 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Dynamic Regret for Non-degenerate Functions
Nov 02, 2017Recently, there has been a growing research interest in the analysis of dynamic regret, which measures the performance of an online learner against a sequence of local minimizers. By exploiting the strong convexity, previous studies have shown that the dynamic regret can be upper bounded by the path-length of the comparator sequence. In this paper, we illustrate that the dynamic regret can be further improved by allowing the learner to query the gradient of the function multiple times, and meanwhile the strong convexity can be weakened to other non-degenerate conditions. Specifically, we introduce the squared path-length, which could be much smaller than the path-length, as a new regularity of the comparator sequence. When multiple gradients are accessible to the learner, we first demonstrate that the dynamic regret of strongly convex functions can be upper bounded by the minimum of the path-length and the squared path-length. We then extend our theoretical guarantee to functions that are semi-strongly convex or self-concordant. To the best of our knowledge, this is the first time that semi-strong convexity and self-concordance are utilized to tighten the dynamic regret.
Stochastic Non-convex Optimization with Strong High Probability Second-order Convergence
Nov 01, 2017
In this paper, we study stochastic non-convex optimization with non-convex random functions. Recent studies on non-convex optimization revolve around establishing second-order convergence, i.e., converging to a nearly second-order optimal stationary points. However, existing results on stochastic non-convex optimization are limited, especially with a high probability second-order convergence. We propose a novel updating step (named NCG-S) by leveraging a stochastic gradient and a noisy negative curvature of a stochastic Hessian, where the stochastic gradient and Hessian are based on a proper mini-batch of random functions. Building on this step, we develop two algorithms and establish their high probability second-order convergence. To the best of our knowledge, the proposed stochastic algorithms are the first with a second-order convergence in {\it high probability} and a time complexity that is {\it almost linear} in the problem's dimensionality.
On Noisy Negative Curvature Descent: Competing with Gradient Descent for Faster Non-convex Optimization
Oct 01, 2017

The Hessian-vector product has been utilized to find a second-order stationary solution with strong complexity guarantee (e.g., almost linear time complexity in the problem's dimensionality). In this paper, we propose to further reduce the number of Hessian-vector products for faster non-convex optimization. Previous algorithms need to approximate the smallest eigen-value with a sufficient precision (e.g., $\epsilon_2\ll 1$) in order to achieve a sufficiently accurate second-order stationary solution (i.e., $\lambda_{\min}(\nabla^2 f(\x))\geq -\epsilon_2)$. In contrast, the proposed algorithms only need to compute the smallest eigen-vector approximating the corresponding eigen-value up to a small power of current gradient's norm. As a result, it can dramatically reduce the number of Hessian-vector products during the course of optimization before reaching first-order stationary points (e.g., saddle points). The key building block of the proposed algorithms is a novel updating step named the NCG step, which lets a noisy negative curvature descent compete with the gradient descent. We show that the worst-case time complexity of the proposed algorithms with their favorable prescribed accuracy requirements can match the best in literature for achieving a second-order stationary point but with an arguably smaller per-iteration cost. We also show that the proposed algorithms can benefit from inexact Hessian by developing their variants accepting inexact Hessian under a mild condition for achieving the same goal. Moreover, we develop a stochastic algorithm for a finite or infinite sum non-convex optimization problem. To the best of our knowledge, the proposed stochastic algorithm is the first one that converges to a second-order stationary point in {\it high probability} with a time complexity independent of the sample size and almost linear in dimensionality.
A Simple Analysis for Exp-concave Empirical Minimization with Arbitrary Convex Regularizer
Sep 09, 2017In this paper, we present a simple analysis of {\bf fast rates} with {\it high probability} of {\bf empirical minimization} for {\it stochastic composite optimization} over a finite-dimensional bounded convex set with exponential concave loss functions and an arbitrary convex regularization. To the best of our knowledge, this result is the first of its kind. As a byproduct, we can directly obtain the fast rate with {\it high probability} for exponential concave empirical risk minimization with and without any convex regularization, which not only extends existing results of empirical risk minimization but also provides a unified framework for analyzing exponential concave empirical risk minimization with and without {\it any} convex regularization. Our proof is very simple only exploiting the covering number of a finite-dimensional bounded set and a concentration inequality of random vectors.
SEP-Nets: Small and Effective Pattern Networks
Jun 13, 2017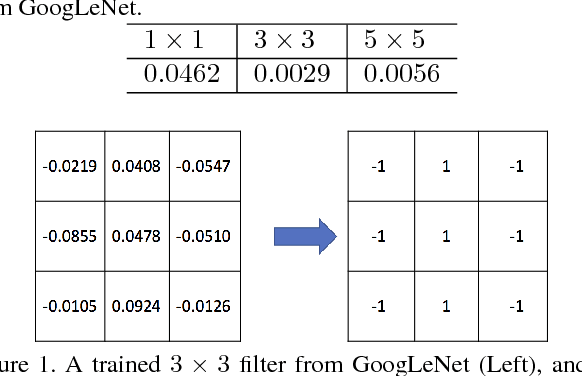
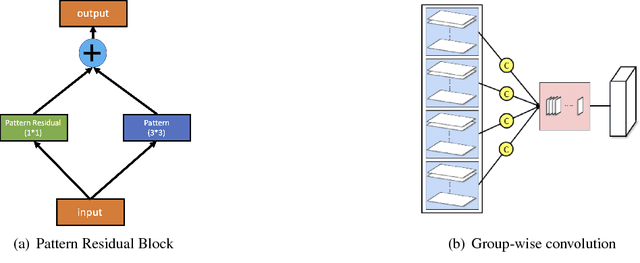
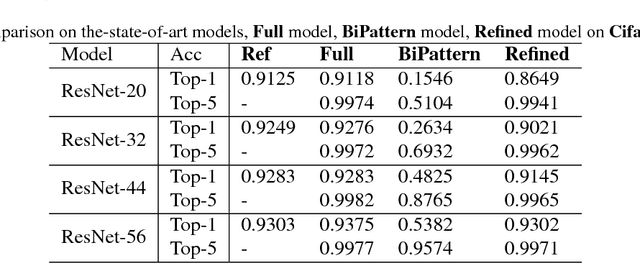
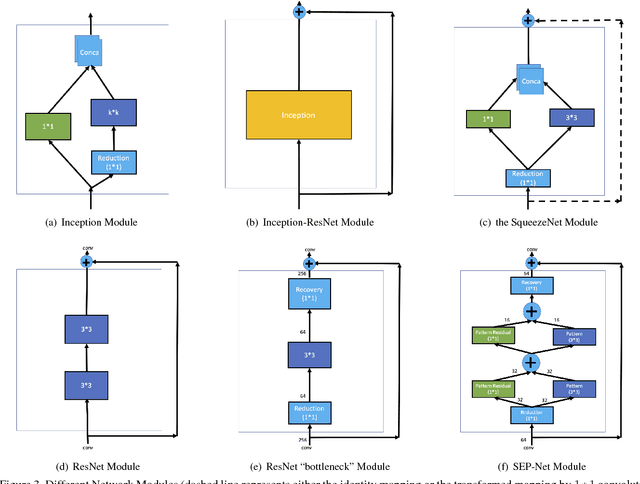
While going deeper has been witnessed to improve the performance of convolutional neural networks (CNN), going smaller for CNN has received increasing attention recently due to its attractiveness for mobile/embedded applications. It remains an active and important topic how to design a small network while retaining the performance of large and deep CNNs (e.g., Inception Nets, ResNets). Albeit there are already intensive studies on compressing the size of CNNs, the considerable drop of performance is still a key concern in many designs. This paper addresses this concern with several new contributions. First, we propose a simple yet powerful method for compressing the size of deep CNNs based on parameter binarization. The striking difference from most previous work on parameter binarization/quantization lies at different treatments of $1\times 1$ convolutions and $k\times k$ convolutions ($k>1$), where we only binarize $k\times k$ convolutions into binary patterns. The resulting networks are referred to as pattern networks. By doing this, we show that previous deep CNNs such as GoogLeNet and Inception-type Nets can be compressed dramatically with marginal drop in performance. Second, in light of the different functionalities of $1\times 1$ (data projection/transformation) and $k\times k$ convolutions (pattern extraction), we propose a new block structure codenamed the pattern residual block that adds transformed feature maps generated by $1\times 1$ convolutions to the pattern feature maps generated by $k\times k$ convolutions, based on which we design a small network with $\sim 1$ million parameters. Combining with our parameter binarization, we achieve better performance on ImageNet than using similar sized networks including recently released Google MobileNets.
A Richer Theory of Convex Constrained Optimization with Reduced Projections and Improved Rates
Jun 12, 2017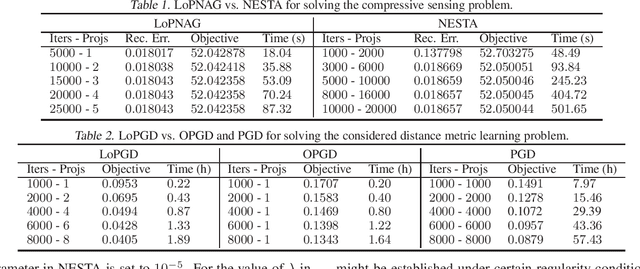
This paper focuses on convex constrained optimization problems, where the solution is subject to a convex inequality constraint. In particular, we aim at challenging problems for which both projection into the constrained domain and a linear optimization under the inequality constraint are time-consuming, which render both projected gradient methods and conditional gradient methods (a.k.a. the Frank-Wolfe algorithm) expensive. In this paper, we develop projection reduced optimization algorithms for both smooth and non-smooth optimization with improved convergence rates under a certain regularity condition of the constraint function. We first present a general theory of optimization with only one projection. Its application to smooth optimization with only one projection yields $O(1/\epsilon)$ iteration complexity, which improves over the $O(1/\epsilon^2)$ iteration complexity established before for non-smooth optimization and can be further reduced under strong convexity. Then we introduce a local error bound condition and develop faster algorithms for non-strongly convex optimization at the price of a logarithmic number of projections. In particular, we achieve an iteration complexity of $\widetilde O(1/\epsilon^{2(1-\theta)})$ for non-smooth optimization and $\widetilde O(1/\epsilon^{1-\theta})$ for smooth optimization, where $\theta\in(0,1]$ appearing the local error bound condition characterizes the functional local growth rate around the optimal solutions. Novel applications in solving the constrained $\ell_1$ minimization problem and a positive semi-definite constrained distance metric learning problem demonstrate that the proposed algorithms achieve significant speed-up compared with previous algorithms.
Adaptive Accelerated Gradient Converging Methods under Holderian Error Bound Condition
May 14, 2017

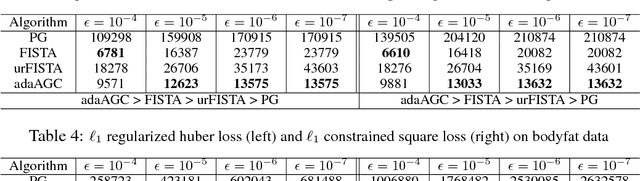
Recent studies have shown that proximal gradient (PG) method and accelerated gradient method (APG) with restarting can enjoy a linear convergence under a weaker condition than strong convexity, namely a quadratic growth condition (QGC). However, the faster convergence of restarting APG method relies on the potentially unknown constant in QGC to appropriately restart APG, which restricts its applicability. We address this issue by developing a novel adaptive gradient converging methods, i.e., leveraging the magnitude of proximal gradient as a criterion for restart and termination. Our analysis extends to a much more general condition beyond the QGC, namely the H\"{o}lderian error bound (HEB) condition. {\it The key technique} for our development is a novel synthesis of {\it adaptive regularization and a conditional restarting scheme}, which extends previous work focusing on strongly convex problems to a much broader family of problems. Furthermore, we demonstrate that our results have important implication and applications in machine learning: (i) if the objective function is coercive and semi-algebraic, PG's convergence speed is essentially $o(\frac{1}{t})$, where $t$ is the total number of iterations; (ii) if the objective function consists of an $\ell_1$, $\ell_\infty$, $\ell_{1,\infty}$, or huber norm regularization and a convex smooth piecewise quadratic loss (e.g., squares loss, squared hinge loss and huber loss), the proposed algorithm is parameter-free and enjoys a {\it faster linear convergence} than PG without any other assumptions (e.g., restricted eigen-value condition). It is notable that our linear convergence results for the aforementioned problems are global instead of local. To the best of our knowledge, these improved results are the first shown in this work.
Doubly Stochastic Primal-Dual Coordinate Method for Bilinear Saddle-Point Problem
Apr 12, 2017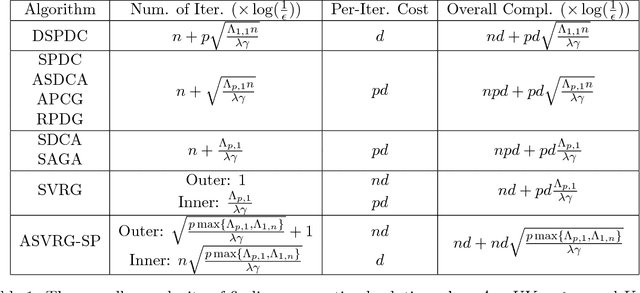
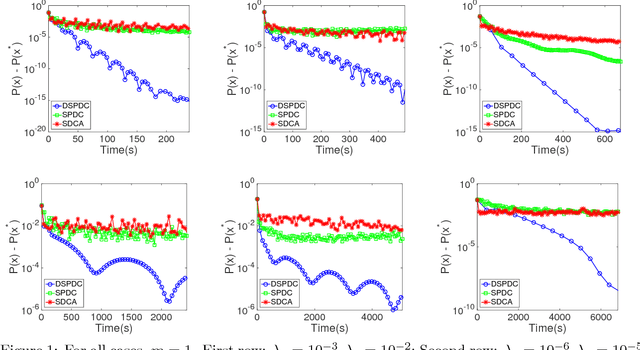

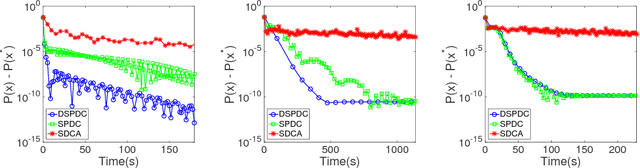
We propose a doubly stochastic primal-dual coordinate optimization algorithm for empirical risk minimization, which can be formulated as a bilinear saddle-point problem. In each iteration, our method randomly samples a block of coordinates of the primal and dual solutions to update. The linear convergence of our method could be established in terms of 1) the distance from the current iterate to the optimal solution and 2) the primal-dual objective gap. We show that the proposed method has a lower overall complexity than existing coordinate methods when either the data matrix has a factorized structure or the proximal mapping on each block is computationally expensive, e.g., involving an eigenvalue decomposition. The efficiency of the proposed method is confirmed by empirical studies on several real applications, such as the multi-task large margin nearest neighbor problem.
Empirical Risk Minimization for Stochastic Convex Optimization: $O(1/n)$- and $O(1/n^2)$-type of Risk Bounds
Feb 07, 2017
Although there exist plentiful theories of empirical risk minimization (ERM) for supervised learning, current theoretical understandings of ERM for a related problem---stochastic convex optimization (SCO), are limited. In this work, we strengthen the realm of ERM for SCO by exploiting smoothness and strong convexity conditions to improve the risk bounds. First, we establish an $\widetilde{O}(d/n + \sqrt{F_*/n})$ risk bound when the random function is nonnegative, convex and smooth, and the expected function is Lipschitz continuous, where $d$ is the dimensionality of the problem, $n$ is the number of samples, and $F_*$ is the minimal risk. Thus, when $F_*$ is small we obtain an $\widetilde{O}(d/n)$ risk bound, which is analogous to the $\widetilde{O}(1/n)$ optimistic rate of ERM for supervised learning. Second, if the objective function is also $\lambda$-strongly convex, we prove an $\widetilde{O}(d/n + \kappa F_*/n )$ risk bound where $\kappa$ is the condition number, and improve it to $O(1/[\lambda n^2] + \kappa F_*/n)$ when $n=\widetilde{\Omega}(\kappa d)$. As a result, we obtain an $O(\kappa/n^2)$ risk bound under the condition that $n$ is large and $F_*$ is small, which to the best of our knowledge, is the first $O(1/n^2)$-type of risk bound of ERM. Third, we stress that the above results are established in a unified framework, which allows us to derive new risk bounds under weaker conditions, e.g., without convexity of the random function and Lipschitz continuity of the expected function. Finally, we demonstrate that to achieve an $O(1/[\lambda n^2] + \kappa F_*/n)$ risk bound for supervised learning, the $\widetilde{\Omega}(\kappa d)$ requirement on $n$ can be replaced with $\Omega(\kappa^2)$, which is dimensionality-independent.
Accelerated Stochastic Subgradient Methods under Local Error Bound Condition
Jan 17, 2017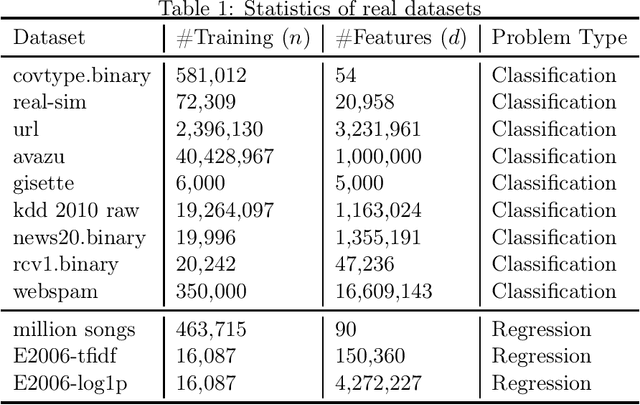
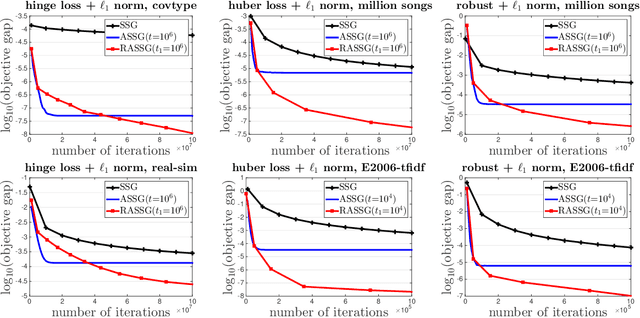
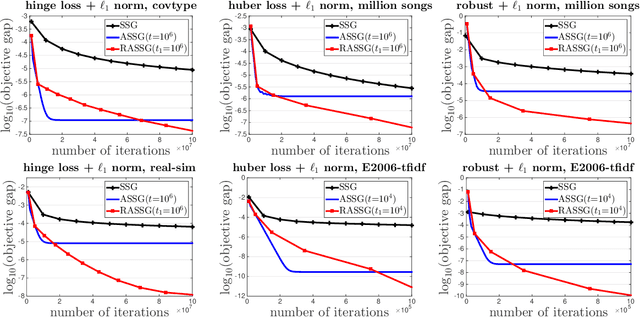
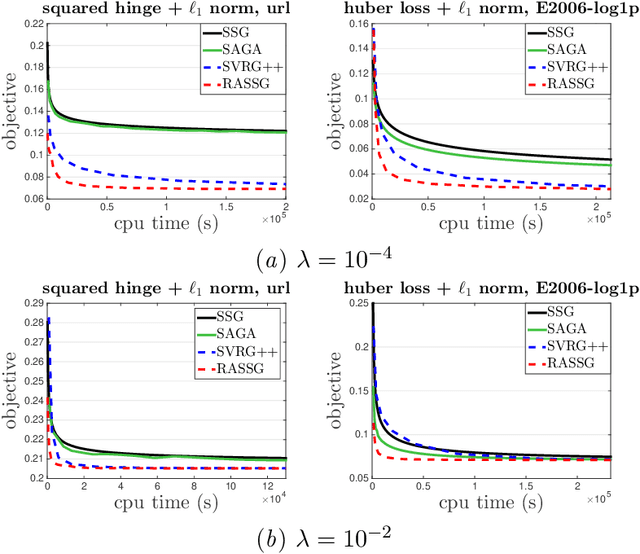
In this paper, we propose two {\bf accelerated stochastic subgradient} methods for stochastic non-strongly convex optimization problems by leveraging a generic local error bound condition. The novelty of the proposed methods lies at smartly leveraging the recent historical solution to tackle the variance in the stochastic subgradient. The key idea of both methods is to iteratively solve the original problem approximately in a local region around a recent historical solution with size of the local region gradually decreasing as the solution approaches the optimal set. The difference of the two methods lies at how to construct the local region. The first method uses an explicit ball constraint and the second method uses an implicit regularization approach. For both methods, we establish the improved iteration complexity in a high probability for achieving an $\epsilon$-optimal solution. Besides the improved order of iteration complexity with a high probability, the proposed algorithms also enjoy a logarithmic dependence on the distance of the initial solution to the optimal set. We also consider applications in machine learning and demonstrate that the proposed algorithms enjoy faster convergence than the traditional stochastic subgradient method. For example, when applied to the $\ell_1$ regularized polyhedral loss minimization (e.g., hinge loss, absolute loss), the proposed stochastic methods have a logarithmic iteration complexity.