 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Chemical Named Entity Recognition in Patents with Contextualized Word Embeddings
Jul 05, 2019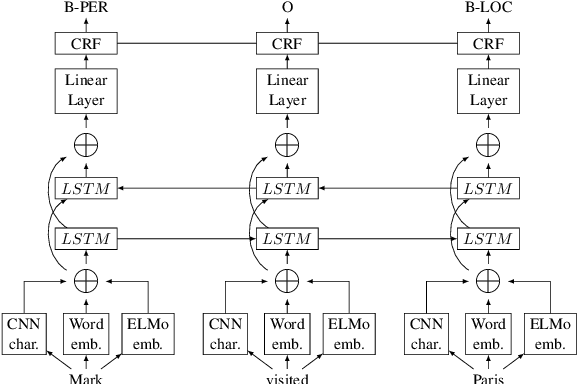

Chemical patents are an important resource for chemical information. However, few chemical Named Entity Recognition (NER) systems have been evaluated on patent documents, due in part to their structural and linguistic complexity. In this paper, we explore the NER performance of a BiLSTM-CRF model utilising pre-trained word embeddings, character-level word representations and contextualized ELMo word representations for chemical patents. We compare word embeddings pre-trained on biomedical and chemical patent corpora. The effect of tokenizers optimized for the chemical domain on NER performance in chemical patents is also explored. The results on two patent corpora show that contextualized word representations generated from ELMo substantially improve chemical NER performance w.r.t. the current state-of-the-art. We also show that domain-specific resources such as word embeddings trained on chemical patents and chemical-specific tokenizers have a positive impact on NER performance.
Semi-supervised Stochastic Multi-Domain Learning using Variational Inference
Jun 07, 2019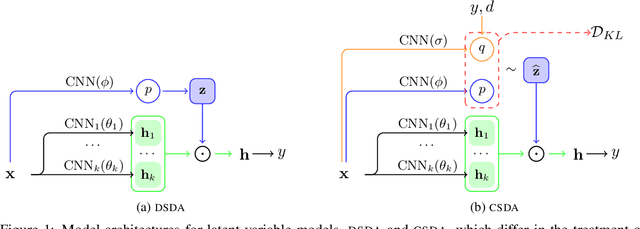
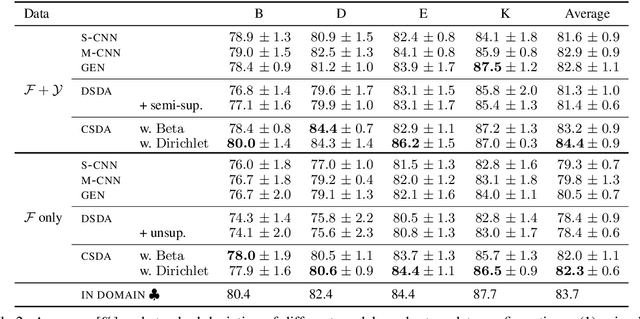
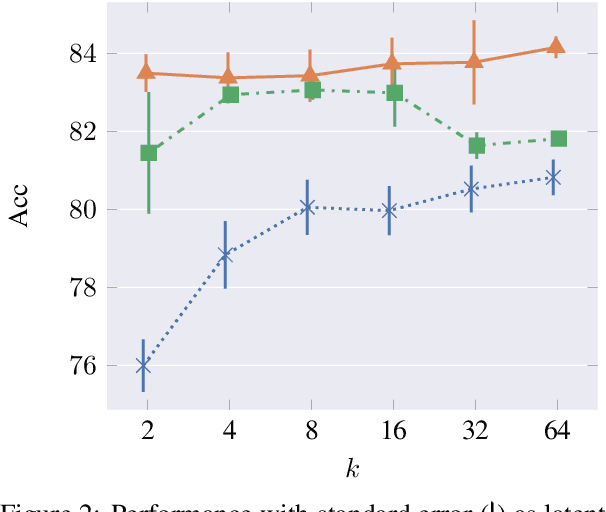
Supervised models of NLP rely on large collections of text which closely resemble the intended testing setting. Unfortunately matching text is often not available in sufficient quantity, and moreover, within any domain of text, data is often highly heterogenous. In this paper we propose a method to distill the important domain signal as part of a multi-domain learning system, using a latent variable model in which parts of a neural model are stochastically gated based on the inferred domain. We compare the use of discrete versus continuous latent variables, operating in a domain-supervised or a domain semi-supervised setting, where the domain is known only for a subset of training inputs. We show that our model leads to substantial performance improvements over competitive benchmark domain adaptation methods, including methods using adversarial learning.
Target Based Speech Act Classification in Political Campaign Text
May 20, 2019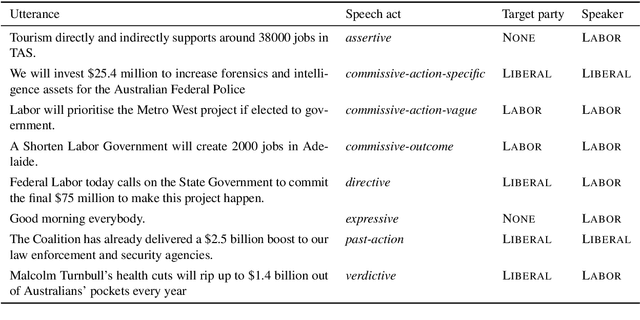
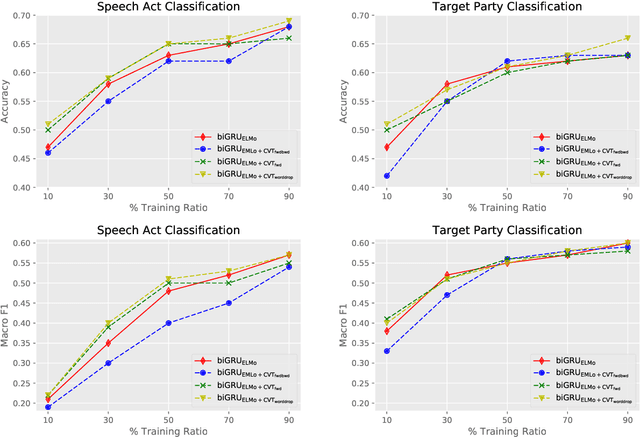

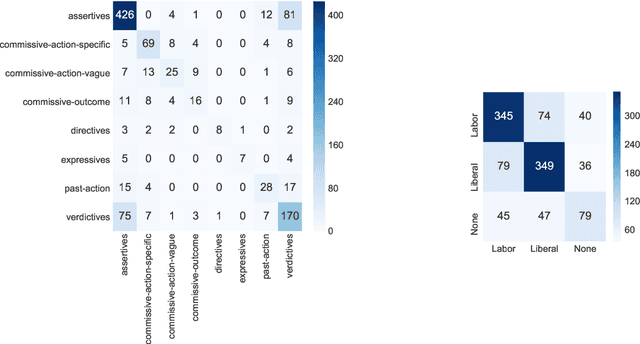
We study pragmatics in political campaign text, through analysis of speech acts and the target of each utterance. We propose a new annotation schema incorporating domain-specific speech acts, such as commissive-action, and present a novel annotated corpus of media releases and speech transcripts from the 2016 Australian election cycle. We show how speech acts and target referents can be modeled as sequential classification, and evaluate several techniques, exploiting contextualized word representations, semi-supervised learning, task dependencies and speaker meta-data.
Contextualization of Morphological Inflection
May 04, 2019
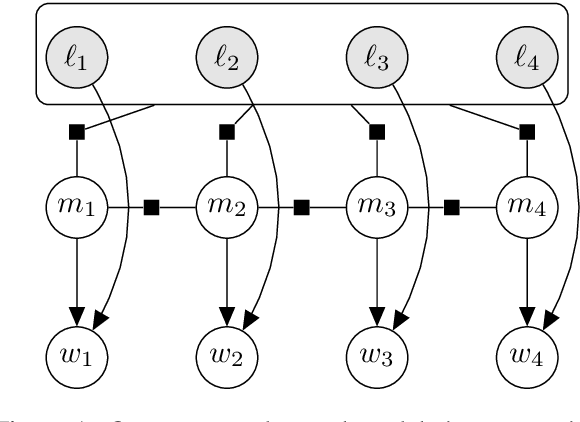
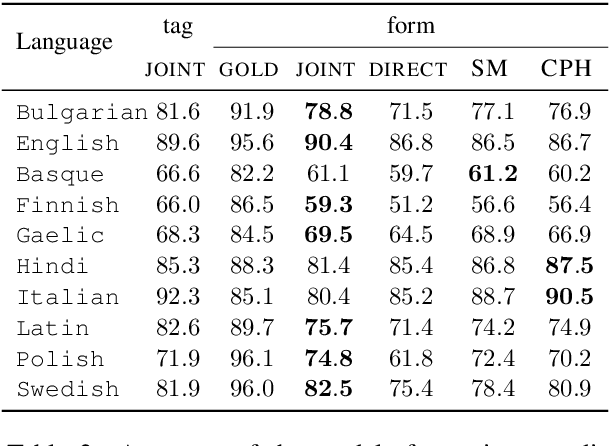
Critical to natural language generation is the production of correctly inflected text. In this paper, we isolate the task of predicting a fully inflected sentence from its partially lemmatized version. Unlike traditional morphological inflection or surface realization, our task input does not provide ``gold'' tags that specify what morphological features to realize on each lemmatized word; rather, such features must be inferred from sentential context. We develop a neural hybrid graphical model that explicitly reconstructs morphological features before predicting the inflected forms, and compare this to a system that directly predicts the inflected forms without relying on any morphological annotation. We experiment on several typologically diverse languages from the Universal Dependencies treebanks, showing the utility of incorporating linguistically-motivated latent variables into NLP models.
A Unified Neural Architecture for Instrumental Audio Tasks
Mar 01, 2019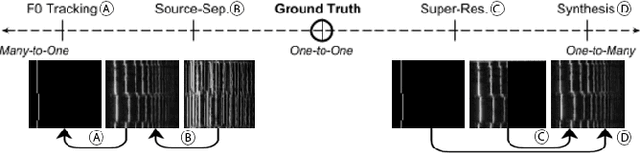
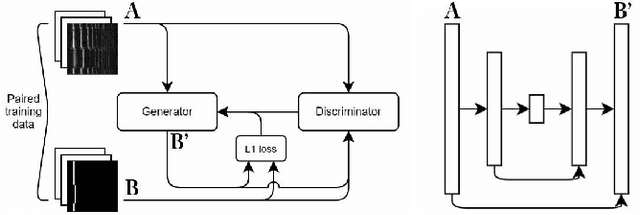
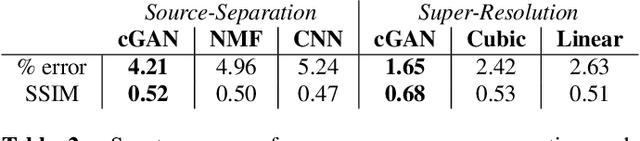
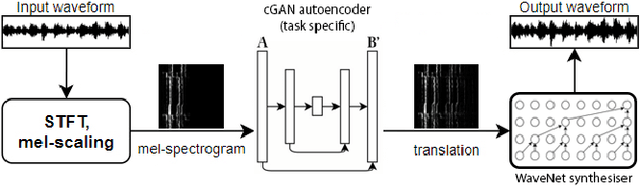
Within Music Information Retrieval (MIR), prominent tasks -- including pitch-tracking, source-separation, super-resolution, and synthesis -- typically call for specialised methods, despite their similarities. Conditional Generative Adversarial Networks (cGANs) have been shown to be highly versatile in learning general image-to-image translations, but have not yet been adapted across MIR. In this work, we present an end-to-end supervisable architecture to perform all aforementioned audio tasks, consisting of a WaveNet synthesiser conditioned on the output of a jointly-trained cGAN spectrogram translator. In doing so, we demonstrate the potential of such flexible techniques to unify MIR tasks, promote efficient transfer learning, and converge research to the improvement of powerful, general methods. Finally, to the best of our knowledge, we present the first application of GANs to guided instrument synthesis.
Truth Inference at Scale: A Bayesian Model for Adjudicating Highly Redundant Crowd Annotations
Feb 24, 2019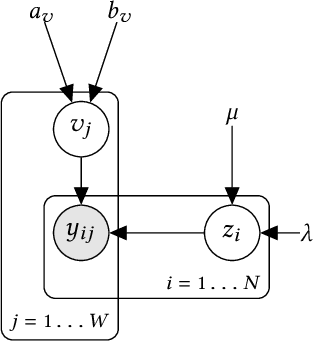
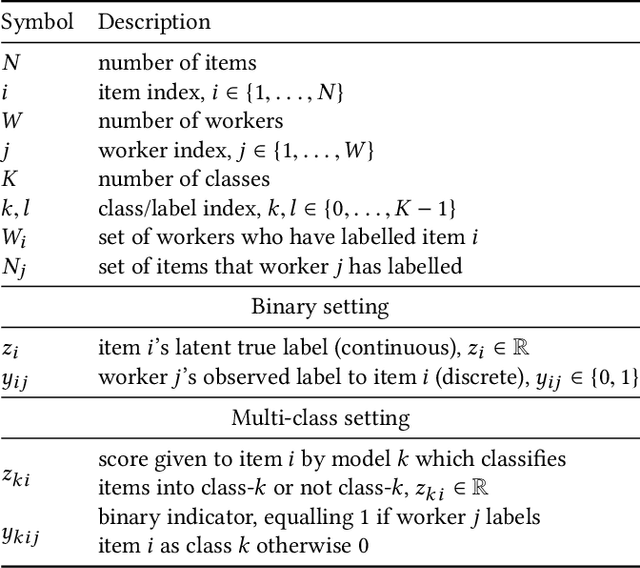
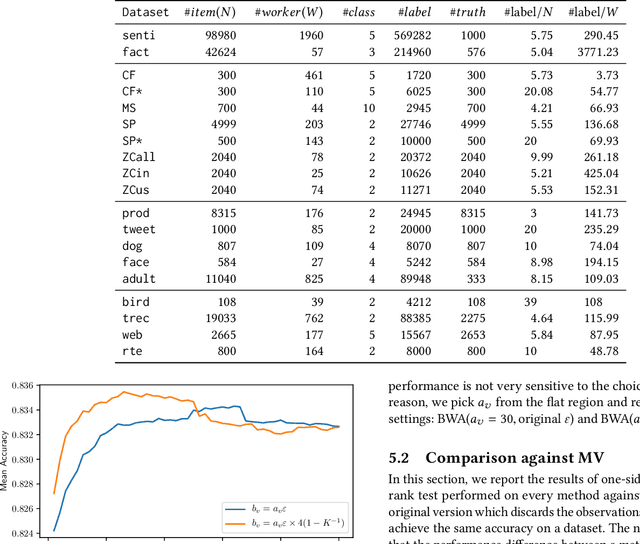
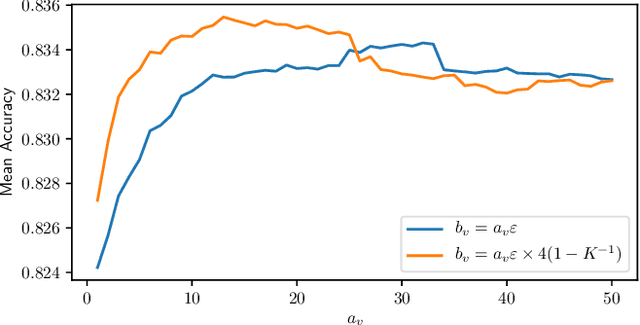
Crowd-sourcing is a cheap and popular means of creating training and evaluation datasets for machine learning, however it poses the problem of `truth inference', as individual workers cannot be wholly trusted to provide reliable annotations. Research into models of annotation aggregation attempts to infer a latent `true' annotation, which has been shown to improve the utility of crowd-sourced data. However, existing techniques beat simple baselines only in low redundancy settings, where the number of annotations per instance is low ($\le 3$), or in situations where workers are unreliable and produce low quality annotations (e.g., through spamming, random, or adversarial behaviours.) As we show, datasets produced by crowd-sourcing are often not of this type: the data is highly redundantly annotated ($\ge 5$ annotations per instance), and the vast majority of workers produce high quality outputs. In these settings, the majority vote heuristic performs very well, and most truth inference models underperform this simple baseline. We propose a novel technique, based on a Bayesian graphical model with conjugate priors, and simple iterative expectation-maximisation inference. Our technique produces competitive performance to the state-of-the-art benchmark methods, and is the only method that significantly outperforms the majority vote heuristic at one-sided level 0.025, shown by significance tests. Moreover, our technique is simple, is implemented in only 50 lines of code, and trains in seconds.
Multilingual NER Transfer for Low-resource Languages
Feb 01, 2019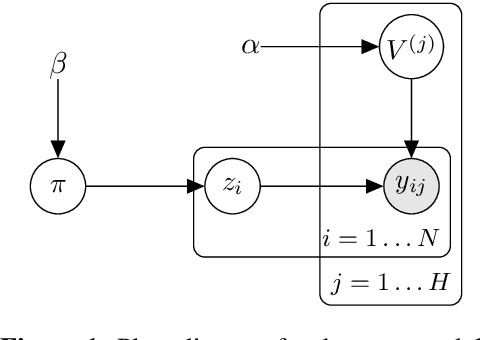


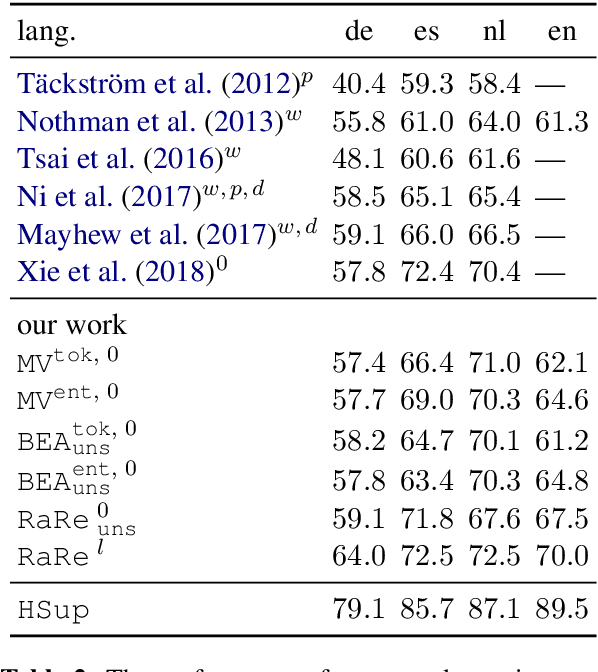
In massively multilingual transfer NLP models over many source languages are applied to a low-resource target language. In contrast to most prior work, which use a single model or a small handful, we consider many such models, which raises the critical problem of poor transfer, particularly from distant languages. We propose two techniques for modulating the transfer: one based on unsupervised truth inference, and another using limited supervision in the target language. Evaluating on named entity recognition over 41 languages, we show that our techniques are much more effective than strong baselines, including standard ensembling, and our unsupervised method rivals oracle selection of the single best individual model.
Evaluating the Utility of Hand-crafted Features in Sequence Labelling
Aug 28, 2018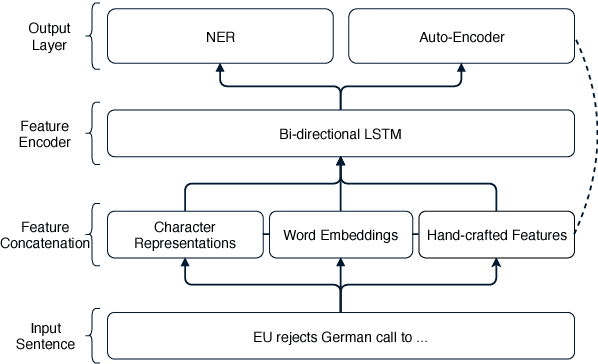

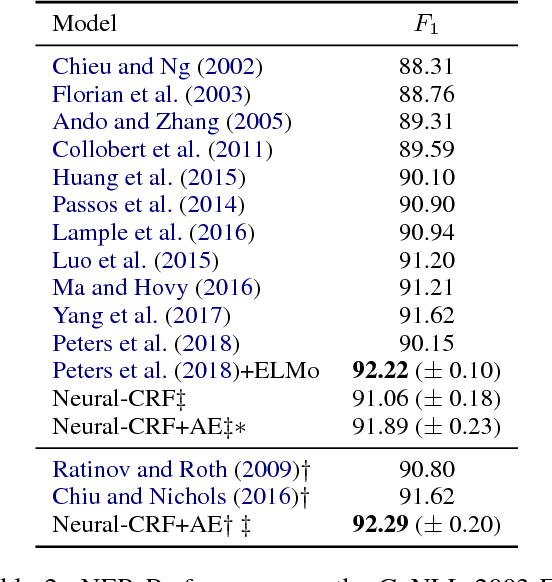
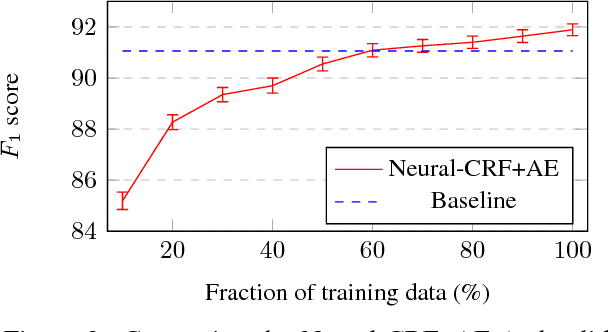
Conventional wisdom is that hand-crafted features are redundant for deep learning models, as they already learn adequate representations of text automatically from corpora. In this work, we test this claim by proposing a new method for exploiting handcrafted features as part of a novel hybrid learning approach, incorporating a feature auto-encoder loss component. We evaluate on the task of named entity recognition (NER), where we show that including manual features for part-of-speech, word shapes and gazetteers can improve the performance of a neural CRF model. We obtain a $F_1$ of 91.89 for the CoNLL-2003 English shared task, which significantly outperforms a collection of highly competitive baseline models. We also present an ablation study showing the importance of auto-encoding, over using features as either inputs or outputs alone, and moreover, show including the autoencoder components reduces training requirements to 60\%, while retaining the same predictive accuracy.
Deep-speare: A Joint Neural Model of Poetic Language, Meter and Rhyme
Jul 10, 2018
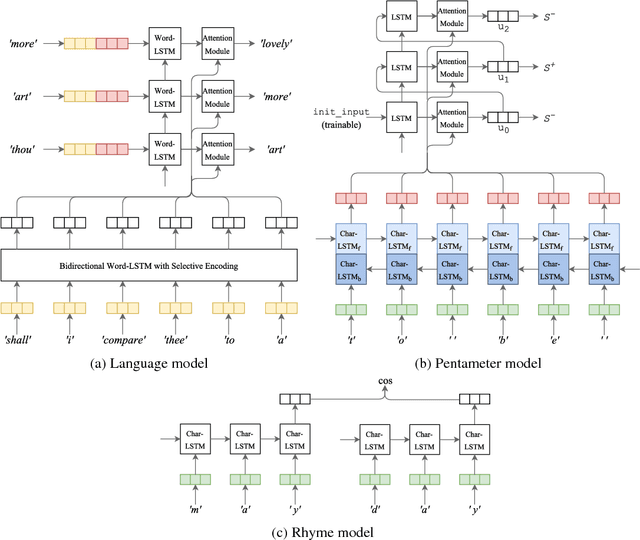
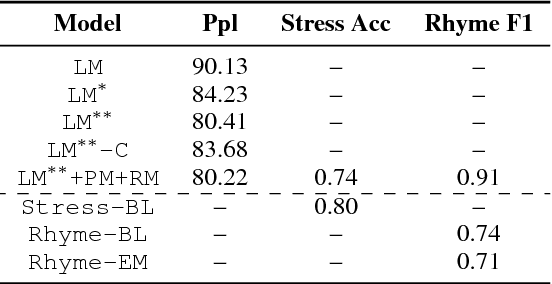
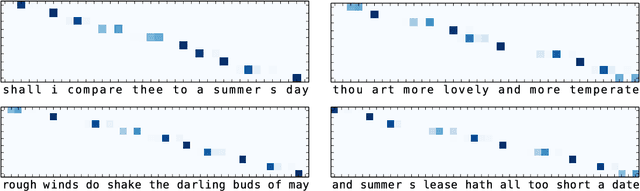
In this paper, we propose a joint architecture that captures language, rhyme and meter for sonnet modelling. We assess the quality of generated poems using crowd and expert judgements. The stress and rhyme models perform very well, as generated poems are largely indistinguishable from human-written poems. Expert evaluation, however, reveals that a vanilla language model captures meter implicitly, and that machine-generated poems still underperform in terms of readability and emotion. Our research shows the importance expert evaluation for poetry generation, and that future research should look beyond rhyme/meter and focus on poetic language.
* 11 pages; ACL2018
Graph-to-Sequence Learning using Gated Graph Neural Networks
Jun 26, 2018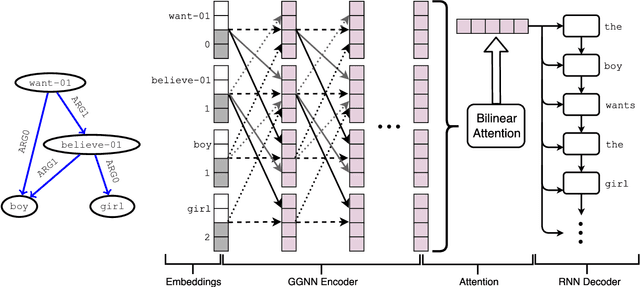
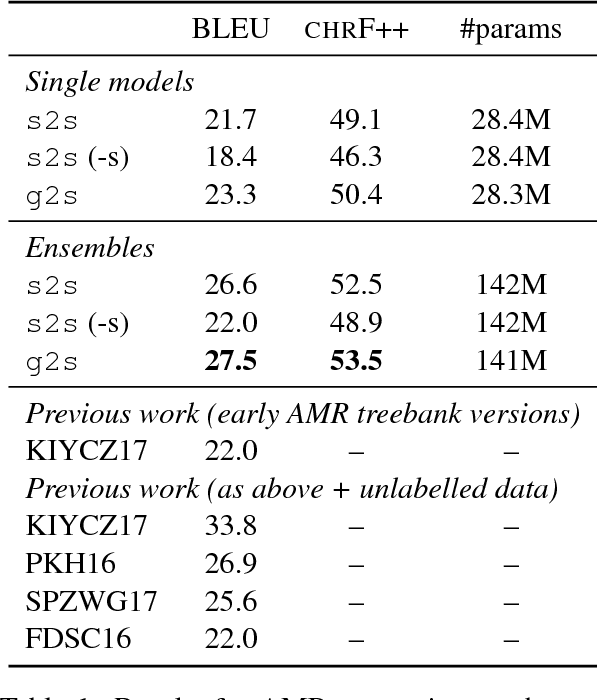
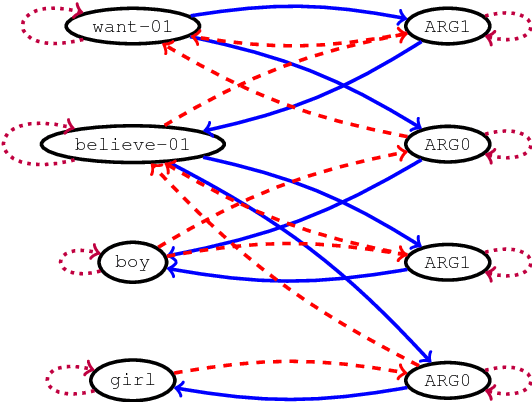
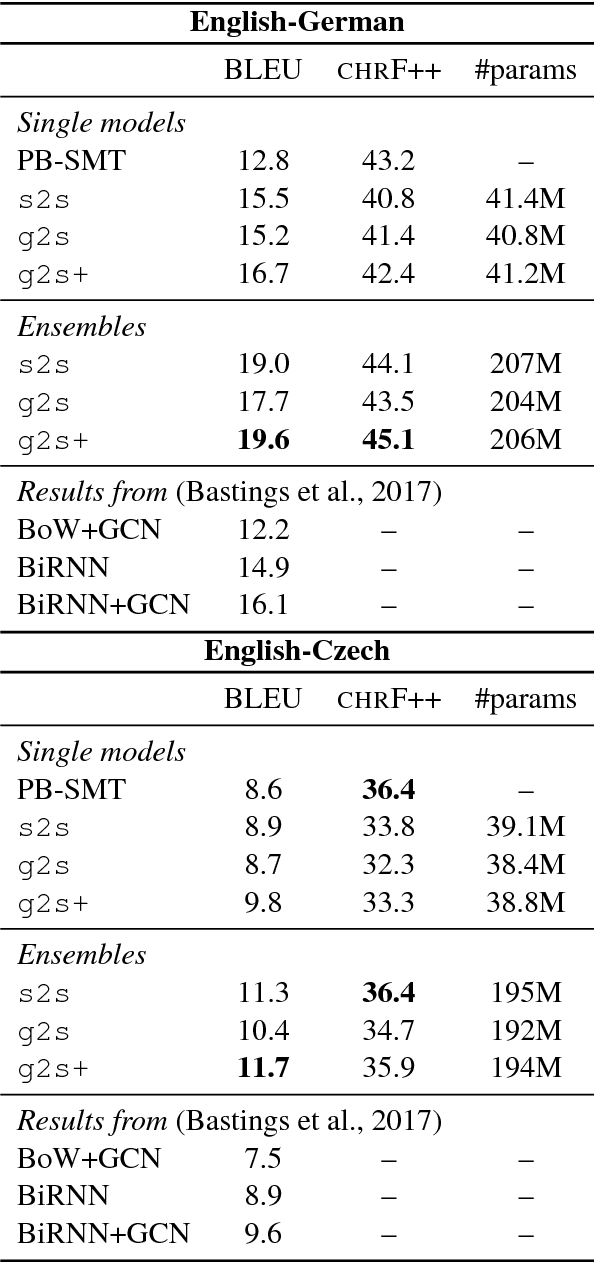
Many NLP applications can be framed as a graph-to-sequence learning problem. Previous work proposing neural architectures on this setting obtained promising results compared to grammar-based approaches but still rely on linearisation heuristics and/or standard recurrent networks to achieve the best performance. In this work, we propose a new model that encodes the full structural information contained in the graph. Our architecture couples the recently proposed Gated Graph Neural Networks with an input transformation that allows nodes and edges to have their own hidden representations, while tackling the parameter explosion problem present in previous work. Experimental results show that our model outperforms strong baselines in generation from AMR graphs and syntax-based neural machine translation.