 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Orbit Real-Time Wildfire Detection Under On-Board Constraints
May 07, 2026We present a deployed system for on-orbit wildfire detection aboard a nine-satellite commercial thermal infrared constellation, operating under demanding joint constraints: sub-megabyte model footprint, sub-150 ms per-batch TensorRT FP16 inference on an NVIDIA Jetson Xavier NX, and an end-to-end alert pipeline targeting under 10 minutes from satellite overpass to fire event communication. The system operates on uncalibrated mid-wave infrared (MWIR) single-band imagery at 200 m ground sampling distance, where fires frequently appear as sub-pixel or single-pixel thermal anomalies under extreme class imbalance -- challenges not addressed by the contextual thermal-thresholding pipelines (MODIS, VIIRS) that currently dominate operational fire monitoring. We present an empirical study of lightweight dense representation learning for this regime using a proprietary nine-satellite MWIR dataset. We compare dense masked autoencoding (DenseMAE) and a hybrid DenseMAE+EMA (exponential moving average) distillation variant, and evaluate representations via linear probing and full-distribution pixel-level average precision (AP) under extreme class imbalance. DenseMAE pretraining enables compact downstream models on the latency-accuracy Pareto frontier: our fastest SSL-pretrained model achieves 0.640 test AP and 0.69 event-level Fire-F1 with 65.34 ms latency per batch and a 0.52 MB engine, without pruning or compression. The best configuration reaches 0.699 AP and 0.744 Fire-F1 below 1 MB, outperforming a supervised baseline (0.650 AP) under comparable constraints.
Multi-Objective Approaches to Markov Decision Processes with Uncertain Transition Parameters
Oct 20, 2017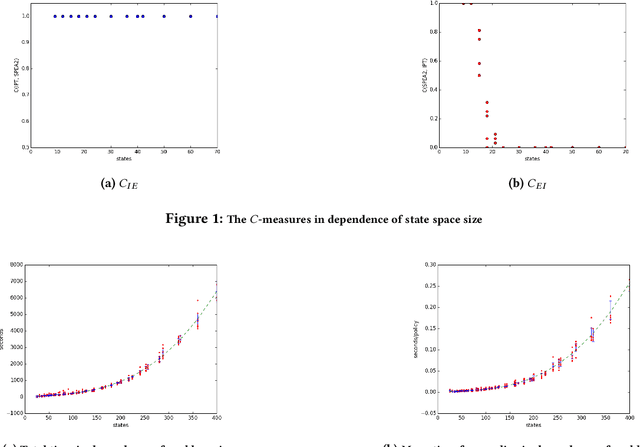
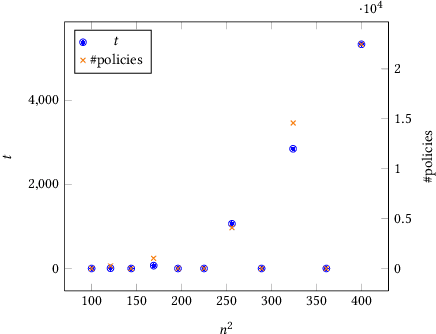
Markov decision processes (MDPs) are a popular model for performance analysis and optimization of stochastic systems. The parameters of stochastic behavior of MDPs are estimates from empirical observations of a system; their values are not known precisely. Different types of MDPs with uncertain, imprecise or bounded transition rates or probabilities and rewards exist in the literature. Commonly, analysis of models with uncertainties amounts to searching for the most robust policy which means that the goal is to generate a policy with the greatest lower bound on performance (or, symmetrically, the lowest upper bound on costs). However, hedging against an unlikely worst case may lead to losses in other situations. In general, one is interested in policies that behave well in all situations which results in a multi-objective view on decision making. In this paper, we consider policies for the expected discounted reward measure of MDPs with uncertain parameters. In particular, the approach is defined for bounded-parameter MDPs (BMDPs) [8]. In this setting the worst, best and average case performances of a policy are analyzed simultaneously, which yields a multi-scenario multi-objective optimization problem. The paper presents and evaluates approaches to compute the pure Pareto optimal policies in the value vector space.