 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevil in the Landscapes: Inferring Epidemic Exposure Risks from Street View Imagery
Nov 09, 2023



Built environment supports all the daily activities and shapes our health. Leveraging informative street view imagery, previous research has established the profound correlation between the built environment and chronic, non-communicable diseases; however, predicting the exposure risk of infectious diseases remains largely unexplored. The person-to-person contacts and interactions contribute to the complexity of infectious disease, which is inherently different from non-communicable diseases. Besides, the complex relationships between street view imagery and epidemic exposure also hinder accurate predictions. To address these problems, we construct a regional mobility graph informed by the gravity model, based on which we propose a transmission-aware graph convolutional network (GCN) to capture disease transmission patterns arising from human mobility. Experiments show that the proposed model significantly outperforms baseline models by 8.54% in weighted F1, shedding light on a low-cost, scalable approach to assess epidemic exposure risks from street view imagery.
FairComp: Workshop on Fairness and Robustness in Machine Learning for Ubiquitous Computing
Sep 22, 2023How can we ensure that Ubiquitous Computing (UbiComp) research outcomes are both ethical and fair? While fairness in machine learning (ML) has gained traction in recent years, fairness in UbiComp remains unexplored. This workshop aims to discuss fairness in UbiComp research and its social, technical, and legal implications. From a social perspective, we will examine the relationship between fairness and UbiComp research and identify pathways to ensure that ubiquitous technologies do not cause harm or infringe on individual rights. From a technical perspective, we will initiate a discussion on data practices to develop bias mitigation approaches tailored to UbiComp research. From a legal perspective, we will examine how new policies shape our community's work and future research. We aim to foster a vibrant community centered around the topic of responsible UbiComp, while also charting a clear path for future research endeavours in this field.
Cross-device Federated Learning for Mobile Health Diagnostics: A First Study on COVID-19 Detection
Mar 13, 2023



Federated learning (FL) aided health diagnostic models can incorporate data from a large number of personal edge devices (e.g., mobile phones) while keeping the data local to the originating devices, largely ensuring privacy. However, such a cross-device FL approach for health diagnostics still imposes many challenges due to both local data imbalance (as extreme as local data consists of a single disease class) and global data imbalance (the disease prevalence is generally low in a population). Since the federated server has no access to data distribution information, it is not trivial to solve the imbalance issue towards an unbiased model. In this paper, we propose FedLoss, a novel cross-device FL framework for health diagnostics. Here the federated server averages the models trained on edge devices according to the predictive loss on the local data, rather than using only the number of samples as weights. As the predictive loss better quantifies the data distribution at a device, FedLoss alleviates the impact of data imbalance. Through a real-world dataset on respiratory sound and symptom-based COVID-$19$ detection task, we validate the superiority of FedLoss. It achieves competitive COVID-$19$ detection performance compared to a centralised model with an AUC-ROC of $79\%$. It also outperforms the state-of-the-art FL baselines in sensitivity and convergence speed. Our work not only demonstrates the promise of federated COVID-$19$ detection but also paves the way to a plethora of mobile health model development in a privacy-preserving fashion.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022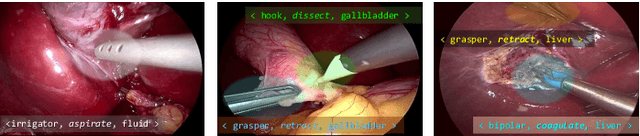

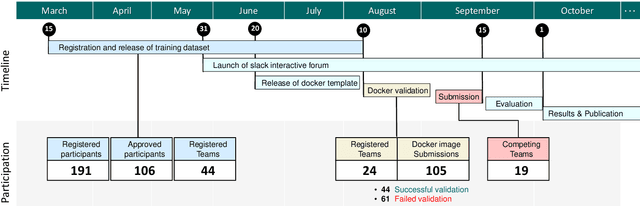
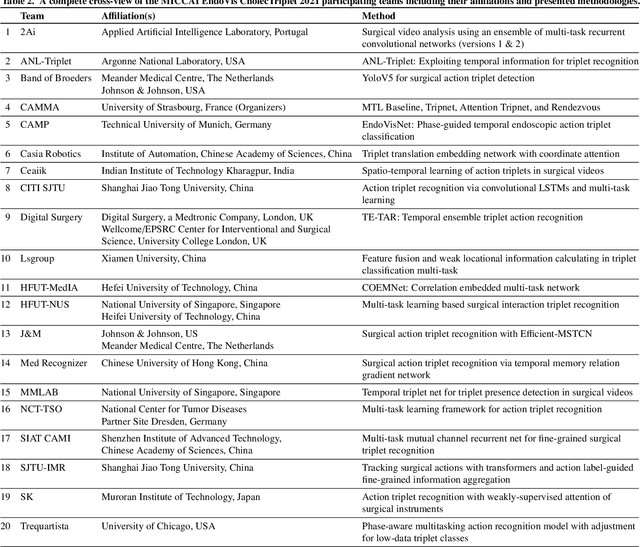
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022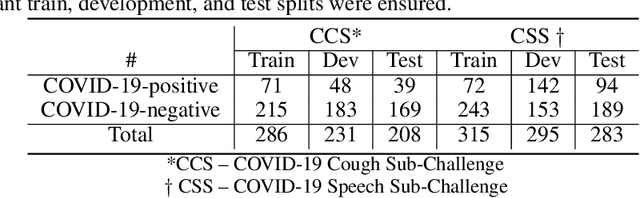
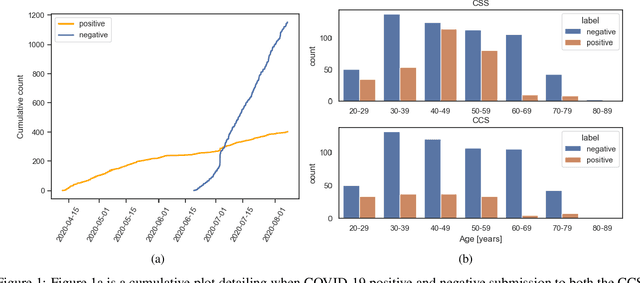
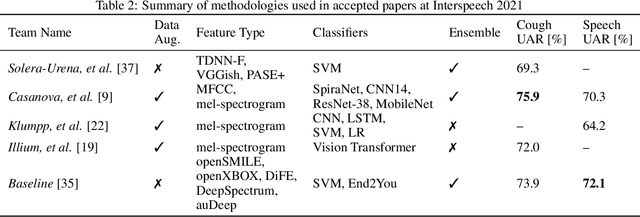
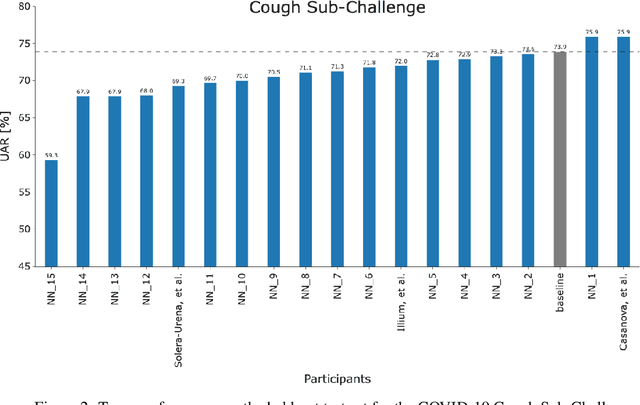
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
Benchmarking Uncertainty Quantification on Biosignal Classification Tasks under Dataset Shift
Jan 25, 2022
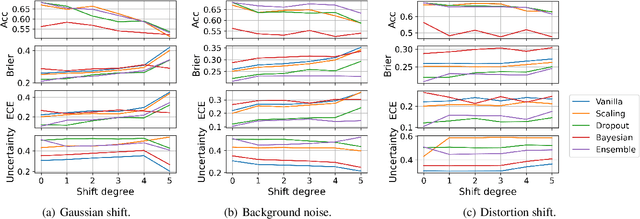
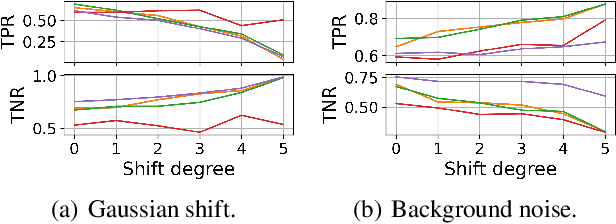
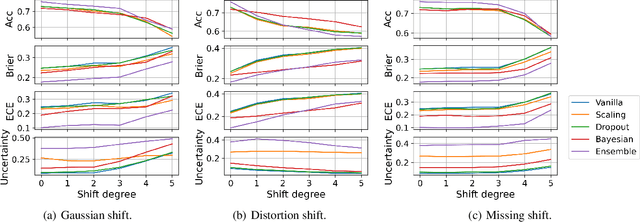
A biosignal is a signal that can be continuously measured from human bodies, such as respiratory sounds, heart activity (ECG), brain waves (EEG), etc, based on which, machine learning models have been developed with very promising performance for automatic disease detection and health status monitoring. However, dataset shift, i.e., data distribution of inference varies from the distribution of the training, is not uncommon for real biosignal-based applications. To improve the robustness, probabilistic models with uncertainty quantification are adapted to capture how reliable a prediction is. Yet, assessing the quality of the estimated uncertainty remains a challenge. In this work, we propose a framework to evaluate the capability of the estimated uncertainty in capturing different types of biosignal dataset shifts with various degrees. In particular, we use three classification tasks based on respiratory sounds and electrocardiography signals to benchmark five representative uncertainty quantification methods. Extensive experiments show that, although Ensemble and Bayesian models could provide relatively better uncertainty estimations under dataset shifts, all tested models fail to meet the promise in trustworthy prediction and model calibration. Our work paves the way for a comprehensive evaluation for any newly developed biosignal classifiers.
COVID-19 Disease Progression Prediction via Audio Signals: A Longitudinal Study
Jan 04, 2022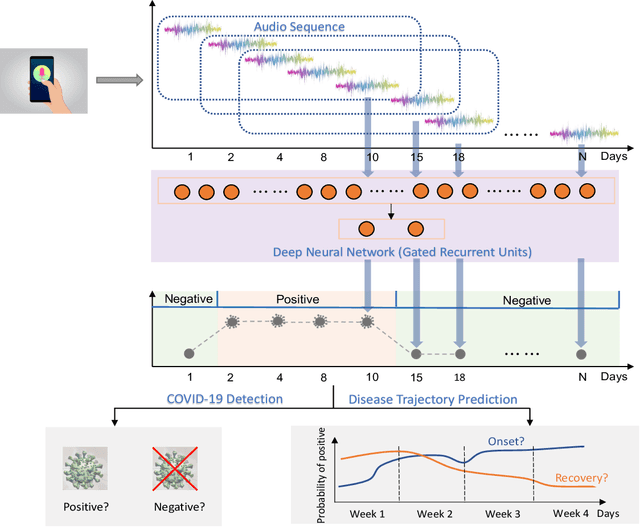
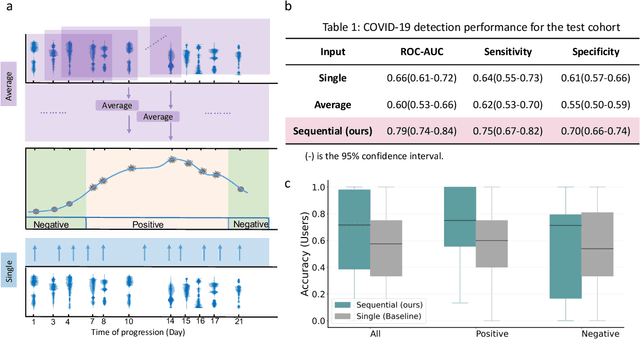
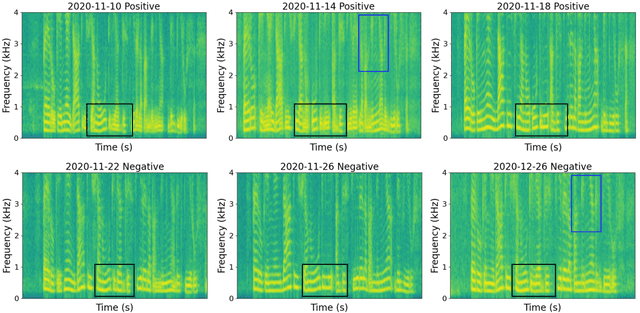
Recent work has shown the potential of the use of audio data in screening for COVID-19. However, very little exploration has been done of monitoring disease progression, especially recovery in COVID-19 through audio. Tracking disease progression characteristics and patterns of recovery could lead to tremendous insights and more timely treatment or treatment adjustment, as well as better resources management in health care systems. The primary objective of this study is to explore the potential of longitudinal audio dynamics for COVID-19 monitoring using sequential deep learning techniques, focusing on prediction of disease progression and, especially, recovery trend prediction. We analysed crowdsourced respiratory audio data from 212 individuals over 5 days to 385 days, alongside their self-reported COVID-19 test results. We first explore the benefits of capturing longitudinal dynamics of audio biomarkers for COVID-19 detection. The strong performance, yielding an AUC-ROC of 0.79, sensitivity of 0.75 and specificity of 0.70, supports the effectiveness of the approach compared to methods that do not leverage longitudinal dynamics. We further examine the predicted disease progression trajectory, which displays high consistency with the longitudinal test results with a correlation of 0.76 in the test cohort, and 0.86 in a subset of the test cohort with 12 participants who report disease recovery. Our findings suggest that monitoring COVID-19 progression via longitudinal audio data has enormous potential in the tracking of individuals' disease progression and recovery.
Comparative Validation of Machine Learning Algorithms for Surgical Workflow and Skill Analysis with the HeiChole Benchmark
Sep 30, 2021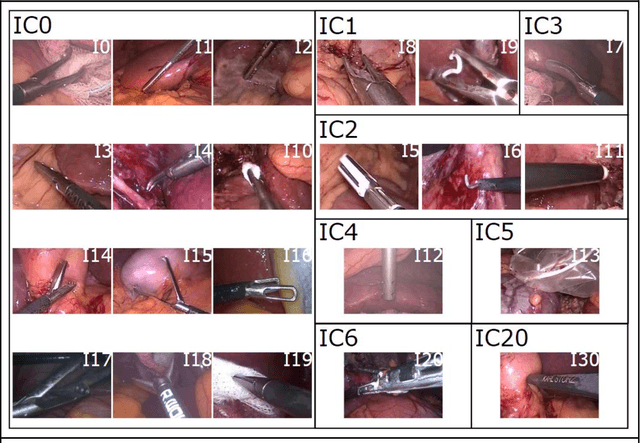
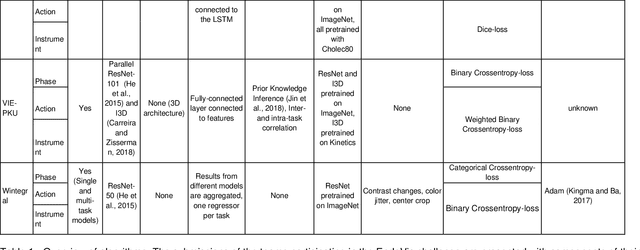
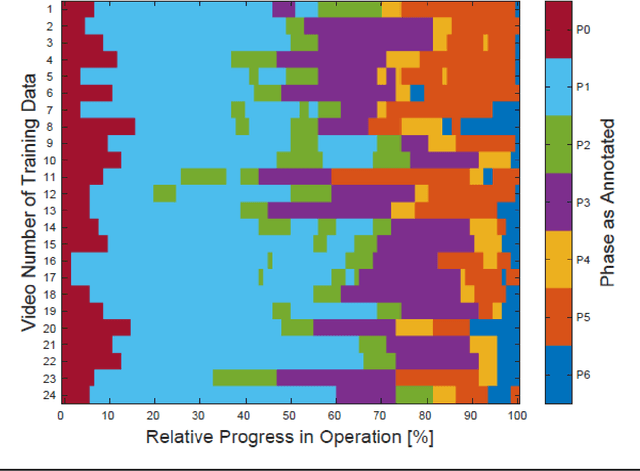
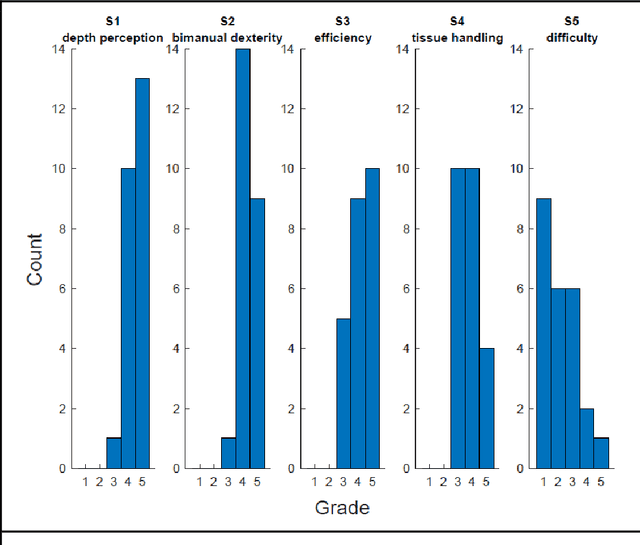
PURPOSE: Surgical workflow and skill analysis are key technologies for the next generation of cognitive surgical assistance systems. These systems could increase the safety of the operation through context-sensitive warnings and semi-autonomous robotic assistance or improve training of surgeons via data-driven feedback. In surgical workflow analysis up to 91% average precision has been reported for phase recognition on an open data single-center dataset. In this work we investigated the generalizability of phase recognition algorithms in a multi-center setting including more difficult recognition tasks such as surgical action and surgical skill. METHODS: To achieve this goal, a dataset with 33 laparoscopic cholecystectomy videos from three surgical centers with a total operation time of 22 hours was created. Labels included annotation of seven surgical phases with 250 phase transitions, 5514 occurences of four surgical actions, 6980 occurences of 21 surgical instruments from seven instrument categories and 495 skill classifications in five skill dimensions. The dataset was used in the 2019 Endoscopic Vision challenge, sub-challenge for surgical workflow and skill analysis. Here, 12 teams submitted their machine learning algorithms for recognition of phase, action, instrument and/or skill assessment. RESULTS: F1-scores were achieved for phase recognition between 23.9% and 67.7% (n=9 teams), for instrument presence detection between 38.5% and 63.8% (n=8 teams), but for action recognition only between 21.8% and 23.3% (n=5 teams). The average absolute error for skill assessment was 0.78 (n=1 team). CONCLUSION: Surgical workflow and skill analysis are promising technologies to support the surgical team, but are not solved yet, as shown by our comparison of algorithms. This novel benchmark can be used for comparable evaluation and validation of future work.
One-shot Transfer Learning for Population Mapping
Aug 17, 2021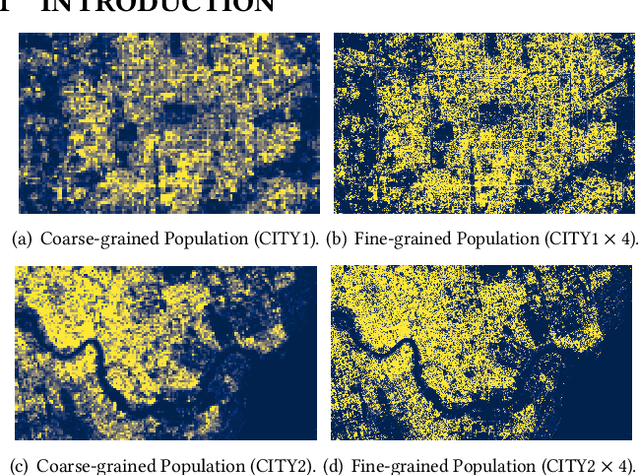
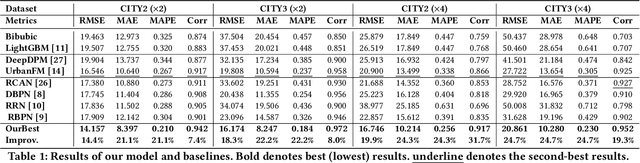
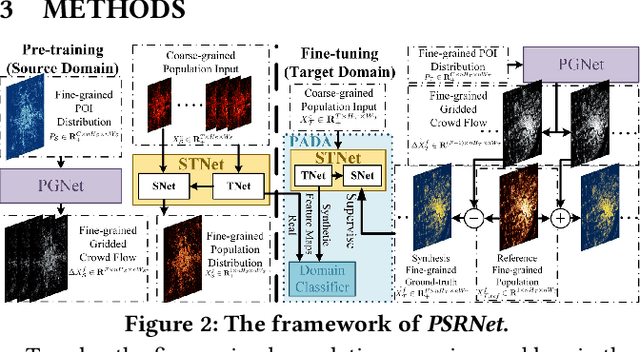
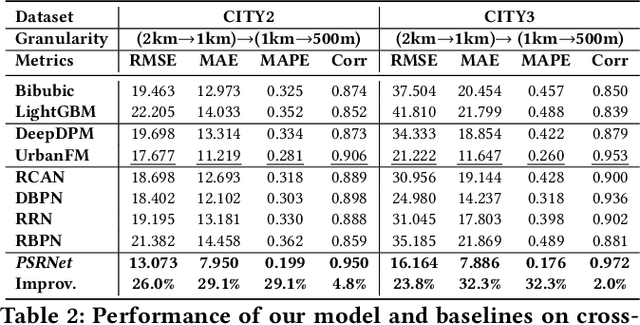
Fine-grained population distribution data is of great importance for many applications, e.g., urban planning, traffic scheduling, epidemic modeling, and risk control. However, due to the limitations of data collection, including infrastructure density, user privacy, and business security, such fine-grained data is hard to collect and usually, only coarse-grained data is available. Thus, obtaining fine-grained population distribution from coarse-grained distribution becomes an important problem. To tackle this problem, existing methods mainly rely on sufficient fine-grained ground truth for training, which is not often available for the majority of cities. That limits the applications of these methods and brings the necessity to transfer knowledge between data-sufficient source cities to data-scarce target cities. In knowledge transfer scenario, we employ single reference fine-grained ground truth in target city, which is easy to obtain via remote sensing or questionnaire, as the ground truth to inform the large-scale urban structure and support the knowledge transfer in target city. By this approach, we transform the fine-grained population mapping problem into a one-shot transfer learning problem. In this paper, we propose a novel one-shot transfer learning framework PSRNet to transfer spatial-temporal knowledge across cities from the view of network structure, the view of data, and the view of optimization. Experiments on real-life datasets of 4 cities demonstrate that PSRNet has significant advantages over 8 state-of-the-art baselines by reducing RMSE and MAE by more than 25%. Our code and datasets are released in Github (https://github.com/erzhuoshao/PSRNet-CIKM).
Deep Reinforcement Learning for Demand Driven Services in Logistics and Transportation Systems: A Survey
Aug 10, 2021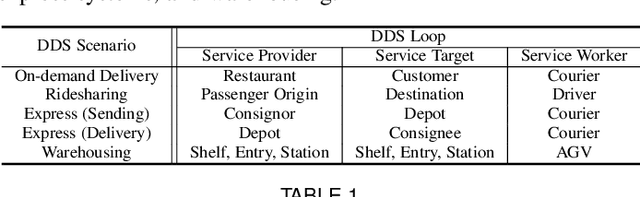
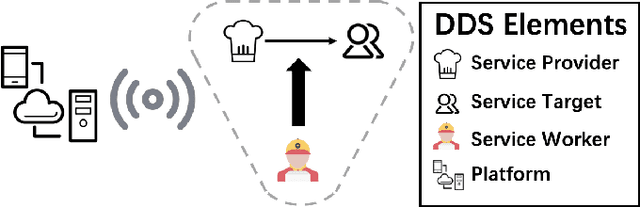
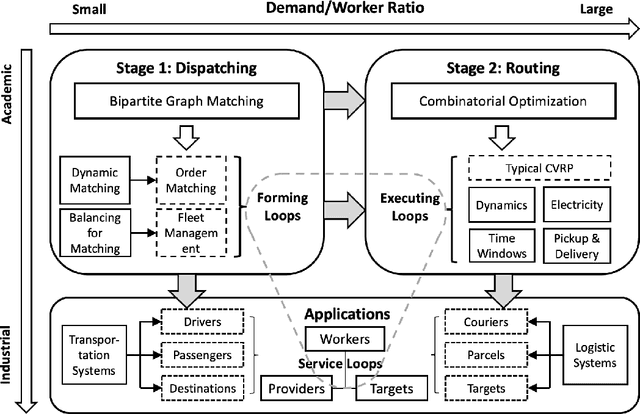
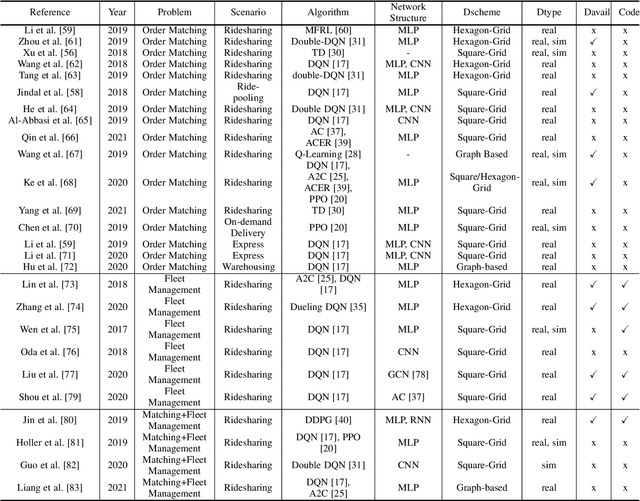
Recent technology development brings the booming of numerous new Demand-Driven Services (DDS) into urban lives, including ridesharing, on-demand delivery, express systems and warehousing. In DDS, a service loop is an elemental structure, including its service worker, the service providers and corresponding service targets. The service workers should transport either humans or parcels from the providers to the target locations. Various planning tasks within DDS can thus be classified into two individual stages: 1) Dispatching, which is to form service loops from demand/supply distributions, and 2)Routing, which is to decide specific serving orders within the constructed loops. Generating high-quality strategies in both stages is important to develop DDS but faces several challenging. Meanwhile, deep reinforcement learning (DRL) has been developed rapidly in recent years. It is a powerful tool to solve these problems since DRL can learn a parametric model without relying on too many problem-based assumptions and optimize long-term effect by learning sequential decisions. In this survey, we first define DDS, then highlight common applications and important decision/control problems within. For each problem, we comprehensively introduce the existing DRL solutions, and further summarize them in \textit{https://github.com/tsinghua-fib-lab/DDS\_Survey}. We also introduce open simulation environments for development and evaluation of DDS applications. Finally, we analyze remaining challenges and discuss further research opportunities in DRL solutions for DDS.