 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Bilingual Lexicons in Polyglot Word Embeddings
Aug 31, 2020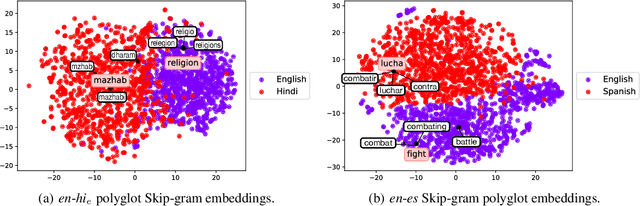


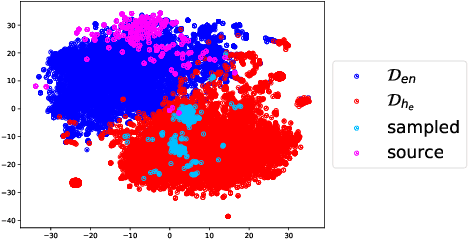
Bilingual lexicons and phrase tables are critical resources for modern Machine Translation systems. Although recent results show that without any seed lexicon or parallel data, highly accurate bilingual lexicons can be learned using unsupervised methods, such methods rely on the existence of large, clean monolingual corpora. In this work, we utilize a single Skip-gram model trained on a multilingual corpus yielding polyglot word embeddings, and present a novel finding that a surprisingly simple constrained nearest-neighbor sampling technique in this embedding space can retrieve bilingual lexicons, even in harsh social media data sets predominantly written in English and Romanized Hindi and often exhibiting code switching. Our method does not require monolingual corpora, seed lexicons, or any other such resources. Additionally, across three European language pairs, we observe that polyglot word embeddings indeed learn a rich semantic representation of words and substantial bilingual lexicons can be retrieved using our constrained nearest neighbor sampling. We investigate potential reasons and downstream applications in settings spanning both clean texts and noisy social media data sets, and in both resource-rich and under-resourced language pairs.
Towards Effective Human-AI Collaboration in GUI-Based Interactive Task Learning Agents
Mar 05, 2020
We argue that a key challenge in enabling usable and useful interactive task learning for intelligent agents is to facilitate effective Human-AI collaboration. We reflect on our past 5 years of efforts on designing, developing and studying the SUGILITE system, discuss the issues on incorporating recent advances in AI with HCI principles in mixed-initiative interactions and multi-modal interactions, and summarize the lessons we learned. Lastly, we identify several challenges and opportunities, and describe our ongoing work
Competence-based Curriculum Learning for Neural Machine Translation
Mar 26, 2019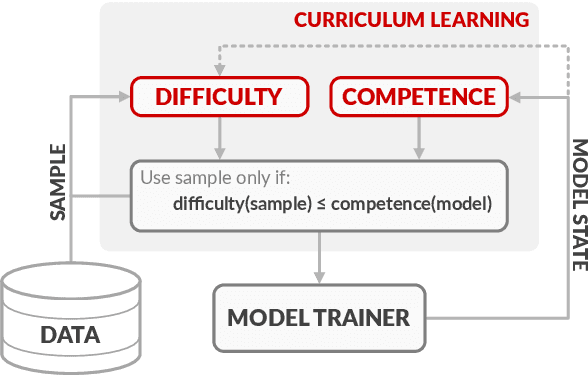

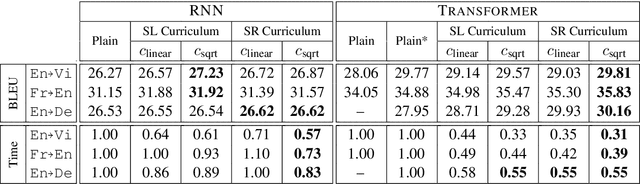
Current state-of-the-art NMT systems use large neural networks that are not only slow to train, but also often require many heuristics and optimization tricks, such as specialized learning rate schedules and large batch sizes. This is undesirable as it requires extensive hyperparameter tuning. In this paper, we propose a curriculum learning framework for NMT that reduces training time, reduces the need for specialized heuristics or large batch sizes, and results in overall better performance. Our framework consists of a principled way of deciding which training samples are shown to the model at different times during training, based on the estimated difficulty of a sample and the current competence of the model. Filtering training samples in this manner prevents the model from getting stuck in bad local optima, making it converge faster and reach a better solution than the common approach of uniformly sampling training examples. Furthermore, the proposed method can be easily applied to existing NMT models by simply modifying their input data pipelines. We show that our framework can help improve the training time and the performance of both recurrent neural network models and Transformers, achieving up to a 70% decrease in training time, while at the same time obtaining accuracy improvements of up to 2.2 BLEU.
Discourse in Multimedia: A Case Study in Information Extraction
Nov 13, 2018
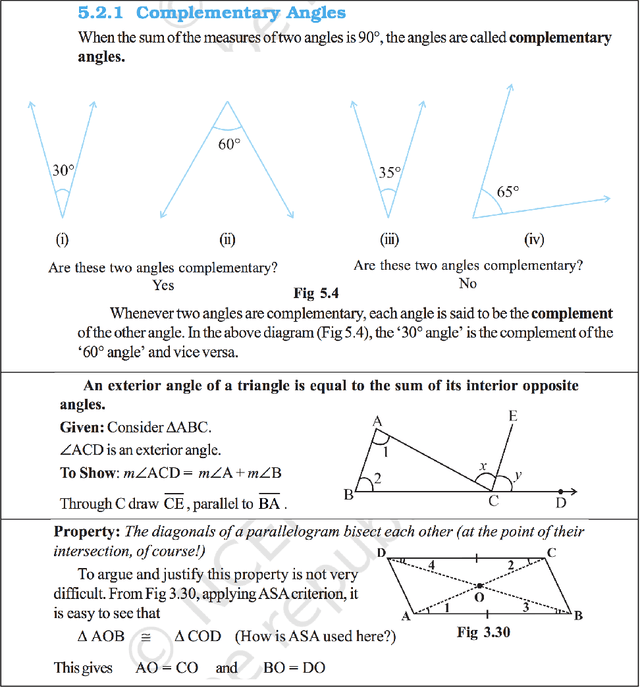
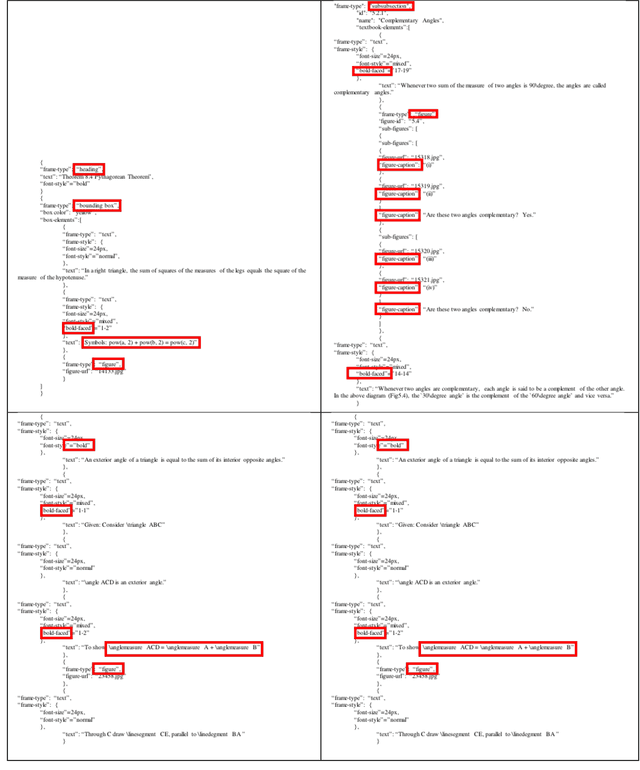
To ensure readability, text is often written and presented with due formatting. These text formatting devices help the writer to effectively convey the narrative. At the same time, these help the readers pick up the structure of the discourse and comprehend the conveyed information. There have been a number of linguistic theories on discourse structure of text. However, these theories only consider unformatted text. Multimedia text contains rich formatting features which can be leveraged for various NLP tasks. In this paper, we study some of these discourse features in multimedia text and what communicative function they fulfil in the context. We examine how these multimedia discourse features can be used to improve an information extraction system. We show that the discourse and text layout features provide information that is complementary to lexical semantic information commonly used for information extraction. As a case study, we use these features to harvest structured subject knowledge of geometry from textbooks. We show that the harvested structured knowledge can be used to improve an existing solver for geometry problems, making it more accurate as well as more explainable.
Estimating Accuracy from Unlabeled Data: A Probabilistic Logic Approach
May 19, 2017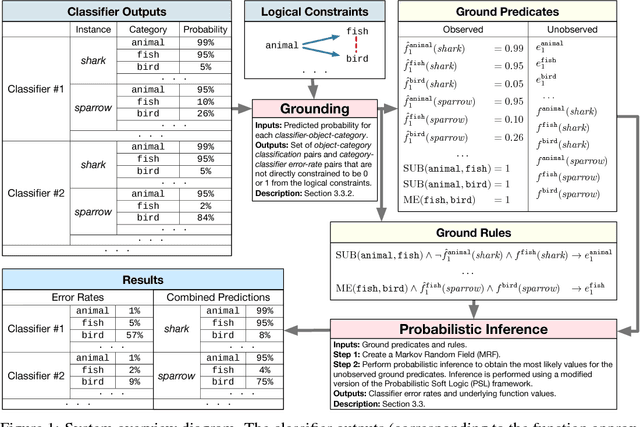
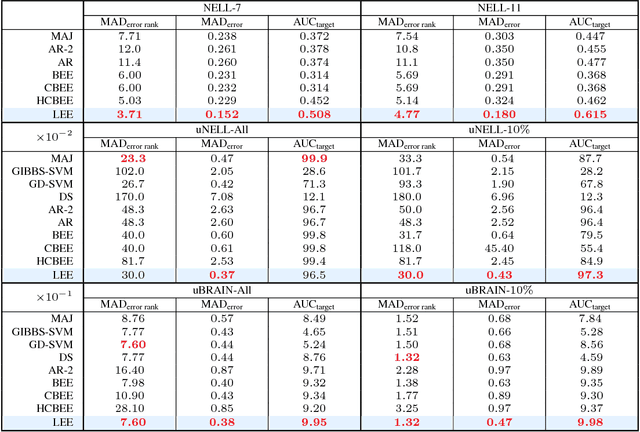

We propose an efficient method to estimate the accuracy of classifiers using only unlabeled data. We consider a setting with multiple classification problems where the target classes may be tied together through logical constraints. For example, a set of classes may be mutually exclusive, meaning that a data instance can belong to at most one of them. The proposed method is based on the intuition that: (i) when classifiers agree, they are more likely to be correct, and (ii) when the classifiers make a prediction that violates the constraints, at least one classifier must be making an error. Experiments on four real-world data sets produce accuracy estimates within a few percent of the true accuracy, using solely unlabeled data. Our models also outperform existing state-of-the-art solutions in both estimating accuracies, and combining multiple classifier outputs. The results emphasize the utility of logical constraints in estimating accuracy, thus validating our intuition.
Machine Reading with Background Knowledge
Dec 16, 2016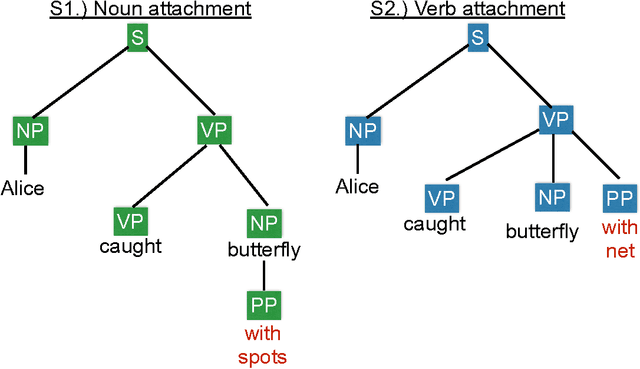
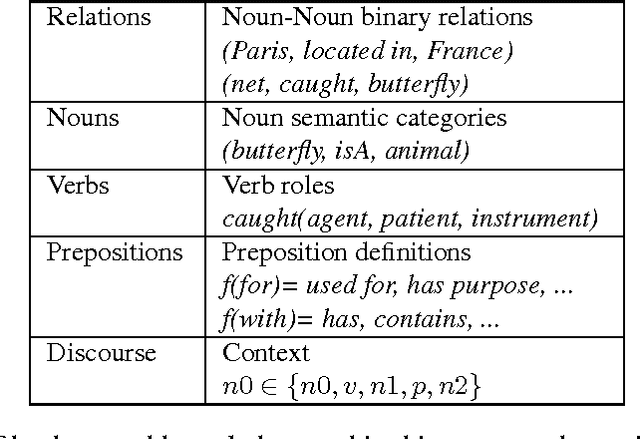
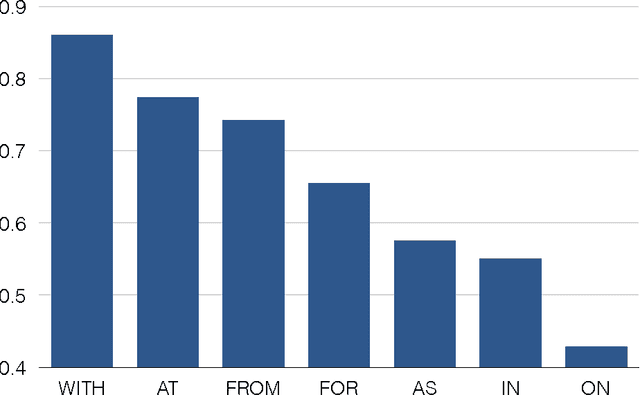
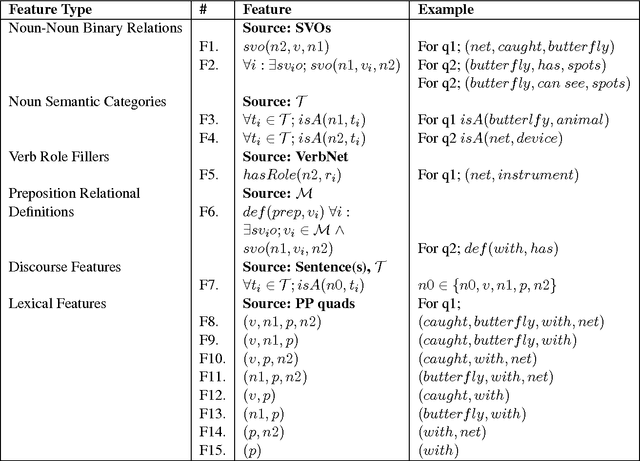
Intelligent systems capable of automatically understanding natural language text are important for many artificial intelligence applications including mobile phone voice assistants, computer vision, and robotics. Understanding language often constitutes fitting new information into a previously acquired view of the world. However, many machine reading systems rely on the text alone to infer its meaning. In this paper, we pursue a different approach; machine reading methods that make use of background knowledge to facilitate language understanding. To this end, we have developed two methods: The first method addresses prepositional phrase attachment ambiguity. It uses background knowledge within a semi-supervised machine learning algorithm that learns from both labeled and unlabeled data. This approach yields state-of-the-art results on two datasets against strong baselines; The second method extracts relationships from compound nouns. Our knowledge-aware method for compound noun analysis accurately extracts relationships and significantly outperforms a baseline that does not make use of background knowledge.
A Probabilistic Generative Grammar for Semantic Parsing
Jun 20, 2016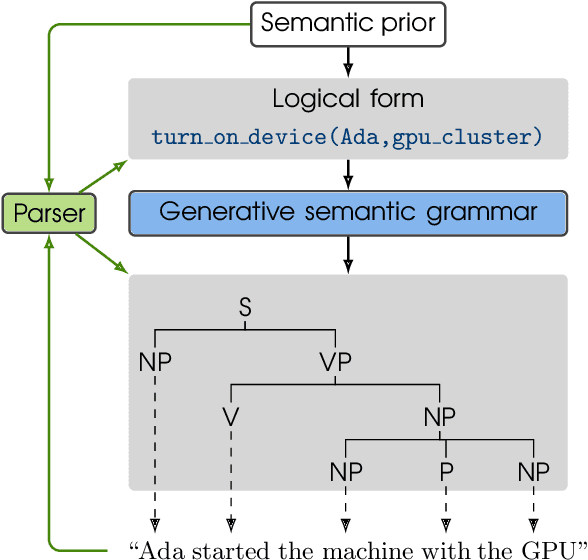

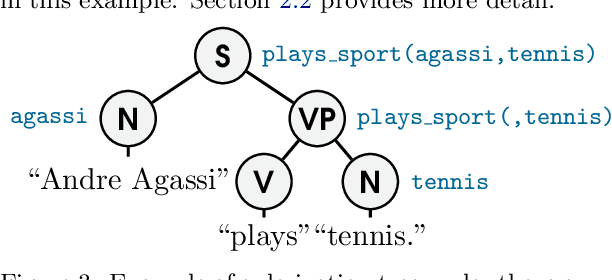
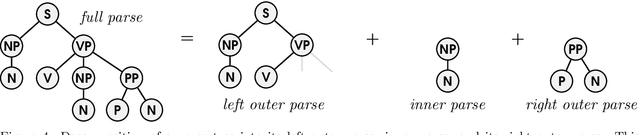
We present a framework that couples the syntax and semantics of natural language sentences in a generative model, in order to develop a semantic parser that jointly infers the syntactic, morphological, and semantic representations of a given sentence under the guidance of background knowledge. To generate a sentence in our framework, a semantic statement is first sampled from a prior, such as from a set of beliefs in a knowledge base. Given this semantic statement, a grammar probabilistically generates the output sentence. A joint semantic-syntactic parser is derived that returns the $k$-best semantic and syntactic parses for a given sentence. The semantic prior is flexible, and can be used to incorporate background knowledge during parsing, in ways unlike previous semantic parsing approaches. For example, semantic statements corresponding to beliefs in a knowledge base can be given higher prior probability, type-correct statements can be given somewhat lower probability, and beliefs outside the knowledge base can be given lower probability. The construction of our grammar invokes a novel application of hierarchical Dirichlet processes (HDPs), which in turn, requires a novel and efficient inference approach. We present experimental results showing, for a simple grammar, that our parser outperforms a state-of-the-art CCG semantic parser and scales to knowledge bases with millions of beliefs.
Scoup-SMT: Scalable Coupled Sparse Matrix-Tensor Factorization
Feb 28, 2013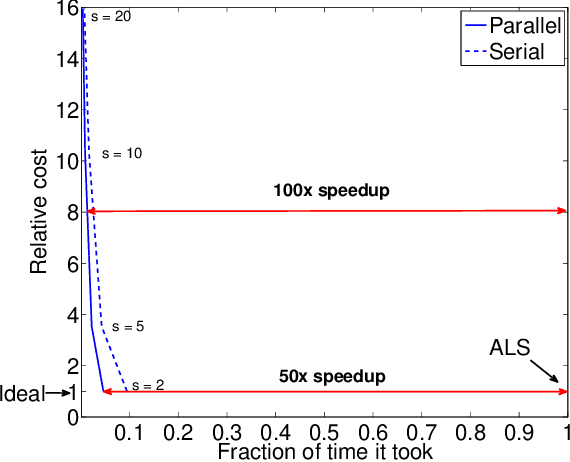
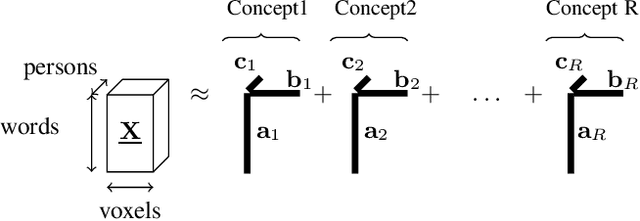
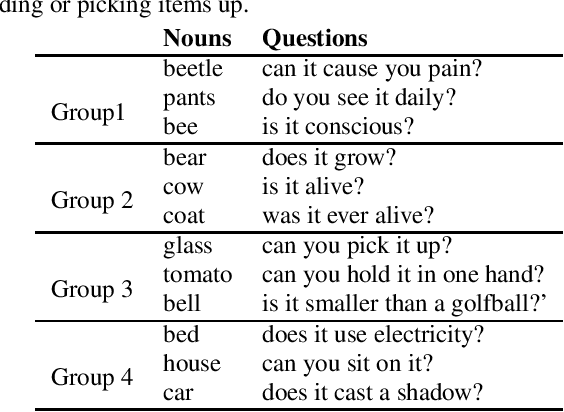
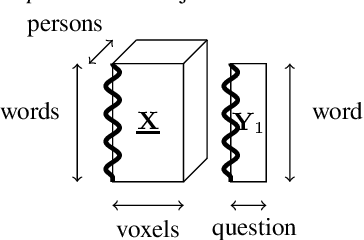
How can we correlate neural activity in the human brain as it responds to words, with behavioral data expressed as answers to questions about these same words? In short, we want to find latent variables, that explain both the brain activity, as well as the behavioral responses. We show that this is an instance of the Coupled Matrix-Tensor Factorization (CMTF) problem. We propose Scoup-SMT, a novel, fast, and parallel algorithm that solves the CMTF problem and produces a sparse latent low-rank subspace of the data. In our experiments, we find that Scoup-SMT is 50-100 times faster than a state-of-the-art algorithm for CMTF, along with a 5 fold increase in sparsity. Moreover, we extend Scoup-SMT to handle missing data without degradation of performance. We apply Scoup-SMT to BrainQ, a dataset consisting of a (nouns, brain voxels, human subjects) tensor and a (nouns, properties) matrix, with coupling along the nouns dimension. Scoup-SMT is able to find meaningful latent variables, as well as to predict brain activity with competitive accuracy. Finally, we demonstrate the generality of Scoup-SMT, by applying it on a Facebook dataset (users, friends, wall-postings); there, Scoup-SMT spots spammer-like anomalies.