 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Associative Inference Using Fast Weight Memory
Nov 16, 2020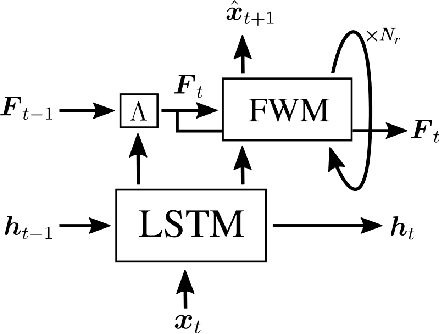
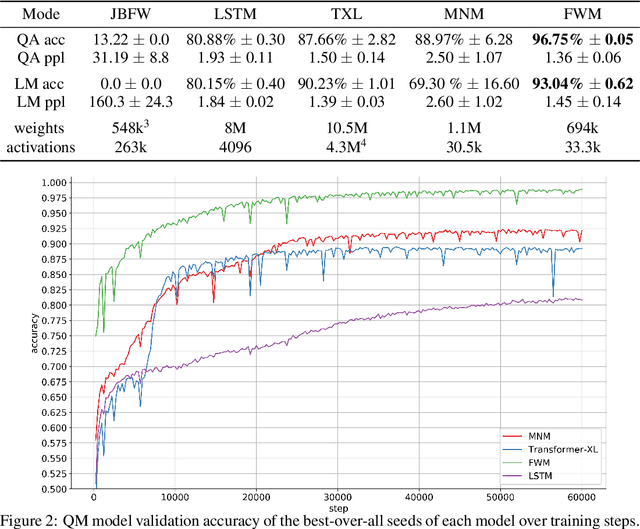
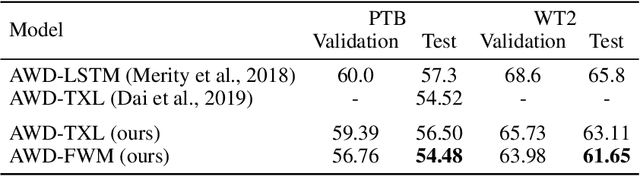
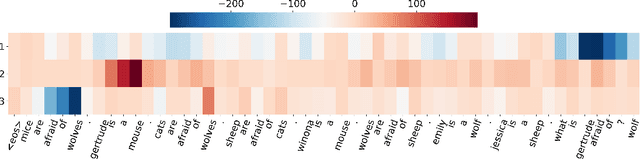
Humans can quickly associate stimuli to solve problems in novel contexts. Our novel neural network model learns state representations of facts that can be composed to perform such associative inference. To this end, we augment the LSTM model with an associative memory, dubbed Fast Weight Memory (FWM). Through differentiable operations at every step of a given input sequence, the LSTM updates and maintains compositional associations stored in the rapidly changing FWM weights. Our model is trained end-to-end by gradient descent and yields excellent performance on compositional language reasoning problems, meta-reinforcement-learning for POMDPs, and small-scale word-level language modelling.
Self-Supervised Meta-Learning for Few-Shot Natural Language Classification Tasks
Sep 17, 2020
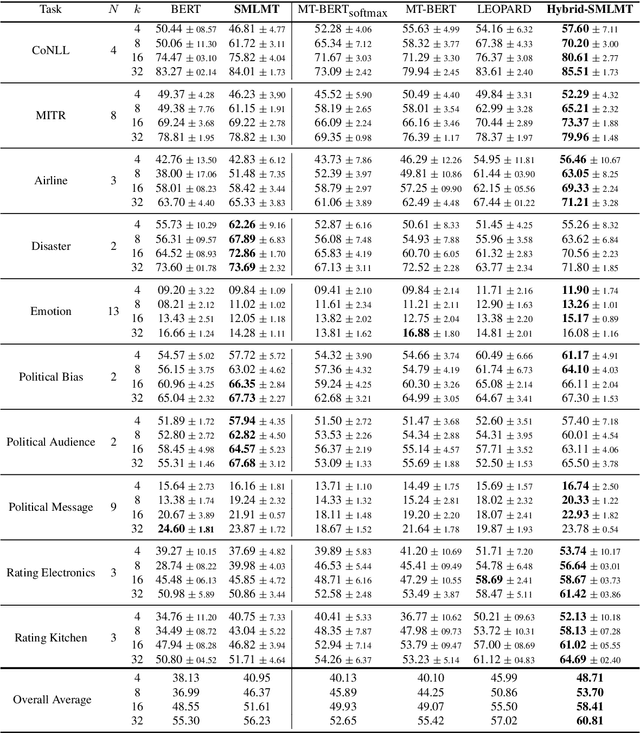
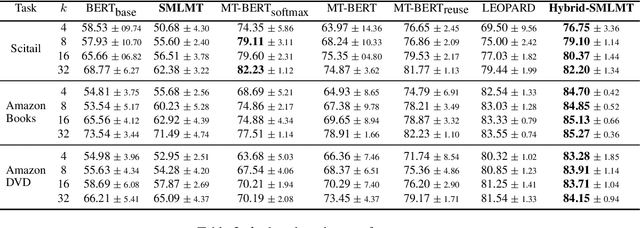

Self-supervised pre-training of transformer models has revolutionized NLP applications. Such pre-training with language modeling objectives provides a useful initial point for parameters that generalize well to new tasks with fine-tuning. However, fine-tuning is still data inefficient -- when there are few labeled examples, accuracy can be low. Data efficiency can be improved by optimizing pre-training directly for future fine-tuning with few examples; this can be treated as a meta-learning problem. However, standard meta-learning techniques require many training tasks in order to generalize; unfortunately, finding a diverse set of such supervised tasks is usually difficult. This paper proposes a self-supervised approach to generate a large, rich, meta-learning task distribution from unlabeled text. This is achieved using a cloze-style objective, but creating separate multi-class classification tasks by gathering tokens-to-be blanked from among only a handful of vocabulary terms. This yields as many unique meta-training tasks as the number of subsets of vocabulary terms. We meta-train a transformer model on this distribution of tasks using a recent meta-learning framework. On 17 NLP tasks, we show that this meta-training leads to better few-shot generalization than language-model pre-training followed by finetuning. Furthermore, we show how the self-supervised tasks can be combined with supervised tasks for meta-learning, providing substantial accuracy gains over previous supervised meta-learning.
Sparse Meta Networks for Sequential Adaptation and its Application to Adaptive Language Modelling
Sep 03, 2020Training a deep neural network requires a large amount of single-task data and involves a long time-consuming optimization phase. This is not scalable to complex, realistic environments with new unexpected changes. Humans can perform fast incremental learning on the fly and memory systems in the brain play a critical role. We introduce Sparse Meta Networks -- a meta-learning approach to learn online sequential adaptation algorithms for deep neural networks, by using deep neural networks. We augment a deep neural network with a layer-specific fast-weight memory. The fast-weights are generated sparsely at each time step and accumulated incrementally through time providing a useful inductive bias for online continual adaptation. We demonstrate strong performance on a variety of sequential adaptation scenarios, from a simple online reinforcement learning to a large scale adaptive language modelling.
A Locally Adaptive Interpretable Regression
May 14, 2020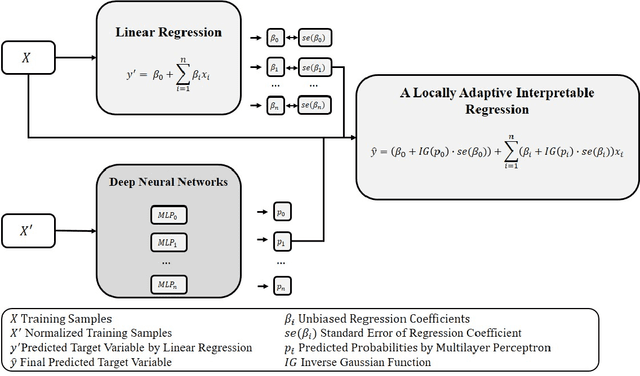
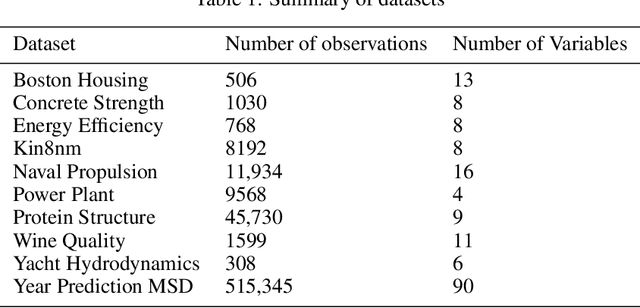
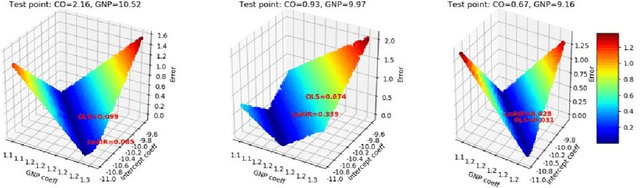
Machine learning models with both good predictability and high interpretability are crucial for decision support systems. Linear regression is one of the most interpretable prediction models. However, the linearity in a simple linear regression worsens its predictability. In this work, we introduce a locally adaptive interpretable regression (LoAIR). In LoAIR, a metamodel parameterized by neural networks predicts percentile of a Gaussian distribution for the regression coefficients for a rapid adaptation. Our experimental results on public benchmark datasets show that our model not only achieves comparable or better predictive performance than the other state-of-the-art baselines but also discovers some interesting relationships between input and target variables such as a parabolic relationship between CO2 emissions and Gross National Product (GNP). Therefore, LoAIR is a step towards bridging the gap between econometrics, statistics, and machine learning by improving the predictive ability of linear regression without depreciating its interpretability.
Exploring and Predicting Transferability across NLP Tasks
May 02, 2020
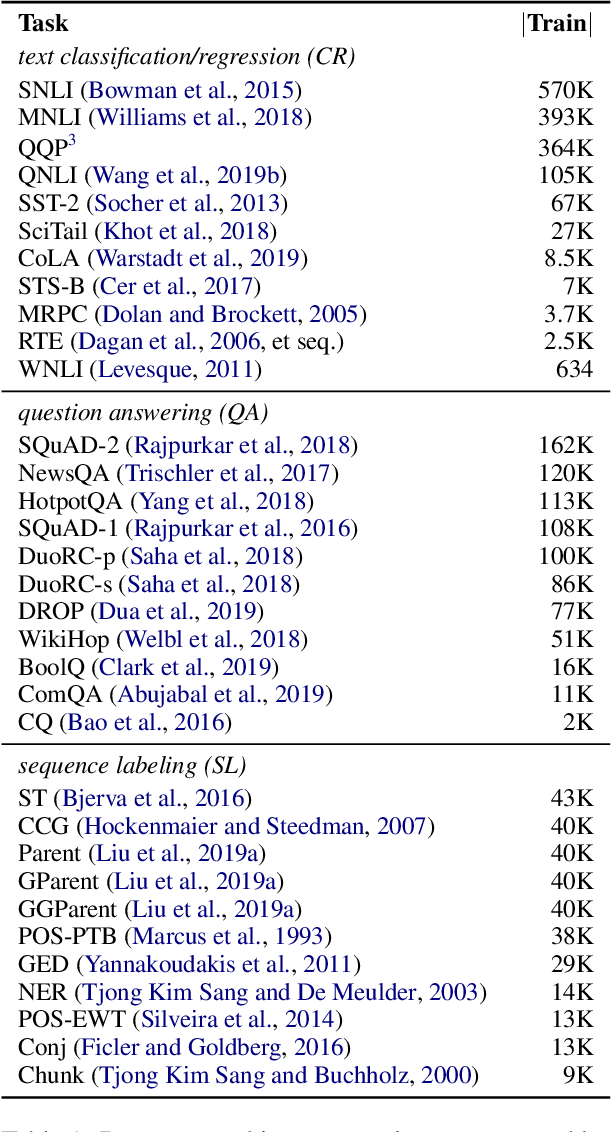
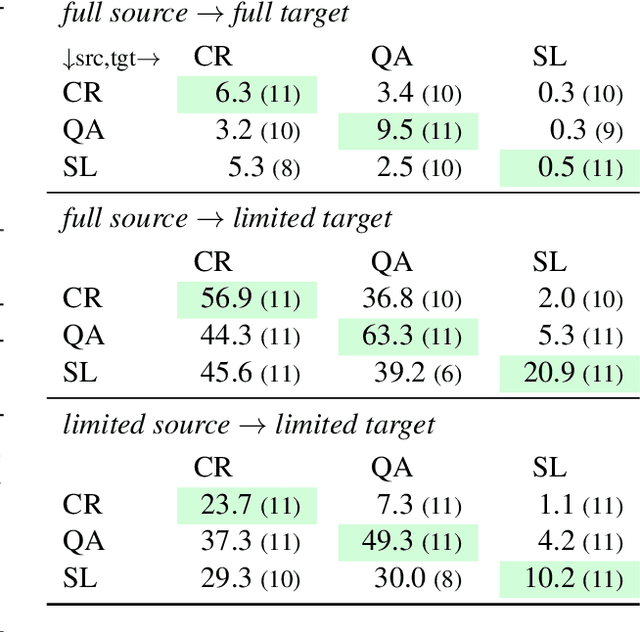
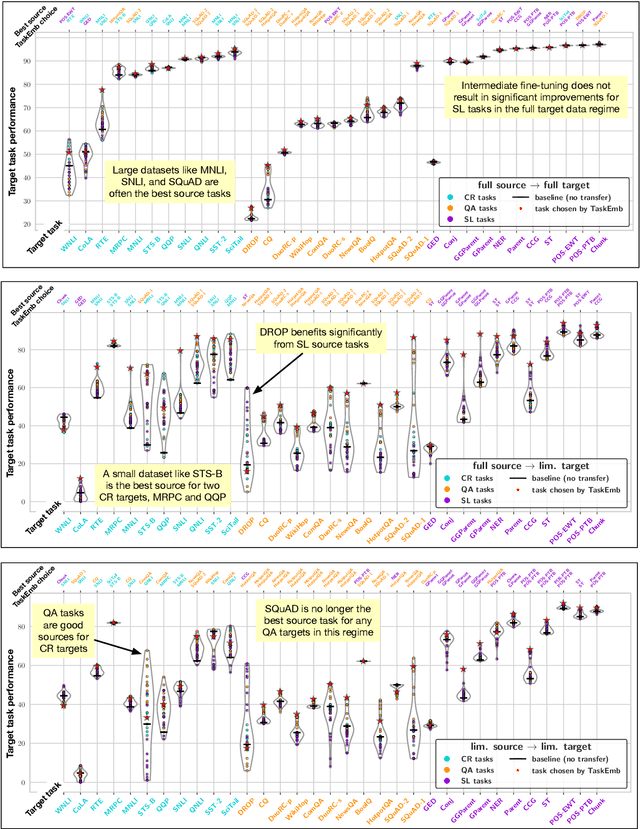
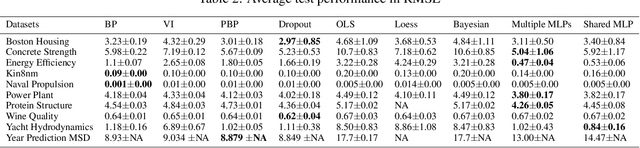
Recent advances in NLP demonstrate the effectiveness of training large-scale language models and transferring them to downstream tasks. Can fine-tuning these models on tasks other than language modeling further improve performance? In this paper, we conduct an extensive study of the transferability between 33 NLP tasks across three broad classes of problems (text classification, question answering, and sequence labeling). Our results show that transfer learning is more beneficial than previously thought, especially when target task data is scarce, and can improve performance even when the source task is small or differs substantially from the target task (e.g., part-of-speech tagging transfers well to the DROP QA dataset). We also develop task embeddings that can be used to predict the most transferable source tasks for a given target task, and we validate their effectiveness in experiments controlled for source and target data size. Overall, our experiments reveal that factors such as source data size, task and domain similarity, and task complexity all play a role in determining transferability.
Metalearned Neural Memory
Jul 23, 2019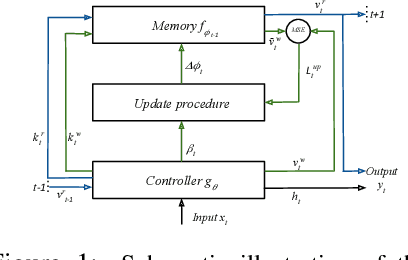
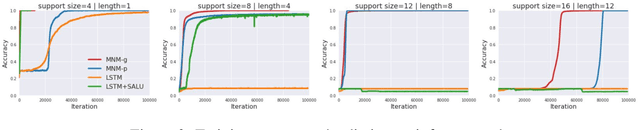

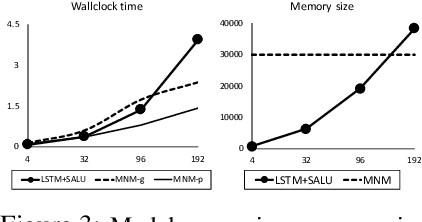
We augment recurrent neural networks with an external memory mechanism that builds upon recent progress in metalearning. We conceptualize this memory as a rapidly adaptable function that we parameterize as a deep neural network. Reading from the neural memory function amounts to pushing an input (the key vector) through the function to produce an output (the value vector). Writing to memory means changing the function; specifically, updating the parameters of the neural network to encode desired information. We leverage training and algorithmic techniques from metalearning to update the neural memory function in one shot. The proposed memory-augmented model achieves strong performance on a variety of learning problems, from supervised question answering to reinforcement learning.
Building Dynamic Knowledge Graphs from Text using Machine Reading Comprehension
Oct 12, 2018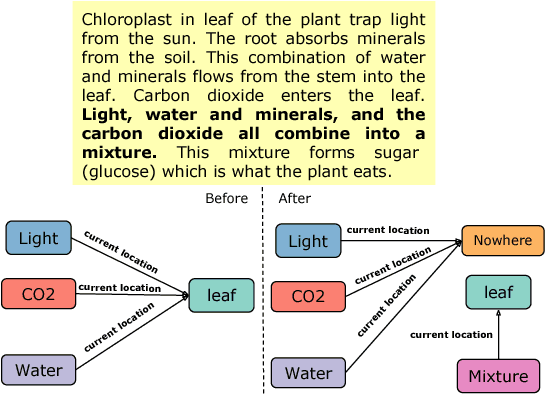

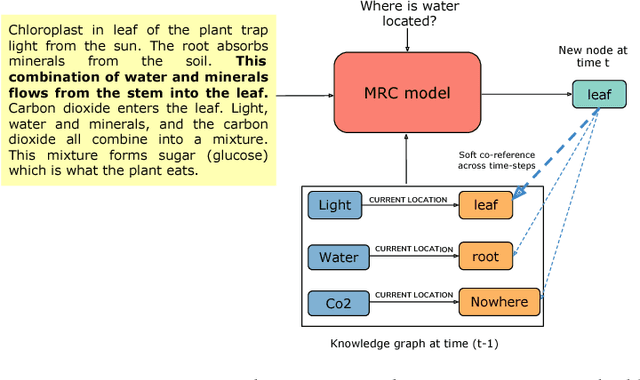
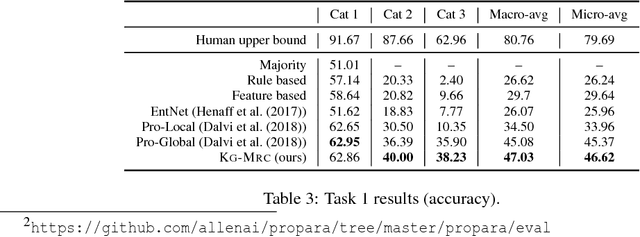
We propose a neural machine-reading model that constructs dynamic knowledge graphs from procedural text. It builds these graphs recurrently for each step of the described procedure, and uses them to track the evolving states of participant entities. We harness and extend a recently proposed machine reading comprehension (MRC) model to query for entity states, since these states are generally communicated in spans of text and MRC models perform well in extracting entity-centric spans. The explicit, structured, and evolving knowledge graph representations that our model constructs can be used in downstream question answering tasks to improve machine comprehension of text, as we demonstrate empirically. On two comprehension tasks from the recently proposed PROPARA dataset (Dalvi et al., 2018), our model achieves state-of-the-art results. We further show that our model is competitive on the RECIPES dataset (Kiddon et al., 2015), suggesting it may be generally applicable. We present some evidence that the model's knowledge graphs help it to impose commonsense constraints on its predictions.
Understanding Deep Learning Performance through an Examination of Test Set Difficulty: A Psychometric Case Study
Sep 07, 2018
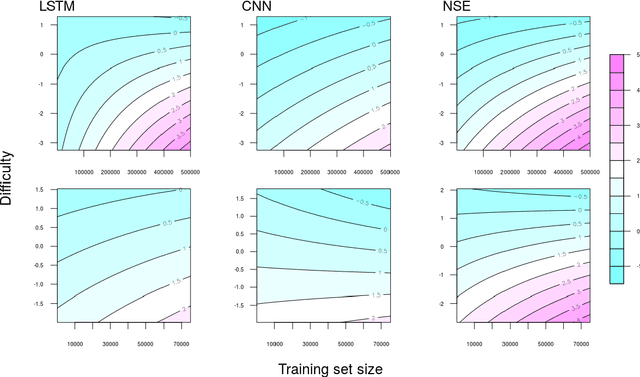

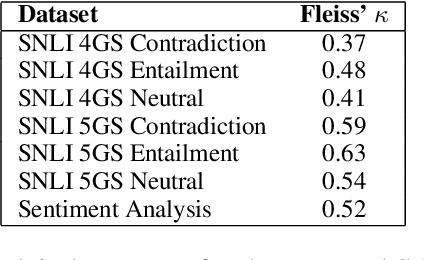
Interpreting the performance of deep learning models beyond test set accuracy is challenging. Characteristics of individual data points are often not considered during evaluation, and each data point is treated equally. We examine the impact of a test set question's difficulty to determine if there is a relationship between difficulty and performance. We model difficulty using well-studied psychometric methods on human response patterns. Experiments on Natural Language Inference (NLI) and Sentiment Analysis (SA) show that the likelihood of answering a question correctly is impacted by the question's difficulty. As DNNs are trained with more data, easy examples are learned more quickly than hard examples.
Metalearning with Hebbian Fast Weights
Jul 12, 2018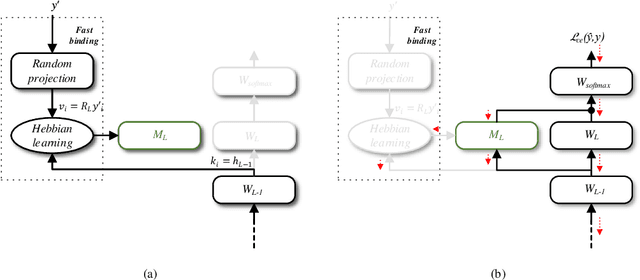
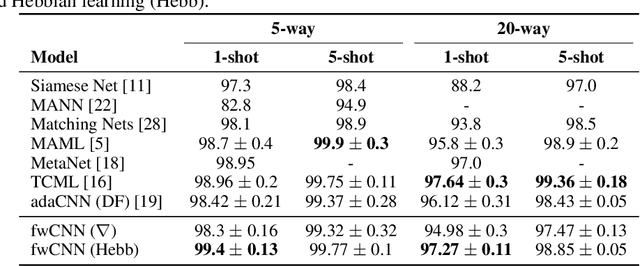
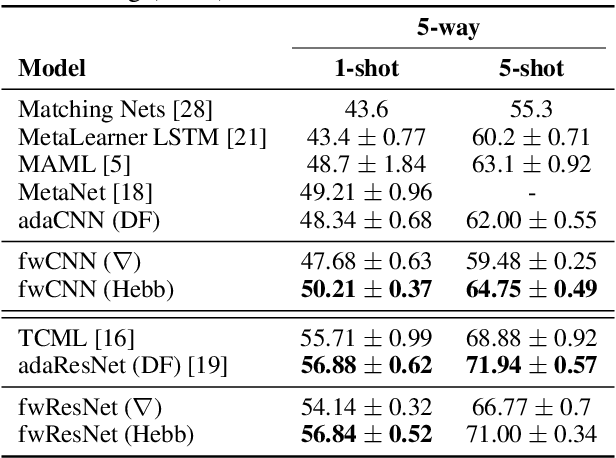
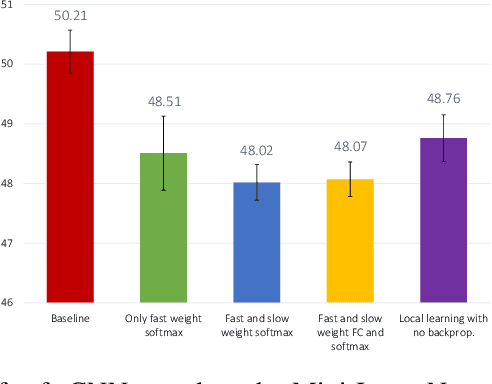
We unify recent neural approaches to one-shot learning with older ideas of associative memory in a model for metalearning. Our model learns jointly to represent data and to bind class labels to representations in a single shot. It builds representations via slow weights, learned across tasks through SGD, while fast weights constructed by a Hebbian learning rule implement one-shot binding for each new task. On the Omniglot, Mini-ImageNet, and Penn Treebank one-shot learning benchmarks, our model achieves state-of-the-art results.
Rapid Adaptation with Conditionally Shifted Neurons
Jul 03, 2018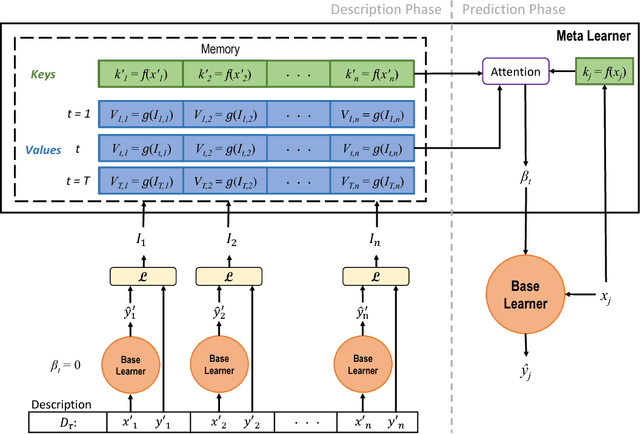
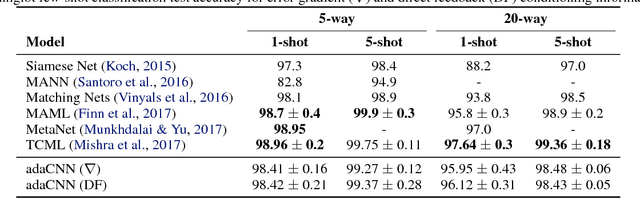
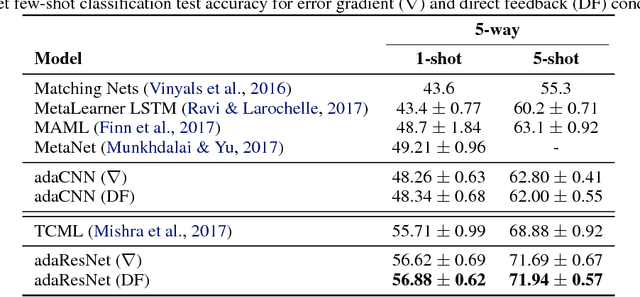
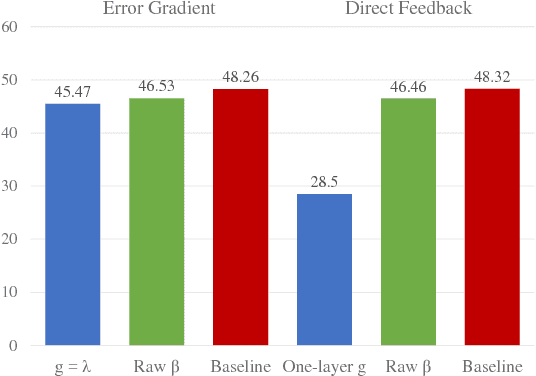
We describe a mechanism by which artificial neural networks can learn rapid adaptation - the ability to adapt on the fly, with little data, to new tasks - that we call conditionally shifted neurons. We apply this mechanism in the framework of metalearning, where the aim is to replicate some of the flexibility of human learning in machines. Conditionally shifted neurons modify their activation values with task-specific shifts retrieved from a memory module, which is populated rapidly based on limited task experience. On metalearning benchmarks from the vision and language domains, models augmented with conditionally shifted neurons achieve state-of-the-art results.