 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Vision-Language-Action Model Already Has Attention Heads For Path Deviation Detection
Mar 14, 2026Vision-Language-Action (VLA) models have demonstrated strong potential for predicting semantic actions in navigation tasks, demonstrating the ability to reason over complex linguistic instructions and visual contexts. However, they are fundamentally hindered by visual-reasoning hallucinations that lead to trajectory deviations. Addressing this issue has conventionally required training external critic modules or relying on complex uncertainty heuristics. In this work, we discover that monitoring a few attention heads within a frozen VLA model can accurately detect path deviations without incurring additional computational overhead. We refer to these heads, which inherently capture the spatiotemporal causality between historical visual sequences and linguistic instructions, as Navigation Heads. Using these heads, we propose an intuitive, training-free anomaly-detection framework that monitors their signals to detect hallucinations in real time. Surprisingly, among over a thousand attention heads, a combination of just three is sufficient to achieve a 44.6 % deviation detection rate with a low false-positive rate of 11.7 %. Furthermore, upon detecting a deviation, we bypass the heavy VLA model and trigger a lightweight Reinforcement Learning (RL) policy to safely execute a shortest-path rollback. By integrating this entire detection-to-recovery pipeline onto a physical robot, we demonstrate its practical robustness. All source code will be publicly available.
Deep Interactive Reinforcement Learning for Path Following of Autonomous Underwater Vehicle
Jan 10, 2020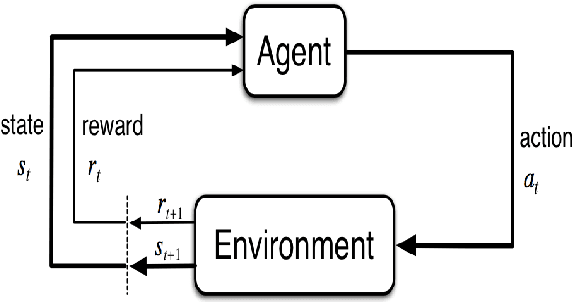
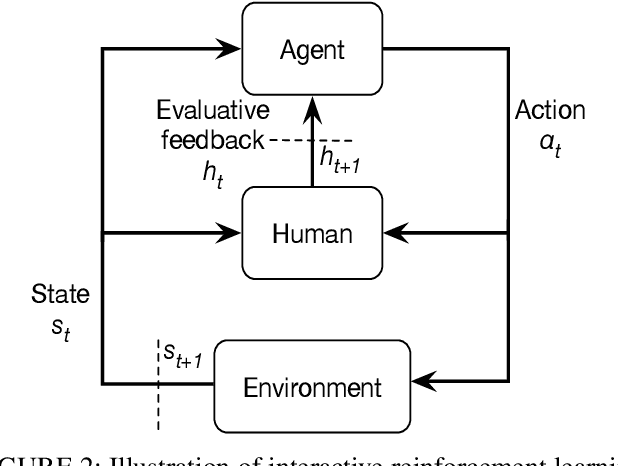
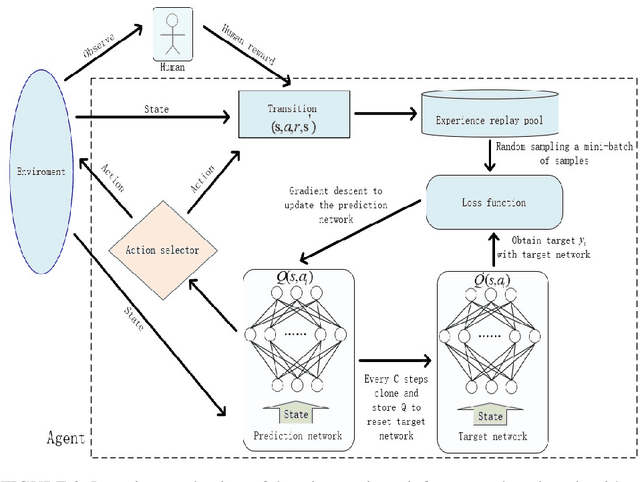
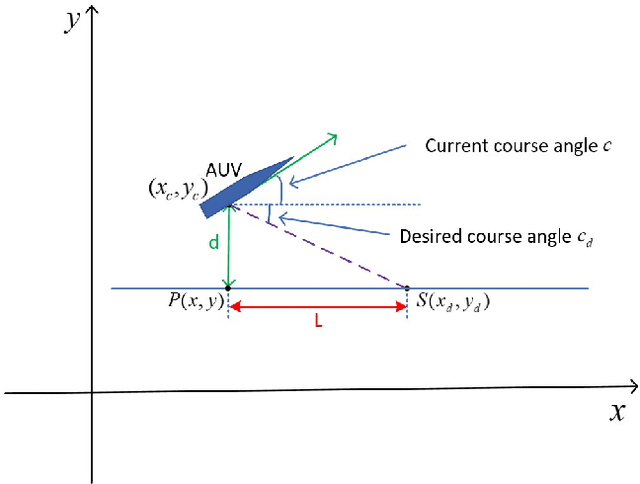
Autonomous underwater vehicle (AUV) plays an increasingly important role in ocean exploration. Existing AUVs are usually not fully autonomous and generally limited to pre-planning or pre-programming tasks. Reinforcement learning (RL) and deep reinforcement learning have been introduced into the AUV design and research to improve its autonomy. However, these methods are still difficult to apply directly to the actual AUV system because of the sparse rewards and low learning efficiency. In this paper, we proposed a deep interactive reinforcement learning method for path following of AUV by combining the advantages of deep reinforcement learning and interactive RL. In addition, since the human trainer cannot provide human rewards for AUV when it is running in the ocean and AUV needs to adapt to a changing environment, we further propose a deep reinforcement learning method that learns from both human rewards and environmental rewards at the same time. We test our methods in two path following tasks---straight line and sinusoids curve following of AUV by simulating in the Gazebo platform. Our experimental results show that with our proposed deep interactive RL method, AUV can converge faster than a DQN learner from only environmental reward. Moreover, AUV learning with our deep RL from both human and environmental rewards can also achieve a similar or even better performance than that with the deep interactive RL method and can adapt to the actual environment by further learning from environmental rewards.
Improving Interactive Reinforcement Agent Planning with Human Demonstration
Apr 18, 2019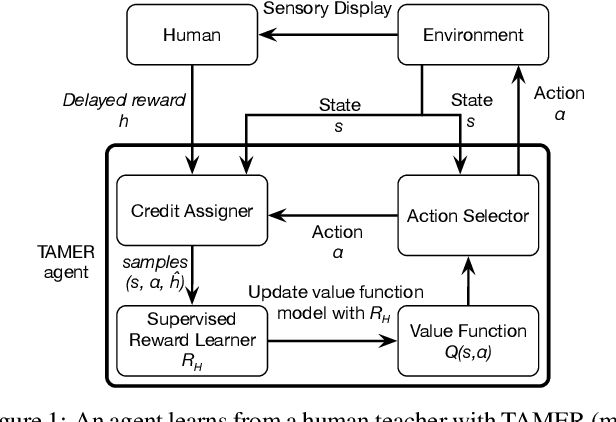
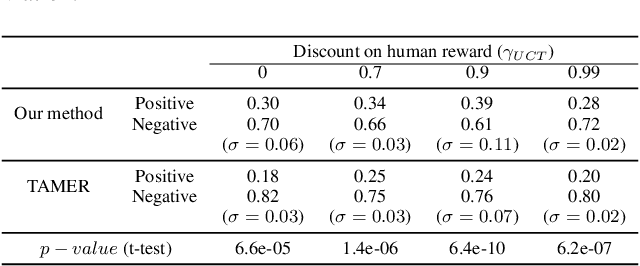

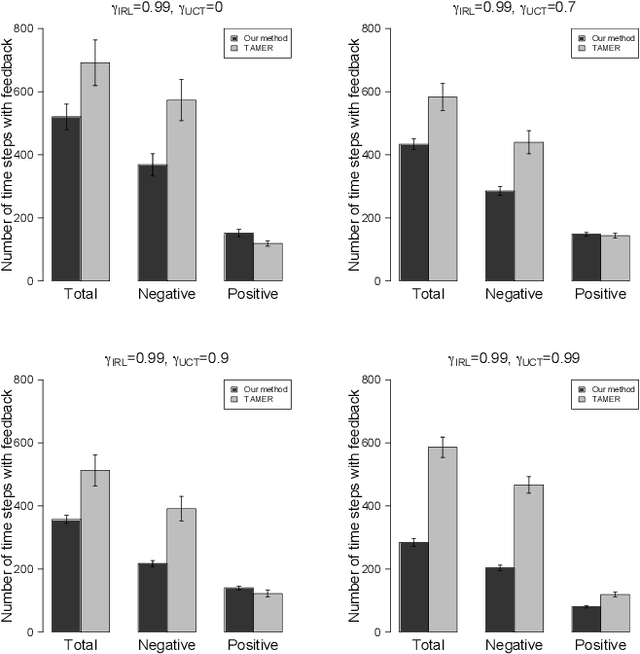
TAMER has proven to be a powerful interactive reinforcement learning method for allowing ordinary people to teach and personalize autonomous agents' behavior by providing evaluative feedback. However, a TAMER agent planning with UCT---a Monte Carlo Tree Search strategy, can only update states along its path and might induce high learning cost especially for a physical robot. In this paper, we propose to drive the agent's exploration along the optimal path and reduce the learning cost by initializing the agent's reward function via inverse reinforcement learning from demonstration. We test our proposed method in the RL benchmark domain---Grid World---with different discounts on human reward. Our results show that learning from demonstration can allow a TAMER agent to learn a roughly optimal policy up to the deepest search and encourage the agent to explore along the optimal path. In addition, we find that learning from demonstration can improve the learning efficiency by reducing total feedback, the number of incorrect actions and increasing the ratio of correct actions to obtain an optimal policy, allowing a TAMER agent to converge faster.