 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeper, Broader and Artier Domain Generalization
Oct 09, 2017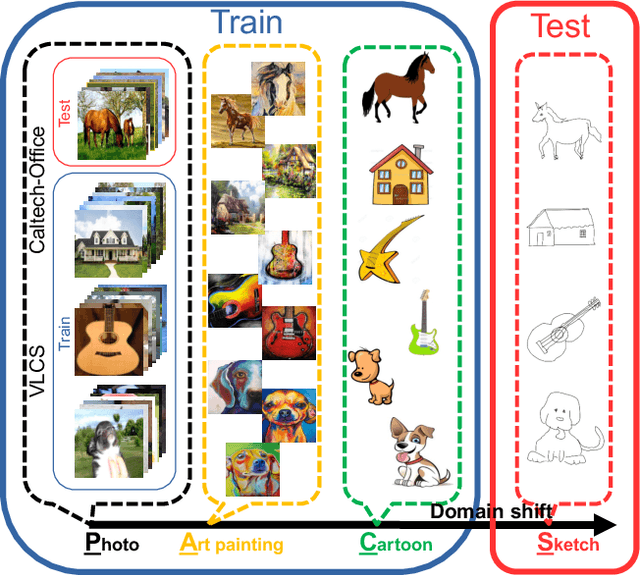

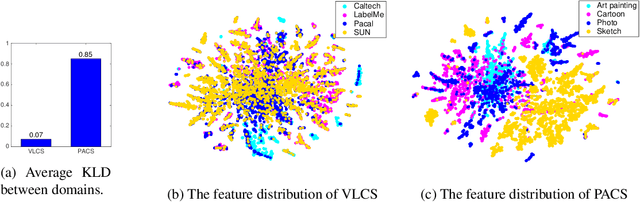

The problem of domain generalization is to learn from multiple training domains, and extract a domain-agnostic model that can then be applied to an unseen domain. Domain generalization (DG) has a clear motivation in contexts where there are target domains with distinct characteristics, yet sparse data for training. For example recognition in sketch images, which are distinctly more abstract and rarer than photos. Nevertheless, DG methods have primarily been evaluated on photo-only benchmarks focusing on alleviating the dataset bias where both problems of domain distinctiveness and data sparsity can be minimal. We argue that these benchmarks are overly straightforward, and show that simple deep learning baselines perform surprisingly well on them. In this paper, we make two main contributions: Firstly, we build upon the favorable domain shift-robust properties of deep learning methods, and develop a low-rank parameterized CNN model for end-to-end DG learning. Secondly, we develop a DG benchmark dataset covering photo, sketch, cartoon and painting domains. This is both more practically relevant, and harder (bigger domain shift) than existing benchmarks. The results show that our method outperforms existing DG alternatives, and our dataset provides a more significant DG challenge to drive future research.
Weakly Supervised Image Annotation and Segmentation with Objects and Attributes
Aug 08, 2017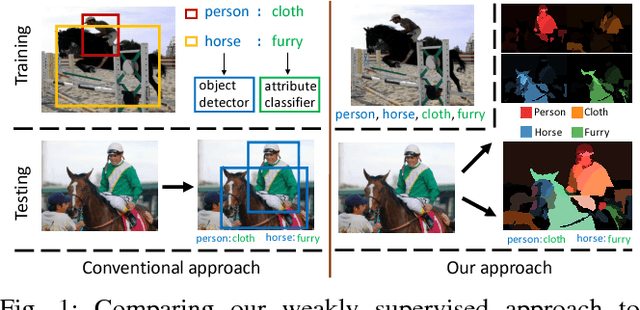
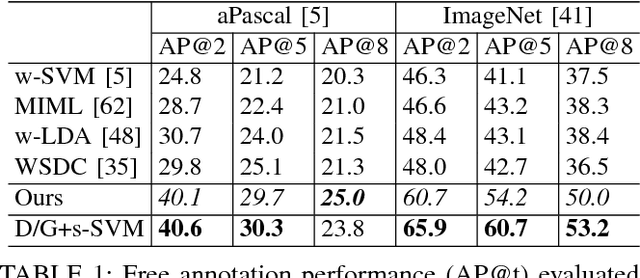
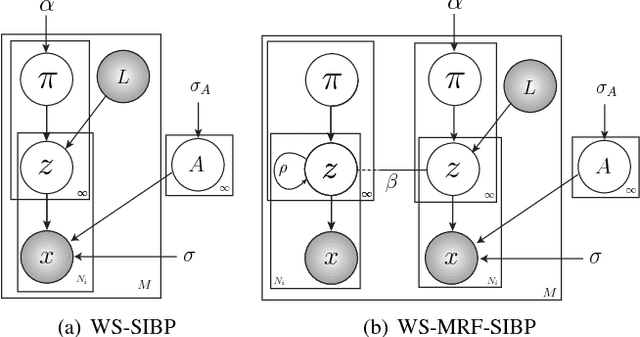
We propose to model complex visual scenes using a non-parametric Bayesian model learned from weakly labelled images abundant on media sharing sites such as Flickr. Given weak image-level annotations of objects and attributes without locations or associations between them, our model aims to learn the appearance of object and attribute classes as well as their association on each object instance. Once learned, given an image, our model can be deployed to tackle a number of vision problems in a joint and coherent manner, including recognising objects in the scene (automatic object annotation), describing objects using their attributes (attribute prediction and association), and localising and delineating the objects (object detection and semantic segmentation). This is achieved by developing a novel Weakly Supervised Markov Random Field Stacked Indian Buffet Process (WS-MRF-SIBP) that models objects and attributes as latent factors and explicitly captures their correlations within and across superpixels. Extensive experiments on benchmark datasets demonstrate that our weakly supervised model significantly outperforms weakly supervised alternatives and is often comparable with existing strongly supervised models on a variety of tasks including semantic segmentation, automatic image annotation and retrieval based on object-attribute associations.
Bayesian Joint Modelling for Object Localisation in Weakly Labelled Images
Jun 19, 2017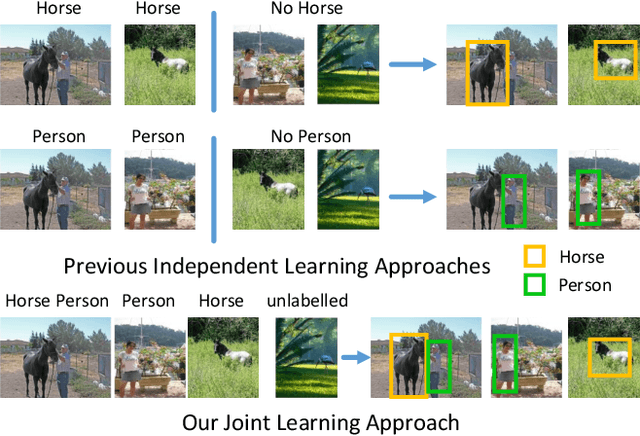

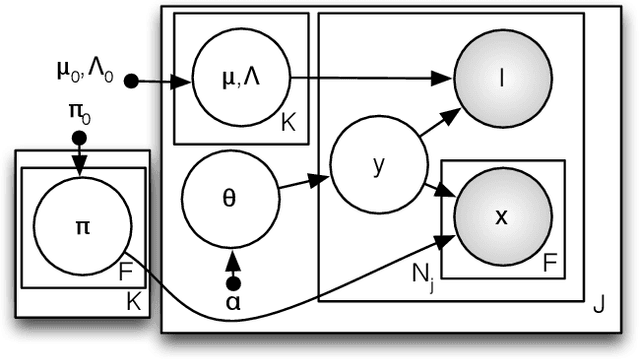
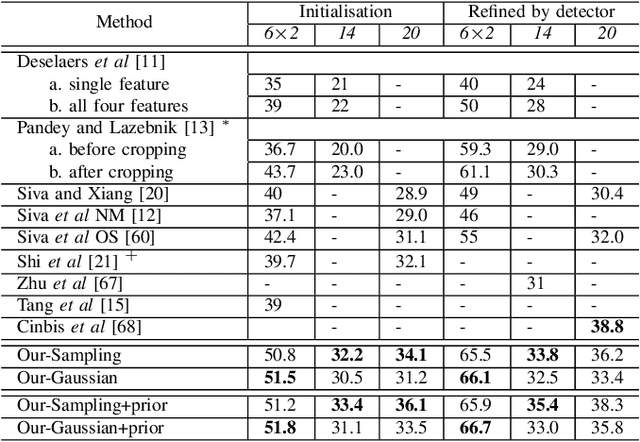
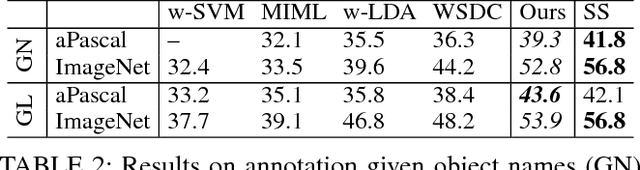
We address the problem of localisation of objects as bounding boxes in images and videos with weak labels. This weakly supervised object localisation problem has been tackled in the past using discriminative models where each object class is localised independently from other classes. In this paper, a novel framework based on Bayesian joint topic modelling is proposed, which differs significantly from the existing ones in that: (1) All foreground object classes are modelled jointly in a single generative model that encodes multiple object co-existence so that "explaining away" inference can resolve ambiguity and lead to better learning and localisation. (2) Image backgrounds are shared across classes to better learn varying surroundings and "push out" objects of interest. (3) Our model can be learned with a mixture of weakly labelled and unlabelled data, allowing the large volume of unlabelled images on the Internet to be exploited for learning. Moreover, the Bayesian formulation enables the exploitation of various types of prior knowledge to compensate for the limited supervision offered by weakly labelled data, as well as Bayesian domain adaptation for transfer learning. Extensive experiments on the PASCAL VOC, ImageNet and YouTube-Object videos datasets demonstrate the effectiveness of our Bayesian joint model for weakly supervised object localisation.
Transferring a Semantic Representation for Person Re-Identification and Search
Jun 12, 2017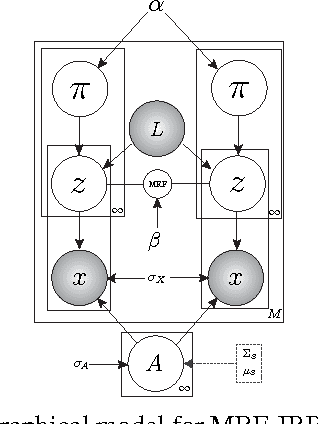
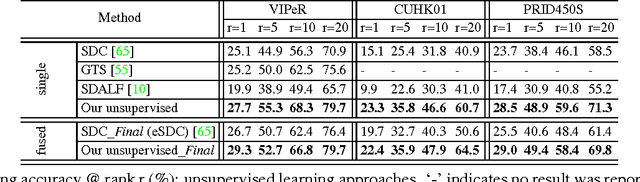
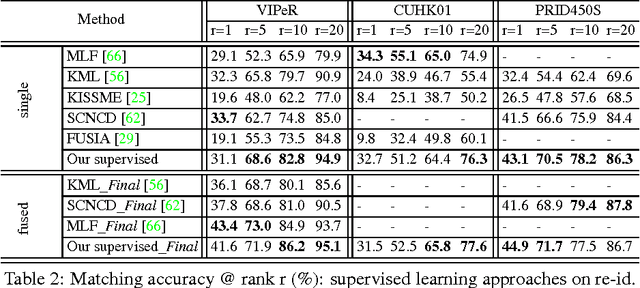

Learning semantic attributes for person re-identification and description-based person search has gained increasing interest due to attributes' great potential as a pose and view-invariant representation. However, existing attribute-centric approaches have thus far underperformed state-of-the-art conventional approaches. This is due to their non-scalable need for extensive domain (camera) specific annotation. In this paper we present a new semantic attribute learning approach for person re-identification and search. Our model is trained on existing fashion photography datasets -- either weakly or strongly labelled. It can then be transferred and adapted to provide a powerful semantic description of surveillance person detections, without requiring any surveillance domain supervision. The resulting representation is useful for both unsupervised and supervised person re-identification, achieving state-of-the-art and near state-of-the-art performance respectively. Furthermore, as a semantic representation it allows description-based person search to be integrated within the same framework.
Deep Mutual Learning
Jun 01, 2017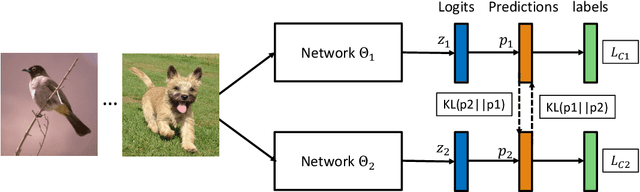

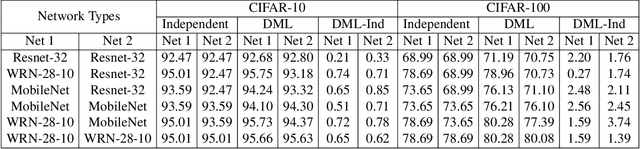
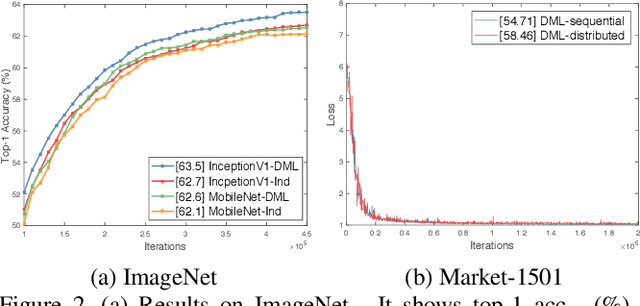
Model distillation is an effective and widely used technique to transfer knowledge from a teacher to a student network. The typical application is to transfer from a powerful large network or ensemble to a small network, that is better suited to low-memory or fast execution requirements. In this paper, we present a deep mutual learning (DML) strategy where, rather than one way transfer between a static pre-defined teacher and a student, an ensemble of students learn collaboratively and teach each other throughout the training process. Our experiments show that a variety of network architectures benefit from mutual learning and achieve compelling results on CIFAR-100 recognition and Market-1501 person re-identification benchmarks. Surprisingly, it is revealed that no prior powerful teacher network is necessary -- mutual learning of a collection of simple student networks works, and moreover outperforms distillation from a more powerful yet static teacher.
Bayesian Joint Topic Modelling for Weakly Supervised Object Localisation
May 09, 2017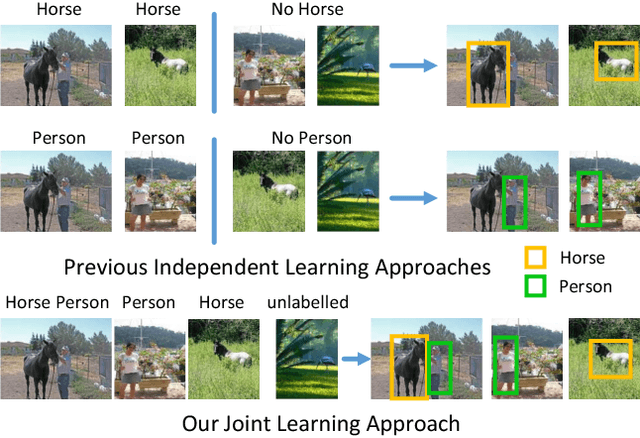
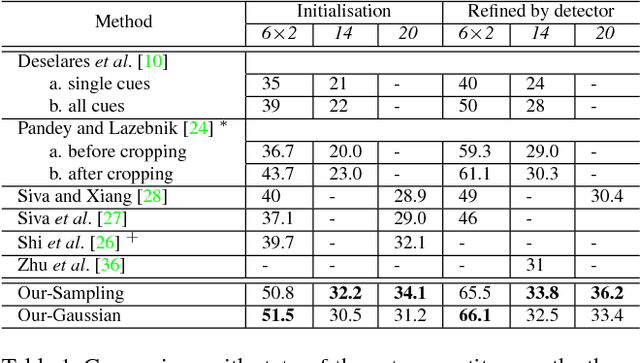
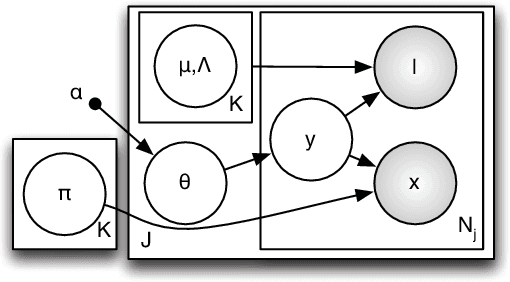
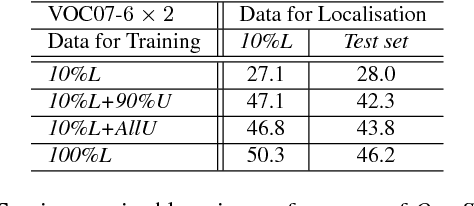
We address the problem of localisation of objects as bounding boxes in images with weak labels. This weakly supervised object localisation problem has been tackled in the past using discriminative models where each object class is localised independently from other classes. We propose a novel framework based on Bayesian joint topic modelling. Our framework has three distinctive advantages over previous works: (1) All object classes and image backgrounds are modelled jointly together in a single generative model so that "explaining away" inference can resolve ambiguity and lead to better learning and localisation. (2) The Bayesian formulation of the model enables easy integration of prior knowledge about object appearance to compensate for limited supervision. (3) Our model can be learned with a mixture of weakly labelled and unlabelled data, allowing the large volume of unlabelled images on the Internet to be exploited for learning. Extensive experiments on the challenging VOC dataset demonstrate that our approach outperforms the state-of-the-art competitors.
Trace Norm Regularised Deep Multi-Task Learning
Feb 17, 2017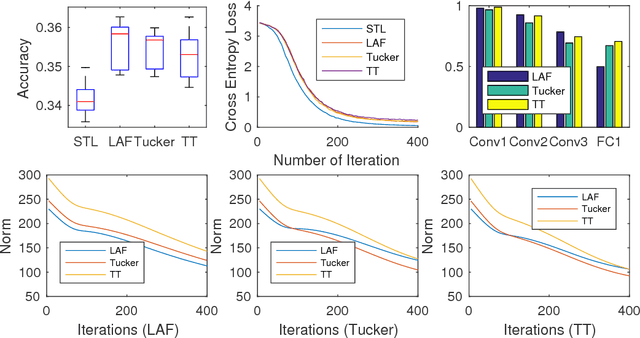
We propose a framework for training multiple neural networks simultaneously. The parameters from all models are regularised by the tensor trace norm, so that each neural network is encouraged to reuse others' parameters if possible -- this is the main motivation behind multi-task learning. In contrast to many deep multi-task learning models, we do not predefine a parameter sharing strategy by specifying which layers have tied parameters. Instead, our framework considers sharing for all shareable layers, and the sharing strategy is learned in a data-driven way.
Unifying Multi-Domain Multi-Task Learning: Tensor and Neural Network Perspectives
Nov 28, 2016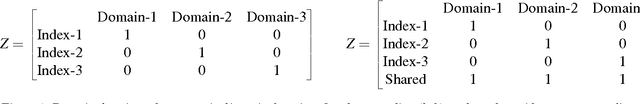
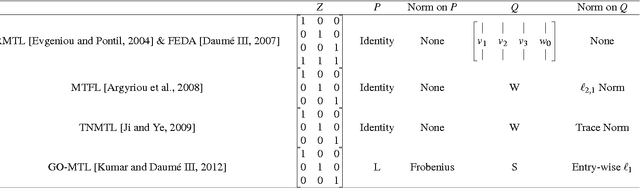
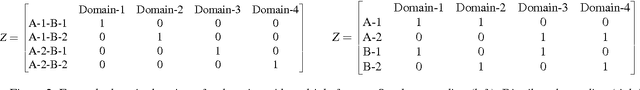
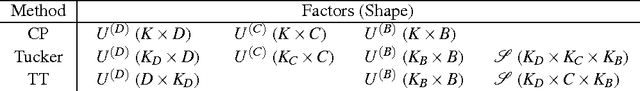
Multi-domain learning aims to benefit from simultaneously learning across several different but related domains. In this chapter, we propose a single framework that unifies multi-domain learning (MDL) and the related but better studied area of multi-task learning (MTL). By exploiting the concept of a \emph{semantic descriptor} we show how our framework encompasses various classic and recent MDL/MTL algorithms as special cases with different semantic descriptor encodings. As a second contribution, we present a higher order generalisation of this framework, capable of simultaneous multi-task-multi-domain learning. This generalisation has two mathematically equivalent views in multi-linear algebra and gated neural networks respectively. Moreover, by exploiting the semantic descriptor, it provides neural networks the capability of zero-shot learning (ZSL), where a classifier is generated for an unseen class without any training data; as well as zero-shot domain adaptation (ZSDA), where a model is generated for an unseen domain without any training data. In practice, this framework provides a powerful yet easy to implement method that can be flexibly applied to MTL, MDL, ZSL and ZSDA.
Multi-Task Zero-Shot Action Recognition with Prioritised Data Augmentation
Nov 26, 2016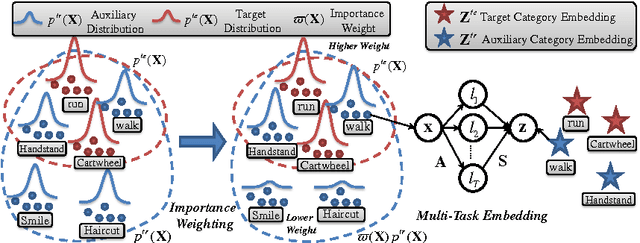
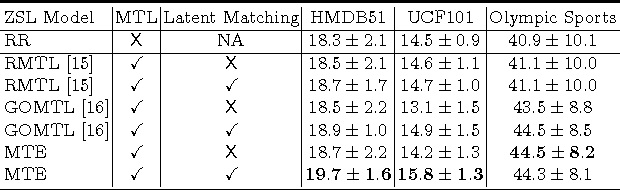

Zero-Shot Learning (ZSL) promises to scale visual recognition by bypassing the conventional model training requirement of annotated examples for every category. This is achieved by establishing a mapping connecting low-level features and a semantic description of the label space, referred as visual-semantic mapping, on auxiliary data. Reusing the learned mapping to project target videos into an embedding space thus allows novel-classes to be recognised by nearest neighbour inference. However, existing ZSL methods suffer from auxiliary-target domain shift intrinsically induced by assuming the same mapping for the disjoint auxiliary and target classes. This compromises the generalisation accuracy of ZSL recognition on the target data. In this work, we improve the ability of ZSL to generalise across this domain shift in both model- and data-centric ways by formulating a visual-semantic mapping with better generalisation properties and a dynamic data re-weighting method to prioritise auxiliary data that are relevant to the target classes. Specifically: (1) We introduce a multi-task visual-semantic mapping to improve generalisation by constraining the semantic mapping parameters to lie on a low-dimensional manifold, (2) We explore prioritised data augmentation by expanding the pool of auxiliary data with additional instances weighted by relevance to the target domain. The proposed new model is applied to the challenging zero-shot action recognition problem to demonstrate its advantages over existing ZSL models.
Gated Neural Networks for Option Pricing: Rationality by Design
Nov 19, 2016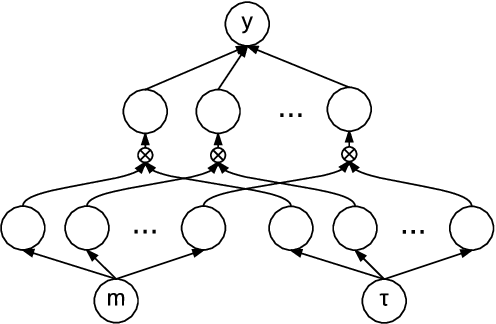


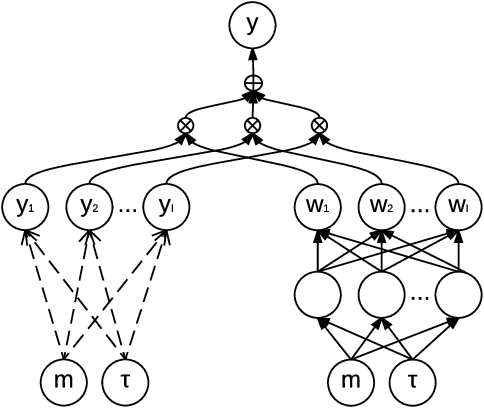
We propose a neural network approach to price EU call options that significantly outperforms some existing pricing models and comes with guarantees that its predictions are economically reasonable. To achieve this, we introduce a class of gated neural networks that automatically learn to divide-and-conquer the problem space for robust and accurate pricing. We then derive instantiations of these networks that are 'rational by design' in terms of naturally encoding a valid call option surface that enforces no arbitrage principles. This integration of human insight within data-driven learning provides significantly better generalisation in pricing performance due to the encoded inductive bias in the learning, guarantees sanity in the model's predictions, and provides econometrically useful byproduct such as risk neutral density.