 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUfuk Topcu
A 3D Printing Hexacopter: Design and Demonstration
Mar 02, 2021

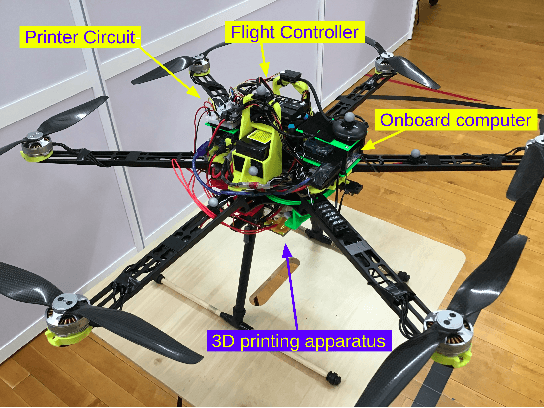


3D printing using robots has garnered significant interest in manufacturing and construction in recent years. A robot's versatility paired with the design freedom of 3D printing offers promising opportunities for how parts and structures are built in the future. However, 3D printed objects are still limited in size and location due to a lack of vertical mobility of ground robots. These limitations severely restrict the potential of the 3D printing process. To overcome these limitations, we develop a hexacopter testbed that can print via fused deposition modeling during flight. We discuss the design of this testbed and develop a simple control strategy for initial print tests. By successfully performing these initial print tests, we demonstrate the feasibility of this approach and lay the groundwork for printing 3D parts and structures with drones.
Physical-Layer Security via Distributed Beamforming in the Presence of Adversaries with Unknown Locations
Feb 28, 2021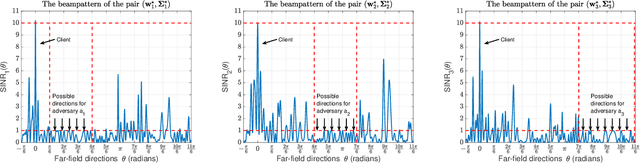
We study the problem of securely communicating a sequence of information bits with a client in the presence of multiple adversaries at unknown locations in the environment. We assume that the client and the adversaries are located in the far-field region, and all possible directions for each adversary can be expressed as a continuous interval of directions. In such a setting, we develop a periodic transmission strategy, i.e., a sequence of joint beamforming gain and artificial noise pairs, that prevents the adversaries from decreasing their uncertainty on the information sequence by eavesdropping on the transmission. We formulate a series of nonconvex semi-infinite optimization problems to synthesize the transmission strategy. We show that the semi-definite program (SDP) relaxations of these nonconvex problems are exact under an efficiently verifiable sufficient condition. We approximate the SDP relaxations, which are subject to infinitely many constraints, by randomly sampling a finite subset of the constraints and establish the probability with which optimal solutions to the obtained finite SDPs and the semi-infinite SDPs coincide. We demonstrate with numerical simulations that the proposed periodic strategy can ensure the security of communication in scenarios in which all stationary strategies fail to guarantee security.
Privacy-Preserving Teacher-Student Deep Reinforcement Learning
Feb 18, 2021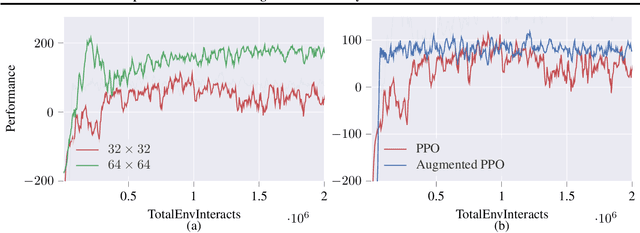
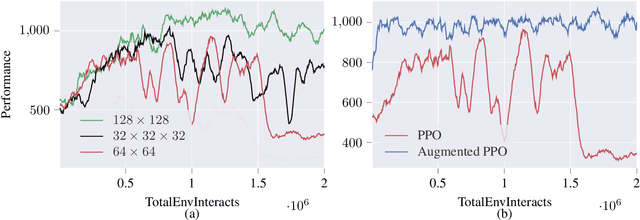
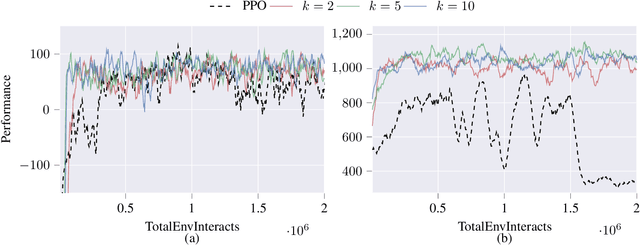
Deep reinforcement learning agents may learn complex tasks more efficiently when they coordinate with one another. We consider a teacher-student coordination scheme wherein an agent may ask another agent for demonstrations. Despite the benefits of sharing demonstrations, however, potential adversaries may obtain sensitive information belonging to the teacher by observing the demonstrations. In particular, deep reinforcement learning algorithms are known to be vulnerable to membership attacks, which make accurate inferences about the membership of the entries of training datasets. Therefore, there is a need to safeguard the teacher against such privacy threats. We fix the teacher's policy as the context of the demonstrations, which allows for different internal models across the student and the teacher, and contrasts the existing methods. We make the following two contributions. (i) We develop a differentially private mechanism that protects the privacy of the teacher's training dataset. (ii) We propose a proximal policy-optimization objective that enables the student to benefit from the demonstrations despite the perturbations of the privacy mechanism. We empirically show that the algorithm improves the student's learning upon convergence rate and utility. Specifically, compared with an agent who learns the same task on its own, we observe that the student's policy converges faster, and the converging policy accumulates higher rewards more robustly.
Safe Multi-Agent Reinforcement Learning via Shielding
Feb 02, 2021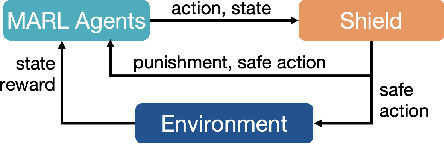


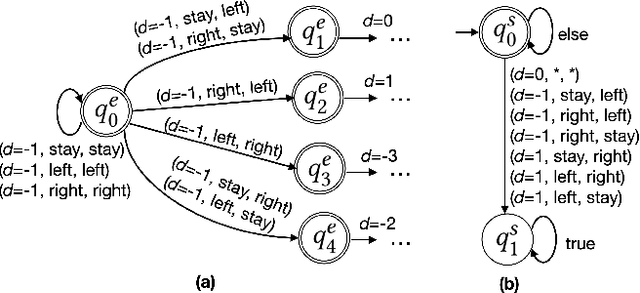
Multi-agent reinforcement learning (MARL) has been increasingly used in a wide range of safety-critical applications, which require guaranteed safety (e.g., no unsafe states are ever visited) during the learning process.Unfortunately, current MARL methods do not have safety guarantees. Therefore, we present two shielding approaches for safe MARL. In centralized shielding, we synthesize a single shield to monitor all agents' joint actions and correct any unsafe action if necessary. In factored shielding, we synthesize multiple shields based on a factorization of the joint state space observed by all agents; the set of shields monitors agents concurrently and each shield is only responsible for a subset of agents at each step.Experimental results show that both approaches can guarantee the safety of agents during learning without compromising the quality of learned policies; moreover, factored shielding is more scalable in the number of agents than centralized shielding.
Multiple Plans are Better than One: Diverse Stochastic Planning
Dec 31, 2020

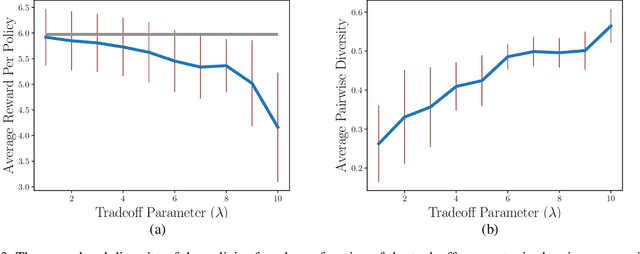
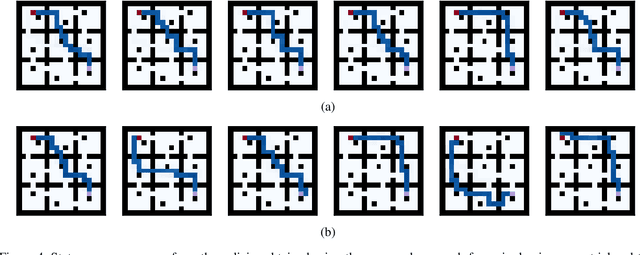
In planning problems, it is often challenging to fully model the desired specifications. In particular, in human-robot interaction, such difficulty may arise due to human's preferences that are either private or complex to model. Consequently, the resulting objective function can only partially capture the specifications and optimizing that may lead to poor performance with respect to the true specifications. Motivated by this challenge, we formulate a problem, called diverse stochastic planning, that aims to generate a set of representative -- small and diverse -- behaviors that are near-optimal with respect to the known objective. In particular, the problem aims to compute a set of diverse and near-optimal policies for systems modeled by a Markov decision process. We cast the problem as a constrained nonlinear optimization for which we propose a solution relying on the Frank-Wolfe method. We then prove that the proposed solution converges to a stationary point and demonstrate its efficacy in several planning problems.
Towards online monitoring and data-driven control: a study of segmentation algorithms for infrared images of the powder bed
Nov 18, 2020

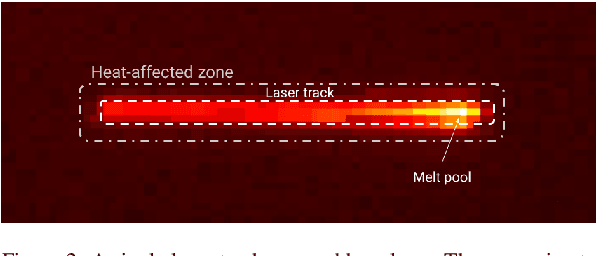

An increasing number of selective laser sintering and selective laser melting machines use off-axis infrared cameras to improve online monitoring and data-driven control capabilities. However, there is still a severe lack of algorithmic solutions to properly process the infrared images from these cameras that has led to several key limitations: a lack of online monitoring capabilities for the laser tracks, insufficient pre-processing of the infrared images for data-driven methods, and large memory requirements for storing the infrared images. To address these limitations, we study over 30 segmentation algorithms that segment each infrared image into a foreground and background. By evaluating each algorithm based on its segmentation accuracy, computational speed, and robustness against spatter detection, we identify promising algorithmic solutions. The identified algorithms can be readily applied to the selective laser sintering and selective laser melting machines to address each of the above limitations and thus, significantly improve process control.
Assured Autonomy: Path Toward Living With Autonomous Systems We Can Trust
Oct 27, 2020The challenge of establishing assurance in autonomy is rapidly attracting increasing interest in the industry, government, and academia. Autonomy is a broad and expansive capability that enables systems to behave without direct control by a human operator. To that end, it is expected to be present in a wide variety of systems and applications. A vast range of industrial sectors, including (but by no means limited to) defense, mobility, health care, manufacturing, and civilian infrastructure, are embracing the opportunities in autonomy yet face the similar barriers toward establishing the necessary level of assurance sooner or later. Numerous government agencies are poised to tackle the challenges in assured autonomy. Given the already immense interest and investment in autonomy, a series of workshops on Assured Autonomy was convened to facilitate dialogs and increase awareness among the stakeholders in the academia, industry, and government. This series of three workshops aimed to help create a unified understanding of the goals for assured autonomy, the research trends and needs, and a strategy that will facilitate sustained progress in autonomy. The first workshop, held in October 2019, focused on current and anticipated challenges and problems in assuring autonomous systems within and across applications and sectors. The second workshop held in February 2020, focused on existing capabilities, current research, and research trends that could address the challenges and problems identified in workshop. The third event was dedicated to a discussion of a draft of the major findings from the previous two workshops and the recommendations.
Minimum-Violation Planning for Autonomous Systems: Theoretical and Practical Considerations
Sep 24, 2020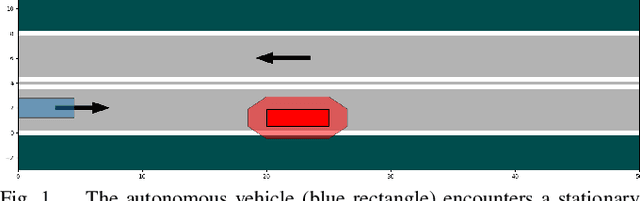
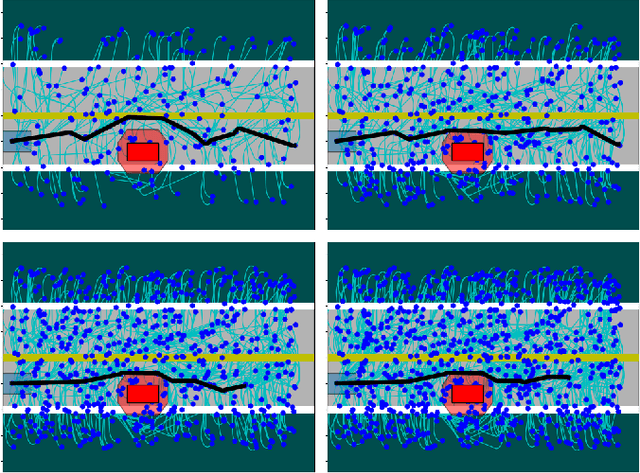
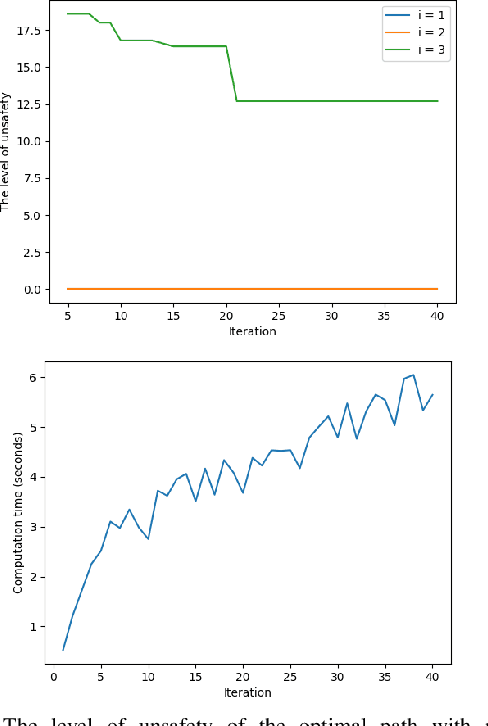
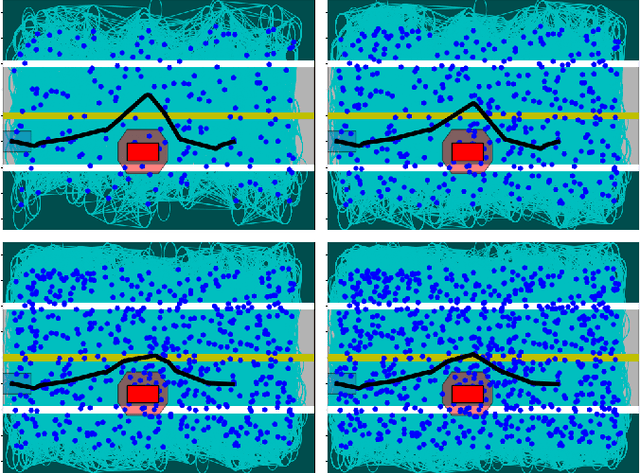
This paper considers the problem of computing an optimal trajectory for an autonomous system that is subject to a set of potentially conflicting rules. First, we introduce the concept of prioritized safety specifications, where each rule is expressed as a temporal logic formula with its associated weight and priority. The optimality is defined based on the violation of such prioritized safety specifications. We then introduce a class of temporal logic formulas called $\textrm{si-FLTL}_{\mathsf{G_X}}$ and develop an efficient, incremental sampling-based approach to solve this minimum-violation planning problem with guarantees on asymptotic optimality. We illustrate the application of the proposed approach in autonomous vehicles, showing that $\textrm{si-FLTL}_{\mathsf{G_X}}$ formulas are sufficiently expressive to describe many traffic rules. Finally, we discuss practical considerations and present simulation results for a vehicle overtaking scenario.
Robust Finite-State Controllers for Uncertain POMDPs
Sep 24, 2020
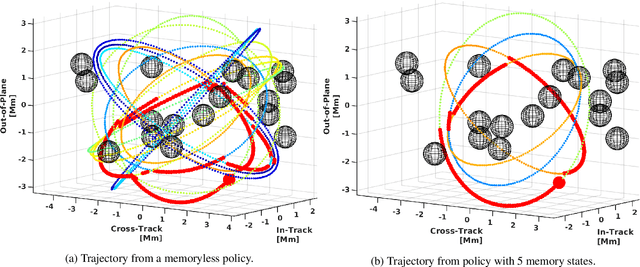
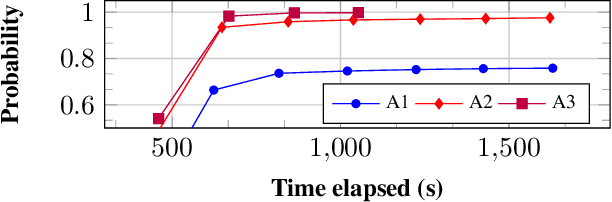
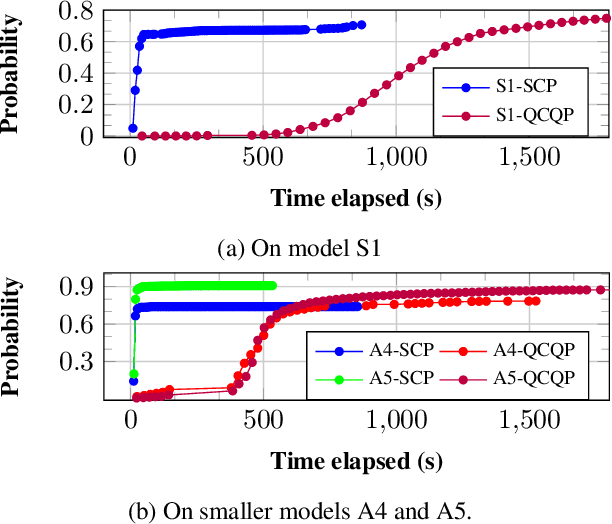
Uncertain partially observable Markov decision processes (uPOMDPs) allow the probabilistic transition and observation functions of standard POMDPs to belong to a so-called uncertainty set. Such uncertainty sets capture uncountable sets of probability distributions. We develop an algorithm to compute finite-memory policies for uPOMDPs that robustly satisfy given specifications against any admissible distribution. In general, computing such policies is both theoretically and practically intractable. We provide an efficient solution to this problem in four steps. (1) We state the underlying problem as a nonconvex optimization problem with infinitely many constraints. (2) A dedicated dualization scheme yields a dual problem that is still nonconvex but has finitely many constraints. (3) We linearize this dual problem and (4) solve the resulting finite linear program to obtain locally optimal solutions to the original problem. The resulting problem formulation is exponentially smaller than those resulting from existing methods. We demonstrate the applicability of our algorithm using large instances of an aircraft collision-avoidance scenario and a novel spacecraft motion planning case study.