 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Learning To Rank for Utility-Maximizing Query Autocompletion
Apr 22, 2022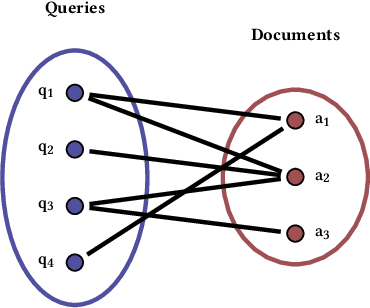

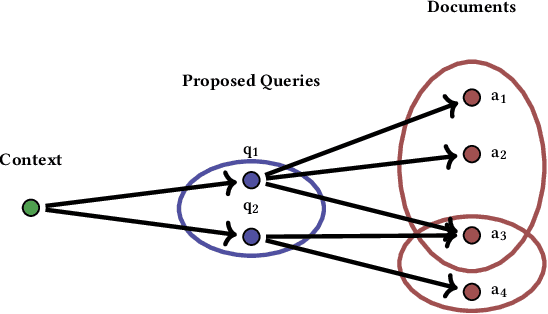
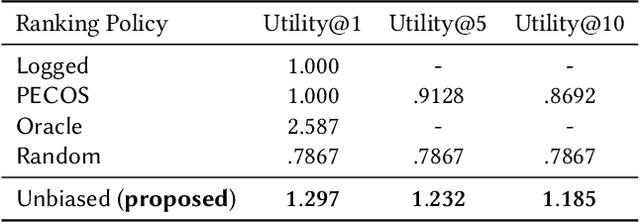
Conventional methods for query autocompletion aim to predict which completed query a user will select from a list. A shortcoming of this approach is that users often do not know which query will provide the best retrieval performance on the current information retrieval system, meaning that any query autocompletion methods trained to mimic user behavior can lead to suboptimal query suggestions. To overcome this limitation, we propose a new approach that explicitly optimizes the query suggestions for downstream retrieval performance. We formulate this as a problem of ranking a set of rankings, where each query suggestion is represented by the downstream item ranking it produces. We then present a learning method that ranks query suggestions by the quality of their item rankings. The algorithm is based on a counterfactual learning approach that is able to leverage feedback on the items (e.g., clicks, purchases) to evaluate query suggestions through an unbiased estimator, thus avoiding the assumption that users write or select optimal queries. We establish theoretical support for the proposed approach and provide learning-theoretic guarantees. We also present empirical results on publicly available datasets, and demonstrate real-world applicability using data from an online shopping store.
Off-Policy Evaluation for Large Action Spaces via Embeddings
Feb 13, 2022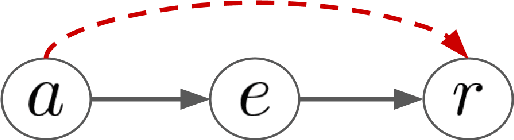

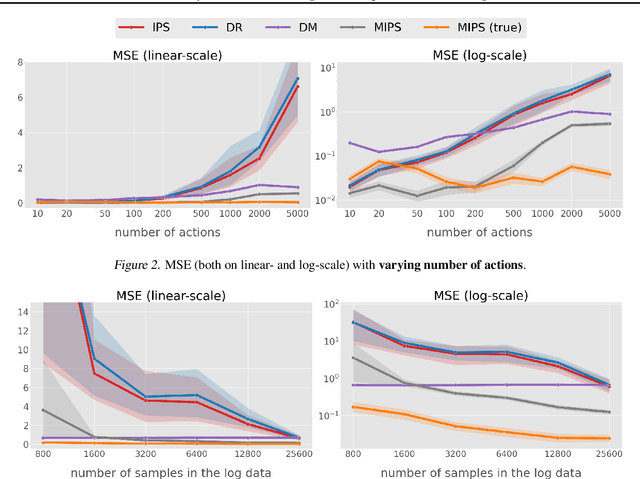
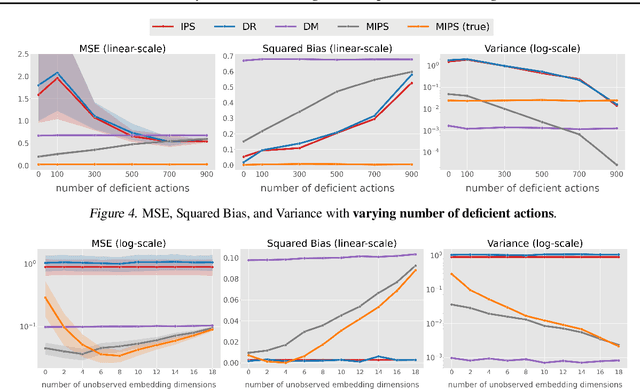
Off-policy evaluation (OPE) in contextual bandits has seen rapid adoption in real-world systems, since it enables offline evaluation of new policies using only historic log data. Unfortunately, when the number of actions is large, existing OPE estimators -- most of which are based on inverse propensity score weighting -- degrade severely and can suffer from extreme bias and variance. This foils the use of OPE in many applications from recommender systems to language models. To overcome this issue, we propose a new OPE estimator that leverages marginalized importance weights when action embeddings provide structure in the action space. We characterize the bias, variance, and mean squared error of the proposed estimator and analyze the conditions under which the action embedding provides statistical benefits over conventional estimators. In addition to the theoretical analysis, we find that the empirical performance improvement can be substantial, enabling reliable OPE even when existing estimators collapse due to a large number of actions.
Variance-Optimal Augmentation Logging for Counterfactual Evaluation in Contextual Bandits
Feb 03, 2022Methods for offline A/B testing and counterfactual learning are seeing rapid adoption in search and recommender systems, since they allow efficient reuse of existing log data. However, there are fundamental limits to using existing log data alone, since the counterfactual estimators that are commonly used in these methods can have large bias and large variance when the logging policy is very different from the target policy being evaluated. To overcome this limitation, we explore the question of how to design data-gathering policies that most effectively augment an existing dataset of bandit feedback with additional observations for both learning and evaluation. To this effect, this paper introduces Minimum Variance Augmentation Logging (MVAL), a method for constructing logging policies that minimize the variance of the downstream evaluation or learning problem. We explore multiple approaches to computing MVAL policies efficiently, and find that they can be substantially more effective in decreasing the variance of an estimator than na\"ive approaches.
Improving Screening Processes via Calibrated Subset Selection
Feb 02, 2022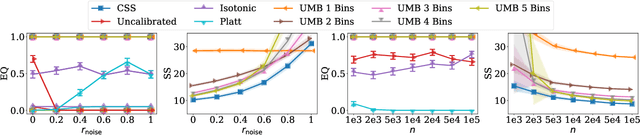

Many selection processes such as finding patients qualifying for a medical trial or retrieval pipelines in search engines consist of multiple stages, where an initial screening stage focuses the resources on shortlisting the most promising candidates. In this paper, we investigate what guarantees a screening classifier can provide, independently of whether it is constructed manually or trained. We find that current solutions do not enjoy distribution-free theoretical guarantees -- we show that, in general, even for a perfectly calibrated classifier, there always exist specific pools of candidates for which its shortlist is suboptimal. Then, we develop a distribution-free screening algorithm -- called Calibrated Subset Selection (CSS) -- that, given any classifier and some amount of calibration data, finds near-optimal shortlists of candidates that contain a desired number of qualified candidates in expectation. Moreover, we show that a variant of our algorithm that calibrates a given classifier multiple times across specific groups can create shortlists with provable diversity guarantees. Experiments on US Census survey data validate our theoretical results and show that the shortlists provided by our algorithm are superior to those provided by several competitive baselines.
Fairness in Ranking under Uncertainty
Jul 14, 2021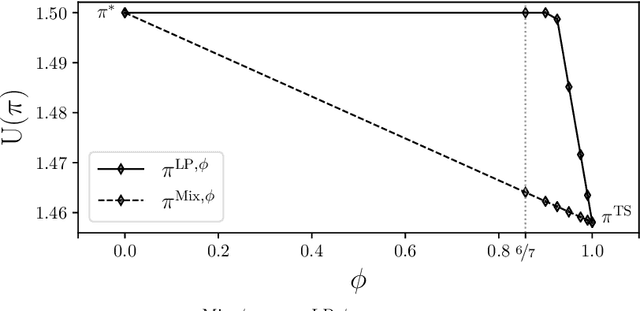
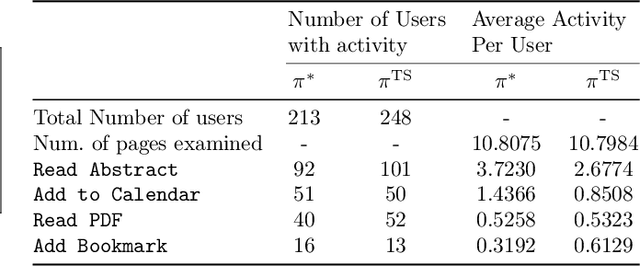
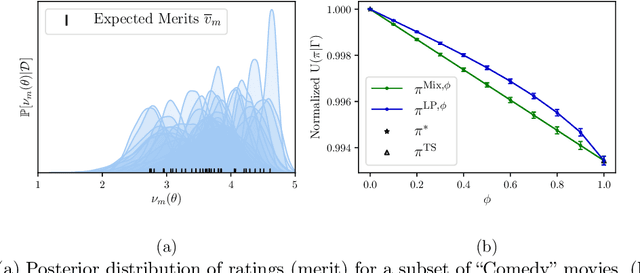
Fairness has emerged as an important consideration in algorithmic decision-making. Unfairness occurs when an agent with higher merit obtains a worse outcome than an agent with lower merit. Our central point is that a primary cause of unfairness is uncertainty. A principal or algorithm making decisions never has access to the agents' true merit, and instead uses proxy features that only imperfectly predict merit (e.g., GPA, star ratings, recommendation letters). None of these ever fully capture an agent's merit; yet existing approaches have mostly been defining fairness notions directly based on observed features and outcomes. Our primary point is that it is more principled to acknowledge and model the uncertainty explicitly. The role of observed features is to give rise to a posterior distribution of the agents' merits. We use this viewpoint to define a notion of approximate fairness in ranking. We call an algorithm $\phi$-fair (for $\phi \in [0,1]$) if it has the following property for all agents $x$ and all $k$: if agent $x$ is among the top $k$ agents with respect to merit with probability at least $\rho$ (according to the posterior merit distribution), then the algorithm places the agent among the top $k$ agents in its ranking with probability at least $\phi \rho$. We show how to compute rankings that optimally trade off approximate fairness against utility to the principal. In addition to the theoretical characterization, we present an empirical analysis of the potential impact of the approach in simulation studies. For real-world validation, we applied the approach in the context of a paper recommendation system that we built and fielded at a large conference.
Optimizing Rankings for Recommendation in Matching Markets
Jun 03, 2021

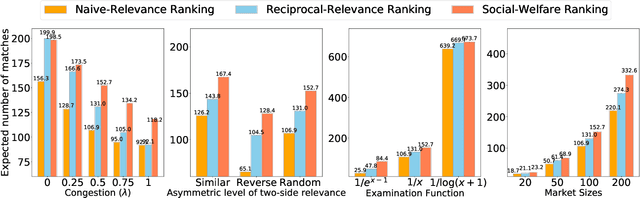

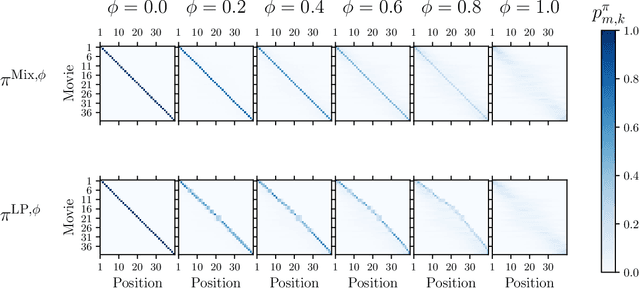
Based on the success of recommender systems in e-commerce, there is growing interest in their use in matching markets (e.g., labor). While this holds potential for improving market fluidity and fairness, we show in this paper that naively applying existing recommender systems to matching markets is sub-optimal. Considering the standard process where candidates apply and then get evaluated by employers, we present a new recommendation framework to model this interaction mechanism and propose efficient algorithms for computing personalized rankings in this setting. We show that the optimal rankings need to not only account for the potentially divergent preferences of candidates and employers, but they also need to account for capacity constraints. This makes conventional ranking systems that merely rank by some local score (e.g., one-sided or reciprocal relevance) highly sub-optimal -- not only for an individual user, but also for societal goals (e.g., low unemployment). To address this shortcoming, we propose the first method for jointly optimizing the rankings for all candidates in the market to explicitly maximize social welfare. In addition to the theoretical derivation, we evaluate the method both on simulated environments and on data from a real-world networking-recommendation system that we built and fielded at a large computer science conference.
Fairness of Exposure in Stochastic Bandits
Mar 03, 2021
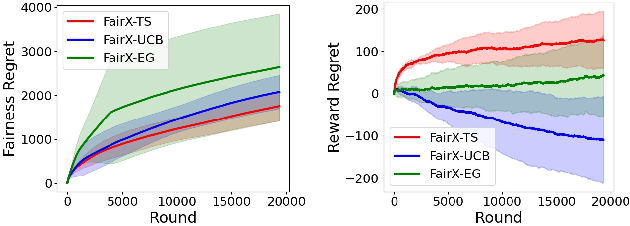
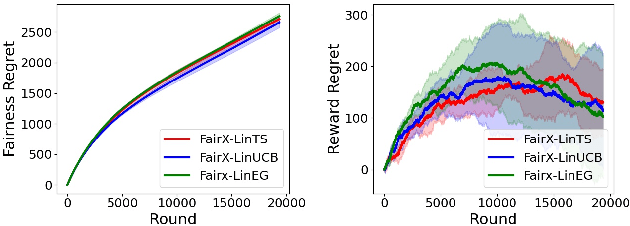

Contextual bandit algorithms have become widely used for recommendation in online systems (e.g. marketplaces, music streaming, news), where they now wield substantial influence on which items get exposed to the users. This raises questions of fairness to the items -- and to the sellers, artists, and writers that benefit from this exposure. We argue that the conventional bandit formulation can lead to an undesirable and unfair winner-takes-all allocation of exposure. To remedy this problem, we propose a new bandit objective that guarantees merit-based fairness of exposure to the items while optimizing utility to the users. We formulate fairness regret and reward regret in this setting, and present algorithms for both stochastic multi-armed bandits and stochastic linear bandits. We prove that the algorithms achieve sub-linear fairness regret and reward regret. Beyond the theoretical analysis, we also provide empirical evidence that these algorithms can fairly allocate exposure to different arms effectively.
Fairness and Diversity for Rankings in Two-Sided Markets
Oct 04, 2020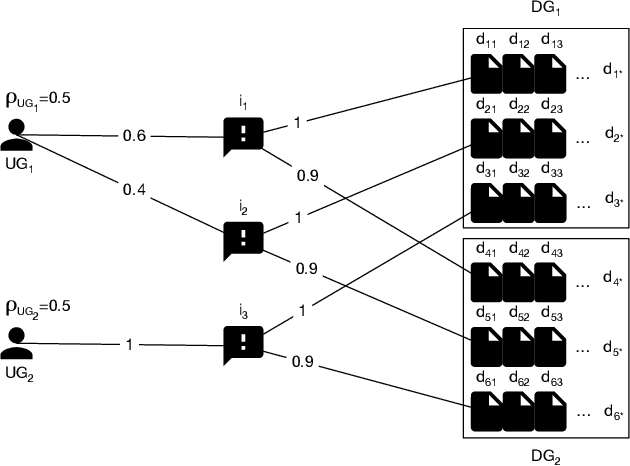


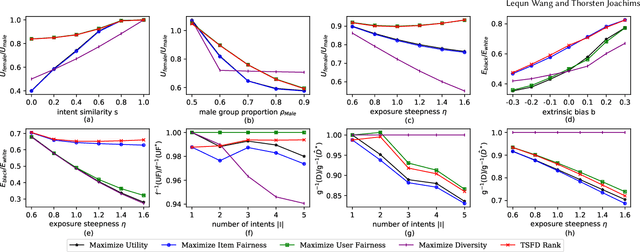
Ranking items by their probability of relevance has long been the goal of conventional ranking systems. While this maximizes traditional criteria of ranking performance, there is a growing understanding that it is an oversimplification in online platforms that serve not only a diverse user population, but also the producers of the items. In particular, ranking algorithms are expected to be fair in how they serve all groups of users -- not just the majority group -- and they also need to be fair in how they divide exposure among the items. These fairness considerations can partially be met by adding diversity to the rankings, as done in several recent works, but we show in this paper that user fairness, item fairness and diversity are fundamentally different concepts. In particular, we find that algorithms that consider only one of the three desiderata can fail to satisfy and even harm the other two. To overcome this shortcoming, we present the first ranking algorithm that explicitly enforces all three desiderata. The algorithm optimizes user and item fairness as a convex optimization problem which can be solved optimally. From its solution, a ranking policy can be derived via a new Birkhoff-von Neumann decomposition algorithm that optimizes diversity. Beyond the theoretical analysis, we provide a comprehensive empirical evaluation on a new benchmark dataset to show the effectiveness of the proposed ranking algorithm on controlling the three desiderata and the interplay between them.
Content-based Music Similarity with Triplet Networks
Aug 11, 2020
We explore the feasibility of using triplet neural networks to embed songs based on content-based music similarity. Our network is trained using triplets of songs such that two songs by the same artist are embedded closer to one another than to a third song by a different artist. We compare two models that are trained using different ways of picking this third song: at random vs. based on shared genre labels. Our experiments are conducted using songs from the Free Music Archive and use standard audio features. The initial results show that shallow Siamese networks can be used to embed music for a simple artist retrieval task.
Off-policy Bandits with Deficient Support
Jun 16, 2020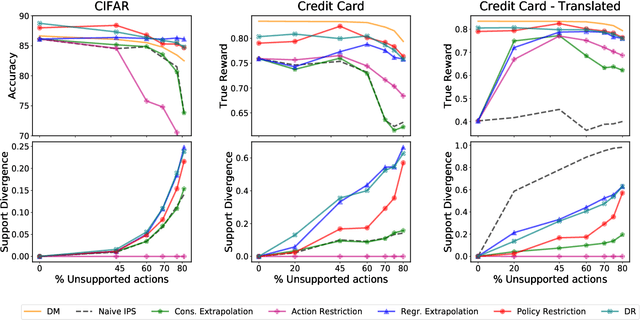
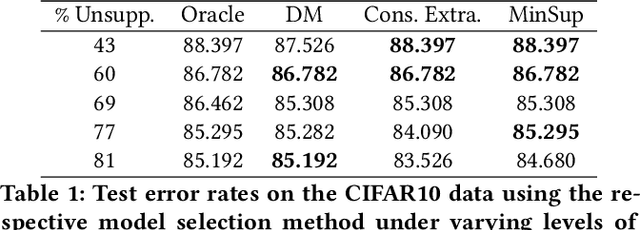
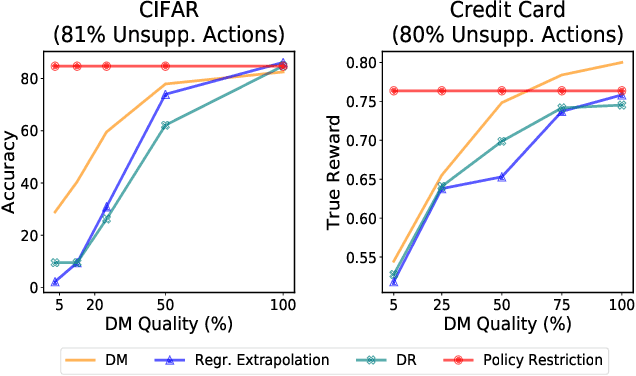
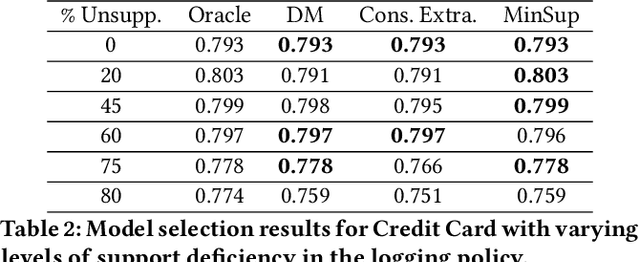
Learning effective contextual-bandit policies from past actions of a deployed system is highly desirable in many settings (e.g. voice assistants, recommendation, search), since it enables the reuse of large amounts of log data. State-of-the-art methods for such off-policy learning, however, are based on inverse propensity score (IPS) weighting. A key theoretical requirement of IPS weighting is that the policy that logged the data has "full support", which typically translates into requiring non-zero probability for any action in any context. Unfortunately, many real-world systems produce support deficient data, especially when the action space is large, and we show how existing methods can fail catastrophically. To overcome this gap between theory and applications, we identify three approaches that provide various guarantees for IPS-based learning despite the inherent limitations of support-deficient data: restricting the action space, reward extrapolation, and restricting the policy space. We systematically analyze the statistical and computational properties of these three approaches, and we empirically evaluate their effectiveness. In addition to providing the first systematic analysis of support-deficiency in contextual-bandit learning, we conclude with recommendations that provide practical guidance.