 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Face Naming with Symmetry-Enhanced Contrastive Loss
Oct 17, 2022
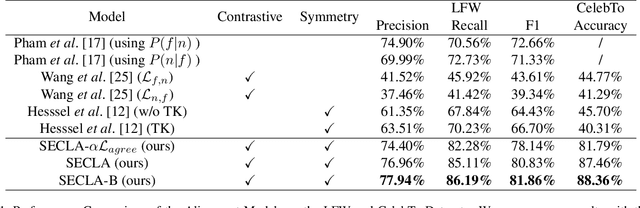
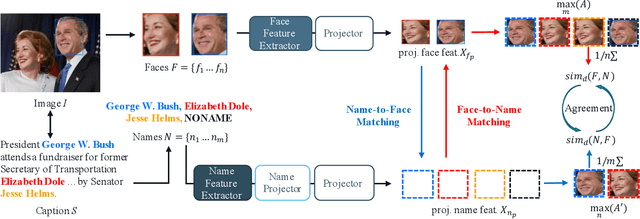
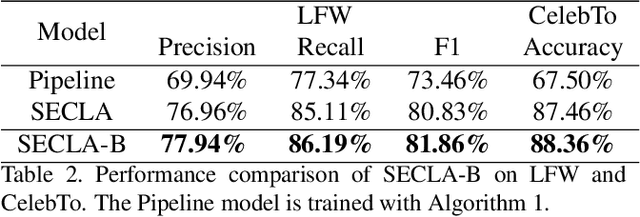
We revisit the weakly supervised cross-modal face-name alignment task; that is, given an image and a caption, we label the faces in the image with the names occurring in the caption. Whereas past approaches have learned the latent alignment between names and faces by uncertainty reasoning over a set of images and their respective captions, in this paper, we rely on appropriate loss functions to learn the alignments in a neural network setting and propose SECLA and SECLA-B. SECLA is a Symmetry-Enhanced Contrastive Learning-based Alignment model that can effectively maximize the similarity scores between corresponding faces and names in a weakly supervised fashion. A variation of the model, SECLA-B, learns to align names and faces as humans do, that is, learning from easy to hard cases to further increase the performance of SECLA. More specifically, SECLA-B applies a two-stage learning framework: (1) Training the model on an easy subset with a few names and faces in each image-caption pair. (2) Leveraging the known pairs of names and faces from the easy cases using a bootstrapping strategy with additional loss to prevent forgetting and learning new alignments at the same time. We achieve state-of-the-art results for both the augmented Labeled Faces in the Wild dataset and the Celebrity Together dataset. In addition, we believe that our methods can be adapted to other multimodal news understanding tasks.
Students taught by multimodal teachers are superior action recognizers
Oct 09, 2022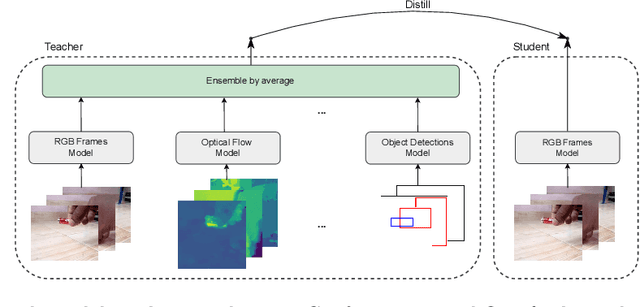

The focal point of egocentric video understanding is modelling hand-object interactions. Standard models -- CNNs, Vision Transformers, etc. -- which receive RGB frames as input perform well, however, their performance improves further by employing additional modalities such as object detections, optical flow, audio, etc. as input. The added complexity of the required modality-specific modules, on the other hand, makes these models impractical for deployment. The goal of this work is to retain the performance of such multimodal approaches, while using only the RGB images as input at inference time. Our approach is based on multimodal knowledge distillation, featuring a multimodal teacher (in the current experiments trained only using object detections, optical flow and RGB frames) and a unimodal student (using only RGB frames as input). We present preliminary results which demonstrate that the resulting model -- distilled from a multimodal teacher -- significantly outperforms the baseline RGB model (trained without knowledge distillation), as well as an omnivorous version of itself (trained on all modalities jointly), in both standard and compositional action recognition.
CLAD: A realistic Continual Learning benchmark for Autonomous Driving
Oct 07, 2022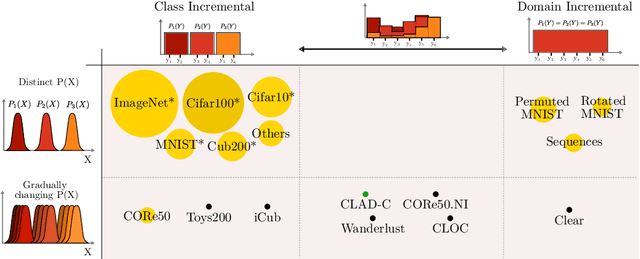

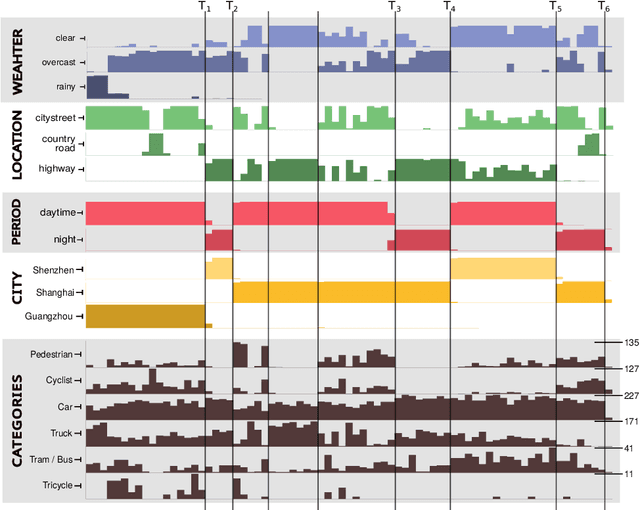
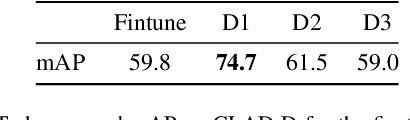
In this paper we describe the design and the ideas motivating a new Continual Learning benchmark for Autonomous Driving (CLAD), that focuses on the problems of object classification and object detection. The benchmark utilises SODA10M, a recently released large-scale dataset that concerns autonomous driving related problems. First, we review and discuss existing continual learning benchmarks, how they are related, and show that most are extreme cases of continual learning. To this end, we survey the benchmarks used in continual learning papers at three highly ranked computer vision conferences. Next, we introduce CLAD-C, an online classification benchmark realised through a chronological data stream that poses both class and domain incremental challenges; and CLAD-D, a domain incremental continual object detection benchmark. We examine the inherent difficulties and challenges posed by the benchmark, through a survey of the techniques and methods used by the top-3 participants in a CLAD-challenge workshop at ICCV 2021. We conclude with possible pathways to improve the current continual learning state of the art, and which directions we deem promising for future research.
FQDet: Fast-converging Query-based Detector
Oct 05, 2022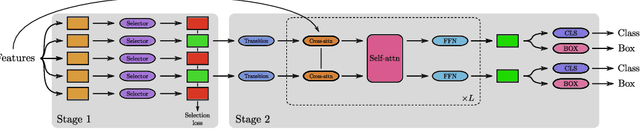
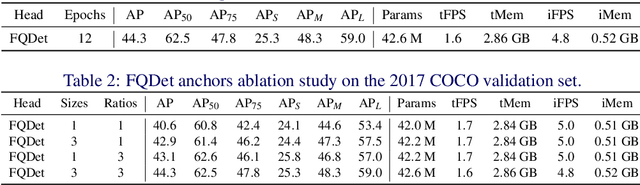
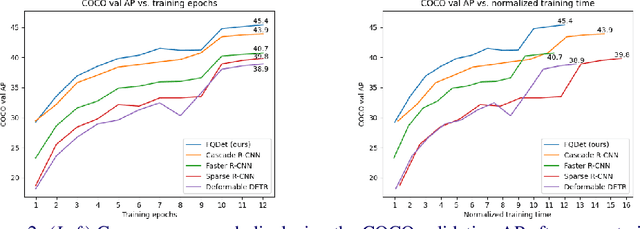

Recently, two-stage Deformable DETR introduced the query-based two-stage head, a new type of two-stage head different from the region-based two-stage heads of classical detectors as Faster R-CNN. In query-based two-stage heads, the second stage selects one feature per detection, called the query, as opposed to pooling a rectangular grid of features as in region-based detectors. In this work, we further improve the query-based head from Deformable DETR, significantly speeding up the convergence while increasing its performance. This is achieved by incorporating classical techniques such as anchor generation within the query-based paradigm. By combining the best of both the classical and the query-based worlds, our FQDet head peaks at 45.4 AP on the 2017 COCO validation set when using a ResNet-50+TPN backbone, only after training for 12 epochs using the 1x schedule. We outperform other high-performing two-stage heads such as e.g. Cascade R-CNN, while using the same backbone and while often being computationally cheaper. Additionally, when using the large ResNeXt-101-DCN+TPN backbone and multi-scale testing, our FQDet head achieves 52.9 AP on the 2017 COCO test-dev set after only 12 epochs of training. Code will be released.
Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation
Aug 16, 2022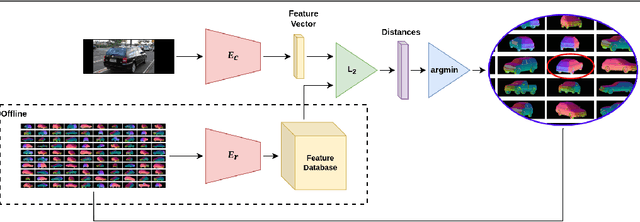
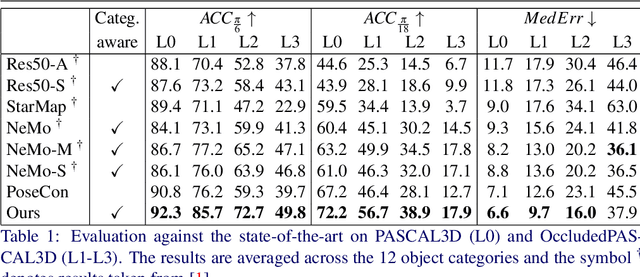

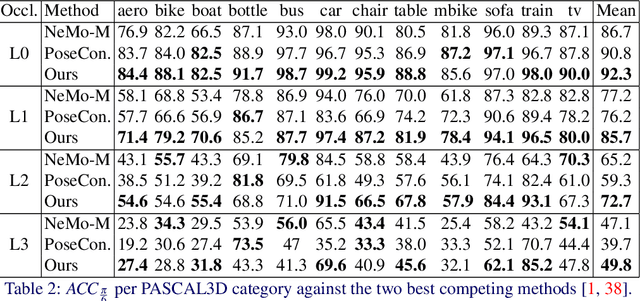
Pose estimation is usually tackled as either a bin classification problem or as a regression problem. In both cases, the idea is to directly predict the pose of an object. This is a non-trivial task because of appearance variations of similar poses and similarities between different poses. Instead, we follow the key idea that it is easier to compare two poses than to estimate them. Render-and-compare approaches have been employed to that end, however, they tend to be unstable, computationally expensive, and slow for real-time applications. We propose doing category-level pose estimation by learning an alignment metric using a contrastive loss with a dynamic margin and a continuous pose-label space. For efficient inference, we use a simple real-time image retrieval scheme with a reference set of renderings projected to an embedding space. To achieve robustness to real-world conditions, we employ synthetic occlusions, bounding box perturbations, and appearance augmentations. Our approach achieves state-of-the-art performance on PASCAL3D and OccludedPASCAL3D, as well as high-quality results on KITTI3D.
Global-Local Self-Distillation for Visual Representation Learning
Jul 29, 2022
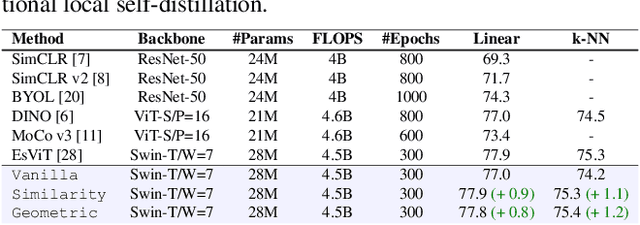

The downstream accuracy of self-supervised methods is tightly linked to the proxy task solved during training and the quality of the gradients extracted from it. Richer and more meaningful gradients updates are key to allow self-supervised methods to learn better and in a more efficient manner. In a typical self-distillation framework, the representation of two augmented images are enforced to be coherent at the global level. Nonetheless, incorporating local cues in the proxy task can be beneficial and improve the model accuracy on downstream tasks. This leads to a dual objective in which, on the one hand, coherence between global-representations is enforced and on the other, coherence between local-representations is enforced. Unfortunately, an exact correspondence mapping between two sets of local-representations does not exist making the task of matching local-representations from one augmentation to another non-trivial. We propose to leverage the spatial information in the input images to obtain geometric matchings and compare this geometric approach against previous methods based on similarity matchings. Our study shows that not only 1) geometric matchings perform better than similarity based matchings in low-data regimes but also 2) that similarity based matchings are highly hurtful in low-data regimes compared to the vanilla baseline without local self-distillation. The code will be released upon acceptance.
MPC-based Imitation Learning for Safe and Human-like Autonomous Driving
Jun 24, 2022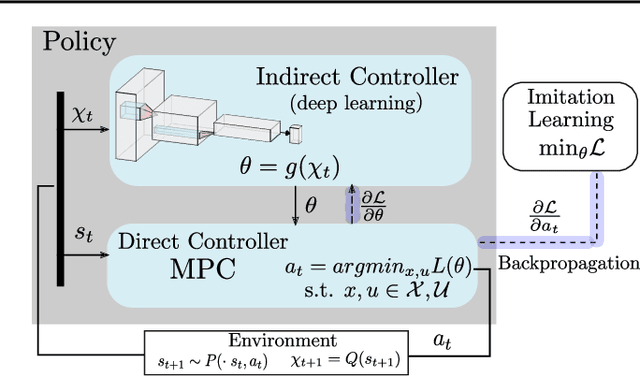
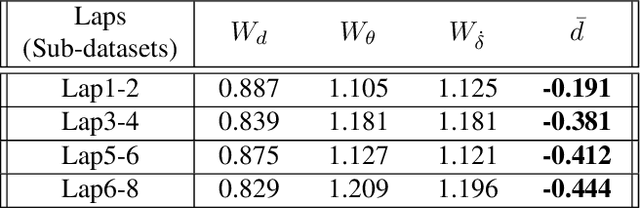
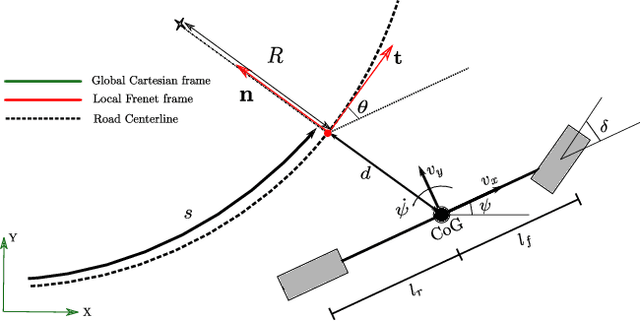
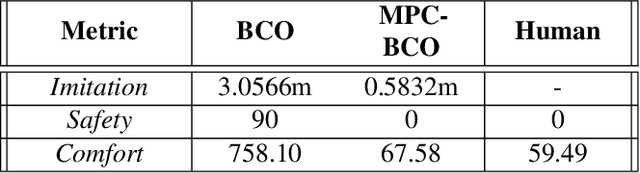
To ensure user acceptance of autonomous vehicles (AVs), control systems are being developed to mimic human drivers from demonstrations of desired driving behaviors. Imitation learning (IL) algorithms serve this purpose, but struggle to provide safety guarantees on the resulting closed-loop system trajectories. On the other hand, Model Predictive Control (MPC) can handle nonlinear systems with safety constraints, but realizing human-like driving with it requires extensive domain knowledge. This work suggests the use of a seamless combination of the two techniques to learn safe AV controllers from demonstrations of desired driving behaviors, by using MPC as a differentiable control layer within a hierarchical IL policy. With this strategy, IL is performed in closed-loop and end-to-end, through parameters in the MPC cost, model or constraints. Experimental results of this methodology are analyzed for the design of a lane keeping control system, learned via behavioral cloning from observations (BCO), given human demonstrations on a fixed-base driving simulator.
Continual evaluation for lifelong learning: Identifying the stability gap
May 26, 2022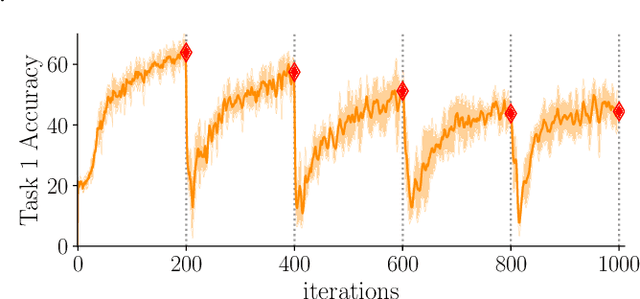
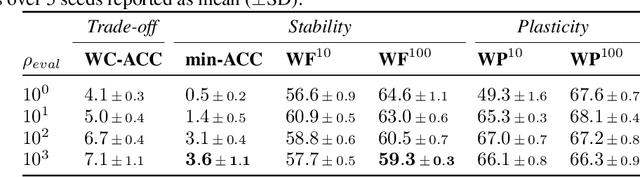
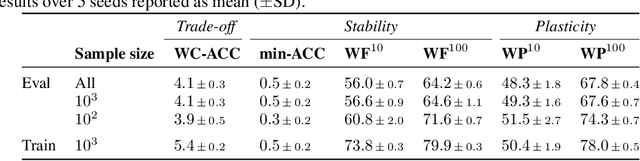
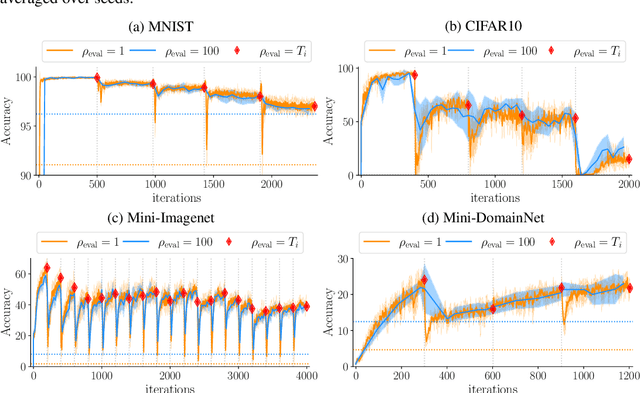
Introducing a time dependency on the data generating distribution has proven to be difficult for gradient-based training of neural networks, as the greedy updates result in catastrophic forgetting of previous timesteps. Continual learning aims to overcome the greedy optimization to enable continuous accumulation of knowledge over time. The data stream is typically divided into locally stationary distributions, called tasks, allowing task-based evaluation on held-out data from the training tasks. Contemporary evaluation protocols and metrics in continual learning are task-based and quantify the trade-off between stability and plasticity only at task transitions. However, our empirical evidence suggests that between task transitions significant, temporary forgetting can occur, remaining unidentified in task-based evaluation. Therefore, we propose a framework for continual evaluation that establishes per-iteration evaluation and define a new set of metrics that enables identifying the worst-case performance of the learner over its lifetime. Performing continual evaluation, we empirically identify that replay suffers from a stability gap: upon learning a new task, there is a substantial but transient decrease in performance on past tasks. Further conceptual and empirical analysis suggests not only replay-based, but also regularization-based continual learning methods are prone to the stability gap.
Continual Pre-Training Mitigates Forgetting in Language and Vision
May 19, 2022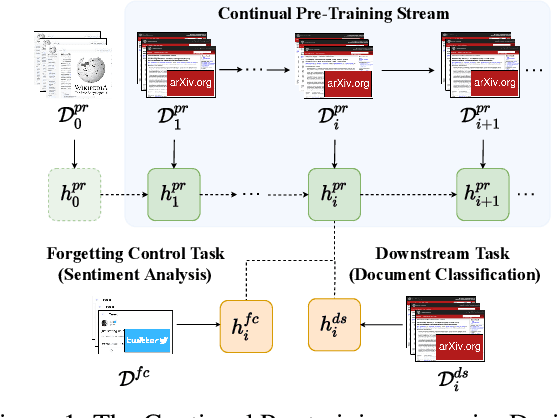
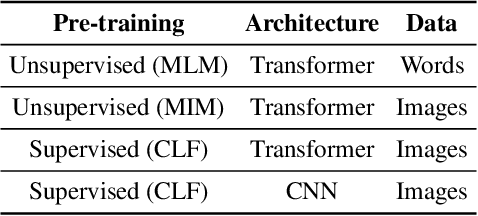
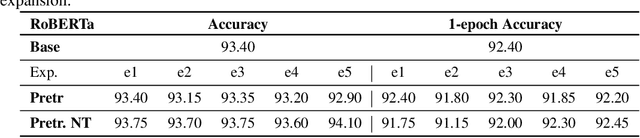
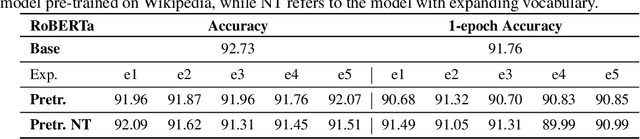
Pre-trained models are nowadays a fundamental component of machine learning research. In continual learning, they are commonly used to initialize the model before training on the stream of non-stationary data. However, pre-training is rarely applied during continual learning. We formalize and investigate the characteristics of the continual pre-training scenario in both language and vision environments, where a model is continually pre-trained on a stream of incoming data and only later fine-tuned to different downstream tasks. We show that continually pre-trained models are robust against catastrophic forgetting and we provide strong empirical evidence supporting the fact that self-supervised pre-training is more effective in retaining previous knowledge than supervised protocols. Code is provided at https://github.com/AndreaCossu/continual-pretraining-nlp-vision .
Re-examining Distillation For Continual Object Detection
Apr 04, 2022
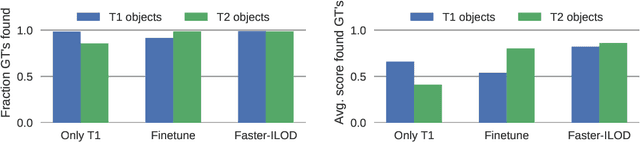


Training models continually to detect and classify objects, from new classes and new domains, remains an open problem. In this work, we conduct a thorough analysis of why and how object detection models forget catastrophically. We focus on distillation-based approaches in two-stage networks; the most-common strategy employed in contemporary continual object detection work.Distillation aims to transfer the knowledge of a model trained on previous tasks -- the teacher -- to a new model -- the student -- while it learns the new task. We show that this works well for the region proposal network, but that wrong, yet overly confident teacher predictions prevent student models from effective learning of the classification head. Our analysis provides a foundation that allows us to propose improvements for existing techniques by detecting incorrect teacher predictions, based on current ground-truth labels, and by employing an adaptive Huber loss as opposed to the mean squared error for the distillation loss in the classification heads. We evidence that our strategy works not only in a class incremental setting, but also in domain incremental settings, which constitute a realistic context, likely to be the setting of representative real-world problems.