 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeScale: Distributed Training for Sequence Recommendation Models with Minimal Scaling Cost
Apr 27, 2026Modern industrial Deep Learning Recommendation Models typically extract user preferences through the analysis of sequential interaction histories, subsequently generating predictions based on these derived interests. The inherent heterogeneity in data characteristics frequently result in substantial under-utilization of computational resources during large-scale training, primarily due to computational bubbles caused by severe stragglers and slow blocking communications. This paper introduces FreeScale, a solution designed to (1) mitigate the straggler problem through meticulously load balanced input samples (2) minimize the blocking communication by overlapping prioritized embedding communications with computations (3) resolve the GPU resource competition during computation and communication overlapping by communicating through SM-Free techniques. Empirical evaluation demonstrates that FreeScale achieves up to 90.3% reduction in computational bubbles when applied to real-world workloads running on 256 H100 GPUs.
Clique: Spatiotemporal Object Re-identification at the City Scale
Dec 17, 2020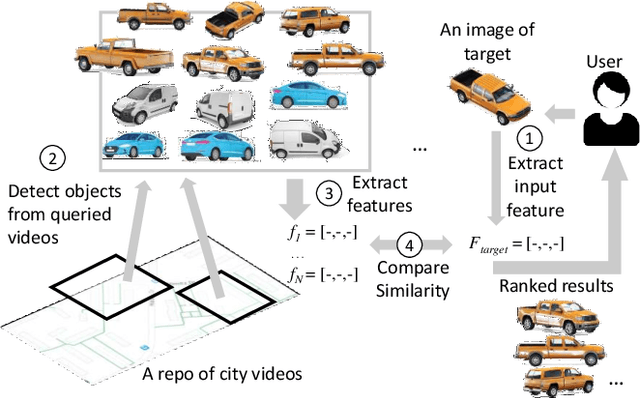

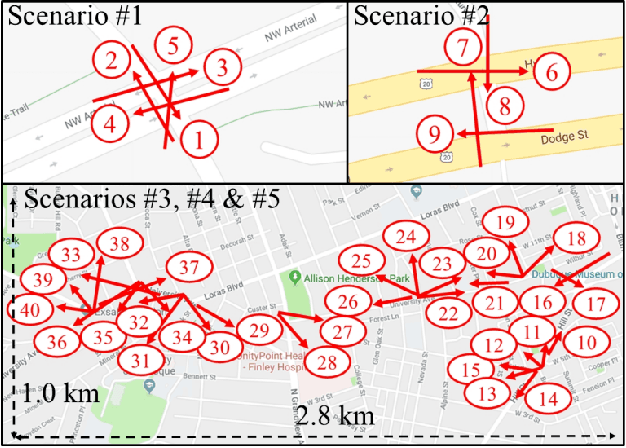
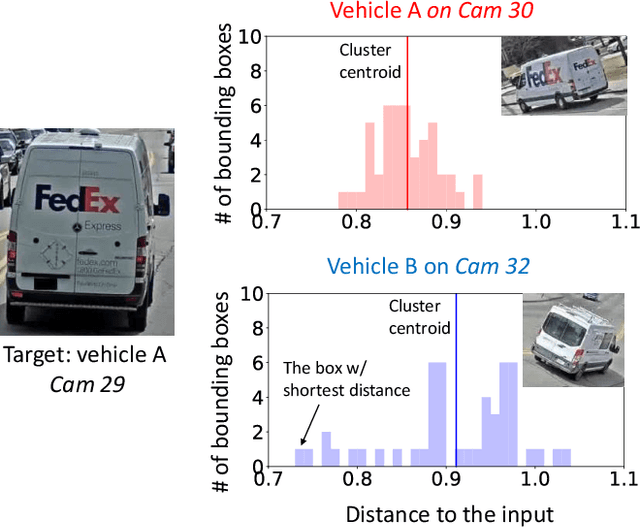
Object re-identification (ReID) is a key application of city-scale cameras. While classic ReID tasks are often considered as image retrieval, we treat them as spatiotemporal queries for locations and times in which the target object appeared. Spatiotemporal reID is challenged by the accuracy limitation in computer vision algorithms and the colossal videos from city cameras. We present Clique, a practical ReID engine that builds upon two new techniques: (1) Clique assesses target occurrences by clustering fuzzy object features extracted by ReID algorithms, with each cluster representing the general impression of a distinct object to be matched against the input; (2) to search in videos, Clique samples cameras to maximize the spatiotemporal coverage and incrementally adds cameras for processing on demand. Through evaluation on 25 hours of videos from 25 cameras, Clique reached a high accuracy of 0.87 (recall at 5) across 70 queries and runs at 830x of video realtime in achieving high accuracy.
Supporting Video Queries on Zero-Streaming Cameras
Apr 30, 2019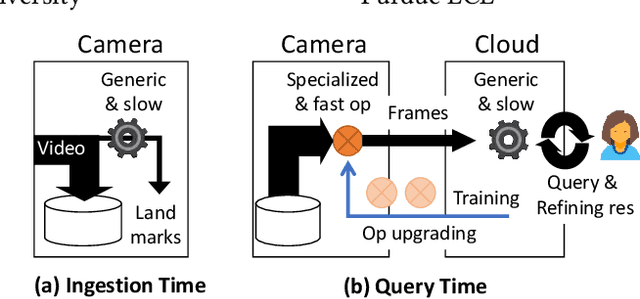
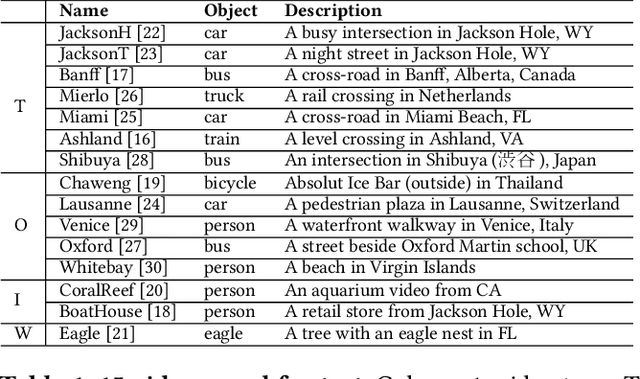
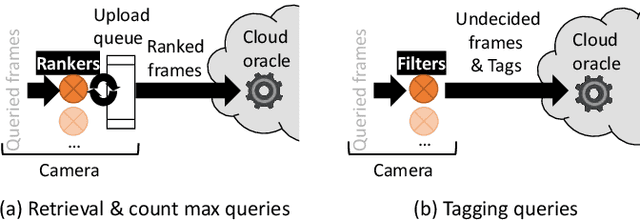

As low-cost surveillance cameras proliferate, we advocate for these cameras to be zero streaming: ingesting videos directly to their local storage and only communicating with the cloud in response to queries. To support queries over videos stored on zero-streaming cameras, we describe a system that spans the cloud and cameras. The system builds on two unconventional ideas. When ingesting video frames, a camera learns accurate knowledge on a sparse sample of frames, rather than learning inaccurate knowledge on all frames; in executing one query, a camera processes frames in multiple passes with multiple operators trained and picked by the cloud during the query, rather than one-pass processing with operator(s) decided ahead of the query. On diverse queries over 720-hour videos and with typical wireless network bandwidth and low-cost camera hardware, our system runs at more than 100x video realtime. It outperforms competitive alternative designs by at least 4x and up to two orders of magnitude.