 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-block Min-max Bilevel Optimization with Applications in Multi-task Deep AUC Maximization
Jun 01, 2022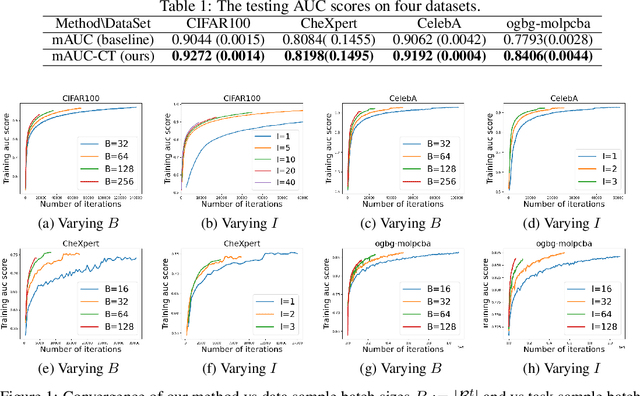
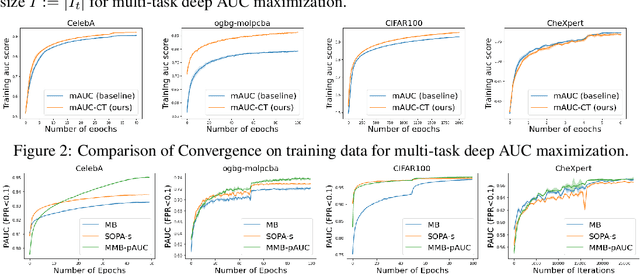
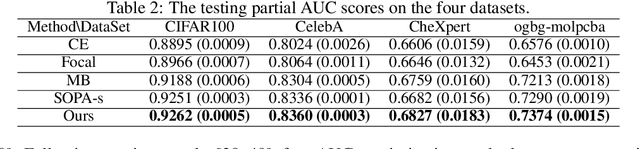
In this paper, we study multi-block min-max bilevel optimization problems, where the upper level is non-convex strongly-concave minimax objective and the lower level is a strongly convex objective, and there are multiple blocks of dual variables and lower level problems. Due to the intertwined multi-block min-max bilevel structure, the computational cost at each iteration could be prohibitively high, especially with a large number of blocks. To tackle this challenge, we present a single-loop randomized stochastic algorithm, which requires updates for only a constant number of blocks at each iteration. Under some mild assumptions on the problem, we establish its sample complexity of $\mathcal{O}(1/\epsilon^4)$ for finding an $\epsilon$-stationary point. This matches the optimal complexity for solving stochastic nonconvex optimization under a general unbiased stochastic oracle model. Moreover, we provide two applications of the proposed method in multi-task deep AUC (area under ROC curve) maximization and multi-task deep partial AUC maximization. Experimental results validate our theory and demonstrate the effectiveness of our method on problems with hundreds of tasks.
Smoothed Online Convex Optimization Based on Discounted-Normal-Predictor
May 02, 2022In this paper, we investigate an online prediction strategy named as Discounted-Normal-Predictor (Kapralov and Panigrahy, 2010) for smoothed online convex optimization (SOCO), in which the learner needs to minimize not only the hitting cost but also the switching cost. In the setting of learning with expert advice, Daniely and Mansour (2019) demonstrate that Discounted-Normal-Predictor can be utilized to yield nearly optimal regret bounds over any interval, even in the presence of switching costs. Inspired by their results, we develop a simple algorithm for SOCO: Combining online gradient descent (OGD) with different step sizes sequentially by Discounted-Normal-Predictor. Despite its simplicity, we prove that it is able to minimize the adaptive regret with switching cost, i.e., attaining nearly optimal regret with switching cost on every interval. By exploiting the theoretical guarantee of OGD for dynamic regret, we further show that the proposed algorithm can minimize the dynamic regret with switching cost in every interval.
Large-scale Stochastic Optimization of NDCG Surrogates for Deep Learning with Provable Convergence
Apr 06, 2022

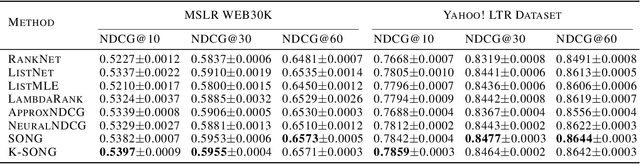

NDCG, namely Normalized Discounted Cumulative Gain, is a widely used ranking metric in information retrieval and machine learning. However, efficient and provable stochastic methods for maximizing NDCG are still lacking, especially for deep models. In this paper, we propose a principled approach to optimize NDCG and its top-$K$ variant. First, we formulate a novel compositional optimization problem for optimizing the NDCG surrogate, and a novel bilevel compositional optimization problem for optimizing the top-$K$ NDCG surrogate. Then, we develop efficient stochastic algorithms with provable convergence guarantees for the non-convex objectives. Different from existing NDCG optimization methods, the per-iteration complexity of our algorithms scales with the mini-batch size instead of the number of total items. To improve the effectiveness for deep learning, we further propose practical strategies by using initial warm-up and stop gradient operator. Experimental results on multiple datasets demonstrate that our methods outperform prior ranking approaches in terms of NDCG. To the best of our knowledge, this is the first time that stochastic algorithms are proposed to optimize NDCG with a provable convergence guarantee.
AUC Maximization in the Era of Big Data and AI: A Survey
Apr 02, 2022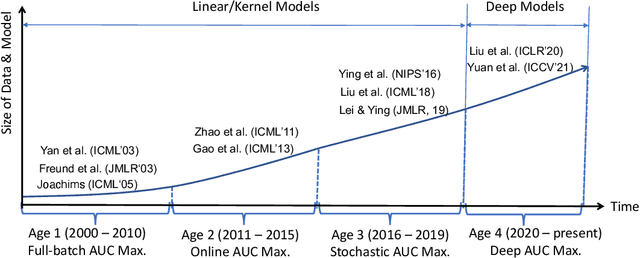


Area under the ROC curve, a.k.a. AUC, is a measure of choice for assessing the performance of a classifier for imbalanced data. AUC maximization refers to a learning paradigm that learns a predictive model by directly maximizing its AUC score. It has been studied for more than two decades dating back to late 90s and a huge amount of work has been devoted to AUC maximization since then. Recently, stochastic AUC maximization for big data and deep AUC maximization for deep learning have received increasing attention and yielded dramatic impact for solving real-world problems. However, to the best our knowledge there is no comprehensive survey of related works for AUC maximization. This paper aims to address the gap by reviewing the literature in the past two decades. We not only give a holistic view of the literature but also present detailed explanations and comparisons of different papers from formulations to algorithms and theoretical guarantees. We also identify and discuss remaining and emerging issues for deep AUC maximization, and provide suggestions on topics for future work.
Benchmarking Deep AUROC Optimization: Loss Functions and Algorithmic Choices
Mar 29, 2022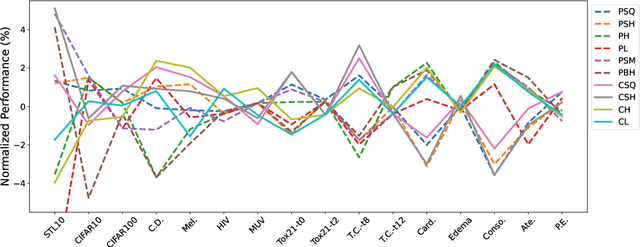
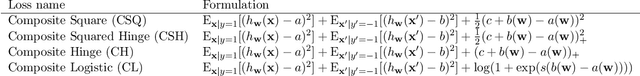
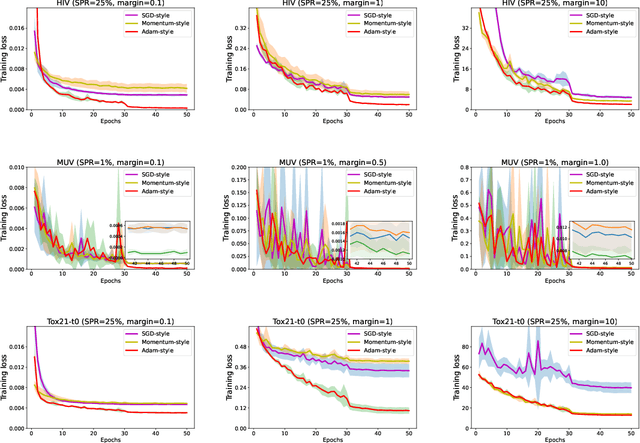
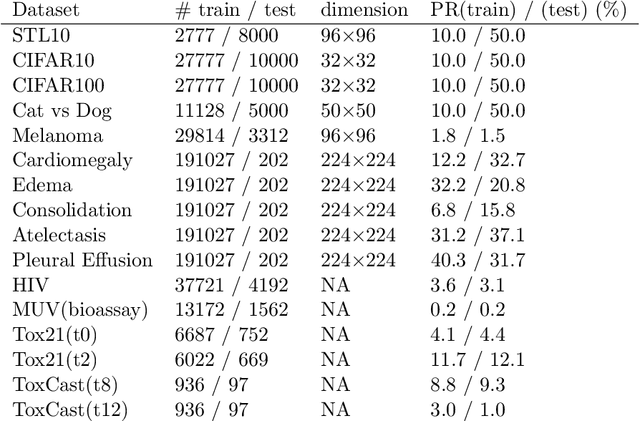
The area under the ROC curve (AUROC) has been vigorously applied for imbalanced classification and moreover combined with deep learning techniques. However, there is no existing work that provides sound information for peers to choose appropriate deep AUROC maximization techniques. In this work, we fill this gap from three aspects. (i) We benchmark a variety of loss functions with different algorithmic choices for deep AUROC optimization problem. We study the loss functions in two categories: pairwise loss and composite loss, which includes a total of 10 loss functions. Interestingly, we find composite loss, as an innovative loss function class, shows more competitive performance than pairwise loss from both training convergence and testing generalization perspectives. Nevertheless, data with more corrupted labels favors a pairwise symmetric loss. (ii) Moreover, we benchmark and highlight the essential algorithmic choices such as positive sampling rate, regularization, normalization/activation, and optimizers. Key findings include: higher positive sampling rate is likely to be beneficial for deep AUROC maximization; different datasets favors different weights of regularizations; appropriate normalization techniques, such as sigmoid and $\ell_2$ score normalization, could improve model performance. (iii) For optimization aspect, we benchmark SGD-type, Momentum-type, and Adam-type optimizers for both pairwise and composite loss. Our findings show that although Adam-type method is more competitive from training perspective, but it does not outperform others from testing perspective.
Optimal Algorithms for Stochastic Multi-Level Compositional Optimization
Mar 11, 2022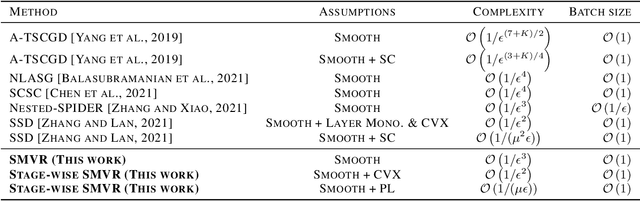
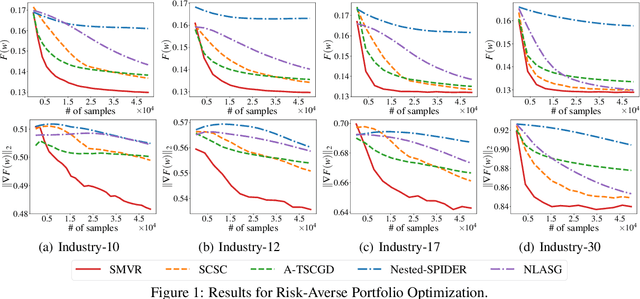
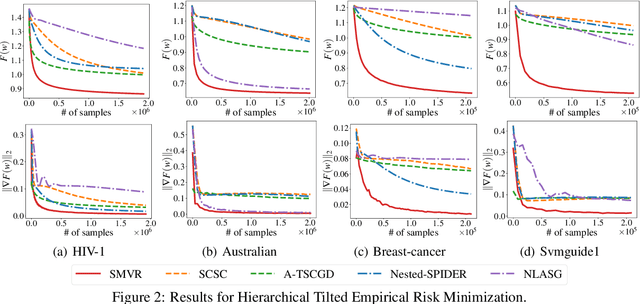

In this paper, we investigate the problem of stochastic multi-level compositional optimization, where the objective function is a composition of multiple smooth but possibly non-convex functions. Existing methods for solving this problem either suffer from sub-optimal sample complexities or need a huge batch size. To address this limitation, we propose a Stochastic Multi-level Variance Reduction method (SMVR), which achieves the optimal sample complexity of $\mathcal{O}\left(1 / \epsilon^{3}\right)$ to find an $\epsilon$-stationary point for non-convex objectives. Furthermore, when the objective function satisfies the convexity or Polyak-{\L}ojasiewicz (PL) condition, we propose a stage-wise variant of SMVR and improve the sample complexity to $\mathcal{O}\left(1 / \epsilon^{2}\right)$ for convex functions or $\mathcal{O}\left(1 /(\mu\epsilon)\right)$ for non-convex functions satisfying the $\mu$-PL condition. The latter result implies the same complexity for $\mu$-strongly convex functions. To make use of adaptive learning rates, we also develop Adaptive SMVR, which achieves the same optimal complexities but converges faster in practice. All our complexities match the lower bounds not only in terms of $\epsilon$ but also in terms of $\mu$ (for PL or strongly convex functions), without using a large batch size in each iteration.
When AUC meets DRO: Optimizing Partial AUC for Deep Learning with Non-Convex Convergence Guarantee
Mar 04, 2022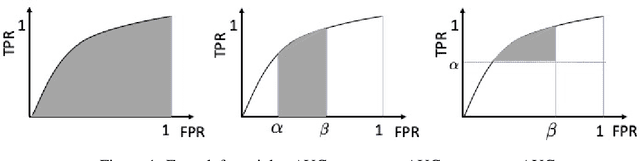
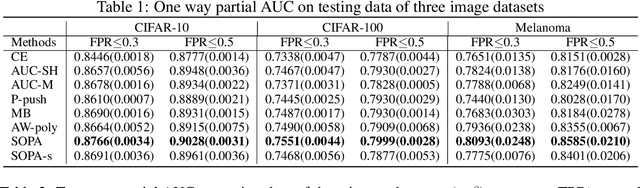
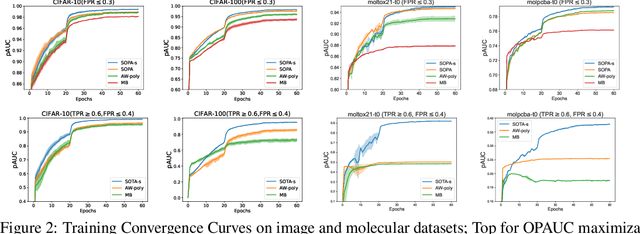
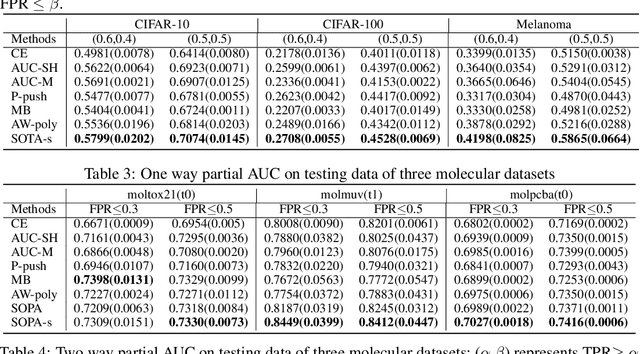
In this paper, we propose systematic and efficient gradient-based methods for both one-way and two-way partial AUC (pAUC) maximization that are applicable to deep learning. We propose new formulations of pAUC surrogate objectives by using the distributionally robust optimization (DRO) to define the loss for each individual positive data. We consider two formulations of DRO, one of which is based on conditional-value-at-risk (CVaR) that yields a non-smooth but exact estimator for pAUC, and another one is based on a KL divergence regularized DRO that yields an inexact but smooth (soft) estimator for pAUC. For both one-way and two-way pAUC maximization, we propose two algorithms and prove their convergence for optimizing their two formulations, respectively. Experiments demonstrate the effectiveness of the proposed algorithms for pAUC maximization for deep learning on various datasets.
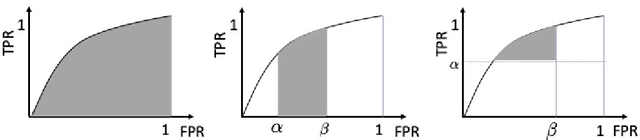
Large-scale Optimization of Partial AUC in a Range of False Positive Rates
Mar 03, 2022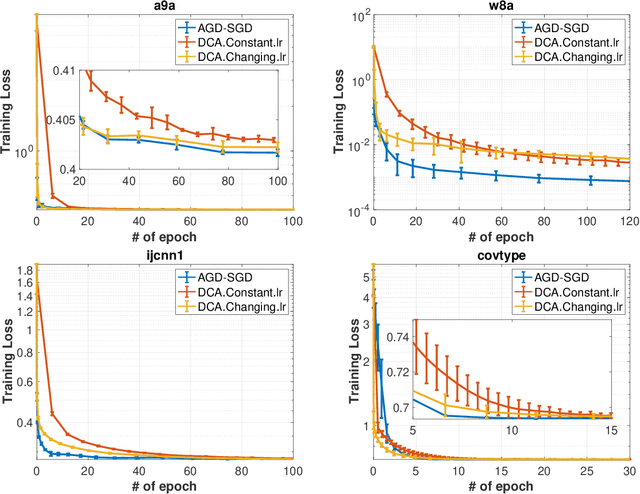
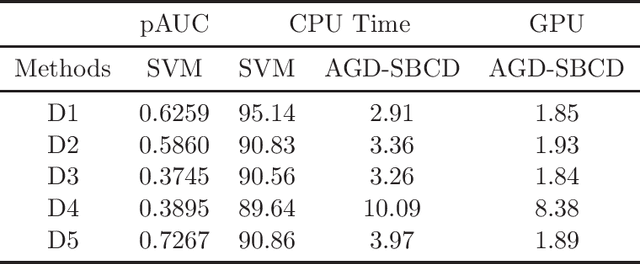
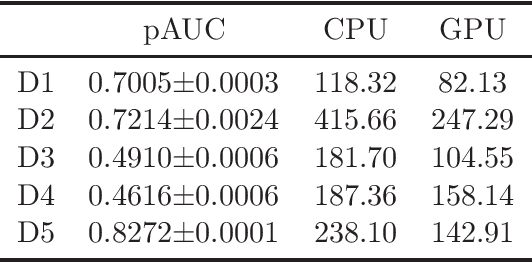
The area under the ROC curve (AUC) is one of the most widely used performance measures for classification models in machine learning. However, it summarizes the true positive rates (TPRs) over all false positive rates (FPRs) in the ROC space, which may include the FPRs with no practical relevance in some applications. The partial AUC, as a generalization of the AUC, summarizes only the TPRs over a specific range of the FPRs and is thus a more suitable performance measure in many real-world situations. Although partial AUC optimization in a range of FPRs had been studied, existing algorithms are not scalable to big data and not applicable to deep learning. To address this challenge, we cast the problem into a non-smooth difference-of-convex (DC) program for any smooth predictive functions (e.g., deep neural networks), which allowed us to develop an efficient approximated gradient descent method based on the Moreau envelope smoothing technique, inspired by recent advances in non-smooth DC optimization. To increase the efficiency of large data processing, we used an efficient stochastic block coordinate update in our algorithm. Our proposed algorithm can also be used to minimize the sum of ranked range loss, which also lacks efficient solvers. We established a complexity of $\tilde O(1/\epsilon^6)$ for finding a nearly $\epsilon$-critical solution. Finally, we numerically demonstrated the effectiveness of our proposed algorithms for both partial AUC maximization and sum of ranked range loss minimization.
Finite-Sum Coupled Compositional Stochastic Optimization: Theory and Applications
Mar 02, 2022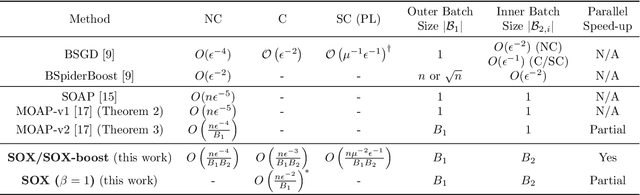
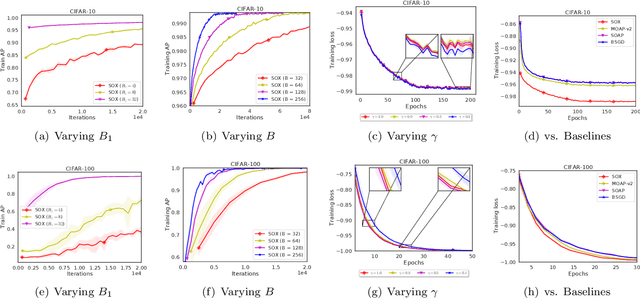
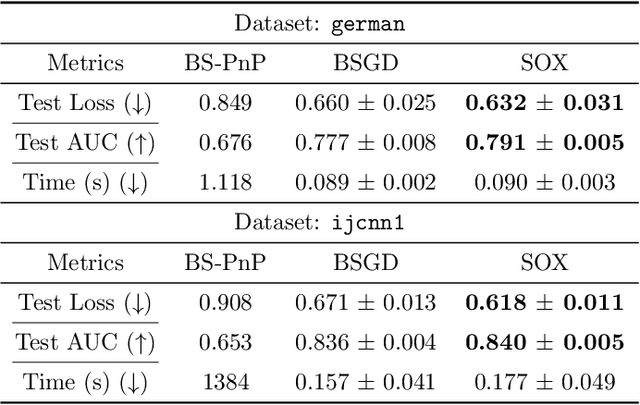

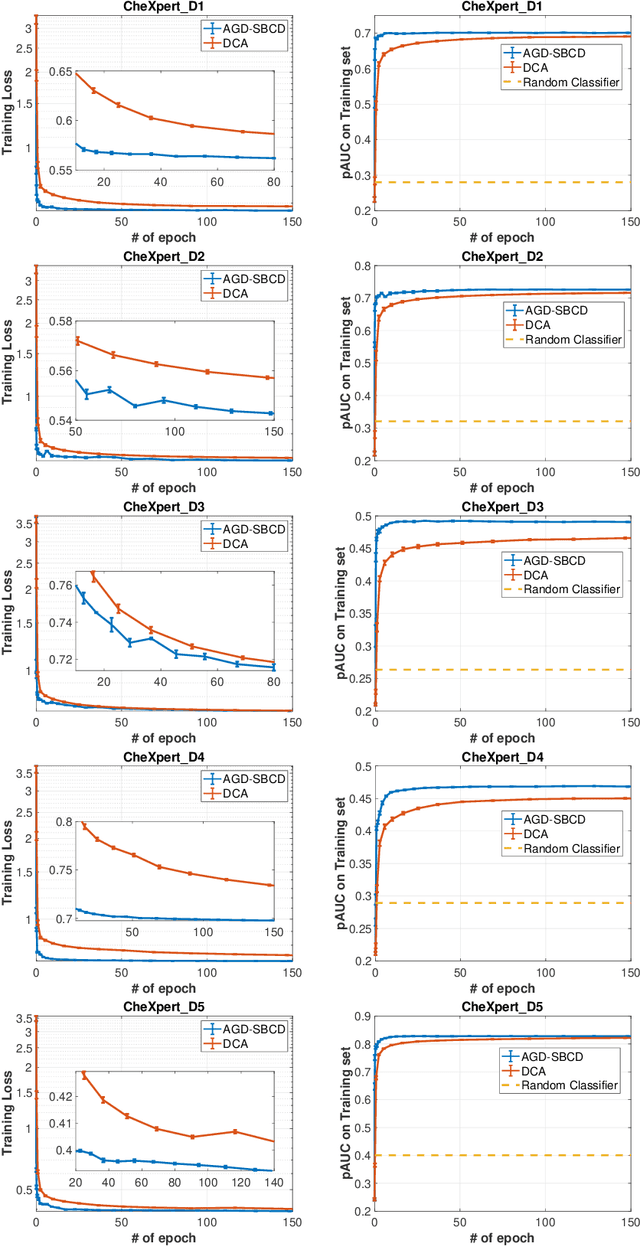
This paper studies stochastic optimization for a sum of compositional functions, where the inner-level function of each summand is coupled with the corresponding summation index. We refer to this family of problems as finite-sum coupled compositional optimization (FCCO). It has broad applications in machine learning for optimizing non-convex or convex compositional measures/objectives such as average precision (AP), $p$-norm push, listwise ranking losses, neighborhood component analysis (NCA), deep survival analysis, deep latent variable models, softmax functions, and model agnostic meta-learning, which deserves finer analysis. Yet, existing algorithms and analysis are restricted in one or other aspects. The contribution of this paper is to provide a comprehensive analysis of a simple stochastic algorithm for both non-convex and convex objectives. The key results are {\bf improved oracle complexities with the parallel speed-up} by the moving-average based stochastic estimator with mini-batching. Our theoretical analysis also exhibits new insights for improving the practical implementation by sampling the batches of equal size for the outer and inner levels. Numerical experiments on AP maximization and $p$-norm push optimization corroborate some aspects of the theory.
Provable Stochastic Optimization for Global Contrastive Learning: Small Batch Does Not Harm Performance
Feb 24, 2022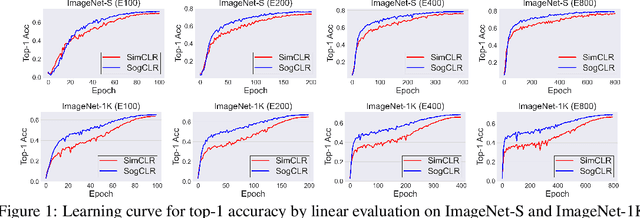
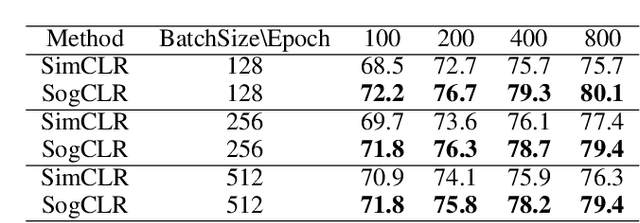
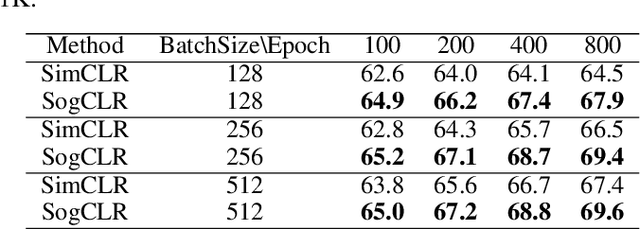
In this paper, we study contrastive learning from an optimization perspective, aiming to analyze and address a fundamental issue of existing contrastive learning methods that either rely on a large batch size or a large dictionary. We consider a global objective for contrastive learning, which contrasts each positive pair with all negative pairs for an anchor point. From the optimization perspective, we explain why existing methods such as SimCLR requires a large batch size in order to achieve a satisfactory result. In order to remove such requirement, we propose a memory-efficient Stochastic Optimization algorithm for solving the Global objective of Contrastive Learning of Representations, named SogCLR. We show that its optimization error is negligible under a reasonable condition after a sufficient number of iterations or is diminishing for a slightly different global contrastive objective. Empirically, we demonstrate that on ImageNet with a batch size 256, SogCLR achieves a performance of 69.4% for top-1 linear evaluation accuracy using ResNet-50, which is on par with SimCLR (69.3%) with a large batch size 8,192. We also attempt to show that the proposed optimization technique is generic and can be applied to solving other contrastive losses, e.g., two-way contrastive losses for bimodal contrastive learning.