 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRARA: Zero-shot Sim2Real Visual Navigation with Following Foreground Cues
Jan 08, 2022
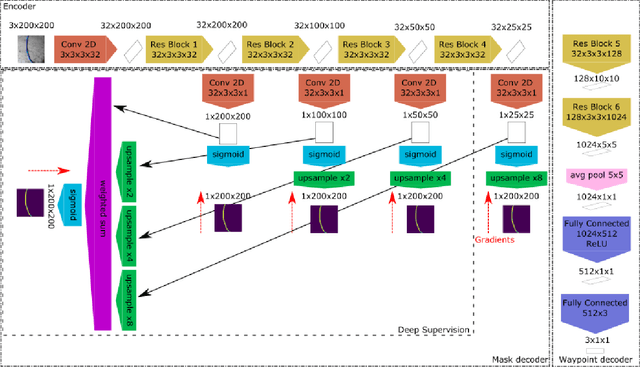


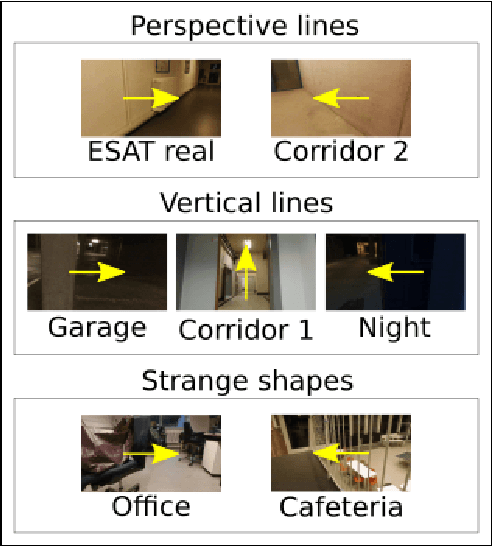
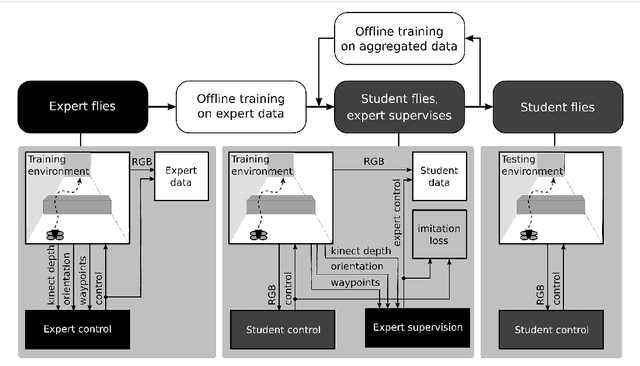
The gap between simulation and the real-world restrains many machine learning breakthroughs in computer vision and reinforcement learning from being applicable in the real world. In this work, we tackle this gap for the specific case of camera-based navigation, formulating it as following a visual cue in the foreground with arbitrary backgrounds. The visual cue in the foreground can often be simulated realistically, such as a line, gate or cone. The challenge then lies in coping with the unknown backgrounds and integrating both. As such, the goal is to train a visual agent on data captured in an empty simulated environment except for this foreground cue and test this model directly in a visually diverse real world. In order to bridge this big gap, we show it's crucial to combine following techniques namely: Randomized augmentation of the fore- and background, regularization with both deep supervision and triplet loss and finally abstraction of the dynamics by using waypoints rather than direct velocity commands. The various techniques are ablated in our experimental results both qualitatively and quantitatively finally demonstrating a successful transfer from simulation to the real world.
Task-Free Continual Learning
Dec 10, 2018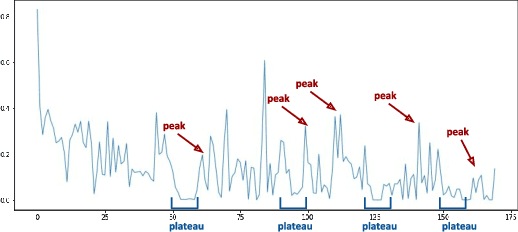
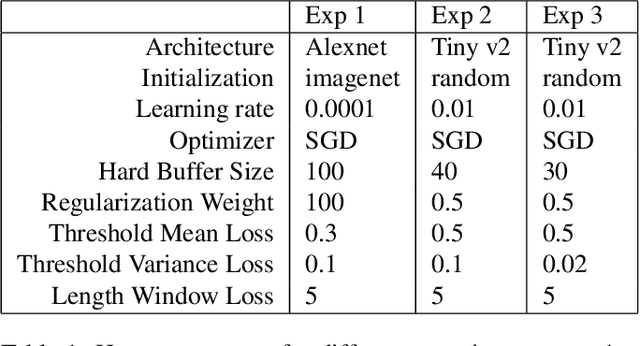
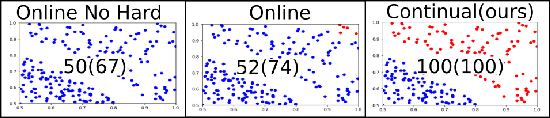

Methods proposed in the literature towards continual deep learning typically operate in a task-based sequential learning setup. A sequence of tasks is learned, one at a time, with all data of current task available but not of previous or future tasks. Task boundaries and identities are known at all times. This setup, however, is rarely encountered in practical applications. Therefore we investigate how to transform continual learning to an online setup. We develop a system that keeps on learning over time in a streaming fashion, with data distributions gradually changing and without the notion of separate tasks. To this end, we build on the work on Memory Aware Synapses, and show how this method can be made online by providing a protocol to decide i) when to update the importance weights, ii) which data to use to update them, and iii) how to accumulate the importance weights at each update step. Experimental results show the validity of the approach in the context of two applications: (self-)supervised learning of a face recognition model by watching soap series and learning a robot to avoid collisions.
DoShiCo Challenge: Domain Shift in Control Prediction
Apr 12, 2018

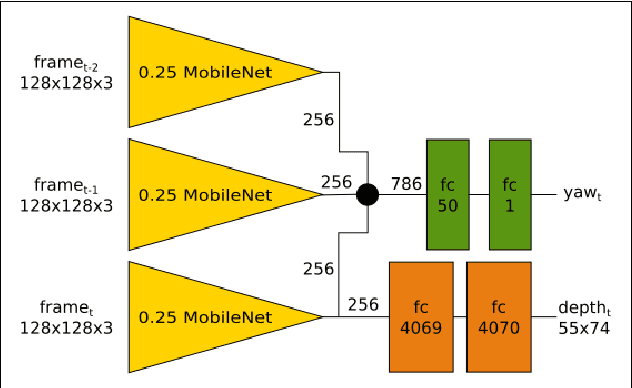
Training deep neural network policies end-to-end for real-world applications so far requires big demonstration datasets in the real world or big sets consisting of a large variety of realistic and closely related 3D CAD models. These real or virtual data should, moreover, have very similar characteristics to the conditions expected at test time. These stringent requirements and the time consuming data collection processes that they entail, are currently the most important impediment that keeps deep reinforcement learning from being deployed in real-world applications. Therefore, in this work we advocate an alternative approach, where instead of avoiding any domain shift by carefully selecting the training data, the goal is to learn a policy that can cope with it. To this end, we propose the DoShiCo challenge: to train a model in very basic synthetic environments, far from realistic, in a way that it can be applied in more realistic environments as well as take the control decisions on real-world data. In particular, we focus on the task of collision avoidance for drones. We created a set of simulated environments that can be used as benchmark and implemented a baseline method, exploiting depth prediction as an auxiliary task to help overcome the domain shift. Even though the policy is trained in very basic environments, it can learn to fly without collisions in a very different realistic simulated environment. Of course several benchmarks for reinforcement learning already exist - but they never include a large domain shift. On the other hand, several benchmarks in computer vision focus on the domain shift, but they take the form of a static datasets instead of simulated environments. In this work we claim that it is crucial to take the two challenges together in one benchmark.
How hard is it to cross the room? -- Training Neural Networks to steer a UAV
Feb 24, 2017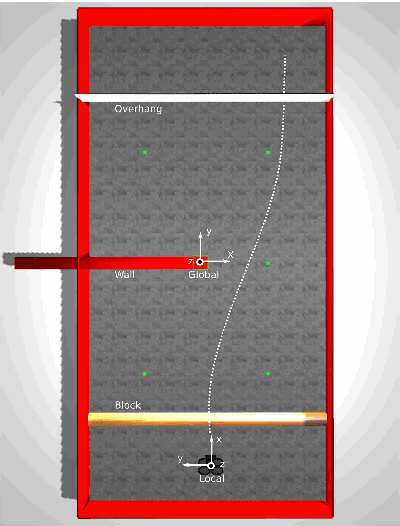

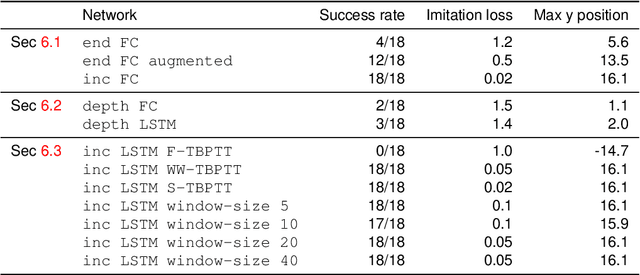
This work explores the feasibility of steering a drone with a (recurrent) neural network, based on input from a forward looking camera, in the context of a high-level navigation task. We set up a generic framework for training a network to perform navigation tasks based on imitation learning. It can be applied to both aerial and land vehicles. As a proof of concept we apply it to a UAV (Unmanned Aerial Vehicle) in a simulated environment, learning to cross a room containing a number of obstacles. So far only feedforward neural networks (FNNs) have been used to train UAV control. To cope with more complex tasks, we propose the use of recurrent neural networks (RNN) instead and successfully train an LSTM (Long-Short Term Memory) network for controlling UAVs. Vision based control is a sequential prediction problem, known for its highly correlated input data. The correlation makes training a network hard, especially an RNN. To overcome this issue, we investigate an alternative sampling method during training, namely window-wise truncated backpropagation through time (WW-TBPTT). Further, end-to-end training requires a lot of data which often is not available. Therefore, we compare the performance of retraining only the Fully Connected (FC) and LSTM control layers with networks which are trained end-to-end. Performing the relatively simple task of crossing a room already reveals important guidelines and good practices for training neural control networks. Different visualizations help to explain the behavior learned.