 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Sound Concepts and Acoustic Relations In Text
Feb 13, 2017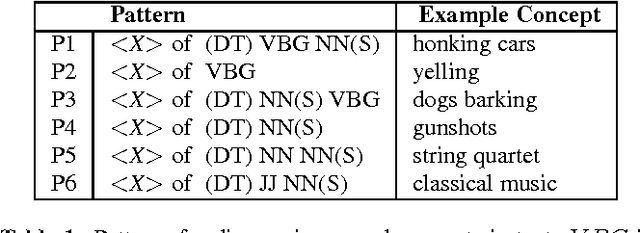


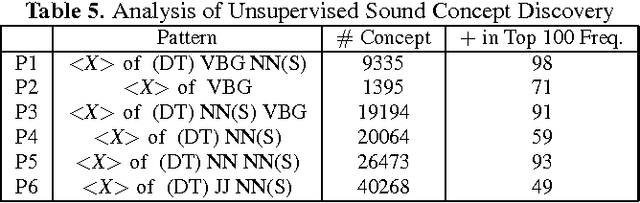
In this paper we describe approaches for discovering acoustic concepts and relations in text. The first major goal is to be able to identify text phrases which contain a notion of audibility and can be termed as a sound or an acoustic concept. We also propose a method to define an acoustic scene through a set of sound concepts. We use pattern matching and parts of speech tags to generate sound concepts from large scale text corpora. We use dependency parsing and LSTM recurrent neural network to predict a set of sound concepts for a given acoustic scene. These methods are not only helpful in creating an acoustic knowledge base but in the future can also directly help acoustic event and scene detection research.
Machine Reading with Background Knowledge
Dec 16, 2016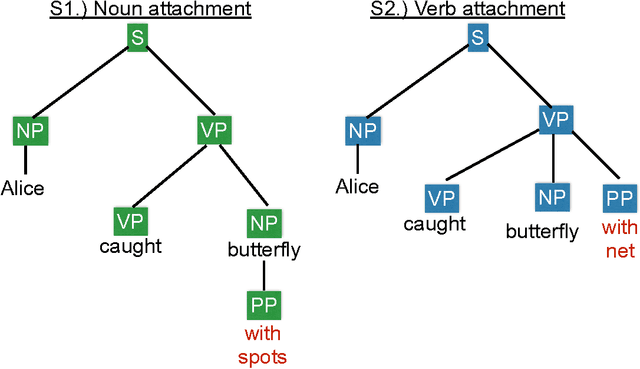
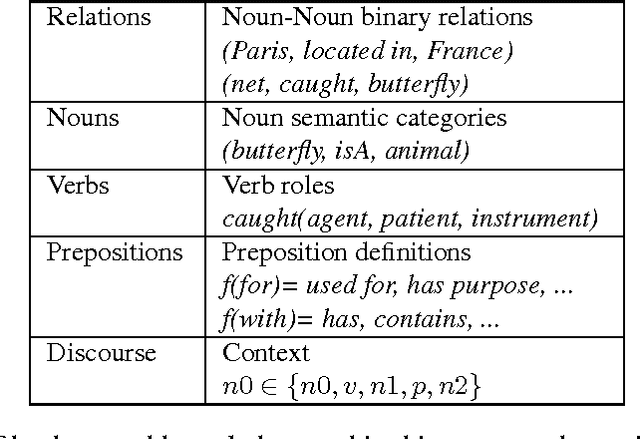
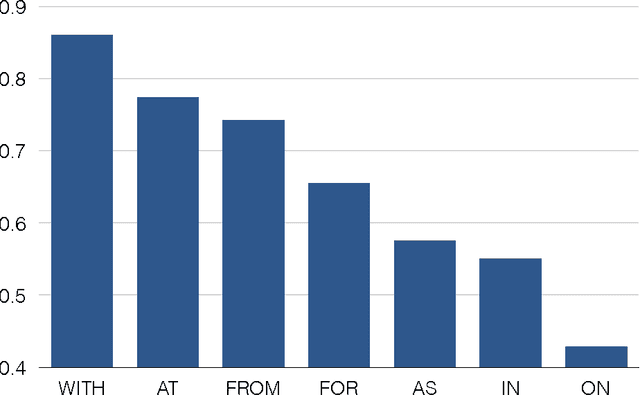
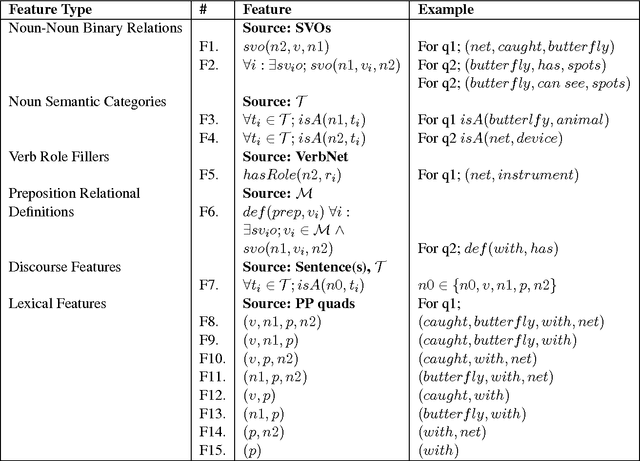
Intelligent systems capable of automatically understanding natural language text are important for many artificial intelligence applications including mobile phone voice assistants, computer vision, and robotics. Understanding language often constitutes fitting new information into a previously acquired view of the world. However, many machine reading systems rely on the text alone to infer its meaning. In this paper, we pursue a different approach; machine reading methods that make use of background knowledge to facilitate language understanding. To this end, we have developed two methods: The first method addresses prepositional phrase attachment ambiguity. It uses background knowledge within a semi-supervised machine learning algorithm that learns from both labeled and unlabeled data. This approach yields state-of-the-art results on two datasets against strong baselines; The second method extracts relationships from compound nouns. Our knowledge-aware method for compound noun analysis accurately extracts relationships and significantly outperforms a baseline that does not make use of background knowledge.
An Operator for Entity Extraction in MapReduce
Dec 15, 2015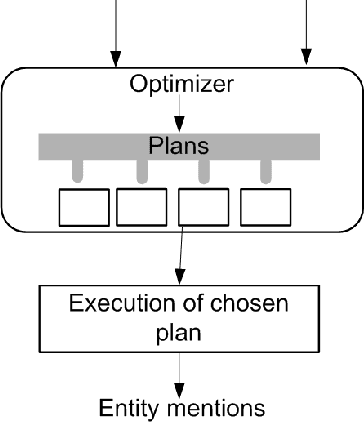



Dictionary-based entity extraction involves finding mentions of dictionary entities in text. Text mentions are often noisy, containing spurious or missing words. Efficient algorithms for detecting approximate entity mentions follow one of two general techniques. The first approach is to build an index on the entities and perform index lookups of document substrings. The second approach recognizes that the number of substrings generated from documents can explode to large numbers, to get around this, they use a filter to prune many such substrings which do not match any dictionary entity and then only verify the remaining substrings if they are entity mentions of dictionary entities, by means of a text join. The choice between the index-based approach and the filter & verification-based approach is a case-to-case decision as the best approach depends on the characteristics of the input entity dictionary, for example frequency of entity mentions. Choosing the right approach for the setting can make a substantial difference in execution time. Making this choice is however non-trivial as there are parameters within each of the approaches that make the space of possible approaches very large. In this paper, we present a cost-based operator for making the choice among execution plans for entity extraction. Since we need to deal with large dictionaries and even larger large datasets, our operator is developed for implementations of MapReduce distributed algorithms.
Bootstrapping Ternary Relation Extractors
Nov 29, 2015
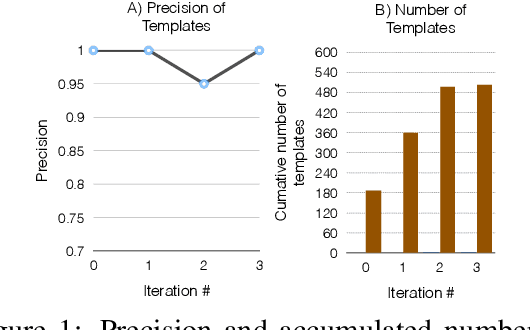
Binary relation extraction methods have been widely studied in recent years. However, few methods have been developed for higher n-ary relation extraction. One limiting factor is the effort required to generate training data. For binary relations, one only has to provide a few dozen pairs of entities per relation, as training data. For ternary relations (n=3), each training instance is a triplet of entities, placing a greater cognitive load on people. For example, many people know that Google acquired Youtube but not the dollar amount or the date of the acquisition and many people know that Hillary Clinton is married to Bill Clinton by not the location or date of their wedding. This makes higher n-nary training data generation a time consuming exercise in searching the Web. We present a resource for training ternary relation extractors. This was generated using a minimally supervised yet effective approach. We present statistics on the size and the quality of the dataset.