 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Adapting Pretrained Language Models To New Languages
Nov 09, 2023



Recent large language models (LLM) exhibit sub-optimal performance on low-resource languages, as the training data of these models is usually dominated by English and other high-resource languages. Furthermore, it is challenging to train models for low-resource languages, especially from scratch, due to a lack of high quality training data. Adapting pretrained LLMs reduces the need for data in the new language while also providing cross lingual transfer capabilities. However, naively adapting to new languages leads to catastrophic forgetting and poor tokenizer efficiency. In this work, we study how to efficiently adapt any existing pretrained LLM to a new language without running into these issues. In particular, we improve the encoding efficiency of the tokenizer by adding new tokens from the target language and study the data mixing recipe to mitigate forgetting. Our experiments on adapting an English LLM to Hungarian and Thai show that our recipe can reach better performance than open source models on the target language, with minimal regressions on English.
Training Large Language Models Efficiently with Sparsity and Dataflow
Apr 11, 2023Large foundation language models have shown their versatility in being able to be adapted to perform a wide variety of downstream tasks, such as text generation, sentiment analysis, semantic search etc. However, training such large foundational models is a non-trivial exercise that requires a significant amount of compute power and expertise from machine learning and systems experts. As models get larger, these demands are only increasing. Sparsity is a promising technique to relieve the compute requirements for training. However, sparsity introduces new challenges in training the sparse model to the same quality as the dense counterparts. Furthermore, sparsity drops the operation intensity and introduces irregular memory access patterns that makes it challenging to efficiently utilize compute resources. This paper demonstrates an end-to-end training flow on a large language model - 13 billion GPT - using sparsity and dataflow. The dataflow execution model and architecture enables efficient on-chip irregular memory accesses as well as native kernel fusion and pipelined parallelism that helps recover device utilization. We show that we can successfully train GPT 13B to the same quality as the dense GPT 13B model, while achieving an end-end speedup of 4.5x over dense A100 baseline.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
Feb 02, 2022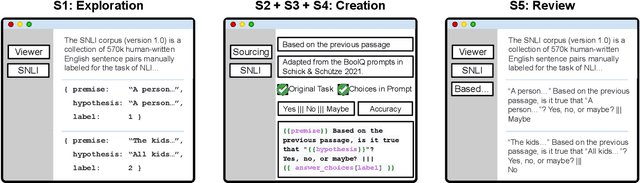
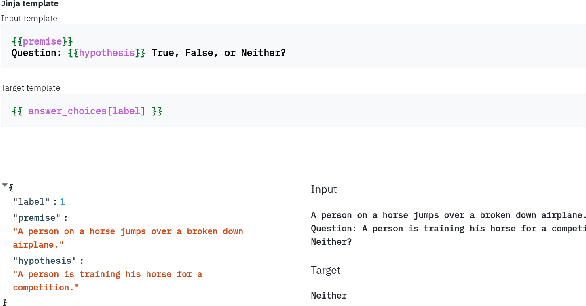

PromptSource is a system for creating, sharing, and using natural language prompts. Prompts are functions that map an example from a dataset to a natural language input and target output. Using prompts to train and query language models is an emerging area in NLP that requires new tools that let users develop and refine these prompts collaboratively. PromptSource addresses the emergent challenges in this new setting with (1) a templating language for defining data-linked prompts, (2) an interface that lets users quickly iterate on prompt development by observing outputs of their prompts on many examples, and (3) a community-driven set of guidelines for contributing new prompts to a common pool. Over 2,000 prompts for roughly 170 datasets are already available in PromptSource. PromptSource is available at https://github.com/bigscience-workshop/promptsource.
Multitask Prompted Training Enables Zero-Shot Task Generalization
Oct 15, 2021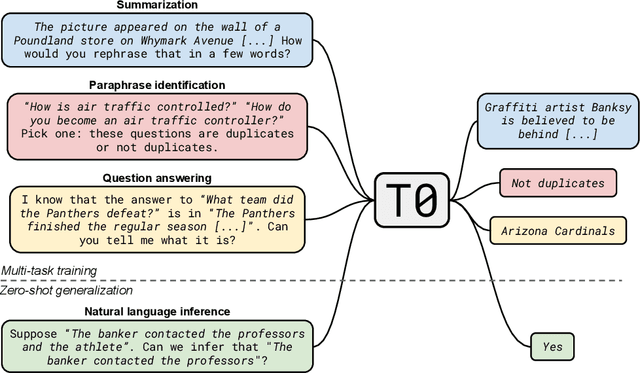

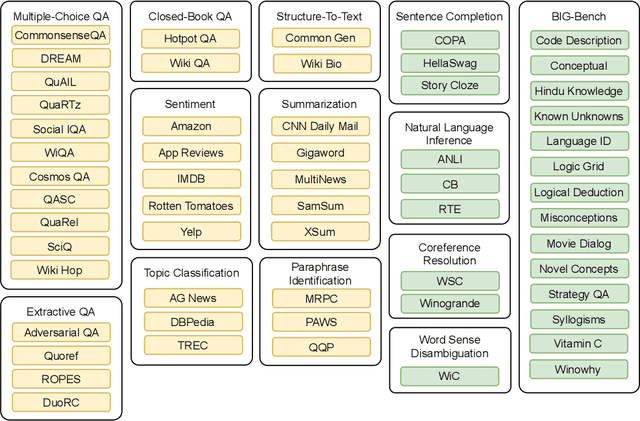

Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks. It has been hypothesized that this is a consequence of implicit multitask learning in language model training. Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping general natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts using varying natural language. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. We fine-tune a pretrained encoder-decoder model on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models 16x its size. Further, our approach attains strong performance on a subset of tasks from the BIG-Bench benchmark, outperforming models 6x its size. All prompts and trained models are available at github.com/bigscience-workshop/promptsource/.
MLPerf Tiny Benchmark
Jun 28, 2021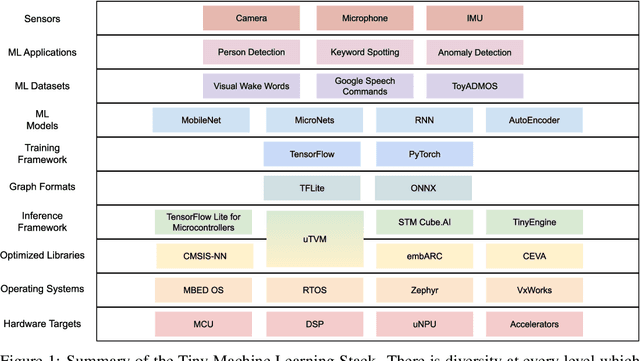
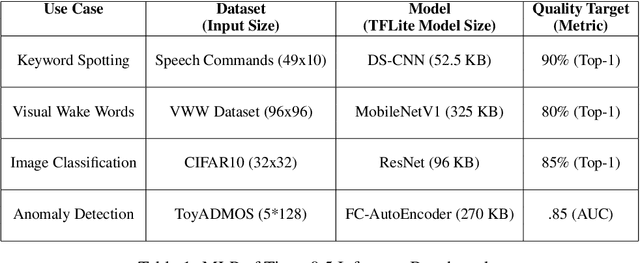
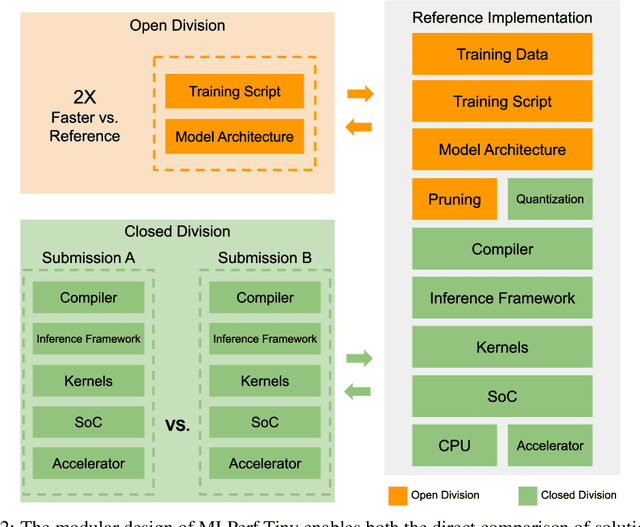
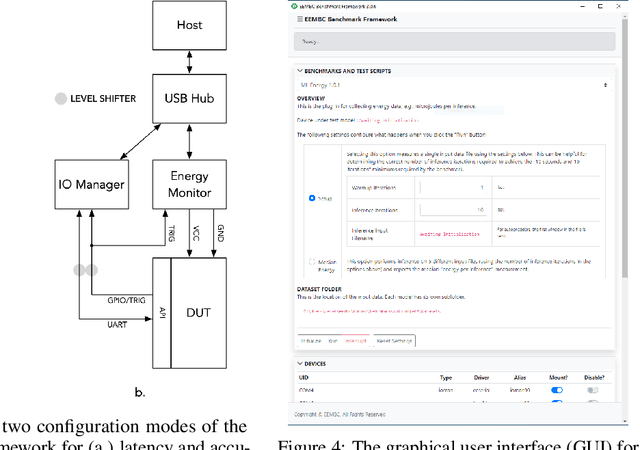
Advancements in ultra-low-power tiny machine learning (TinyML) systems promise to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted and easily reproducible benchmark for these systems. To meet this need, we present MLPerf Tiny, the first industry-standard benchmark suite for ultra-low-power tiny machine learning systems. The benchmark suite is the collaborative effort of more than 50 organizations from industry and academia and reflects the needs of the community. MLPerf Tiny measures the accuracy, latency, and energy of machine learning inference to properly evaluate the tradeoffs between systems. Additionally, MLPerf Tiny implements a modular design that enables benchmark submitters to show the benefits of their product, regardless of where it falls on the ML deployment stack, in a fair and reproducible manner. The suite features four benchmarks: keyword spotting, visual wake words, image classification, and anomaly detection.
Doping: A technique for efficient compression of LSTM models using sparse structured additive matrices
Feb 14, 2021
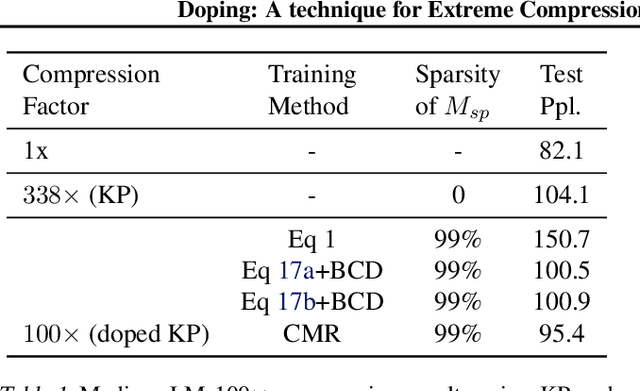
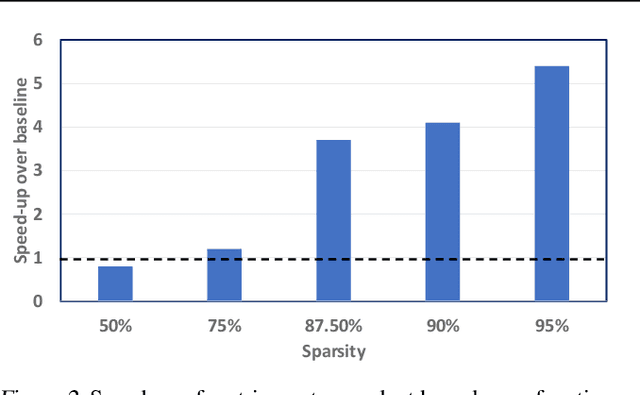

Structured matrices, such as those derived from Kronecker products (KP), are effective at compressing neural networks, but can lead to unacceptable accuracy loss when applied to large models. In this paper, we propose the notion of doping -- addition of an extremely sparse matrix to a structured matrix. Doping facilitates additional degrees of freedom for a small number of parameters, allowing them to independently diverge from the fixed structure. To train LSTMs with doped structured matrices, we introduce the additional parameter matrix while slowly annealing its sparsity level. However, we find that performance degrades as we slowly sparsify the doping matrix, due to co-matrix adaptation (CMA) between the structured and the sparse matrices. We address this over dependence on the sparse matrix using a co-matrix dropout regularization (CMR) scheme. We provide empirical evidence to show that doping, CMA and CMR are concepts generally applicable to multiple structured matrices (Kronecker Product, LMF, Hybrid Matrix Decomposition). Additionally, results with doped kronecker product matrices demonstrate state-of-the-art accuracy at large compression factors (10 - 25x) across 4 natural language processing applications with minor loss in accuracy. Doped KP compression technique outperforms previous state-of-the art compression results by achieving 1.3 - 2.4x higher compression factor at a similar accuracy, while also beating strong alternatives like pruning and low-rank methods by a large margin (8% or more). Additionally, we show that doped KP can be deployed on commodity hardware using the current software stack and achieve 2.5 - 5.5x inference run-time speed-up over baseline.
MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers
Oct 25, 2020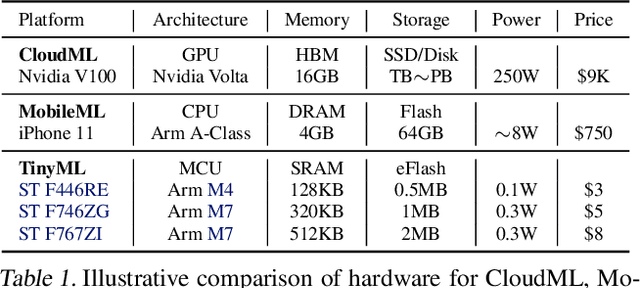
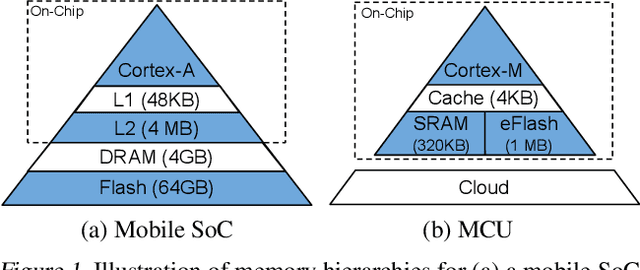
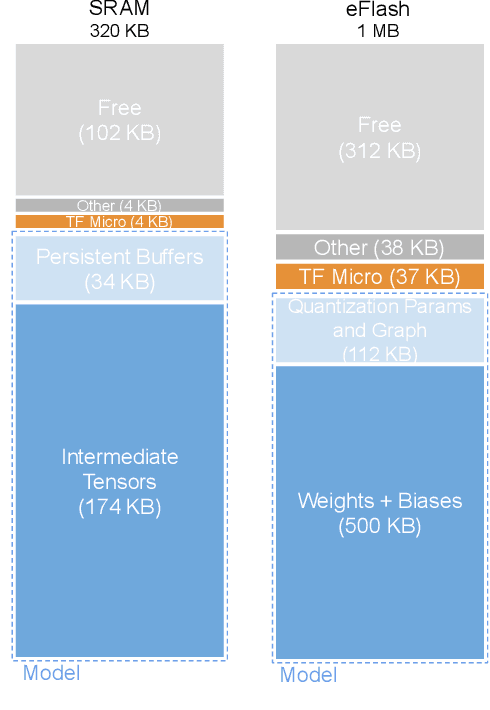
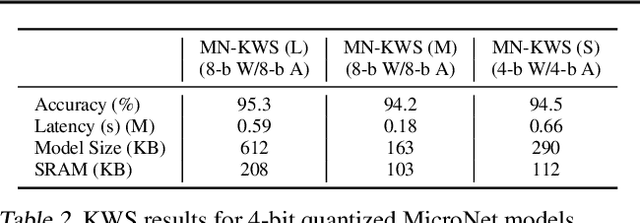
Executing machine learning workloads locally on resource constrained microcontrollers (MCUs) promises to drastically expand the application space of IoT. However, so-called TinyML presents severe technical challenges, as deep neural network inference demands a large compute and memory budget. To address this challenge, neural architecture search (NAS) promises to help design accurate ML models that meet the tight MCU memory, latency and energy constraints. A key component of NAS algorithms is their latency/energy model, i.e., the mapping from a given neural network architecture to its inference latency/energy on an MCU. In this paper, we observe an intriguing property of NAS search spaces for MCU model design: on average, model latency varies linearly with model operation (op) count under a uniform prior over models in the search space. Exploiting this insight, we employ differentiable NAS (DNAS) to search for models with low memory usage and low op count, where op count is treated as a viable proxy to latency. Experimental results validate our methodology, yielding our MicroNet models, which we deploy on MCUs using Tensorflow Lite Micro, a standard open-source NN inference runtime widely used in the TinyML community. MicroNets demonstrate state-of-the-art results for all three TinyMLperf industry-standard benchmark tasks: visual wake words, audio keyword spotting, and anomaly detection.
Rank and run-time aware compression of NLP Applications
Oct 06, 2020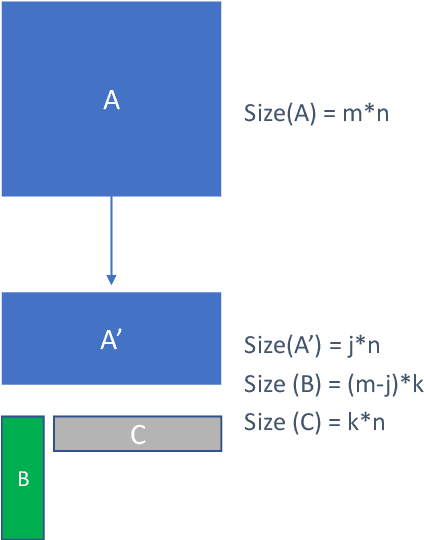
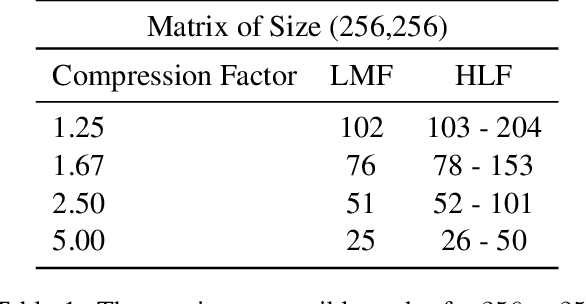
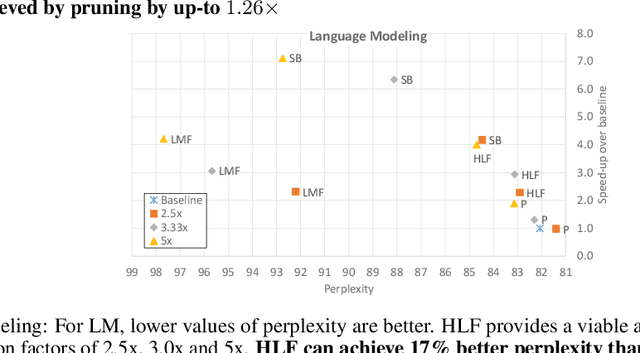
Sequence model based NLP applications can be large. Yet, many applications that benefit from them run on small devices with very limited compute and storage capabilities, while still having run-time constraints. As a result, there is a need for a compression technique that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper proposes a new compression technique called Hybrid Matrix Factorization that achieves this dual objective. HMF improves low-rank matrix factorization (LMF) techniques by doubling the rank of the matrix using an intelligent hybrid-structure leading to better accuracy than LMF. Further, by preserving dense matrices, it leads to faster inference run-time than pruning or structure matrix based compression technique. We evaluate the impact of this technique on 5 NLP benchmarks across multiple tasks (Translation, Intent Detection, Language Modeling) and show that for similar accuracy values and compression factors, HMF can achieve more than 2.32x faster inference run-time than pruning and 16.77% better accuracy than LMF.
Benchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020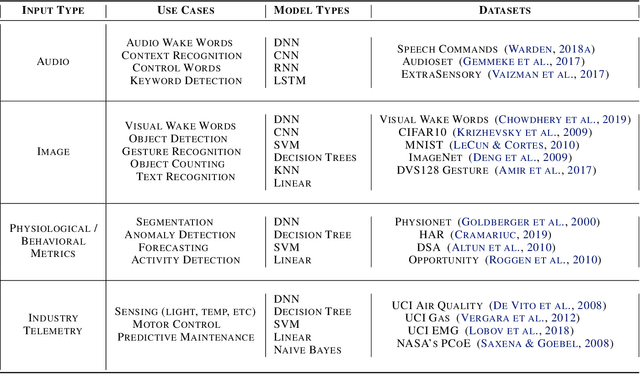
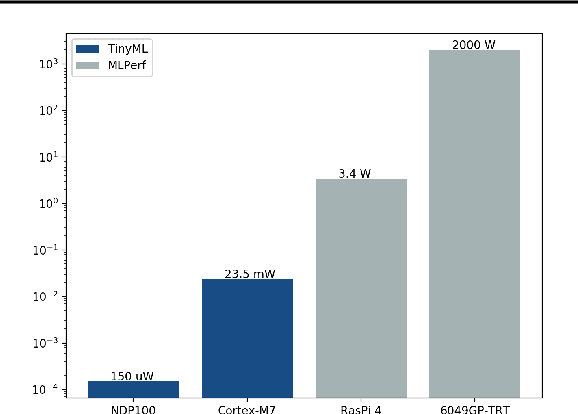
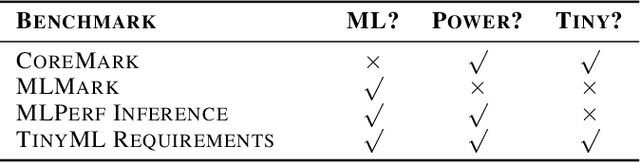
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.