 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIG: Exploration via Conditional Information Gain
May 20, 2026Intrinsic rewards for exploration in reinforcement learning condition on different contexts: lifelong rewards score each transition against accumulated experience but ignore within-rollout redundancy; episodic rewards penalize intra-trajectory repetition but discard lifetime progress. Hybrid methods combine both signals through heuristic weights or require Gaussian-process dynamics that do not scale beyond low-dimensional state spaces. Trajectory-level information gain decomposes into per-step terms that condition on the replay buffer and rollout prefix simultaneously, but remains intractable for deep models. We derive the Conditional Information Gain (CIG) reward as a tractable surrogate: a log-determinant objective over an ensemble disagreement kernel whose Cholesky factorization yields causal per-step rewards that retain both conditioning sets while scaling to high-dimensional state spaces. We instantiate CIG in a model-based setting, where rollouts are short and within-rollout corrections remain largely unexplored. Across twelve tasks spanning discrete (MiniGrid) and continuous control (OGBench), in both clean and stochastic-distractor settings, CIG outperforms or matches prior exploration methods while remaining robust to stochastic distractors.
Automatic Curriculum Learning for Driving Scenarios: Towards Robust and Efficient Reinforcement Learning
May 13, 2025This paper addresses the challenges of training end-to-end autonomous driving agents using Reinforcement Learning (RL). RL agents are typically trained in a fixed set of scenarios and nominal behavior of surrounding road users in simulations, limiting their generalization and real-life deployment. While domain randomization offers a potential solution by randomly sampling driving scenarios, it frequently results in inefficient training and sub-optimal policies due to the high variance among training scenarios. To address these limitations, we propose an automatic curriculum learning framework that dynamically generates driving scenarios with adaptive complexity based on the agent's evolving capabilities. Unlike manually designed curricula that introduce expert bias and lack scalability, our framework incorporates a ``teacher'' that automatically generates and mutates driving scenarios based on their learning potential -- an agent-centric metric derived from the agent's current policy -- eliminating the need for expert design. The framework enhances training efficiency by excluding scenarios the agent has mastered or finds too challenging. We evaluate our framework in a reinforcement learning setting where the agent learns a driving policy from camera images. Comparative results against baseline methods, including fixed scenario training and domain randomization, demonstrate that our approach leads to enhanced generalization, achieving higher success rates: +9\% in low traffic density, +21\% in high traffic density, and faster convergence with fewer training steps. Our findings highlight the potential of ACL in improving the robustness and efficiency of RL-based autonomous driving agents.
Balancing Progress and Safety: A Novel Risk-Aware Objective for RL in Autonomous Driving
May 10, 2025Reinforcement Learning (RL) is a promising approach for achieving autonomous driving due to robust decision-making capabilities. RL learns a driving policy through trial and error in traffic scenarios, guided by a reward function that combines the driving objectives. The design of such reward function has received insufficient attention, yielding ill-defined rewards with various pitfalls. Safety, in particular, has long been regarded only as a penalty for collisions. This leaves the risks associated with actions leading up to a collision unaddressed, limiting the applicability of RL in real-world scenarios. To address these shortcomings, our work focuses on enhancing the reward formulation by defining a set of driving objectives and structuring them hierarchically. Furthermore, we discuss the formulation of these objectives in a normalized manner to transparently determine their contribution to the overall reward. Additionally, we introduce a novel risk-aware objective for various driving interactions based on a two-dimensional ellipsoid function and an extension of Responsibility-Sensitive Safety (RSS) concepts. We evaluate the efficacy of our proposed reward in unsignalized intersection scenarios with varying traffic densities. The approach decreases collision rates by 21\% on average compared to baseline rewards and consistently surpasses them in route progress and cumulative reward, demonstrating its capability to promote safer driving behaviors while maintaining high-performance levels.
Constrained Meta Agnostic Reinforcement Learning
Jun 20, 2024Meta-Reinforcement Learning (Meta-RL) aims to acquire meta-knowledge for quick adaptation to diverse tasks. However, applying these policies in real-world environments presents a significant challenge in balancing rapid adaptability with adherence to environmental constraints. Our novel approach, Constraint Model Agnostic Meta Learning (C-MAML), merges meta learning with constrained optimization to address this challenge. C-MAML enables rapid and efficient task adaptation by incorporating task-specific constraints directly into its meta-algorithm framework during the training phase. This fusion results in safer initial parameters for learning new tasks. We demonstrate the effectiveness of C-MAML in simulated locomotion with wheeled robot tasks of varying complexity, highlighting its practicality and robustness in dynamic environments.
UMAD: Unsupervised Mask-Level Anomaly Detection for Autonomous Driving
Jun 10, 2024



Dealing with atypical traffic scenarios remains a challenging task in autonomous driving. However, most anomaly detection approaches cannot be trained on raw sensor data but require exposure to outlier data and powerful semantic segmentation models trained in a supervised fashion. This limits the representation of normality to labeled data, which does not scale well. In this work, we revisit unsupervised anomaly detection and present UMAD, leveraging generative world models and unsupervised image segmentation. Our method outperforms state-of-the-art unsupervised anomaly detection.
Hybrid Video Anomaly Detection for Anomalous Scenarios in Autonomous Driving
Jun 10, 2024



In autonomous driving, the most challenging scenarios are the ones that can only be detected within their temporal context. Most video anomaly detection approaches focus either on surveillance or traffic accidents, which are only a subfield of autonomous driving. In this work, we present HF$^2$-VAD$_{AD}$, a variation of the HF$^2$-VAD surveillance video anomaly detection method for autonomous driving. We learn a representation of normality from a vehicle's ego perspective and evaluate pixel-wise anomaly detections in rare and critical scenarios.
Informed Reinforcement Learning for Situation-Aware Traffic Rule Exceptions
Feb 06, 2024Reinforcement Learning is a highly active research field with promising advancements. In the field of autonomous driving, however, often very simple scenarios are being examined. Common approaches use non-interpretable control commands as the action space and unstructured reward designs which lack structure. In this work, we introduce Informed Reinforcement Learning, where a structured rulebook is integrated as a knowledge source. We learn trajectories and asses them with a situation-aware reward design, leading to a dynamic reward which allows the agent to learn situations which require controlled traffic rule exceptions. Our method is applicable to arbitrary RL models. We successfully demonstrate high completion rates of complex scenarios with recent model-based agents.
Exploring the Potential of World Models for Anomaly Detection in Autonomous Driving
Aug 10, 2023



In recent years there have been remarkable advancements in autonomous driving. While autonomous vehicles demonstrate high performance in closed-set conditions, they encounter difficulties when confronted with unexpected situations. At the same time, world models emerged in the field of model-based reinforcement learning as a way to enable agents to predict the future depending on potential actions. This led to outstanding results in sparse reward and complex control tasks. This work provides an overview of how world models can be leveraged to perform anomaly detection in the domain of autonomous driving. We provide a characterization of world models and relate individual components to previous works in anomaly detection to facilitate further research in the field.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022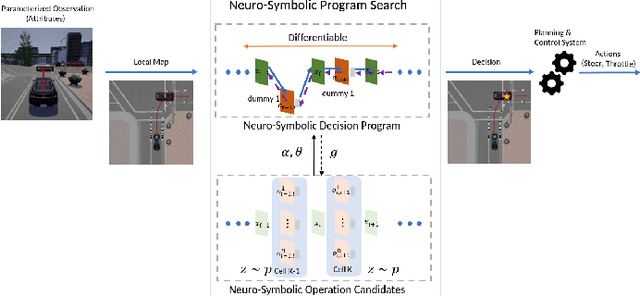
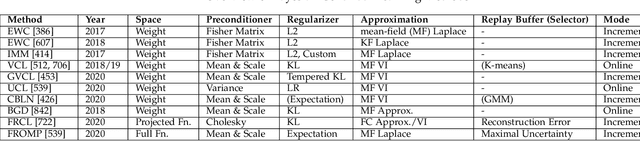
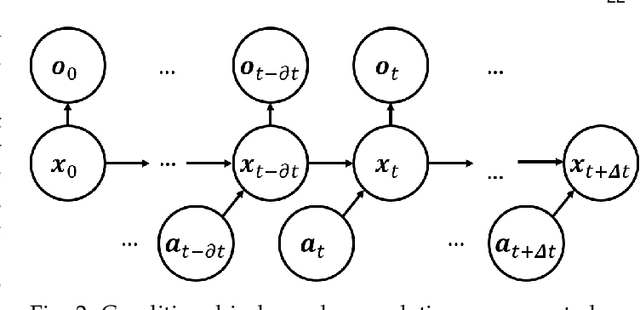
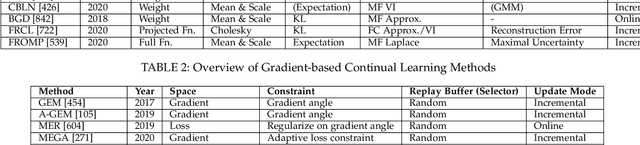
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Cycle-Consistent World Models for Domain Independent Latent Imagination
Oct 02, 2021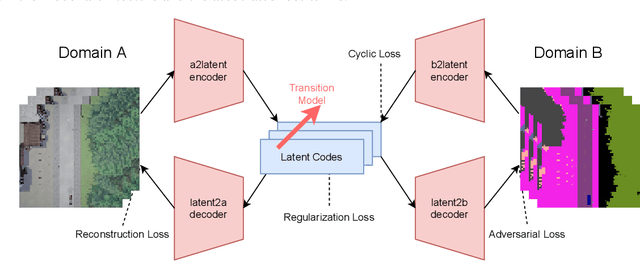


End-to-end autonomous driving seeks to solve the perception, decision, and control problems in an integrated way, which can be easier to generalize at scale and be more adapting to new scenarios. However, high costs and risks make it very hard to train autonomous cars in the real world. Simulations can therefore be a powerful tool to enable training. Due to slightly different observations, agents trained and evaluated solely in simulation often perform well there but have difficulties in real-world environments. To tackle this problem, we propose a novel model-based reinforcement learning approach called Cycleconsistent World Models. Contrary to related approaches, our model can embed two modalities in a shared latent space and thereby learn from samples in one modality (e.g., simulated data) and be used for inference in different domain (e.g., real-world data). Our experiments using different modalities in the CARLA simulator showed that this enables CCWM to outperform state-of-the-art domain adaptation approaches. Furthermore, we show that CCWM can decode a given latent representation into semantically coherent observations in both modalities.