 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LLM + ASP Workflow for Joint Entity-Relation Extraction
Aug 18, 2025



Joint entity-relation extraction (JERE) identifies both entities and their relationships simultaneously. Traditional machine-learning based approaches to performing this task require a large corpus of annotated data and lack the ability to easily incorporate domain specific information in the construction of the model. Therefore, creating a model for JERE is often labor intensive, time consuming, and elaboration intolerant. In this paper, we propose harnessing the capabilities of generative pretrained large language models (LLMs) and the knowledge representation and reasoning capabilities of Answer Set Programming (ASP) to perform JERE. We present a generic workflow for JERE using LLMs and ASP. The workflow is generic in the sense that it can be applied for JERE in any domain. It takes advantage of LLM's capability in natural language understanding in that it works directly with unannotated text. It exploits the elaboration tolerant feature of ASP in that no modification of its core program is required when additional domain specific knowledge, in the form of type specifications, is found and needs to be used. We demonstrate the usefulness of the proposed workflow through experiments with limited training data on three well-known benchmarks for JERE. The results of our experiments show that the LLM + ASP workflow is better than state-of-the-art JERE systems in several categories with only 10\% of training data. It is able to achieve a 2.5 times (35\% over 15\%) improvement in the Relation Extraction task for the SciERC corpus, one of the most difficult benchmarks.
Learn from Real: Reality Defender's Submission to ASVspoof5 Challenge
Oct 09, 2024



Audio deepfake detection is crucial to combat the malicious use of AI-synthesized speech. Among many efforts undertaken by the community, the ASVspoof challenge has become one of the benchmarks to evaluate the generalizability and robustness of detection models. In this paper, we present Reality Defender's submission to the ASVspoof5 challenge, highlighting a novel pretraining strategy which significantly improves generalizability while maintaining low computational cost during training. Our system SLIM learns the style-linguistics dependency embeddings from various types of bonafide speech using self-supervised contrastive learning. The learned embeddings help to discriminate spoof from bonafide speech by focusing on the relationship between the style and linguistics aspects. We evaluated our system on ASVspoof5, ASV2019, and In-the-wild. Our submission achieved minDCF of 0.1499 and EER of 5.5% on ASVspoof5 Track 1, and EER of 7.4% and 10.8% on ASV2019 and In-the-wild respectively.
SLIM: Style-Linguistics Mismatch Model for Generalized Audio Deepfake Detection
Jul 26, 2024



Audio deepfake detection (ADD) is crucial to combat the misuse of speech synthesized from generative AI models. Existing ADD models suffer from generalization issues, with a large performance discrepancy between in-domain and out-of-domain data. Moreover, the black-box nature of existing models limits their use in real-world scenarios, where explanations are required for model decisions. To alleviate these issues, we introduce a new ADD model that explicitly uses the StyleLInguistics Mismatch (SLIM) in fake speech to separate them from real speech. SLIM first employs self-supervised pretraining on only real samples to learn the style-linguistics dependency in the real class. The learned features are then used in complement with standard pretrained acoustic features (e.g., Wav2vec) to learn a classifier on the real and fake classes. When the feature encoders are frozen, SLIM outperforms benchmark methods on out-of-domain datasets while achieving competitive results on in-domain data. The features learned by SLIM allow us to quantify the (mis)match between style and linguistic content in a sample, hence facilitating an explanation of the model decision.
Box Embeddings: An open-source library for representation learning using geometric structures
Sep 10, 2021
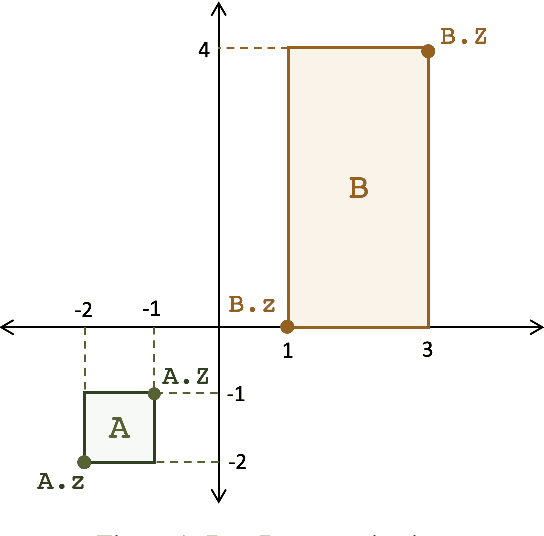
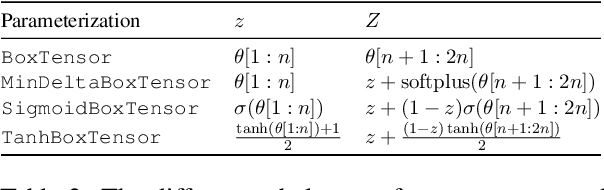
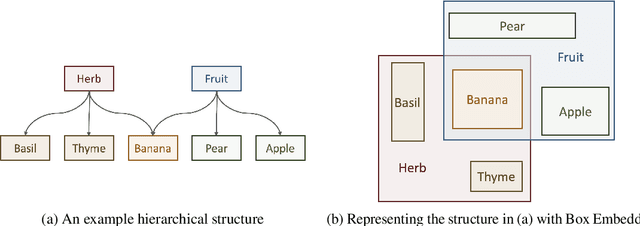
A major factor contributing to the success of modern representation learning is the ease of performing various vector operations. Recently, objects with geometric structures (eg. distributions, complex or hyperbolic vectors, or regions such as cones, disks, or boxes) have been explored for their alternative inductive biases and additional representational capacities. In this work, we introduce Box Embeddings, a Python library that enables researchers to easily apply and extend probabilistic box embeddings.
Assessing the Use of Prosody in Constituency Parsing of Imperfect Transcripts
Jun 14, 2021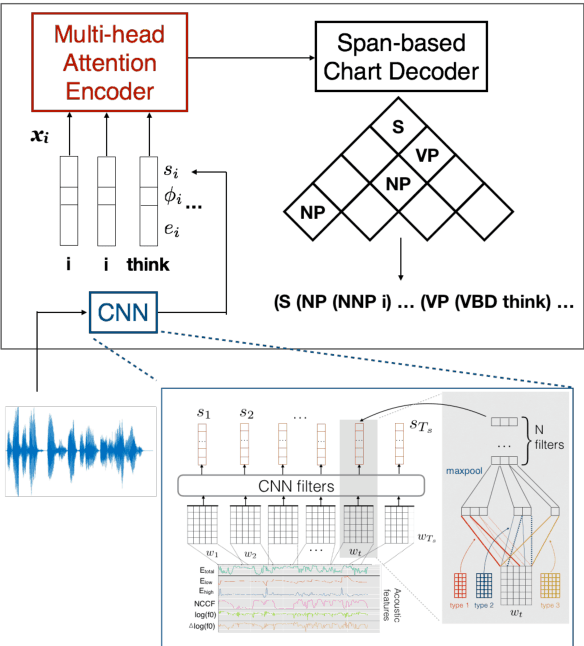
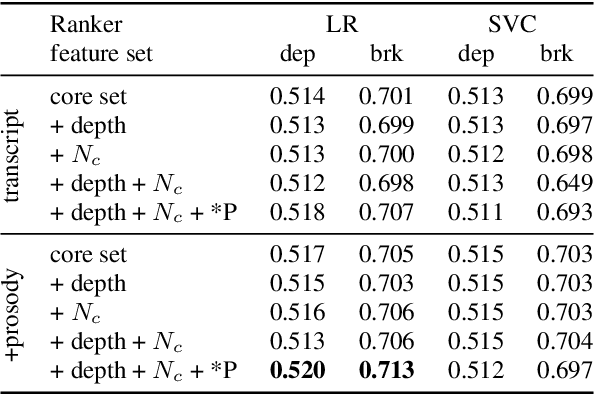
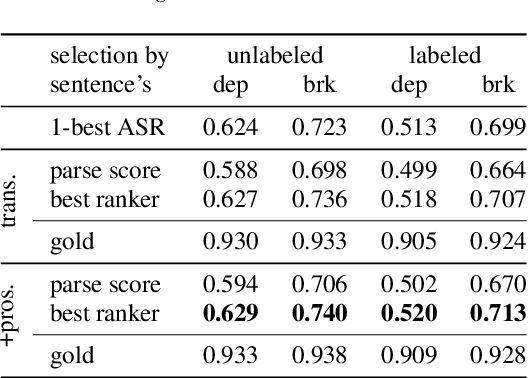
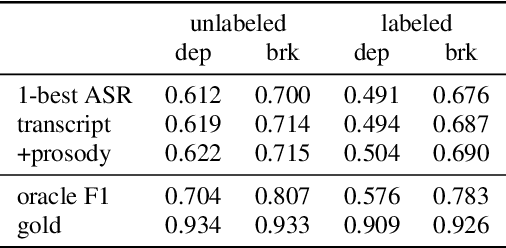
This work explores constituency parsing on automatically recognized transcripts of conversational speech. The neural parser is based on a sentence encoder that leverages word vectors contextualized with prosodic features, jointly learning prosodic feature extraction with parsing. We assess the utility of the prosody in parsing on imperfect transcripts, i.e. transcripts with automatic speech recognition (ASR) errors, by applying the parser in an N-best reranking framework. In experiments on Switchboard, we obtain 13-15% of the oracle N-best gain relative to parsing the 1-best ASR output, with insignificant impact on word recognition error rate. Prosody provides a significant part of the gain, and analyses suggest that it leads to more grammatical utterances via recovering function words.
KnowledgeCheckR: Intelligent Techniques for Counteracting Forgetting
Feb 15, 2021
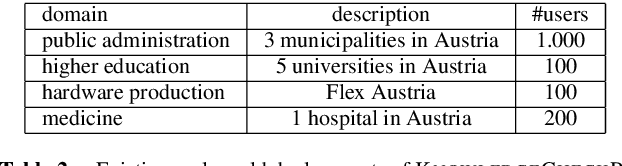
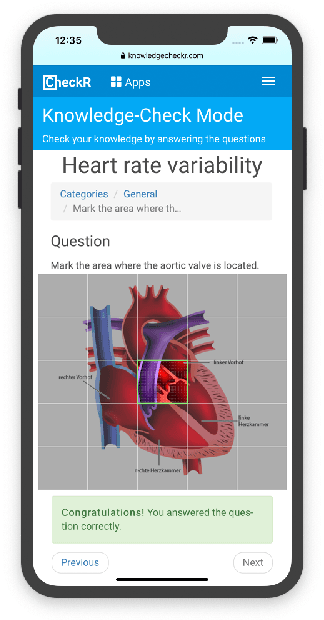
Existing e-learning environments primarily focus on the aspect of providing intuitive learning contents and to recommend learning units in a personalized fashion. The major focus of the KnowledgeCheckR environment is to take into account forgetting processes which immediately start after a learning unit has been completed. In this context, techniques are needed that are able to predict which learning units are the most relevant ones to be repeated in future learning sessions. In this paper, we provide an overview of the recommendation approaches integrated in KnowledgeCheckR. Examples thereof are utility-based recommendation that helps to identify learning contents to be repeated in the future, collaborative filtering approaches that help to implement session-based recommendation, and content-based recommendation that supports intelligent question answering. In order to show the applicability of the presented techniques, we provide an overview of the results of empirical studies that have been conducted in real-world scenarios.
Analysis of Disfluency in Children's Speech
Oct 08, 2020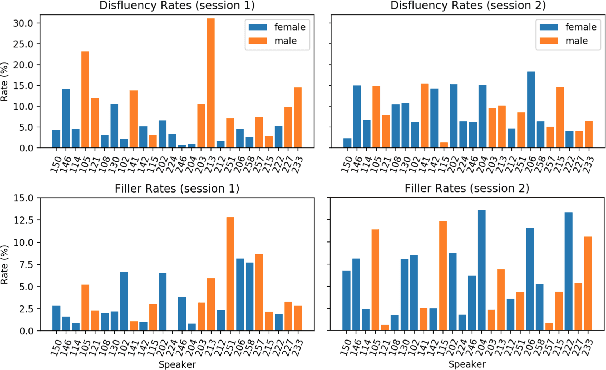
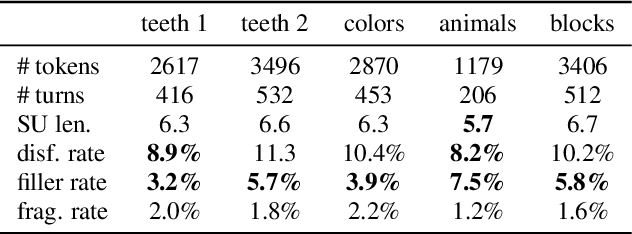
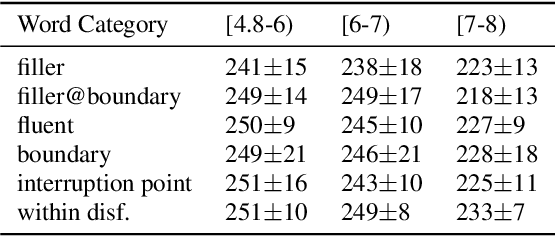
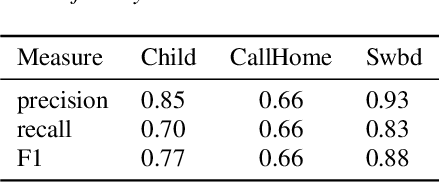
Disfluencies are prevalent in spontaneous speech, as shown in many studies of adult speech. Less is understood about children's speech, especially in pre-school children who are still developing their language skills. We present a novel dataset with annotated disfluencies of spontaneous explanations from 26 children (ages 5--8), interviewed twice over a year-long period. Our preliminary analysis reveals significant differences between children's speech in our corpus and adult spontaneous speech from two corpora (Switchboard and CallHome). Children have higher disfluency and filler rates, tend to use nasal filled pauses more frequently, and on average exhibit longer reparandums than repairs, in contrast to adult speakers. Despite the differences, an automatic disfluency detection system trained on adult (Switchboard) speech transcripts performs reasonably well on children's speech, achieving an F1 score that is 10\% higher than the score on an adult out-of-domain dataset (CallHome).
On the Role of Style in Parsing Speech with Neural Models
Oct 08, 2020
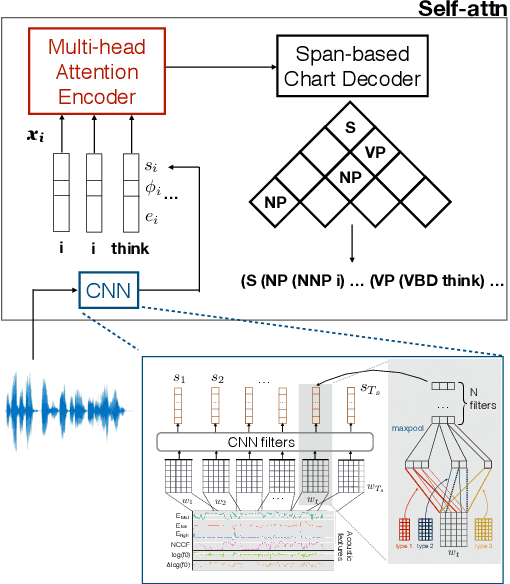

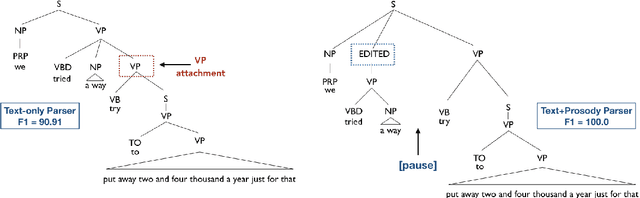
The differences in written text and conversational speech are substantial; previous parsers trained on treebanked text have given very poor results on spontaneous speech. For spoken language, the mismatch in style also extends to prosodic cues, though it is less well understood. This paper re-examines the use of written text in parsing speech in the context of recent advances in neural language processing. We show that neural approaches facilitate using written text to improve parsing of spontaneous speech, and that prosody further improves over this state-of-the-art result. Further, we find an asymmetric degradation from read vs. spontaneous mismatch, with spontaneous speech more generally useful for training parsers.
Disfluencies and Human Speech Transcription Errors
Apr 08, 2019
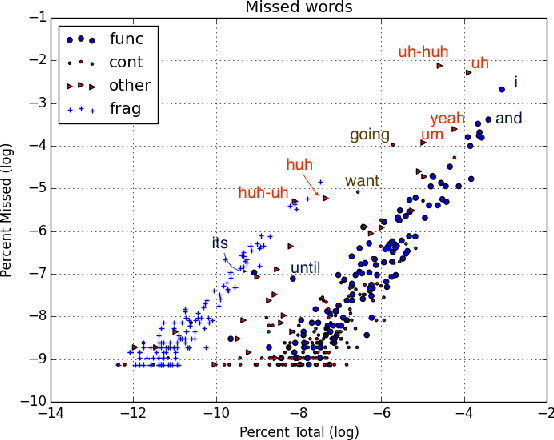
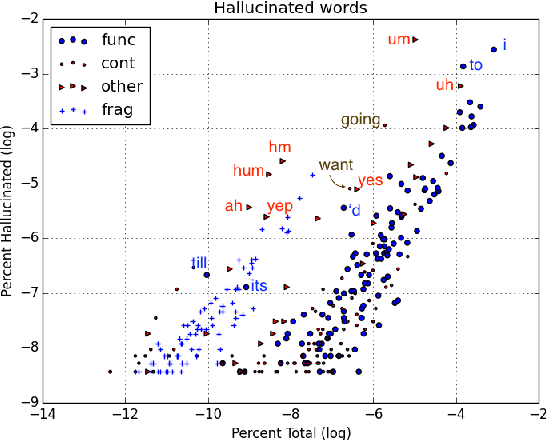
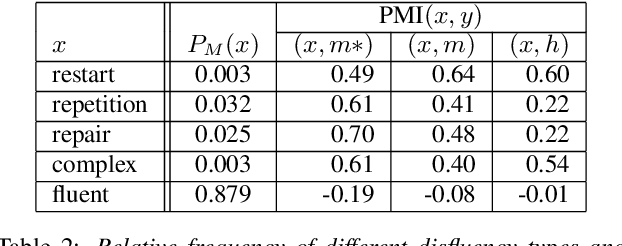
This paper explores contexts associated with errors in transcrip-tion of spontaneous speech, shedding light on human perceptionof disfluencies and other conversational speech phenomena. Anew version of the Switchboard corpus is provided with disfluency annotations for careful speech transcripts, together with results showing the impact of transcription errors on evaluation of automatic disfluency detection.
Parsing Speech: A Neural Approach to Integrating Lexical and Acoustic-Prosodic Information
Apr 15, 2018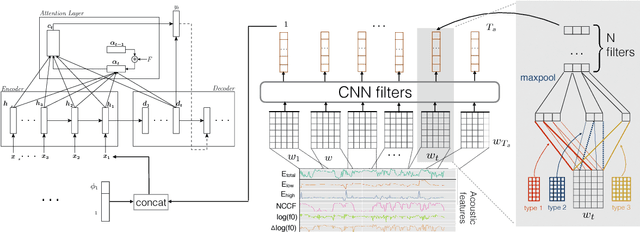
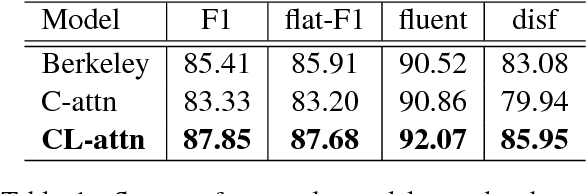
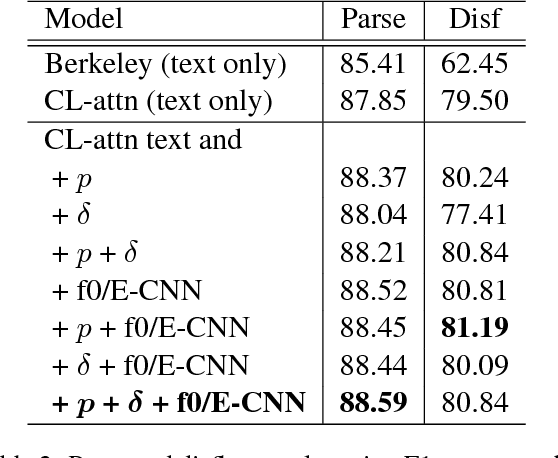
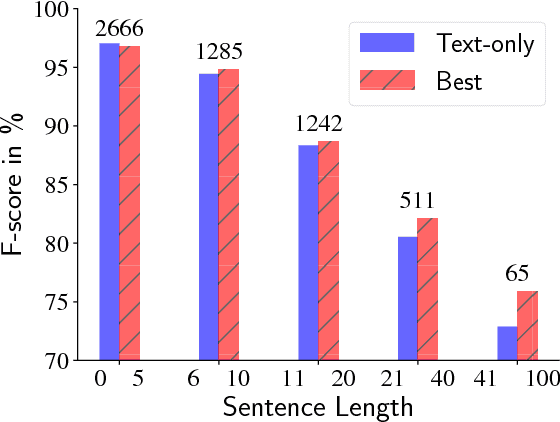
In conversational speech, the acoustic signal provides cues that help listeners disambiguate difficult parses. For automatically parsing spoken utterances, we introduce a model that integrates transcribed text and acoustic-prosodic features using a convolutional neural network over energy and pitch trajectories coupled with an attention-based recurrent neural network that accepts text and prosodic features. We find that different types of acoustic-prosodic features are individually helpful, and together give statistically significant improvements in parse and disfluency detection F1 scores over a strong text-only baseline. For this study with known sentence boundaries, error analyses show that the main benefit of acoustic-prosodic features is in sentences with disfluencies, attachment decisions are most improved, and transcription errors obscure gains from prosody.