 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefensive Tensorization
Oct 26, 2021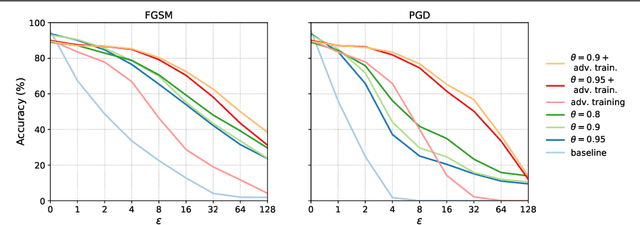
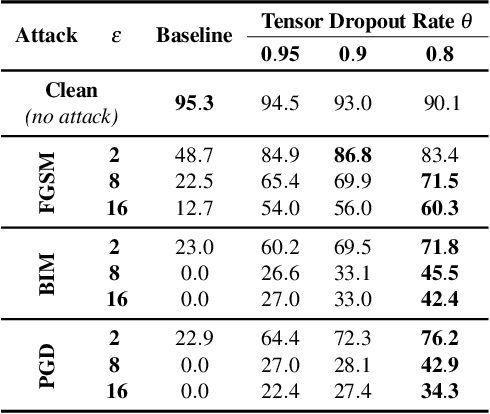
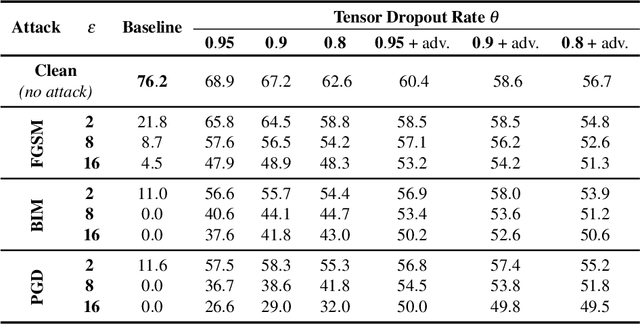
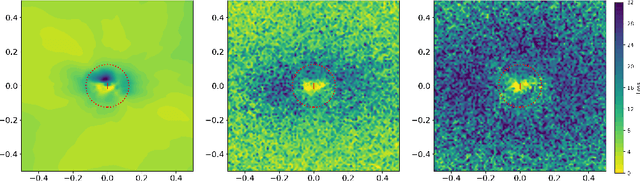
We propose defensive tensorization, an adversarial defence technique that leverages a latent high-order factorization of the network. The layers of a network are first expressed as factorized tensor layers. Tensor dropout is then applied in the latent subspace, therefore resulting in dense reconstructed weights, without the sparsity or perturbations typically induced by the randomization.Our approach can be readily integrated with any arbitrary neural architecture and combined with techniques like adversarial training. We empirically demonstrate the effectiveness of our approach on standard image classification benchmarks. We validate the versatility of our approach across domains and low-precision architectures by considering an audio classification task and binary networks. In all cases, we demonstrate improved performance compared to prior works.
Online Hyperparameter Meta-Learning with Hypergradient Distillation
Oct 06, 2021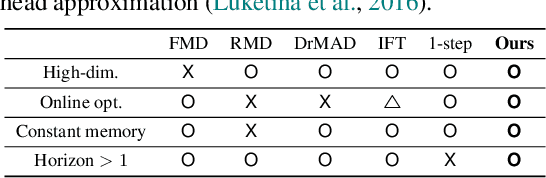
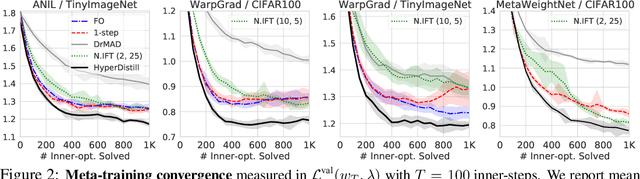
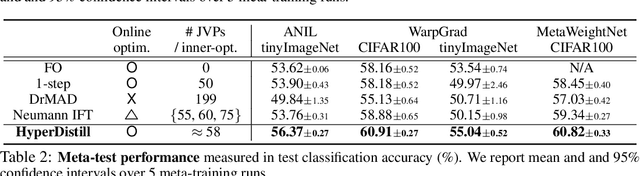
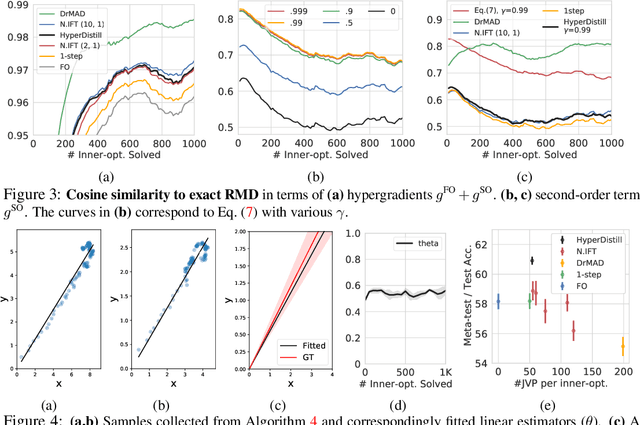
Many gradient-based meta-learning methods assume a set of parameters that do not participate in inner-optimization, which can be considered as hyperparameters. Although such hyperparameters can be optimized using the existing gradient-based hyperparameter optimization (HO) methods, they suffer from the following issues. Unrolled differentiation methods do not scale well to high-dimensional hyperparameters or horizon length, Implicit Function Theorem (IFT) based methods are restrictive for online optimization, and short horizon approximations suffer from short horizon bias. In this work, we propose a novel HO method that can overcome these limitations, by approximating the second-order term with knowledge distillation. Specifically, we parameterize a single Jacobian-vector product (JVP) for each HO step and minimize the distance from the true second-order term. Our method allows online optimization and also is scalable to the hyperparameter dimension and the horizon length. We demonstrate the effectiveness of our method on two different meta-learning methods and three benchmark datasets.
Vision-based system identification and 3D keypoint discovery using dynamics constraints
Sep 13, 2021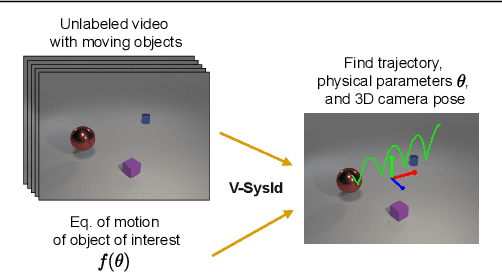
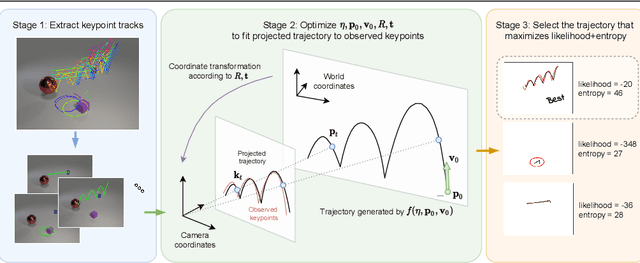
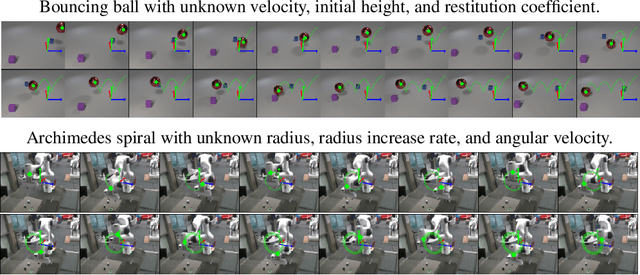

This paper introduces V-SysId, a novel method that enables simultaneous keypoint discovery, 3D system identification, and extrinsic camera calibration from an unlabeled video taken from a static camera, using only the family of equations of motion of the object of interest as weak supervision. V-SysId takes keypoint trajectory proposals and alternates between maximum likelihood parameter estimation and extrinsic camera calibration, before applying a suitable selection criterion to identify the track of interest. This is then used to train a keypoint tracking model using supervised learning. Results on a range of settings (robotics, physics, physiology) highlight the utility of this approach.
A Channel Coding Benchmark for Meta-Learning
Jul 15, 2021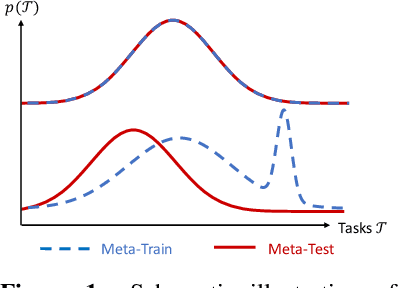


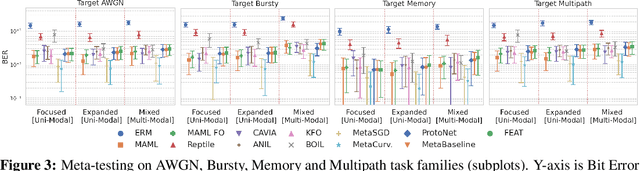
Meta-learning provides a popular and effective family of methods for data-efficient learning of new tasks. However, several important issues in meta-learning have proven hard to study thus far. For example, performance degrades in real-world settings where meta-learners must learn from a wide and potentially multi-modal distribution of training tasks; and when distribution shift exists between meta-train and meta-test task distributions. These issues are typically hard to study since the shape of task distributions, and shift between them are not straightforward to measure or control in standard benchmarks. We propose the channel coding problem as a benchmark for meta-learning. Channel coding is an important practical application where task distributions naturally arise, and fast adaptation to new tasks is practically valuable. We use this benchmark to study several aspects of meta-learning, including the impact of task distribution breadth and shift, which can be controlled in the coding problem. Going forward, this benchmark provides a tool for the community to study the capabilities and limitations of meta-learning, and to drive research on practically robust and effective meta-learners.
EvoGrad: Efficient Gradient-Based Meta-Learning and Hyperparameter Optimization
Jun 19, 2021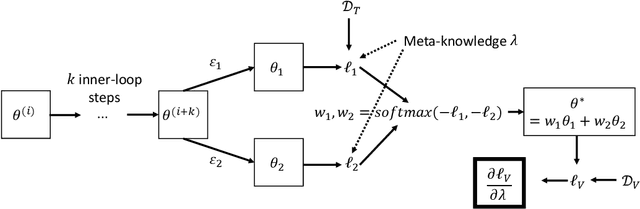


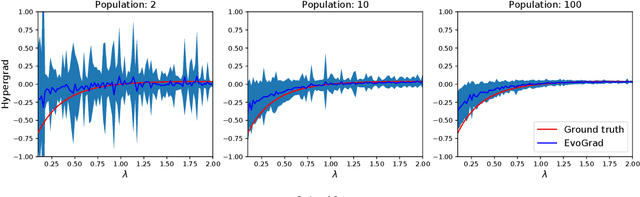
Gradient-based meta-learning and hyperparameter optimization have seen significant progress recently, enabling practical end-to-end training of neural networks together with many hyperparameters. Nevertheless, existing approaches are relatively expensive as they need to compute second-order derivatives and store a longer computational graph. This cost prevents scaling them to larger network architectures. We present EvoGrad, a new approach to meta-learning that draws upon evolutionary techniques to more efficiently compute hypergradients. EvoGrad estimates hypergradient with respect to hyperparameters without calculating second-order gradients, or storing a longer computational graph, leading to significant improvements in efficiency. We evaluate EvoGrad on two substantial recent meta-learning applications, namely cross-domain few-shot learning with feature-wise transformations and noisy label learning with MetaWeightNet. The results show that EvoGrad significantly improves efficiency and enables scaling meta-learning to bigger CNN architectures such as from ResNet18 to ResNet34.
Meta-Calibration: Meta-Learning of Model Calibration Using Differentiable Expected Calibration Error
Jun 17, 2021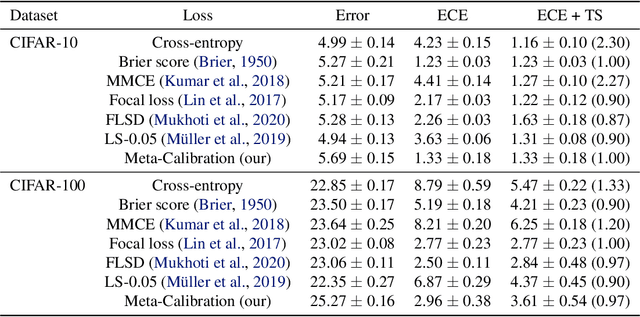
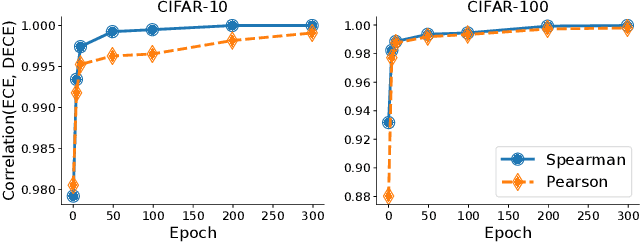
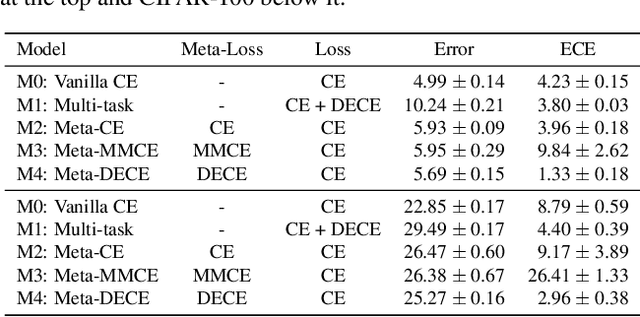
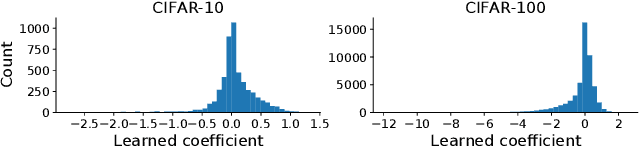
Calibration of neural networks is a topical problem that is becoming increasingly important for real-world use of neural networks. The problem is especially noticeable when using modern neural networks, for which there is significant difference between the model confidence and the confidence it should have. Various strategies have been successfully proposed, yet there is more space for improvements. We propose a novel approach that introduces a differentiable metric for expected calibration error and successfully uses it as an objective for meta-learning, achieving competitive results with state-of-the-art approaches. Our approach presents a new direction of using meta-learning to directly optimize model calibration, which we believe will inspire further work in this promising and new direction.
Cloud2Curve: Generation and Vectorization of Parametric Sketches
Mar 29, 2021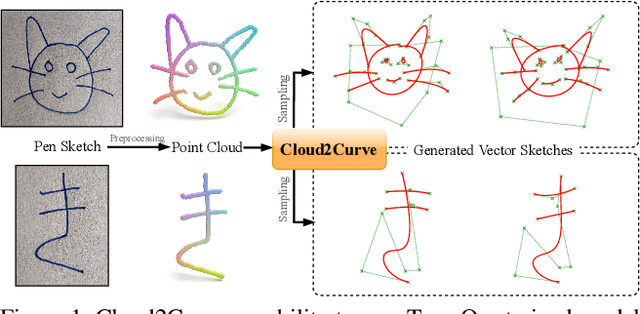
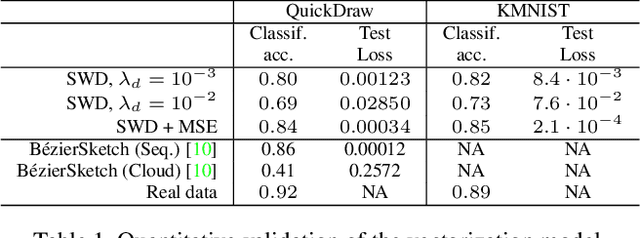
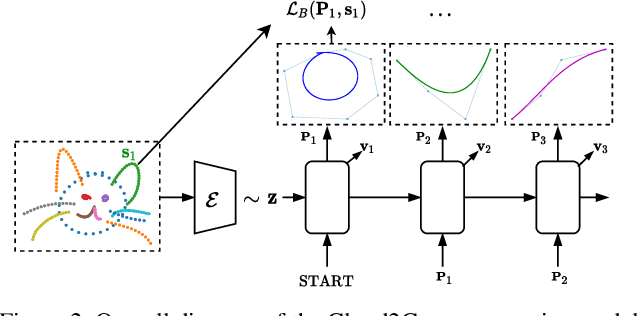
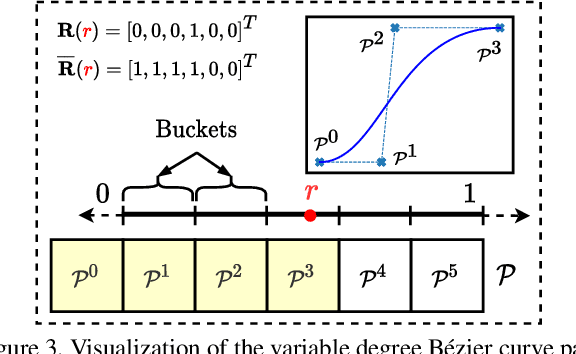
Analysis of human sketches in deep learning has advanced immensely through the use of waypoint-sequences rather than raster-graphic representations. We further aim to model sketches as a sequence of low-dimensional parametric curves. To this end, we propose an inverse graphics framework capable of approximating a raster or waypoint based stroke encoded as a point-cloud with a variable-degree B\'ezier curve. Building on this module, we present Cloud2Curve, a generative model for scalable high-resolution vector sketches that can be trained end-to-end using point-cloud data alone. As a consequence, our model is also capable of deterministic vectorization which can map novel raster or waypoint based sketches to their corresponding high-resolution scalable B\'ezier equivalent. We evaluate the generation and vectorization capabilities of our model on Quick, Draw! and K-MNIST datasets.
Shallow Bayesian Meta Learning for Real-World Few-Shot Recognition
Jan 08, 2021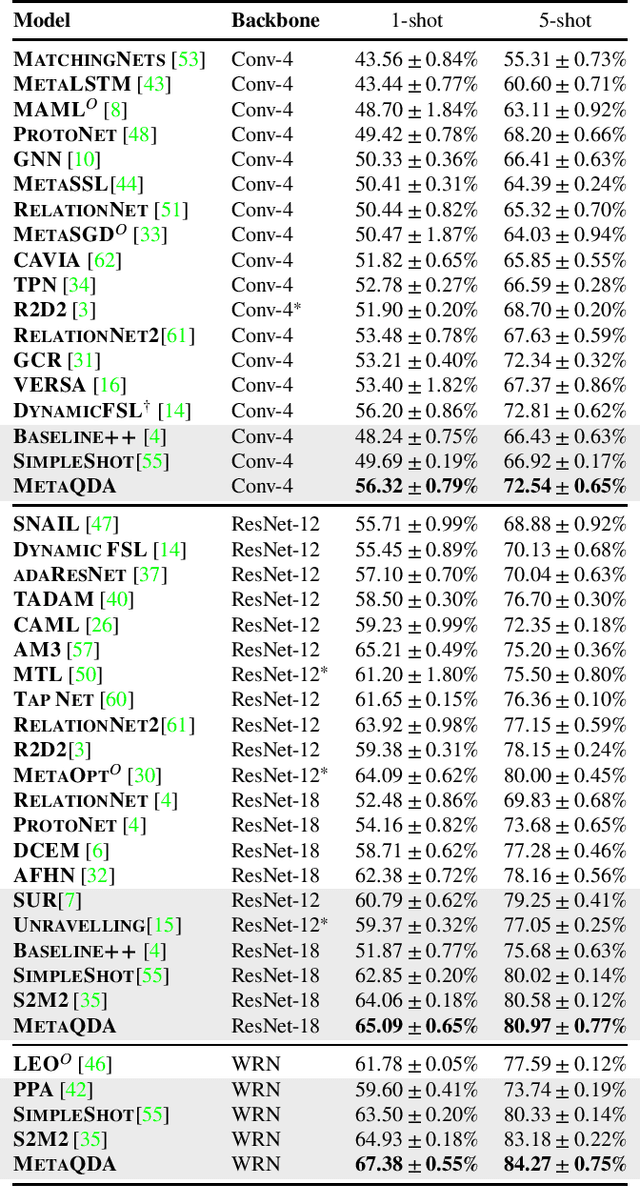
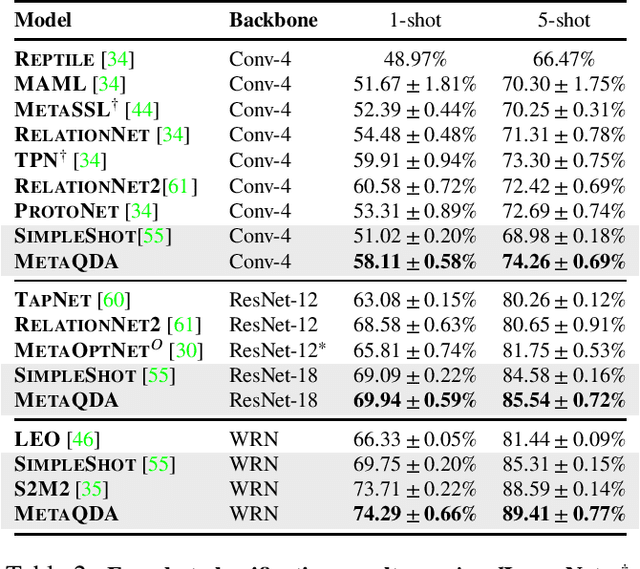
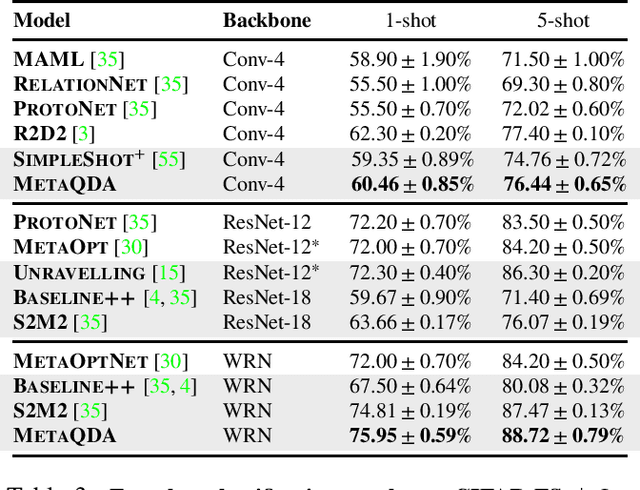
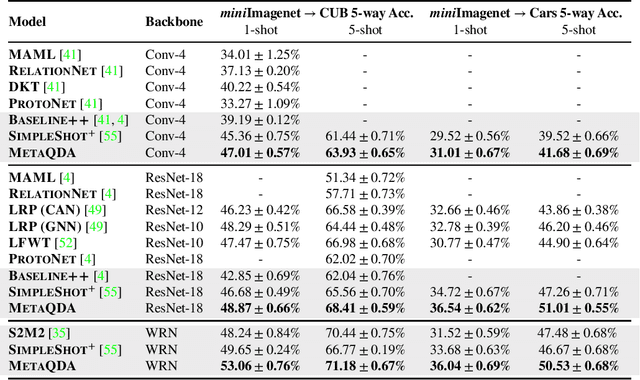
Current state-of-the-art few-shot learners focus on developing effective training procedures for feature representations, before using simple, e.g. nearest centroid, classifiers. In this paper we take an orthogonal approach that is agnostic to the features used, and focus exclusively on meta-learning the actual classifier layer. Specifically, we introduce MetaQDA, a Bayesian meta-learning generalisation of the classic quadratic discriminant analysis. This setup has several benefits of interest to practitioners: meta-learning is fast and memory efficient, without the need to fine-tune features. It is agnostic to the off-the-shelf features chosen, and thus will continue to benefit from advances in feature representations. Empirically, it leads to robust performance in cross-domain few-shot learning and, crucially for real-world applications, it leads to better uncertainty calibration in predictions.
Robust Domain Randomised Reinforcement Learning through Peer-to-Peer Distillation
Dec 09, 2020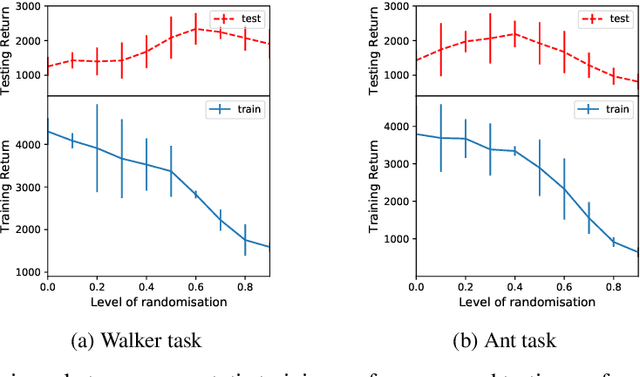
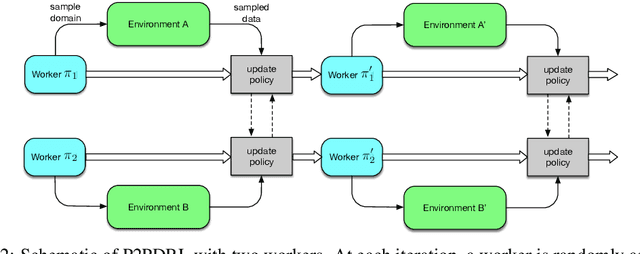
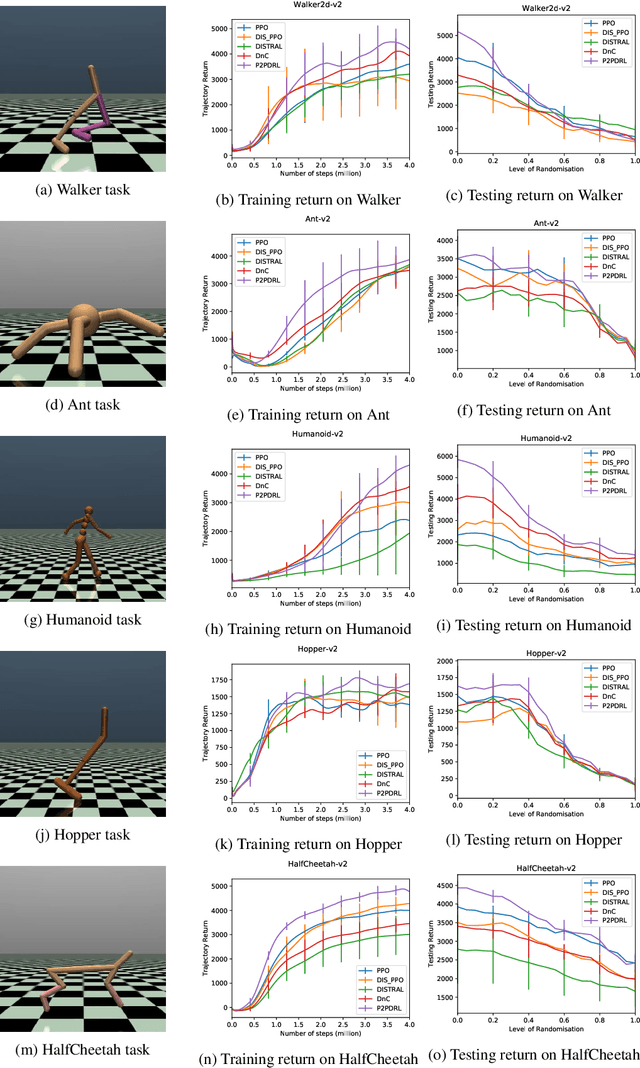
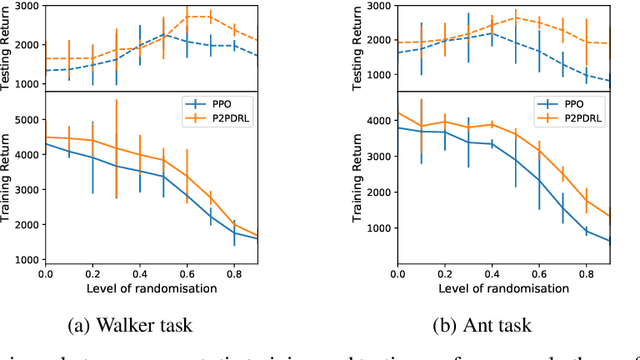
In reinforcement learning, domain randomisation is an increasingly popular technique for learning more general policies that are robust to domain-shifts at deployment. However, naively aggregating information from randomised domains may lead to high variance in gradient estimation and unstable learning process. To address this issue, we present a peer-to-peer online distillation strategy for RL termed P2PDRL, where multiple workers are each assigned to a different environment, and exchange knowledge through mutual regularisation based on Kullback-Leibler divergence. Our experiments on continuous control tasks show that P2PDRL enables robust learning across a wider randomisation distribution than baselines, and more robust generalisation to new environments at testing.
Margin-Based Transfer Bounds for Meta Learning with Deep Feature Embedding
Dec 02, 2020
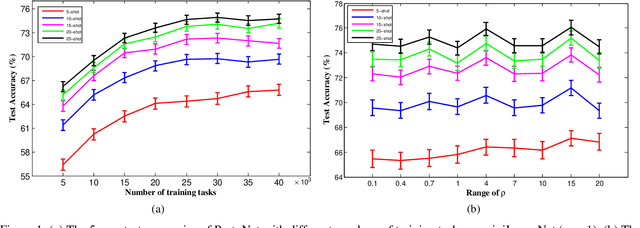

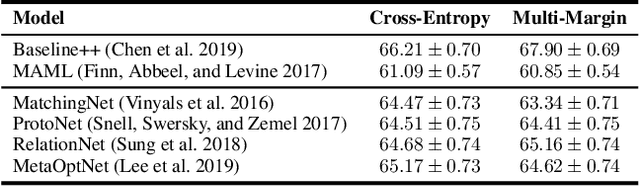
By transferring knowledge learned from seen/previous tasks, meta learning aims to generalize well to unseen/future tasks. Existing meta-learning approaches have shown promising empirical performance on various multiclass classification problems, but few provide theoretical analysis on the classifiers' generalization ability on future tasks. In this paper, under the assumption that all classification tasks are sampled from the same meta-distribution, we leverage margin theory and statistical learning theory to establish three margin-based transfer bounds for meta-learning based multiclass classification (MLMC). These bounds reveal that the expected error of a given classification algorithm for a future task can be estimated with the average empirical error on a finite number of previous tasks, uniformly over a class of preprocessing feature maps/deep neural networks (i.e. deep feature embeddings). To validate these bounds, instead of the commonly-used cross-entropy loss, a multi-margin loss is employed to train a number of representative MLMC models. Experiments on three benchmarks show that these margin-based models still achieve competitive performance, validating the practical value of our margin-based theoretical analysis.