 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Evaluate the Generalization of Detection? A Benchmark for Comprehensive Open-Vocabulary Detection
Aug 25, 2023



Object detection (OD) in computer vision has made significant progress in recent years, transitioning from closed-set labels to open-vocabulary detection (OVD) based on large-scale vision-language pre-training (VLP). However, current evaluation methods and datasets are limited to testing generalization over object types and referral expressions, which do not provide a systematic, fine-grained, and accurate benchmark of OVD models' abilities. In this paper, we propose a new benchmark named OVDEval, which includes 9 sub-tasks and introduces evaluations on commonsense knowledge, attribute understanding, position understanding, object relation comprehension, and more. The dataset is meticulously created to provide hard negatives that challenge models' true understanding of visual and linguistic input. Additionally, we identify a problem with the popular Average Precision (AP) metric when benchmarking models on these fine-grained label datasets and propose a new metric called Non-Maximum Suppression Average Precision (NMS-AP) to address this issue. Extensive experimental results show that existing top OVD models all fail on the new tasks except for simple object types, demonstrating the value of the proposed dataset in pinpointing the weakness of current OVD models and guiding future research. Furthermore, the proposed NMS-AP metric is verified by experiments to provide a much more truthful evaluation of OVD models, whereas traditional AP metrics yield deceptive results. Data is available at \url{https://github.com/om-ai-lab/OVDEval}
RS5M: A Large Scale Vision-Language Dataset for Remote Sensing Vision-Language Foundation Model
Jun 20, 2023Pre-trained Vision-Language Foundation Models utilizing extensive image-text paired data have demonstrated unprecedented image-text association capabilities, achieving remarkable results across various downstream tasks. A critical challenge is how to make use of existing large-scale pre-trained VLMs, which are trained on common objects, to perform the domain-specific transfer for accomplishing domain-related downstream tasks. In this paper, we propose a new framework that includes the Domain Foundation Model (DFM), bridging the gap between the General Foundation Model (GFM) and domain-specific downstream tasks. Moreover, we present an image-text paired dataset in the field of remote sensing (RS), RS5M, which has 5 million RS images with English descriptions. The dataset is obtained from filtering publicly available image-text paired datasets and captioning label-only RS datasets with pre-trained VLM. These constitute the first large-scale RS image-text paired dataset. Additionally, we tried several Parameter-Efficient Fine-Tuning methods on RS5M to implement the DFM. Experimental results show that our proposed dataset are highly effective for various tasks, improving upon the baseline by $8 \% \sim 16 \%$ in zero-shot classification tasks, and obtaining good results in both Vision-Language Retrieval and Semantic Localization tasks. Finally, we show successful results of training the RS Stable Diffusion model using the RS5M, uncovering more use cases of the dataset.
OmDet: Language-Aware Object Detection with Large-scale Vision-Language Multi-dataset Pre-training
Sep 10, 2022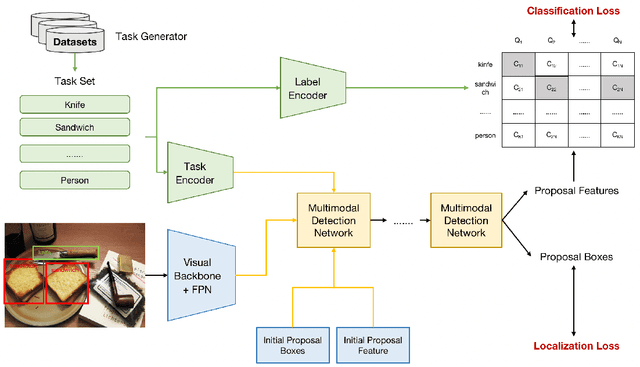


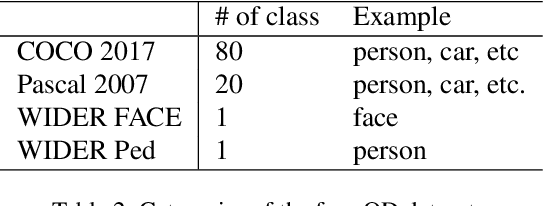
Advancing object detection to open-vocabulary and few-shot transfer has long been a challenge for computer vision research. This work explores a continual learning approach that enables a detector to expand its zero/few-shot capabilities via multi-dataset vision-language pre-training. Using natural language as knowledge representation, we explore methods to accumulate "visual vocabulary" from different training datasets and unify the task as a language-conditioned detection framework. Specifically, we propose a novel language-aware detector OmDet and a novel training mechanism. The proposed multimodal detection network can resolve the technical challenges in multi-dataset joint training and it can generalize to arbitrary number of training datasets without the requirements for manual label taxonomy merging. Experiment results on COCO, Pascal VOC, and Wider Face/Pedestrian confirmed the efficacy by achieving on par or higher scores in joint training compared to training separately. Moreover, we pre-train on more than 20 million images with 4 million unique object vocabulary, and the resulting model is evaluated on 35 downstream tasks of ODinW. Results show that OmDet is able to achieve the state-of-the-art fine-tuned performance on ODinW. And analysis shows that by scaling up the proposed pre-training method, OmDet continues to improve its zero/few-shot tuning performance, suggesting a promising way for further scaling.
Understanding the Effect of Data Augmentation in Self-supervised Anomaly Detection
Aug 30, 2022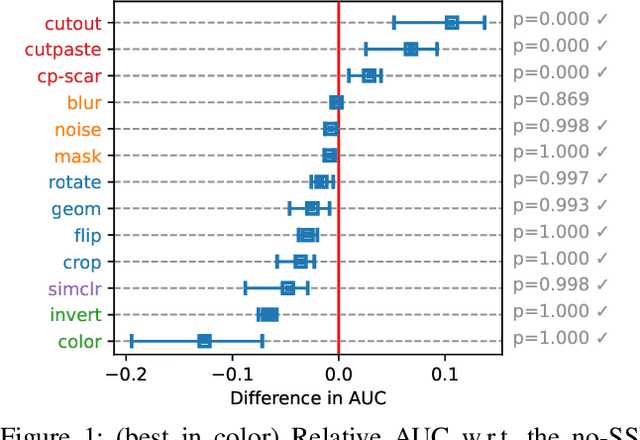
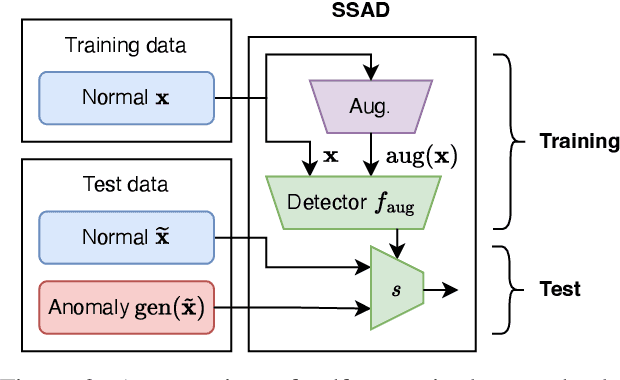
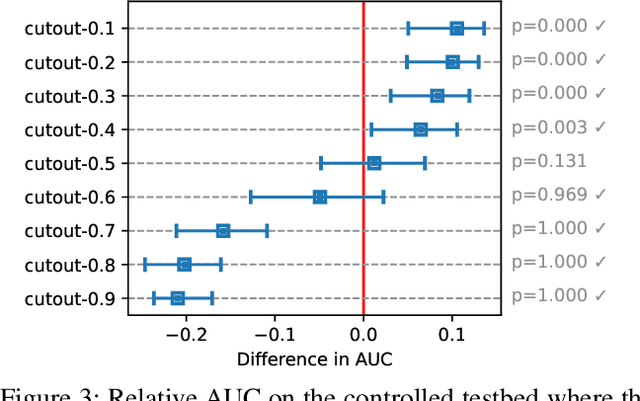
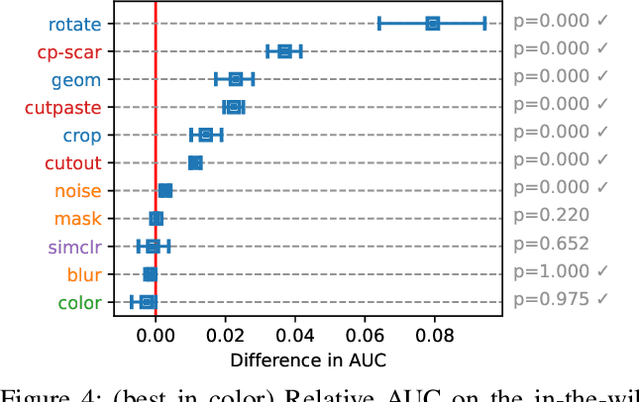
Self-supervised learning (SSL) has emerged as a promising alternative to create supervisory signals to real-world tasks, avoiding extensive cost of careful labeling. SSL is particularly attractive for unsupervised problems such as anomaly detection (AD), where labeled anomalies are costly to secure, difficult to simulate, or even nonexistent. A large catalog of augmentation functions have been used for SSL-based AD (SSAD), and recent works have observed that the type of augmentation has a significant impact on performance. Motivated by those, this work sets out to put SSAD under a larger lens and carefully investigate the role of data augmentation in AD through extensive experiments on many testbeds. Our main finding is that self-supervision acts as a yet-another model hyperparameter, and should be chosen carefully in regards to the nature of true anomalies in the data. That is, the alignment between the augmentation and the underlying anomaly-generating mechanism is the key for the success of SSAD, and in the lack thereof, SSL can even impair (!) detection performance. Moving beyond proposing another SSAD method, our study contributes to the better understanding of this growing area and lays out new directions for future research.
VL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations
Jul 01, 2022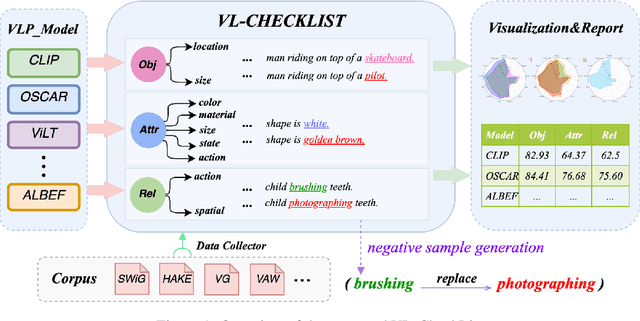
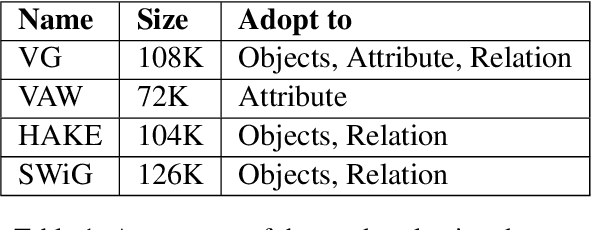
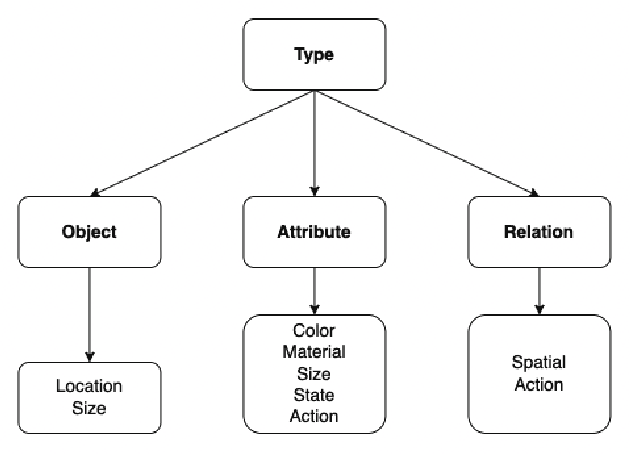
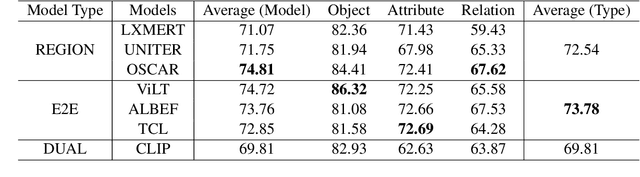
Vision-Language Pretraining (VLP) models have recently successfully facilitated many cross-modal downstream tasks. Most existing works evaluated their systems by comparing the fine-tuned downstream task performance. However, only average downstream task accuracy provides little information about the pros and cons of each VLP method, let alone provides insights on how the community can improve the systems in the future. Inspired by the CheckList for testing natural language processing, we introduce VL-CheckList, a novel framework to understand the capabilities of VLP models. The proposed method divides the image-texting ability of a VLP model into three categories: objects, attributes, and relations, and uses a novel taxonomy to further break down these three aspects. We conduct comprehensive studies to analyze seven recently popular VLP models via the proposed framework. Results confirm the effectiveness of the proposed method by revealing fine-grained differences among the compared models that were not visible from downstream task-only evaluation. Further results show promising research direction in building better VLP models. Data and Code: https://github.com/om-ai-lab/VL-CheckList
SF-QA: Simple and Fair Evaluation Library for Open-domain Question Answering
Jan 06, 2021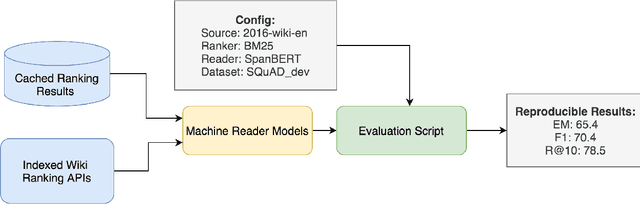
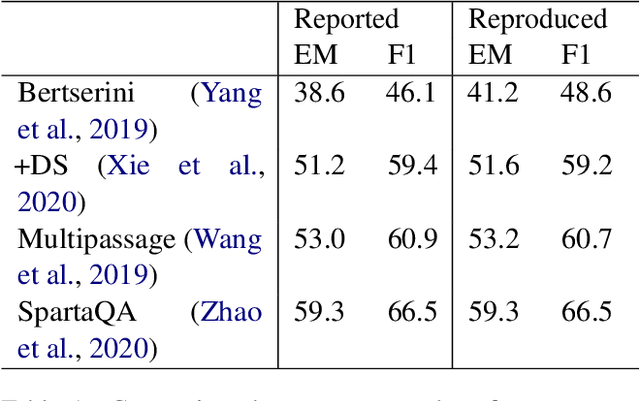
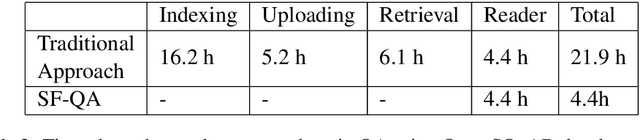

Although open-domain question answering (QA) draws great attention in recent years, it requires large amounts of resources for building the full system and is often difficult to reproduce previous results due to complex configurations. In this paper, we introduce SF-QA: simple and fair evaluation framework for open-domain QA. SF-QA framework modularizes the pipeline open-domain QA system, which makes the task itself easily accessible and reproducible to research groups without enough computing resources. The proposed evaluation framework is publicly available and anyone can contribute to the code and evaluations.
VisualSparta: Sparse Transformer Fragment-level Matching for Large-scale Text-to-Image Search
Jan 01, 2021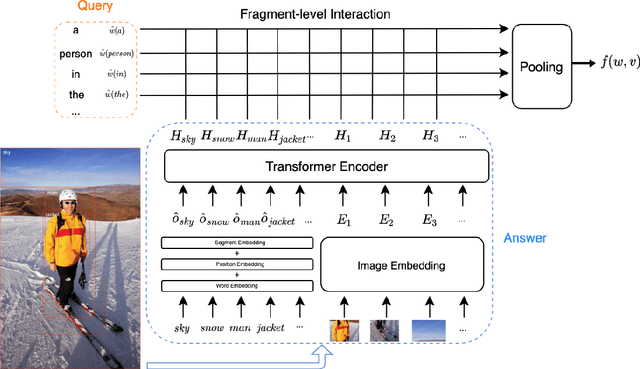
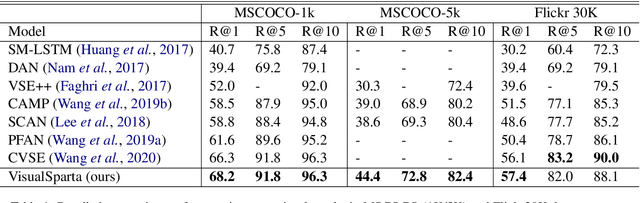
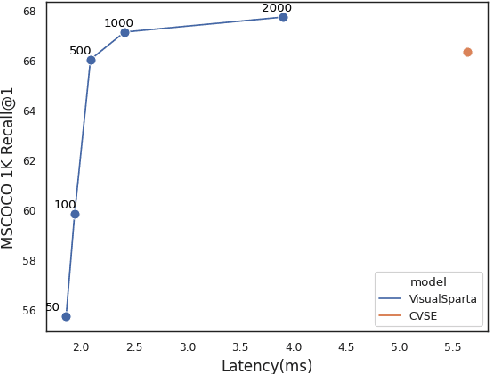
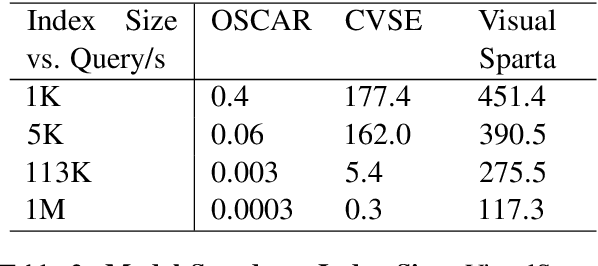
Text-to-image retrieval is an essential task in multi-modal information retrieval, i.e. retrieving relevant images from a large and unlabelled image dataset given textual queries. In this paper, we propose VisualSparta, a novel text-to-image retrieval model that shows substantial improvement over existing models on both accuracy and efficiency. We show that VisualSparta is capable of outperforming all previous scalable methods in MSCOCO and Flickr30K. It also shows substantial retrieving speed advantages, i.e. for an index with 1 million images, VisualSparta gets over 391x speed up compared to standard vector search. Experiments show that this speed advantage even gets bigger for larger datasets because VisualSparta can be efficiently implemented as an inverted index. To the best of our knowledge, VisualSparta is the first transformer-based text-to-image retrieval model that can achieve real-time searching for very large dataset, with significant accuracy improvement compared to previous state-of-the-art methods.
SPARTA: Efficient Open-Domain Question Answering via Sparse Transformer Matching Retrieval
Sep 28, 2020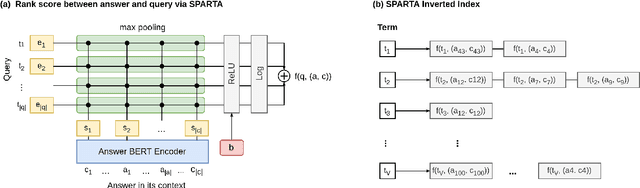
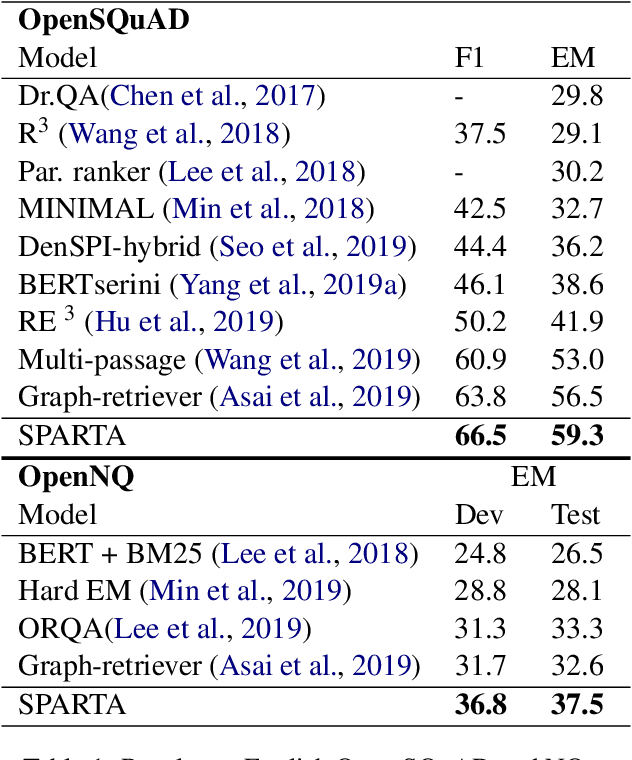
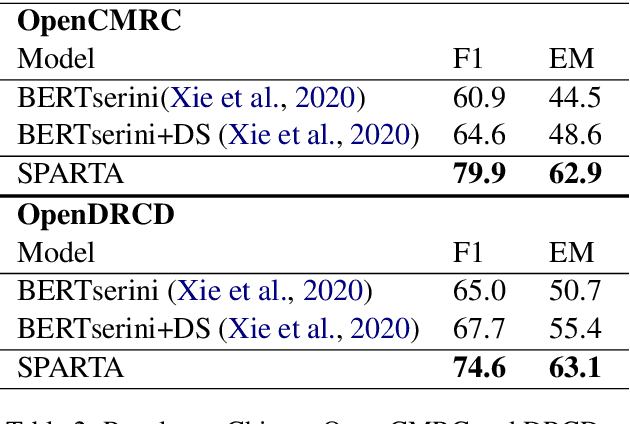
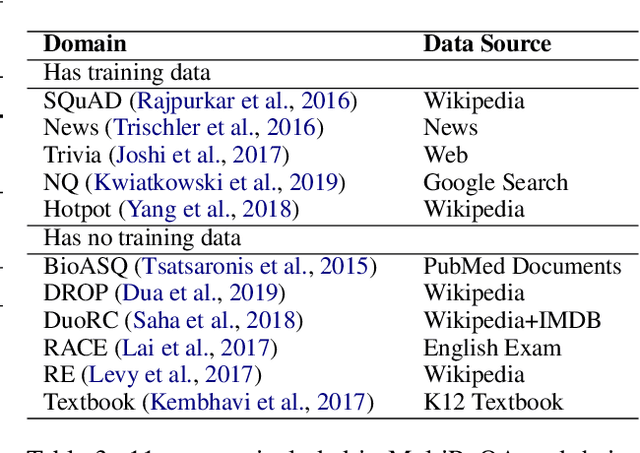
We introduce SPARTA, a novel neural retrieval method that shows great promise in performance, generalization, and interpretability for open-domain question answering. Unlike many neural ranking methods that use dense vector nearest neighbor search, SPARTA learns a sparse representation that can be efficiently implemented as an Inverted Index. The resulting representation enables scalable neural retrieval that does not require expensive approximate vector search and leads to better performance than its dense counterpart. We validated our approaches on 4 open-domain question answering (OpenQA) tasks and 11 retrieval question answering (ReQA) tasks. SPARTA achieves new state-of-the-art results across a variety of open-domain question answering tasks in both English and Chinese datasets, including open SQuAD, Natuarl Question, CMRC and etc. Analysis also confirms that the proposed method creates human interpretable representation and allows flexible control over the trade-off between performance and efficiency.
Report from the NSF Future Directions Workshop, Toward User-Oriented Agents: Research Directions and Challenges
Jun 10, 2020
This USER Workshop was convened with the goal of defining future research directions for the burgeoning intelligent agent research community and to communicate them to the National Science Foundation. It took place in Pittsburgh Pennsylvania on October 24 and 25, 2019 and was sponsored by National Science Foundation Grant Number IIS-1934222. Any opinions, findings and conclusions or future directions expressed in this document are those of the authors and do not necessarily reflect the views of the National Science Foundation. The 27 participants presented their individual research interests and their personal research goals. In the breakout sessions that followed, the participants defined the main research areas within the domain of intelligent agents and they discussed the major future directions that the research in each area of this domain should take
"None of the Above":Measure Uncertainty in Dialog Response Retrieval
Apr 04, 2020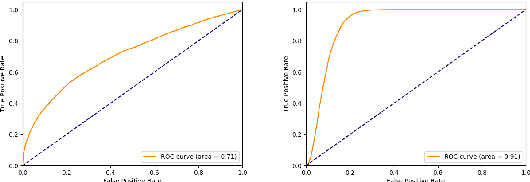
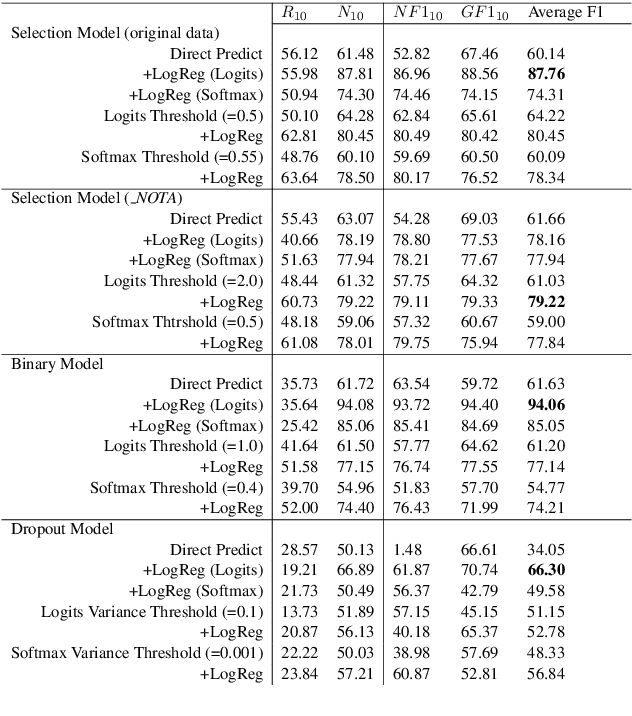
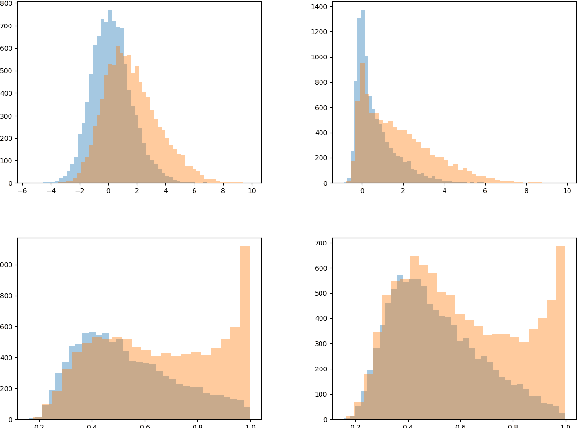
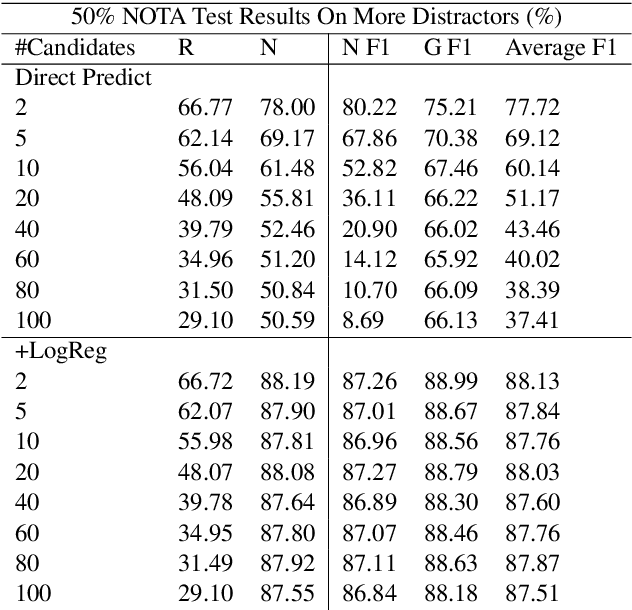
This paper discusses the importance of uncovering uncertainty in end-to-end dialog tasks, and presents our experimental results on uncertainty classification on the Ubuntu Dialog Corpus. We show that, instead of retraining models for this specific purpose, the original retrieval model's underlying confidence concerning the best prediction can be captured with trivial additional computation.