 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIF: An Objective Quality Assessment for Underwater Image Enhancement
May 19, 2022


Due to complex and volatile lighting environment, underwater imaging can be readily impaired by light scattering, warping, and noises. To improve the visual quality, Underwater Image Enhancement (UIE) techniques have been widely studied. Recent efforts have also been contributed to evaluate and compare the UIE performances with subjective and objective methods. However, the subjective evaluation is time-consuming and uneconomic for all images, while existing objective methods have limited capabilities for the newly-developed UIE approaches based on deep learning. To fill this gap, we propose an Underwater Image Fidelity (UIF) metric for objective evaluation of enhanced underwater images. By exploiting the statistical features of these images, we present to extract naturalness-related, sharpness-related, and structure-related features. Among them, the naturalness-related and sharpness-related features evaluate visual improvement of enhanced images; the structure-related feature indicates structural similarity between images before and after UIE. Then, we employ support vector regression to fuse the above three features into a final UIF metric. In addition, we have also established a large-scale UIE database with subjective scores, namely Underwater Image Enhancement Database (UIED), which is utilized as a benchmark to compare all objective metrics. Experimental results confirm that the proposed UIF outperforms a variety of underwater and general-purpose image quality metrics.
Deep Quality Assessment of Compressed Videos: A Subjective and Objective Study
May 07, 2022
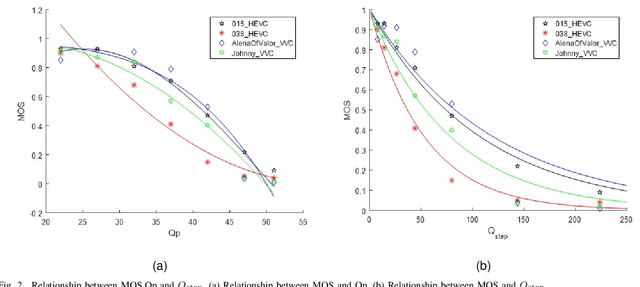
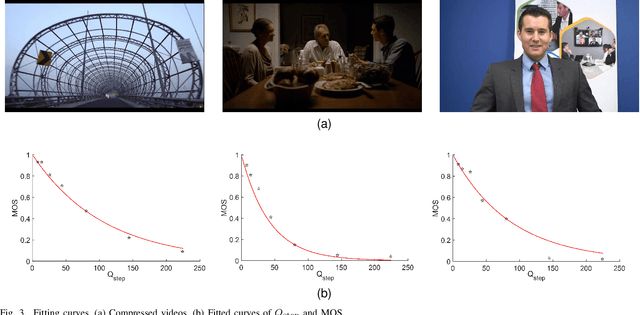
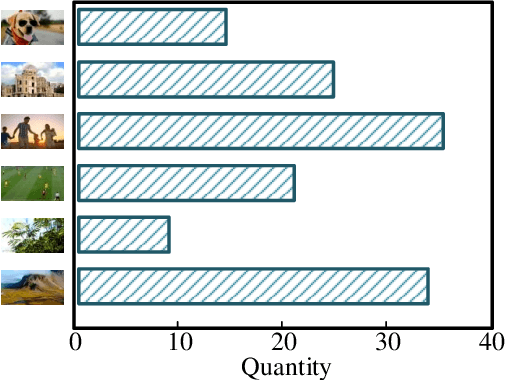
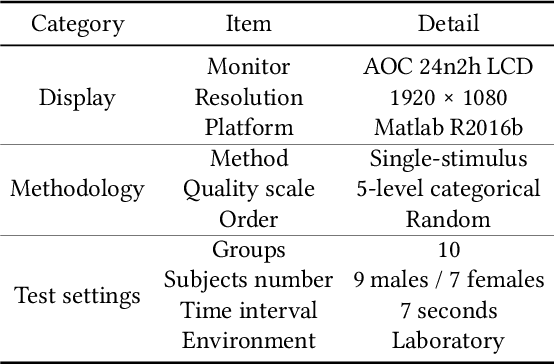
In the video coding process, the perceived quality of a compressed video is evaluated by full-reference quality evaluation metrics. However, it is difficult to obtain reference videos with perfect quality. To solve this problem, it is critical to design no-reference compressed video quality assessment algorithms, which assists in measuring the quality of experience on the server side and resource allocation on the network side. Convolutional Neural Network (CNN) has shown its advantage in Video Quality Assessment (VQA) with promising successes in recent years. A large-scale quality database is very important for learning accurate and powerful compressed video quality metrics. In this work, a semi-automatic labeling method is adopted to build a large-scale compressed video quality database, which allows us to label a large number of compressed videos with manageable human workload. The resulting Compressed Video quality database with Semi-Automatic Ratings (CVSAR), so far the largest of compressed video quality database. We train a no-reference compressed video quality assessment model with a 3D CNN for SpatioTemporal Feature Extraction and Evaluation (STFEE). Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics and achieves promising generalization performance in cross-database tests. The CVSAR database and STFEE model will be made publicly available to facilitate reproducible research.
Multi-View Video Coding with GAN Latent Learning
May 07, 2022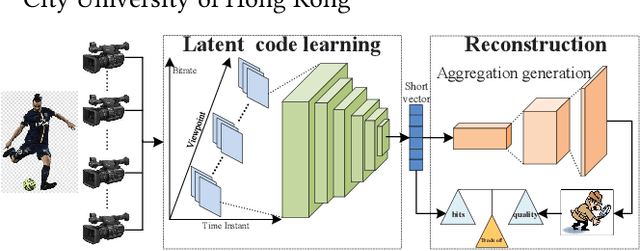

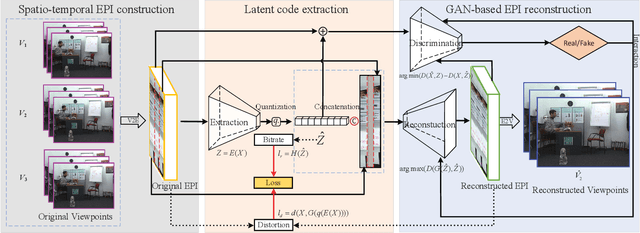

The introduction of multiple viewpoints inevitably increases the bitrates to store and transmit video scenes. To reduce the compressed bitrates, researchers have developed to skip intermediate viewpoints during compression and delivery, and finally reconstruct them with Side Information (SI). Generally, the depth maps can be utilized to construct SI; however, it shows inferior performance with inaccurate reconstruction or high bitrates. In this paper, we propose a multi-view video coding based on SI of Generative Adversarial Network (GAN). At the encoder, we construct a spatio-temporal Epipolar Plane Image (EPI) and further utilize convolutional network to extract the latent code of GAN as SI; while at the decoder side, we combine the SI and adjacent viewpoints to reconstruct intermediate views by the generator of GAN. In particular, we set a joint encoder constraint of reconstruction cost and SI entropy, in order to achieve an optimal tradeoff between reconstruction quality and bitrate overhead. Experiments show a significantly improved Rate-Distortion (RD) performance compared with the state-of-the-art methods.
Efficient VVC Intra Prediction Based on Deep Feature Fusion and Probability Estimation
May 07, 2022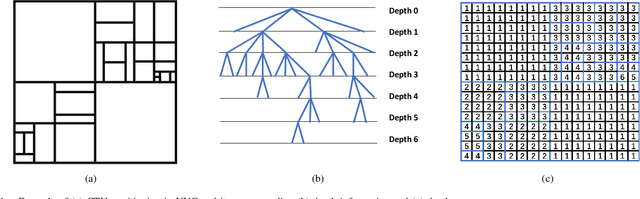
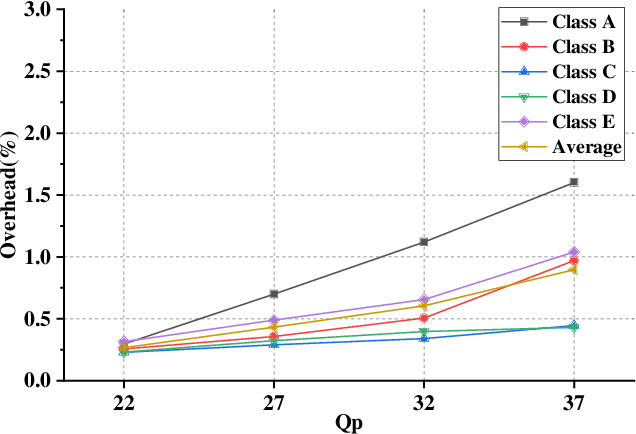
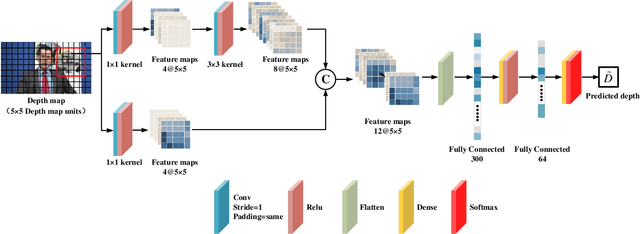
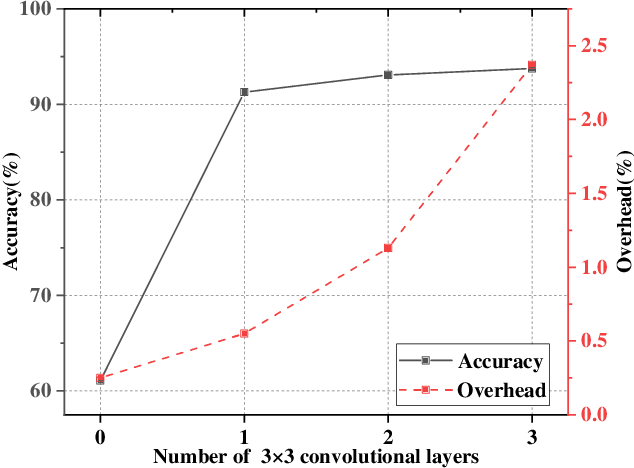
The ever-growing multimedia traffic has underscored the importance of effective multimedia codecs. Among them, the up-to-date lossy video coding standard, Versatile Video Coding (VVC), has been attracting attentions of video coding community. However, the gain of VVC is achieved at the cost of significant encoding complexity, which brings the need to realize fast encoder with comparable Rate Distortion (RD) performance. In this paper, we propose to optimize the VVC complexity at intra-frame prediction, with a two-stage framework of deep feature fusion and probability estimation. At the first stage, we employ the deep convolutional network to extract the spatialtemporal neighboring coding features. Then we fuse all reference features obtained by different convolutional kernels to determine an optimal intra coding depth. At the second stage, we employ a probability-based model and the spatial-temporal coherence to select the candidate partition modes within the optimal coding depth. Finally, these selected depths and partitions are executed whilst unnecessary computations are excluded. Experimental results on standard database demonstrate the superiority of proposed method, especially for High Definition (HD) and Ultra-HD (UHD) video sequences.
SPQE: Structure-and-Perception-Based Quality Evaluation for Image Super-Resolution
May 07, 2022
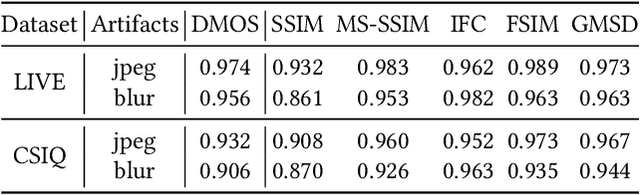

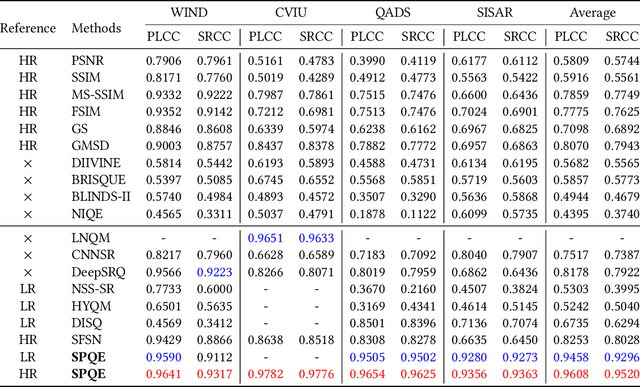
The image Super-Resolution (SR) technique has greatly improved the visual quality of images by enhancing their resolutions. It also calls for an efficient SR Image Quality Assessment (SR-IQA) to evaluate those algorithms or their generated images. In this paper, we focus on the SR-IQA under deep learning and propose a Structure-and-Perception-based Quality Evaluation (SPQE). In emerging deep-learning-based SR, a generated high-quality, visually pleasing image may have different structures from its corresponding low-quality image. In such case, how to balance the quality scores between no-reference perceptual quality and referenced structural similarity is a critical issue. To help ease this problem, we give a theoretical analysis on this tradeoff and further calculate adaptive weights for the two types of quality scores. We also propose two deep-learning-based regressors to model the no-reference and referenced scores. By combining the quality scores and their weights, we propose a unified SPQE metric for SR-IQA. Experimental results demonstrate that the proposed method outperforms the state-of-the-arts in different datasets.
Utility-Oriented Underwater Image Quality Assessment Based on Transfer Learning
May 07, 2022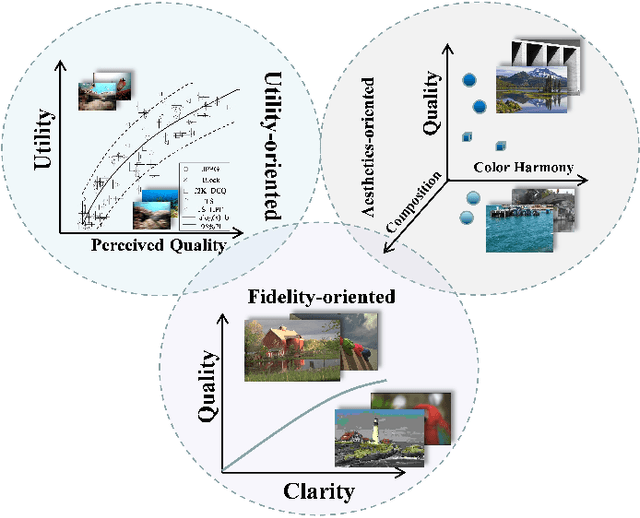

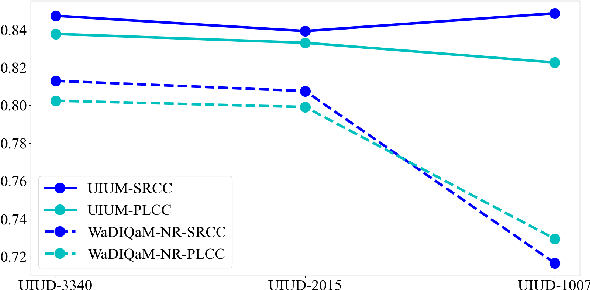
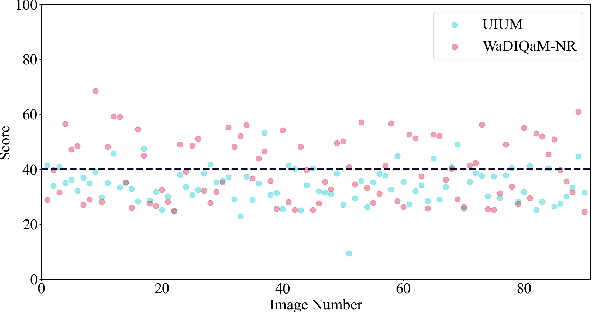
The widespread image applications have greatly promoted the vision-based tasks, in which the Image Quality Assessment (IQA) technique has become an increasingly significant issue. For user enjoyment in multimedia systems, the IQA exploits image fidelity and aesthetics to characterize user experience; while for other tasks such as popular object recognition, there exists a low correlation between utilities and perceptions. In such cases, the fidelity-based and aesthetics-based IQA methods cannot be directly applied. To address this issue, this paper proposes a utility-oriented IQA in object recognition. In particular, we initialize our research in the scenario of underwater fish detection, which is a critical task that has not yet been perfectly addressed. Based on this task, we build an Underwater Image Utility Database (UIUD) and a learning-based Underwater Image Utility Measure (UIUM). Inspired by the top-down design of fidelity-based IQA, we exploit the deep models of object recognition and transfer their features to our UIUM. Experiments validate that the proposed transfer-learning-based UIUM achieves promising performance in the recognition task. We envision our research provides insights to bridge the researches of IQA and computer vision.
Deep Video Coding with Dual-Path Generative Adversarial Network
Nov 29, 2021

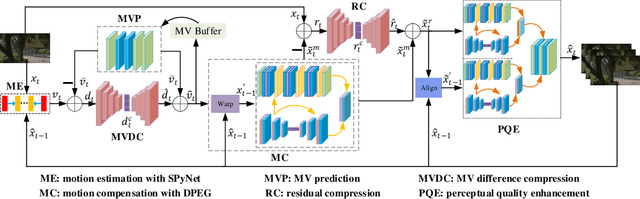
The deep-learning-based video coding has attracted substantial attention for its great potential to squeeze out the spatial-temporal redundancies of video sequences. This paper proposes an efficient codec namely dual-path generative adversarial network-based video codec (DGVC). First, we propose a dual-path enhancement with generative adversarial network (DPEG) to reconstruct the compressed video details. The DPEG consists of an $\alpha$-path of auto-encoder and convolutional long short-term memory (ConvLSTM), which facilitates the structure feature reconstruction with a large receptive field and multi-frame references, and a $\beta$-path of residual attention blocks, which facilitates the reconstruction of local texture features. Both paths are fused and co-trained by a generative-adversarial process. Second, we reuse the DPEG network in both motion compensation and quality enhancement modules, which are further combined with motion estimation and entropy coding modules in our DGVC framework. Third, we employ a joint training of deep video compression and enhancement to further improve the rate-distortion (RD) performance. Compared with x265 LDP very fast mode, our DGVC reduces the average bit-per-pixel (bpp) by 39.39%/54.92% at the same PSNR/MS-SSIM, which outperforms the state-of-the art deep video codecs by a considerable margin.
Contrastive Semantic Similarity Learning for Image Captioning Evaluation with Intrinsic Auto-encoder
Jun 29, 2021
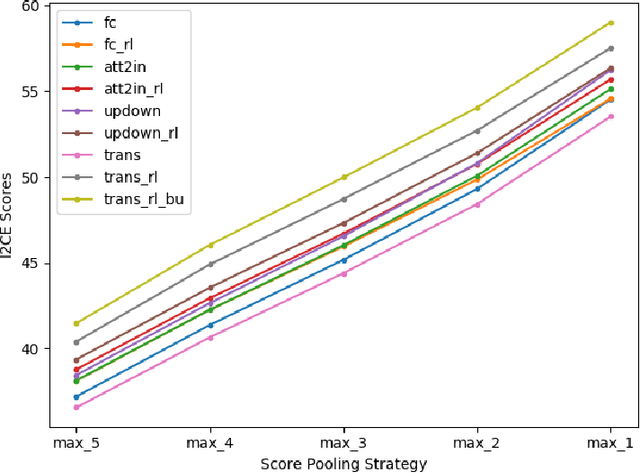
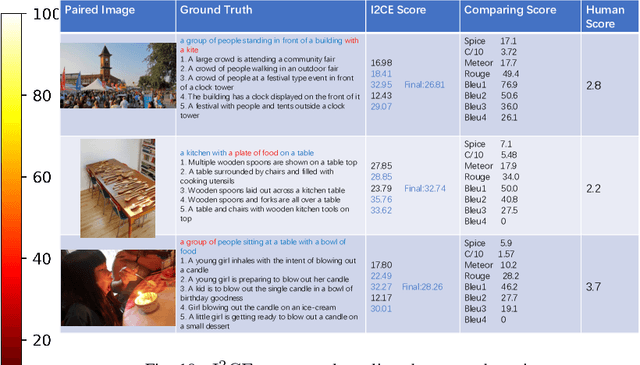
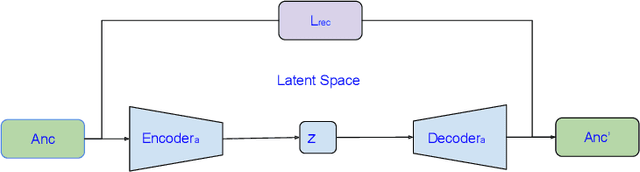
Automatically evaluating the quality of image captions can be very challenging since human language is quite flexible that there can be various expressions for the same meaning. Most of the current captioning metrics rely on token level matching between candidate caption and the ground truth label sentences. It usually neglects the sentence-level information. Motivated by the auto-encoder mechanism and contrastive representation learning advances, we propose a learning-based metric for image captioning, which we call Intrinsic Image Captioning Evaluation($I^2CE$). We develop three progressive model structures to learn the sentence level representations--single branch model, dual branches model, and triple branches model. Our empirical tests show that $I^2CE$ trained with dual branches structure achieves better consistency with human judgments to contemporary image captioning evaluation metrics. Furthermore, We select several state-of-the-art image captioning models and test their performances on the MS COCO dataset concerning both contemporary metrics and the proposed $I^2CE$. Experiment results show that our proposed method can align well with the scores generated from other contemporary metrics. On this concern, the proposed metric could serve as a novel indicator of the intrinsic information between captions, which may be complementary to the existing ones.
Learning-Based Quality Assessment for Image Super-Resolution
Dec 16, 2020
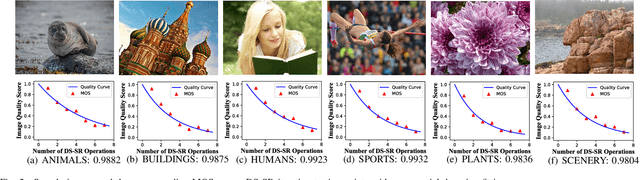

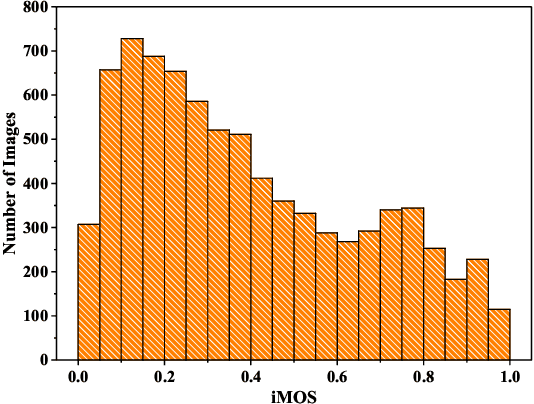
Image Super-Resolution (SR) techniques improve visual quality by enhancing the spatial resolution of images. Quality evaluation metrics play a critical role in comparing and optimizing SR algorithms, but current metrics achieve only limited success, largely due to the lack of large-scale quality databases, which are essential for learning accurate and robust SR quality metrics. In this work, we first build a large-scale SR image database using a novel semi-automatic labeling approach, which allows us to label a large number of images with manageable human workload. The resulting SR Image quality database with Semi-Automatic Ratings (SISAR), so far the largest of SR-IQA database, contains 8,400 images of 100 natural scenes. We train an end-to-end Deep Image SR Quality (DISQ) model by employing two-stream Deep Neural Networks (DNNs) for feature extraction, followed by a feature fusion network for quality prediction. Experimental results demonstrate that the proposed method outperforms state-of-the-art metrics and achieves promising generalization performance in cross-database tests. The SISAR database and DISQ model will be made publicly available to facilitate reproducible research.
PEA265: Perceptual Assessment of Video Compression Artifacts
Mar 01, 2019
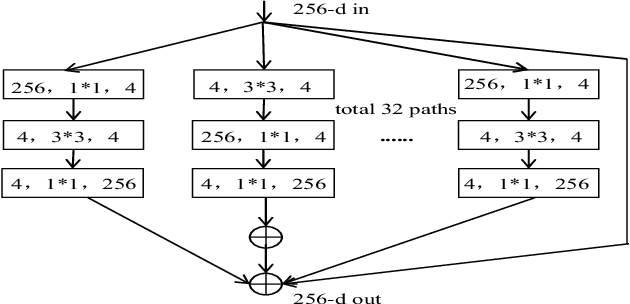
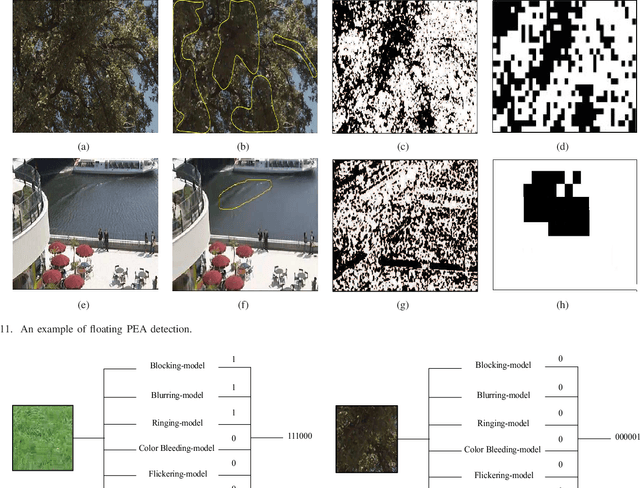
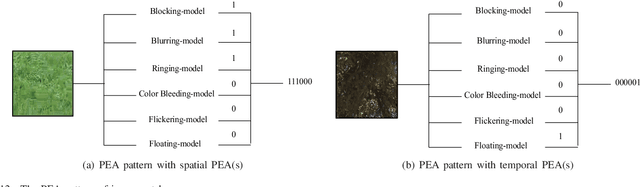
The most widely used video encoders share a common hybrid coding framework that includes block-based motion estimation/compensation and block-based transform coding. Despite their high coding efficiency, the encoded videos often exhibit visually annoying artifacts, denoted as Perceivable Encoding Artifacts (PEAs), which significantly degrade the visual Qualityof- Experience (QoE) of end users. To monitor and improve visual QoE, it is crucial to develop subjective and objective measures that can identify and quantify various types of PEAs. In this work, we make the first attempt to build a large-scale subjectlabelled database composed of H.265/HEVC compressed videos containing various PEAs. The database, namely the PEA265 database, includes 4 types of spatial PEAs (i.e. blurring, blocking, ringing and color bleeding) and 2 types of temporal PEAs (i.e. flickering and floating). Each containing at least 60,000 image or video patches with positive and negative labels. To objectively identify these PEAs, we train Convolutional Neural Networks (CNNs) using the PEA265 database. It appears that state-of-theart ResNeXt is capable of identifying each type of PEAs with high accuracy. Furthermore, we define PEA pattern and PEA intensity measures to quantify PEA levels of compressed video sequence. We believe that the PEA265 database and our findings will benefit the future development of video quality assessment methods and perceptually motivated video encoders.