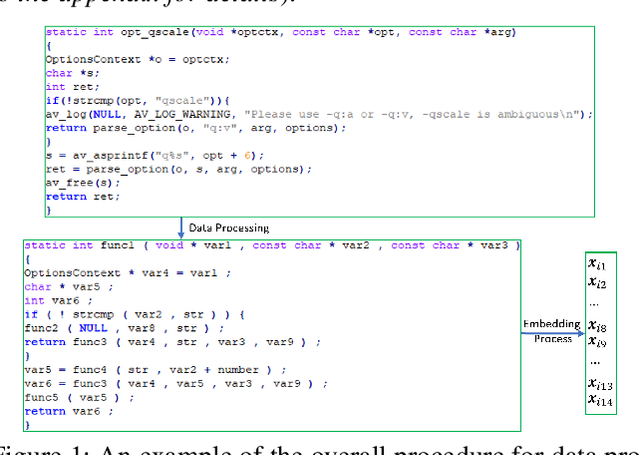
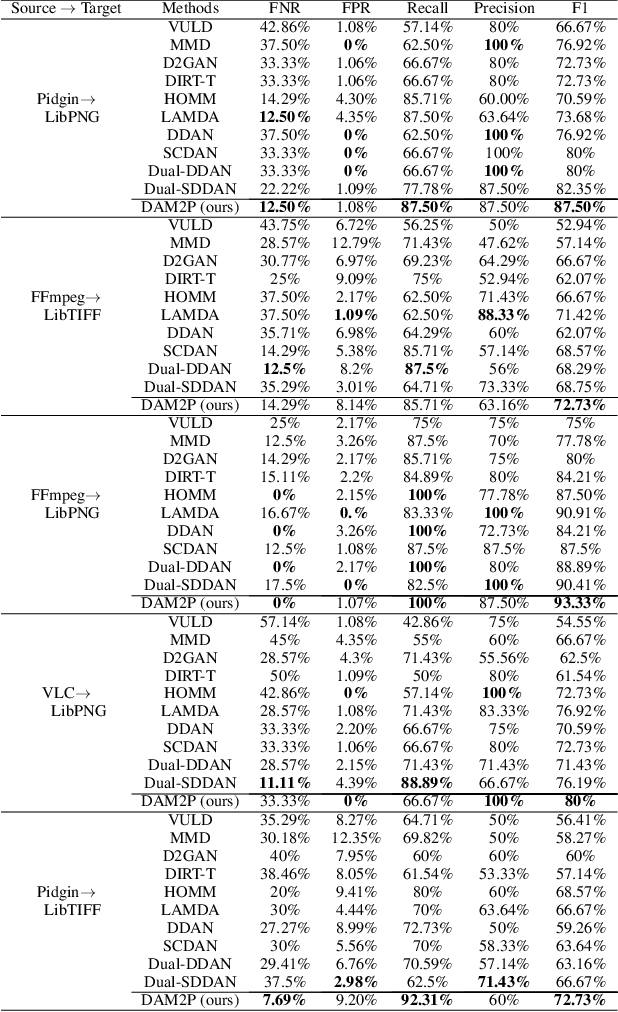
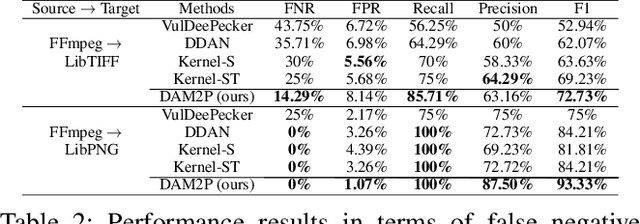
Software vulnerabilities (SVs) have become a common, serious and crucial concern due to the ubiquity of computer software. Many machine learning-based approaches have been proposed to solve the software vulnerability detection (SVD) problem. However, there are still two open and significant issues for SVD in terms of i) learning automatic representations to improve the predictive performance of SVD, and ii) tackling the scarcity of labeled vulnerabilities datasets that conventionally need laborious labeling effort by experts. In this paper, we propose a novel end-to-end approach to tackle these two crucial issues. We first exploit the automatic representation learning with deep domain adaptation for software vulnerability detection. We then propose a novel cross-domain kernel classifier leveraging the max-margin principle to significantly improve the transfer learning process of software vulnerabilities from labeled projects into unlabeled ones. The experimental results on real-world software datasets show the superiority of our proposed method over state-of-the-art baselines. In short, our method obtains a higher performance on F1-measure, the most important measure in SVD, from 1.83% to 6.25% compared to the second highest method in the used datasets. Our released source code samples are publicly available at https://github.com/vannguyennd/dam2p
An Additive Instance-Wise Approach to Multi-class Model Interpretation
Jul 07, 2022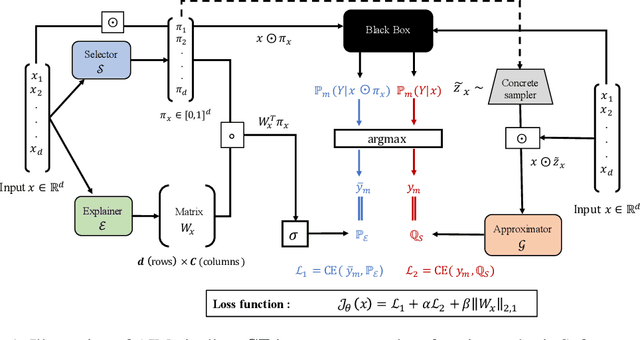
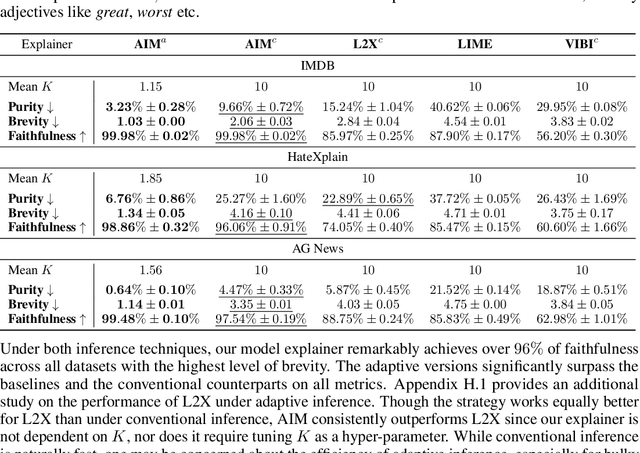

Interpretable machine learning offers insights into what factors drive a certain prediction of a black-box system and whether to trust it for high-stakes decisions or large-scale deployment. Existing methods mainly focus on selecting explanatory input features, which follow either locally additive or instance-wise approaches. Additive models use heuristically sampled perturbations to learn instance-specific explainers sequentially. The process is thus inefficient and susceptible to poorly-conditioned samples. Meanwhile, instance-wise techniques directly learn local sampling distributions and can leverage global information from other inputs. However, they can only interpret single-class predictions and suffer from inconsistency across different settings, due to a strict reliance on a pre-defined number of features selected. This work exploits the strengths of both methods and proposes a global framework for learning local explanations simultaneously for multiple target classes. We also propose an adaptive inference strategy to determine the optimal number of features for a specific instance. Our model explainer significantly outperforms additive and instance-wise counterparts on faithfulness while achieves high level of brevity on various data sets and black-box model architectures.