 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving GANs Using Optimal Transport
Mar 15, 2018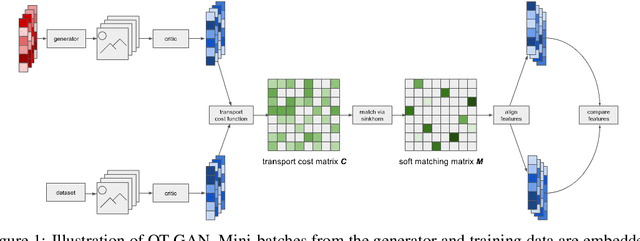
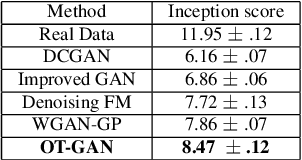
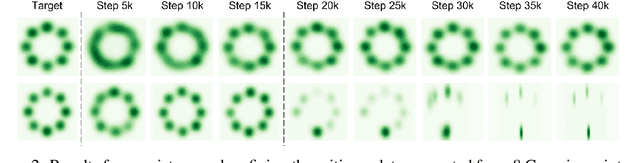
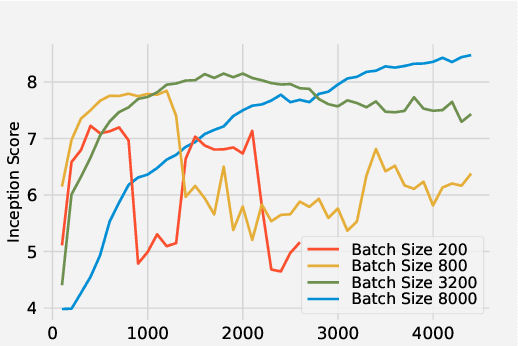
We present Optimal Transport GAN (OT-GAN), a variant of generative adversarial nets minimizing a new metric measuring the distance between the generator distribution and the data distribution. This metric, which we call mini-batch energy distance, combines optimal transport in primal form with an energy distance defined in an adversarially learned feature space, resulting in a highly discriminative distance function with unbiased mini-batch gradients. Experimentally we show OT-GAN to be highly stable when trained with large mini-batches, and we present state-of-the-art results on several popular benchmark problems for image generation.
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Sep 07, 2017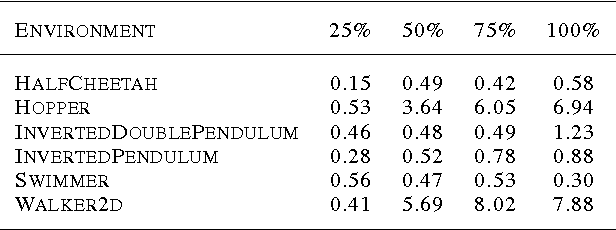
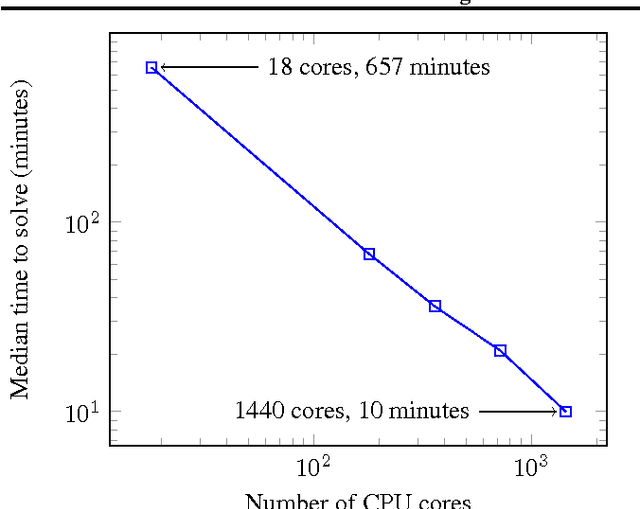
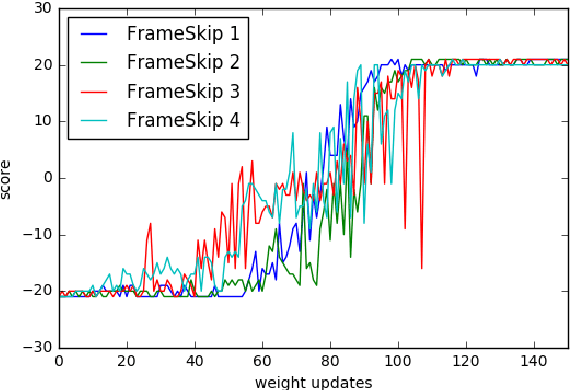
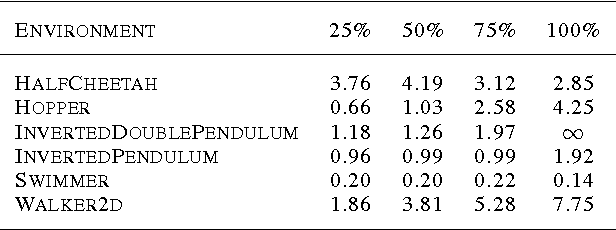
We explore the use of Evolution Strategies (ES), a class of black box optimization algorithms, as an alternative to popular MDP-based RL techniques such as Q-learning and Policy Gradients. Experiments on MuJoCo and Atari show that ES is a viable solution strategy that scales extremely well with the number of CPUs available: By using a novel communication strategy based on common random numbers, our ES implementation only needs to communicate scalars, making it possible to scale to over a thousand parallel workers. This allows us to solve 3D humanoid walking in 10 minutes and obtain competitive results on most Atari games after one hour of training. In addition, we highlight several advantages of ES as a black box optimization technique: it is invariant to action frequency and delayed rewards, tolerant of extremely long horizons, and does not need temporal discounting or value function approximation.
Variational Lossy Autoencoder
Mar 04, 2017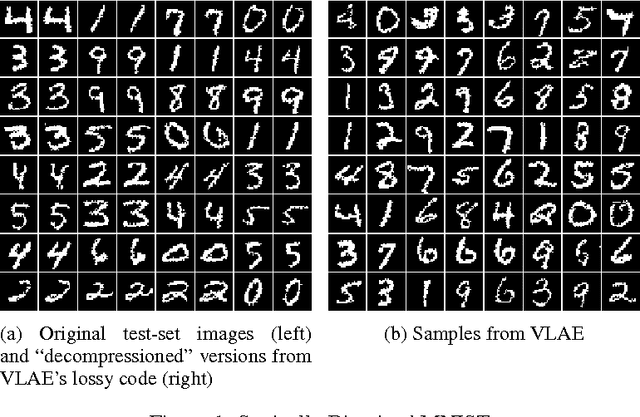
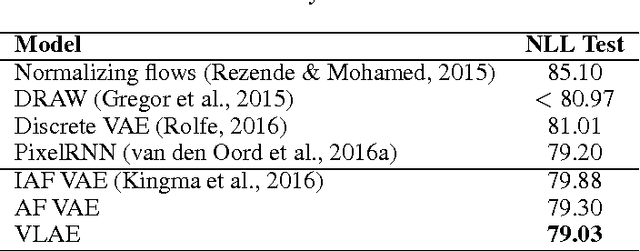


Representation learning seeks to expose certain aspects of observed data in a learned representation that's amenable to downstream tasks like classification. For instance, a good representation for 2D images might be one that describes only global structure and discards information about detailed texture. In this paper, we present a simple but principled method to learn such global representations by combining Variational Autoencoder (VAE) with neural autoregressive models such as RNN, MADE and PixelRNN/CNN. Our proposed VAE model allows us to have control over what the global latent code can learn and , by designing the architecture accordingly, we can force the global latent code to discard irrelevant information such as texture in 2D images, and hence the VAE only "autoencodes" data in a lossy fashion. In addition, by leveraging autoregressive models as both prior distribution $p(z)$ and decoding distribution $p(x|z)$, we can greatly improve generative modeling performance of VAEs, achieving new state-of-the-art results on MNIST, OMNIGLOT and Caltech-101 Silhouettes density estimation tasks.
Improving Variational Inference with Inverse Autoregressive Flow
Jan 30, 2017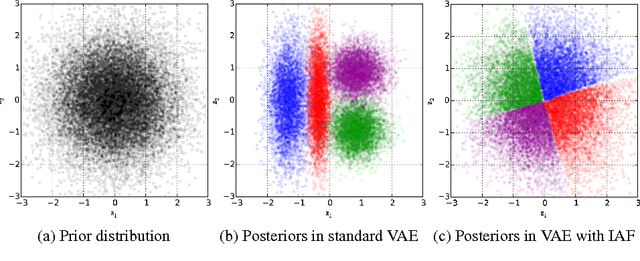
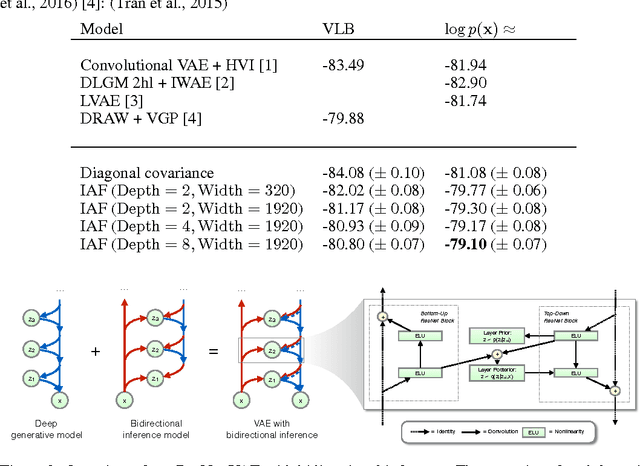
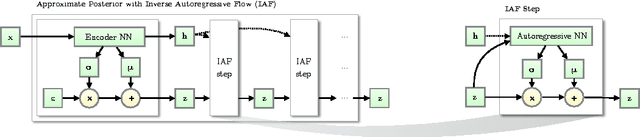
The framework of normalizing flows provides a general strategy for flexible variational inference of posteriors over latent variables. We propose a new type of normalizing flow, inverse autoregressive flow (IAF), that, in contrast to earlier published flows, scales well to high-dimensional latent spaces. The proposed flow consists of a chain of invertible transformations, where each transformation is based on an autoregressive neural network. In experiments, we show that IAF significantly improves upon diagonal Gaussian approximate posteriors. In addition, we demonstrate that a novel type of variational autoencoder, coupled with IAF, is competitive with neural autoregressive models in terms of attained log-likelihood on natural images, while allowing significantly faster synthesis.
PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications
Jan 19, 2017
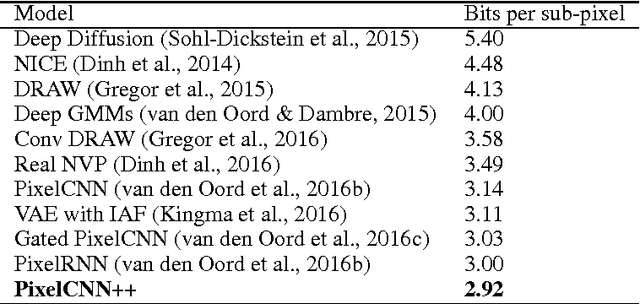
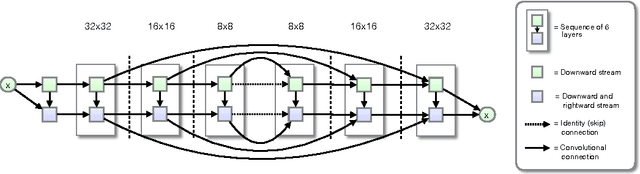

PixelCNNs are a recently proposed class of powerful generative models with tractable likelihood. Here we discuss our implementation of PixelCNNs which we make available at https://github.com/openai/pixel-cnn. Our implementation contains a number of modifications to the original model that both simplify its structure and improve its performance. 1) We use a discretized logistic mixture likelihood on the pixels, rather than a 256-way softmax, which we find to speed up training. 2) We condition on whole pixels, rather than R/G/B sub-pixels, simplifying the model structure. 3) We use downsampling to efficiently capture structure at multiple resolutions. 4) We introduce additional short-cut connections to further speed up optimization. 5) We regularize the model using dropout. Finally, we present state-of-the-art log likelihood results on CIFAR-10 to demonstrate the usefulness of these modifications.
Improved Techniques for Training GANs
Jun 10, 2016



We present a variety of new architectural features and training procedures that we apply to the generative adversarial networks (GANs) framework. We focus on two applications of GANs: semi-supervised learning, and the generation of images that humans find visually realistic. Unlike most work on generative models, our primary goal is not to train a model that assigns high likelihood to test data, nor do we require the model to be able to learn well without using any labels. Using our new techniques, we achieve state-of-the-art results in semi-supervised classification on MNIST, CIFAR-10 and SVHN. The generated images are of high quality as confirmed by a visual Turing test: our model generates MNIST samples that humans cannot distinguish from real data, and CIFAR-10 samples that yield a human error rate of 21.3%. We also present ImageNet samples with unprecedented resolution and show that our methods enable the model to learn recognizable features of ImageNet classes.
Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
Jun 04, 2016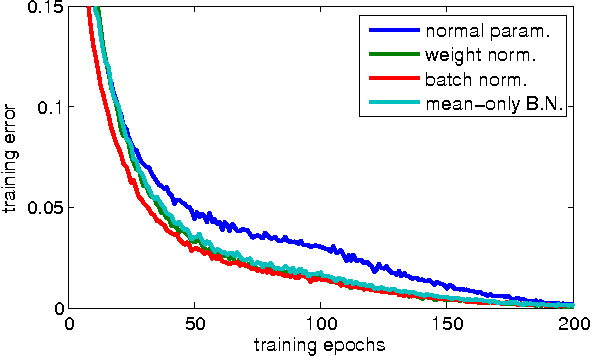
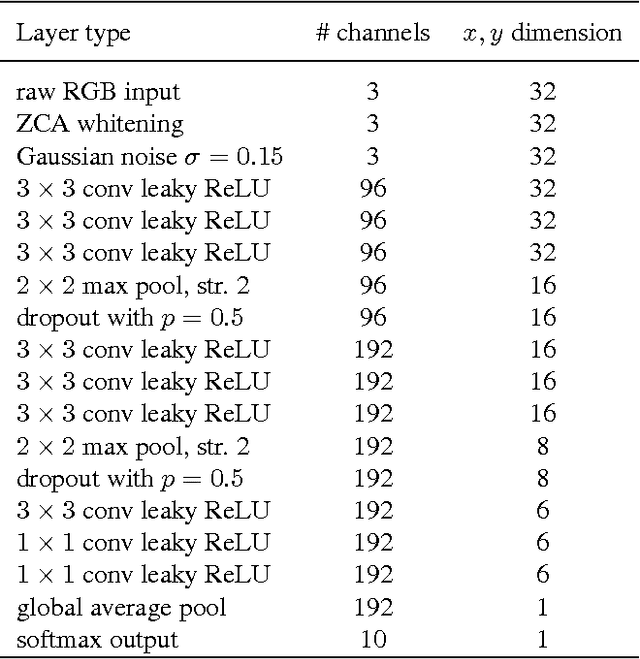

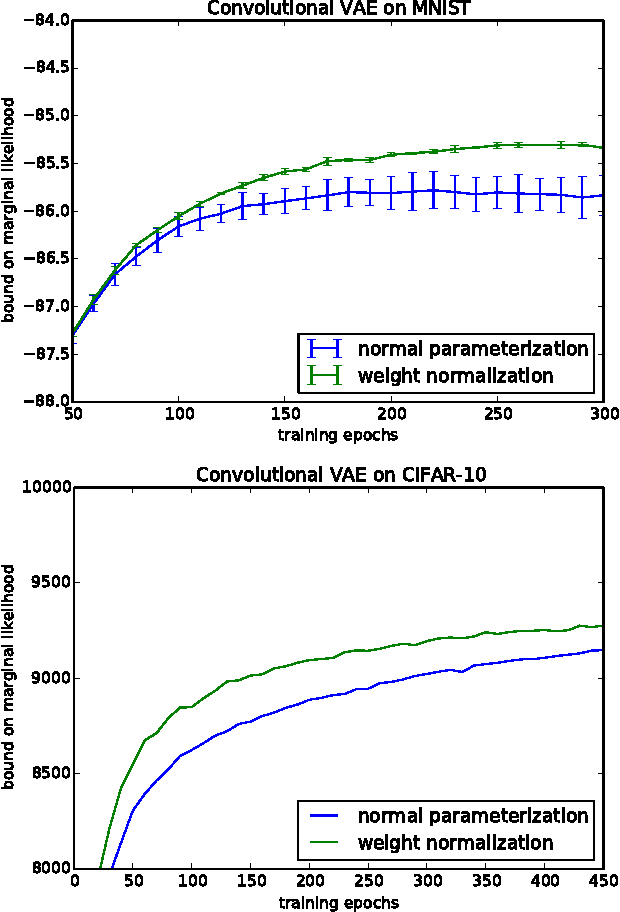
We present weight normalization: a reparameterization of the weight vectors in a neural network that decouples the length of those weight vectors from their direction. By reparameterizing the weights in this way we improve the conditioning of the optimization problem and we speed up convergence of stochastic gradient descent. Our reparameterization is inspired by batch normalization but does not introduce any dependencies between the examples in a minibatch. This means that our method can also be applied successfully to recurrent models such as LSTMs and to noise-sensitive applications such as deep reinforcement learning or generative models, for which batch normalization is less well suited. Although our method is much simpler, it still provides much of the speed-up of full batch normalization. In addition, the computational overhead of our method is lower, permitting more optimization steps to be taken in the same amount of time. We demonstrate the usefulness of our method on applications in supervised image recognition, generative modelling, and deep reinforcement learning.
A Structured Variational Auto-encoder for Learning Deep Hierarchies of Sparse Features
Feb 28, 2016In this note we present a generative model of natural images consisting of a deep hierarchy of layers of latent random variables, each of which follows a new type of distribution that we call rectified Gaussian. These rectified Gaussian units allow spike-and-slab type sparsity, while retaining the differentiability necessary for efficient stochastic gradient variational inference. To learn the parameters of the new model, we approximate the posterior of the latent variables with a variational auto-encoder. Rather than making the usual mean-field assumption however, the encoder parameterizes a new type of structured variational approximation that retains the prior dependencies of the generative model. Using this structured posterior approximation, we are able to perform joint training of deep models with many layers of latent random variables, without having to resort to stacking or other layerwise training procedures.
Variational Dropout and the Local Reparameterization Trick
Dec 20, 2015
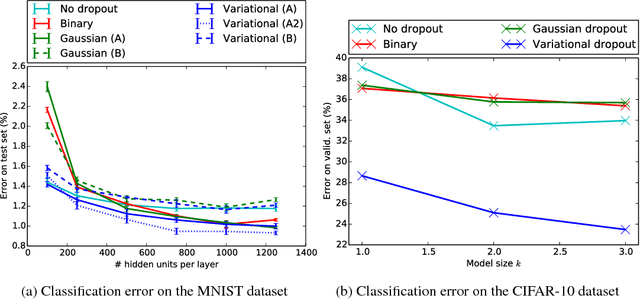
We investigate a local reparameterizaton technique for greatly reducing the variance of stochastic gradients for variational Bayesian inference (SGVB) of a posterior over model parameters, while retaining parallelizability. This local reparameterization translates uncertainty about global parameters into local noise that is independent across datapoints in the minibatch. Such parameterizations can be trivially parallelized and have variance that is inversely proportional to the minibatch size, generally leading to much faster convergence. Additionally, we explore a connection with dropout: Gaussian dropout objectives correspond to SGVB with local reparameterization, a scale-invariant prior and proportionally fixed posterior variance. Our method allows inference of more flexibly parameterized posteriors; specifically, we propose variational dropout, a generalization of Gaussian dropout where the dropout rates are learned, often leading to better models. The method is demonstrated through several experiments.
Markov Chain Monte Carlo and Variational Inference: Bridging the Gap
May 19, 2015

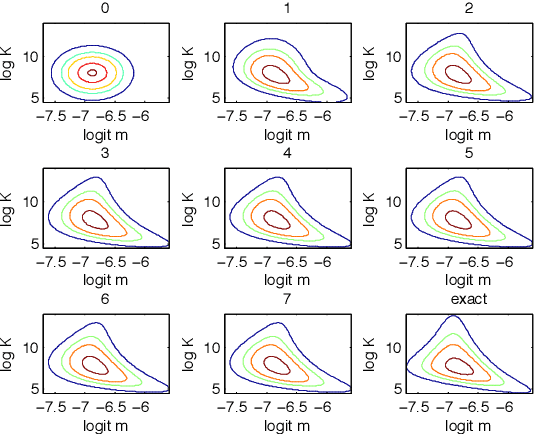
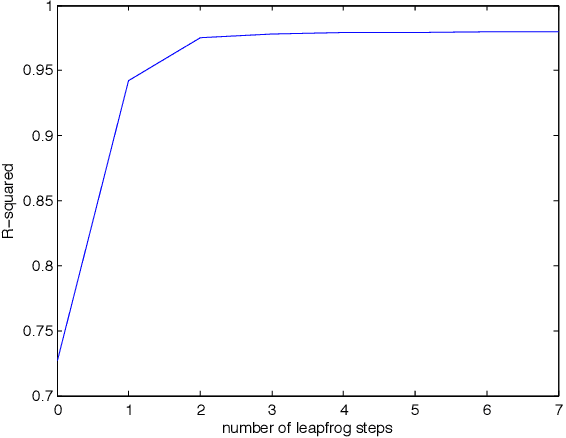
Recent advances in stochastic gradient variational inference have made it possible to perform variational Bayesian inference with posterior approximations containing auxiliary random variables. This enables us to explore a new synthesis of variational inference and Monte Carlo methods where we incorporate one or more steps of MCMC into our variational approximation. By doing so we obtain a rich class of inference algorithms bridging the gap between variational methods and MCMC, and offering the best of both worlds: fast posterior approximation through the maximization of an explicit objective, with the option of trading off additional computation for additional accuracy. We describe the theoretical foundations that make this possible and show some promising first results.