 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-BEHRT: Hierarchical Transformer-based model for accurate prediction of clinical events using multimodal longitudinal electronic health records
Jun 21, 2021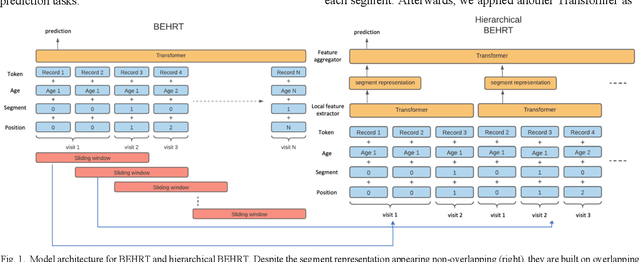
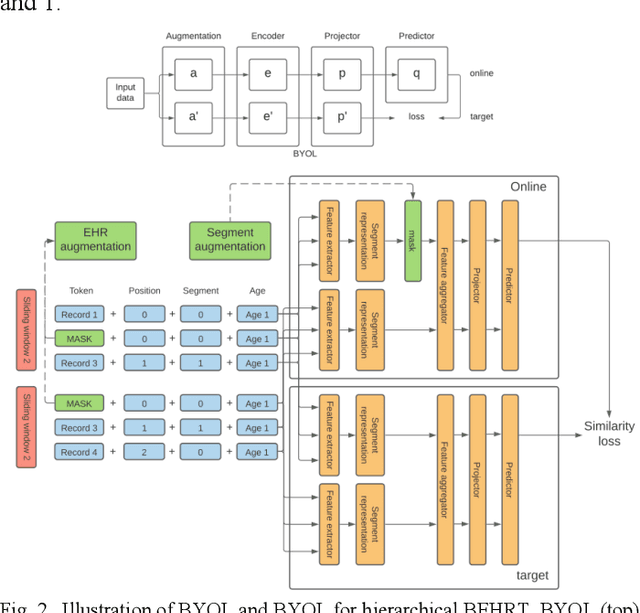
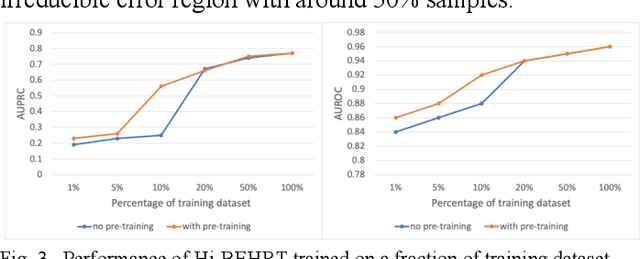
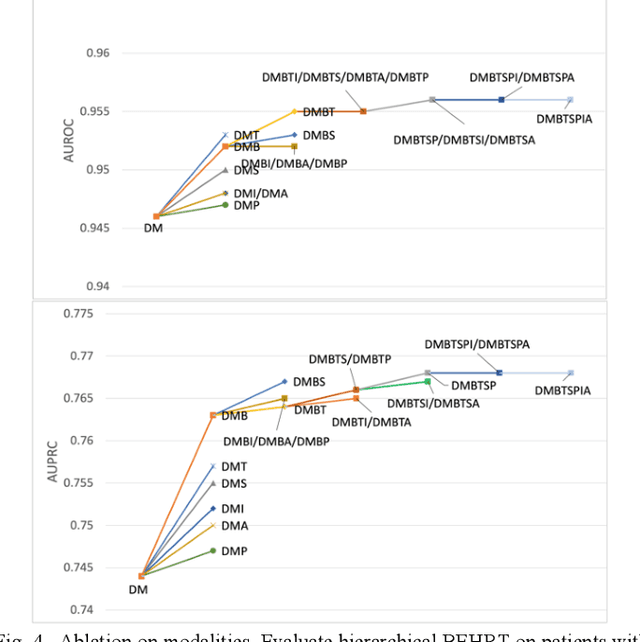
Electronic health records represent a holistic overview of patients' trajectories. Their increasing availability has fueled new hopes to leverage them and develop accurate risk prediction models for a wide range of diseases. Given the complex interrelationships of medical records and patient outcomes, deep learning models have shown clear merits in achieving this goal. However, a key limitation of these models remains their capacity in processing long sequences. Capturing the whole history of medical encounters is expected to lead to more accurate predictions, but the inclusion of records collected for decades and from multiple resources can inevitably exceed the receptive field of the existing deep learning architectures. This can result in missing crucial, long-term dependencies. To address this gap, we present Hi-BEHRT, a hierarchical Transformer-based model that can significantly expand the receptive field of Transformers and extract associations from much longer sequences. Using a multimodal large-scale linked longitudinal electronic health records, the Hi-BEHRT exceeds the state-of-the-art BEHRT 1% to 5% for area under the receiver operating characteristic (AUROC) curve and 3% to 6% for area under the precision recall (AUPRC) curve on average, and 3% to 6% (AUROC) and 3% to 11% (AUPRC) for patients with long medical history for 5-year heart failure, diabetes, chronic kidney disease, and stroke risk prediction. Additionally, because pretraining for hierarchical Transformer is not well-established, we provide an effective end-to-end contrastive pre-training strategy for Hi-BEHRT using EHR, improving its transferability on predicting clinical events with relatively small training dataset.
RSG: A Simple but Effective Module for Learning Imbalanced Datasets
Jun 18, 2021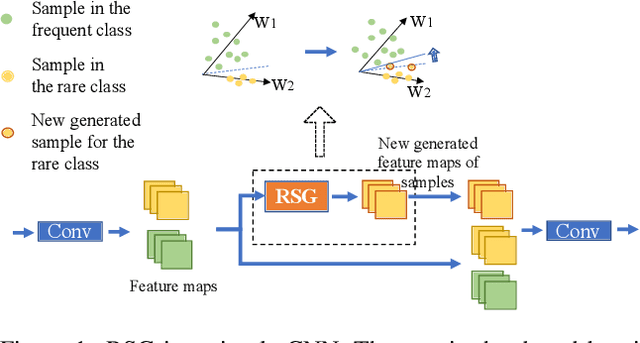
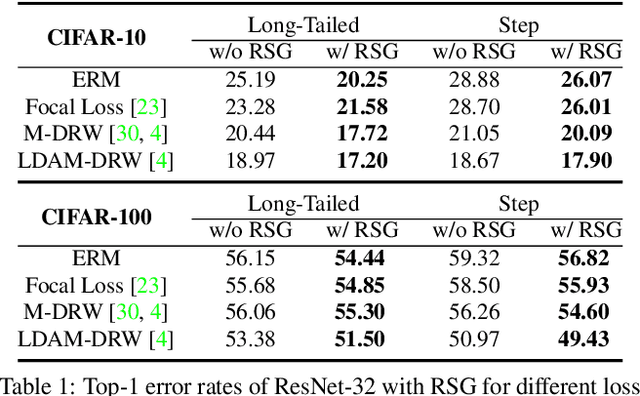
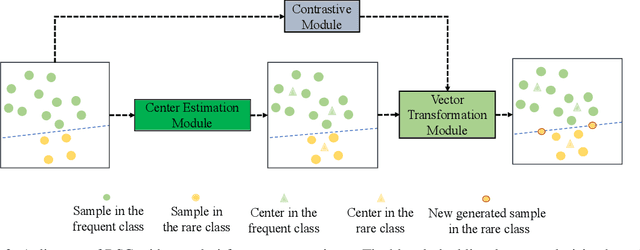
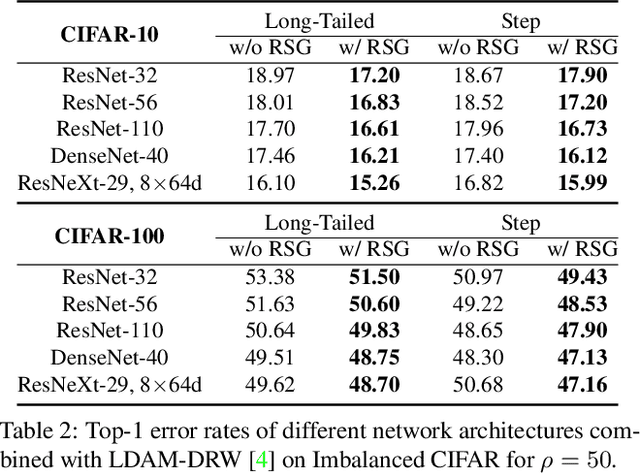
Imbalanced datasets widely exist in practice and area great challenge for training deep neural models with agood generalization on infrequent classes. In this work, wepropose a new rare-class sample generator (RSG) to solvethis problem. RSG aims to generate some new samplesfor rare classes during training, and it has in particularthe following advantages: (1) it is convenient to use andhighly versatile, because it can be easily integrated intoany kind of convolutional neural network, and it works wellwhen combined with different loss functions, and (2) it isonly used during the training phase, and therefore, no ad-ditional burden is imposed on deep neural networks duringthe testing phase. In extensive experimental evaluations, weverify the effectiveness of RSG. Furthermore, by leveragingRSG, we obtain competitive results on Imbalanced CIFARand new state-of-the-art results on Places-LT, ImageNet-LT, and iNaturalist 2018. The source code is available at https://github.com/Jianf-Wang/RSG.
Controlling Text Edition by Changing Answers of Specific Questions
May 23, 2021

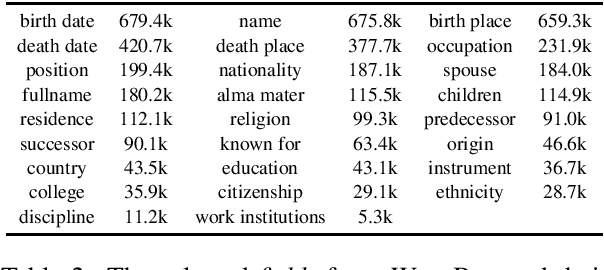
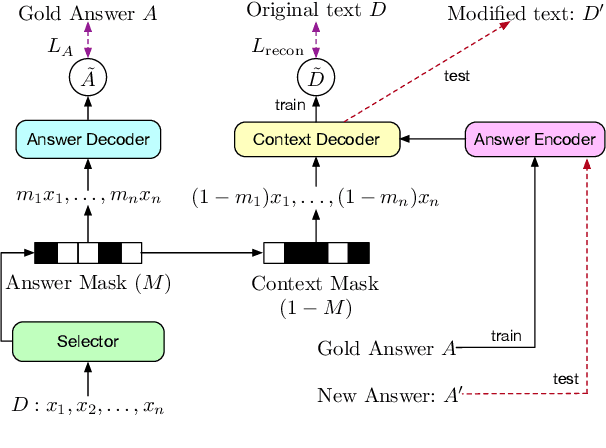
In this paper, we introduce the new task of controllable text edition, in which we take as input a long text, a question, and a target answer, and the output is a minimally modified text, so that it fits the target answer. This task is very important in many situations, such as changing some conditions, consequences, or properties in a legal document, or changing some key information of an event in a news text. This is very challenging, as it is hard to obtain a parallel corpus for training, and we need to first find all text positions that should be changed and then decide how to change them. We constructed the new dataset WikiBioCTE for this task based on the existing dataset WikiBio (originally created for table-to-text generation). We use WikiBioCTE for training, and manually labeled a test set for testing. We also propose novel evaluation metrics and a novel method for solving the new task. Experimental results on the test set show that our proposed method is a good fit for this novel NLP task.
e-ViL: A Dataset and Benchmark for Natural Language Explanations in Vision-Language Tasks
May 08, 2021


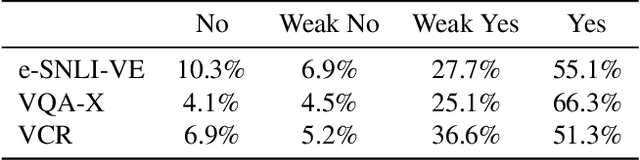
Recently, an increasing number of works have introduced models capable of generating natural language explanations (NLEs) for their predictions on vision-language (VL) tasks. Such models are appealing because they can provide human-friendly and comprehensive explanations. However, there is still a lack of unified evaluation approaches for the explanations generated by these models. Moreover, there are currently only few datasets of NLEs for VL tasks. In this work, we introduce e-ViL, a benchmark for explainable vision-language tasks that establishes a unified evaluation framework and provides the first comprehensive comparison of existing approaches that generate NLEs for VL tasks. e-ViL spans four models and three datasets. Both automatic metrics and human evaluation are used to assess model-generated explanations. We also introduce e-SNLI-VE, the largest existing VL dataset with NLEs (over 430k instances). Finally, we propose a new model that combines UNITER, which learns joint embeddings of images and text, and GPT-2, a pre-trained language model that is well-suited for text generation. It surpasses the previous state-of-the-art by a large margin across all datasets.
Multi-Label Classification Neural Networks with Hard Logical Constraints
Mar 24, 2021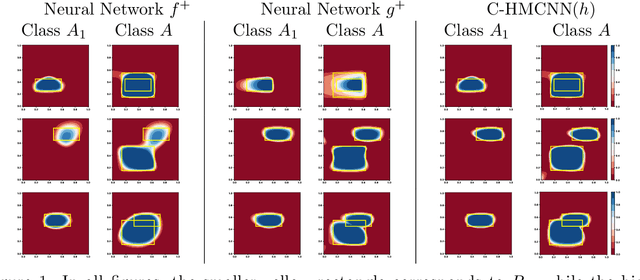
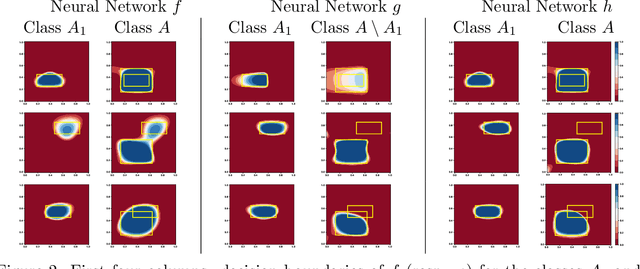
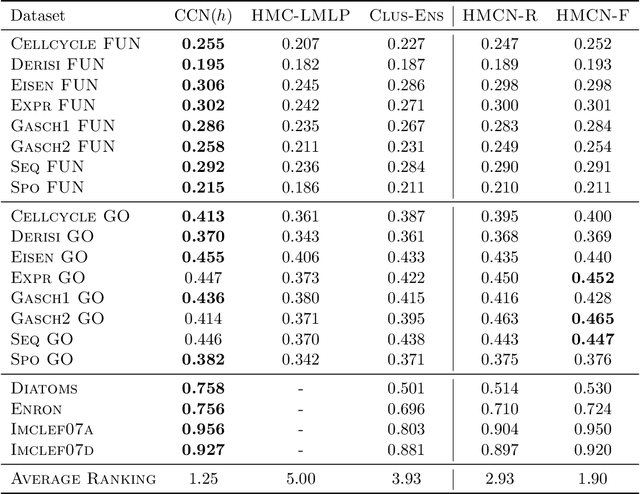
Multi-label classification (MC) is a standard machine learning problem in which a data point can be associated with a set of classes. A more challenging scenario is given by hierarchical multi-label classification (HMC) problems, in which every prediction must satisfy a given set of hard constraints expressing subclass relationships between classes. In this paper, we propose C-HMCNN(h), a novel approach for solving HMC problems, which, given a network h for the underlying MC problem, exploits the hierarchy information in order to produce predictions coherent with the constraints and to improve performance. Furthermore, we extend the logic used to express HMC constraints in order to be able to specify more complex relations among the classes and propose a new model CCN(h), which extends C-HMCNN(h) and is again able to satisfy and exploit the constraints to improve performance. We conduct an extensive experimental analysis showing the superior performance of both C-HMCNN(h) and CCN(h) when compared to state-of-the-art models in both the HMC and the general MC setting with hard logical constraints.
Predictive Coding Can Do Exact Backpropagation on Any Neural Network
Mar 08, 2021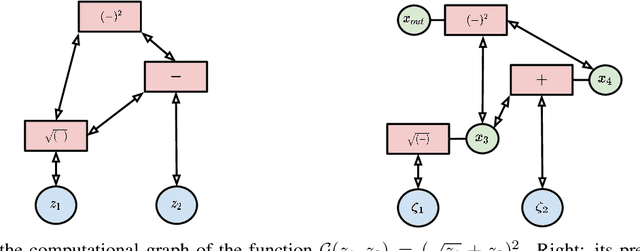
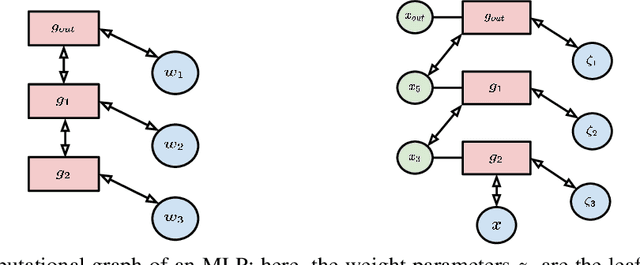

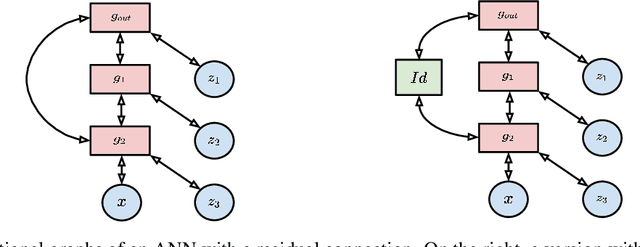
Intersecting neuroscience and deep learning has brought benefits and developments to both fields for several decades, which help to both understand how learning works in the brain, and to achieve the state-of-the-art performances in different AI benchmarks. Backpropagation (BP) is the most widely adopted method for the training of artificial neural networks, which, however, is often criticized for its biological implausibility (e.g., lack of local update rules for the parameters). Therefore, biologically plausible learning methods (e.g., inference learning (IL)) that rely on predictive coding (a framework for describing information processing in the brain) are increasingly studied. Recent works prove that IL can approximate BP up to a certain margin on multilayer perceptrons (MLPs), and asymptotically on any other complex model, and that zero-divergence inference learning (Z-IL), a variant of IL, is able to exactly implement BP on MLPs. However, the recent literature shows also that there is no biologically plausible method yet that can exactly replicate the weight update of BP on complex models. To fill this gap, in this paper, we generalize (IL and) Z-IL by directly defining them on computational graphs. To our knowledge, this is the first biologically plausible algorithm that is shown to be equivalent to BP in the way of updating parameters on any neural network, and it is thus a great breakthrough for the interdisciplinary research of neuroscience and deep learning.
Predictive Coding Can Do Exact Backpropagation on Convolutional and Recurrent Neural Networks
Mar 05, 2021
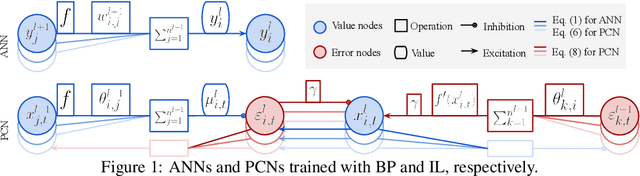
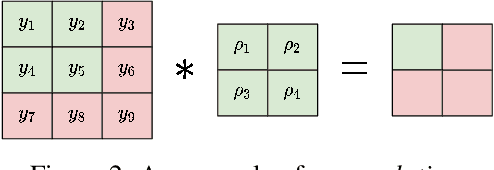

Predictive coding networks (PCNs) are an influential model for information processing in the brain. They have appealing theoretical interpretations and offer a single mechanism that accounts for diverse perceptual phenomena of the brain. On the other hand, backpropagation (BP) is commonly regarded to be the most successful learning method in modern machine learning. Thus, it is exciting that recent work formulates inference learning (IL) that trains PCNs to approximate BP. However, there are several remaining critical issues: (i) IL is an approximation to BP with unrealistic/non-trivial requirements, (ii) IL approximates BP in single-step weight updates; whether it leads to the same point as BP after the weight updates are conducted for more steps is unknown, and (iii) IL is computationally significantly more costly than BP. To solve these issues, a variant of IL that is strictly equivalent to BP in fully connected networks has been proposed. In this work, we build on this result by showing that it also holds for more complex architectures, namely, convolutional neural networks and (many-to-one) recurrent neural networks. To our knowledge, we are the first to show that a biologically plausible algorithm is able to exactly replicate the accuracy of BP on such complex architectures, bridging the existing gap between IL and BP, and setting an unprecedented performance for PCNs, which can now be considered as efficient alternatives to BP.
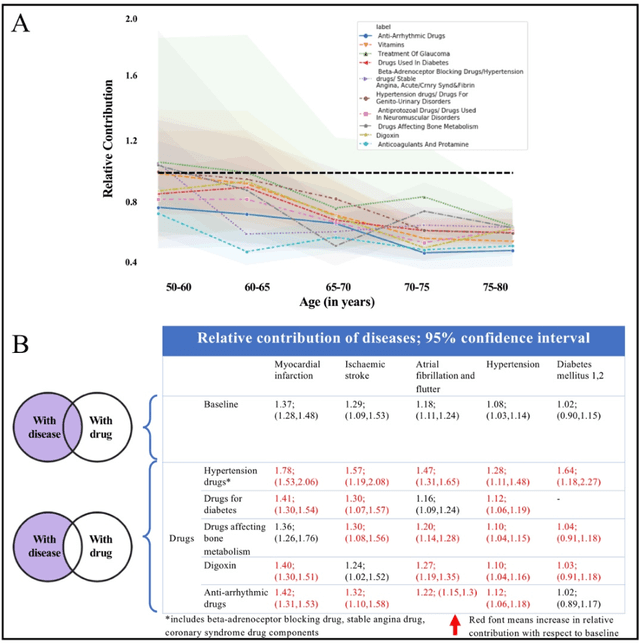
Risk factor identification for incident heart failure using neural network distillation and variable selection
Mar 01, 2021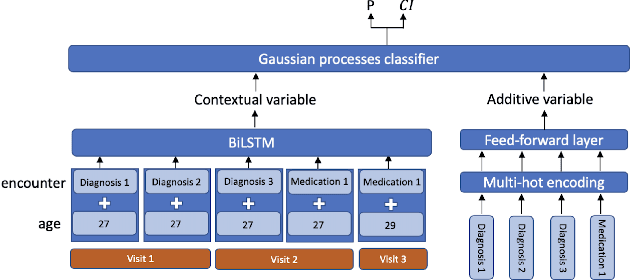
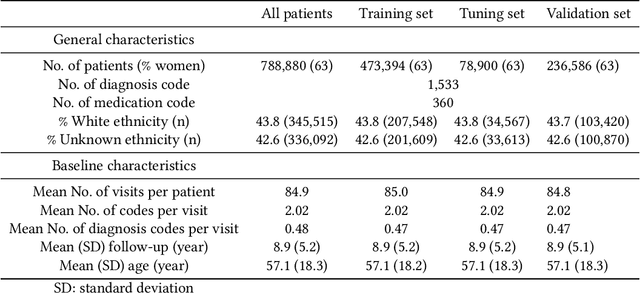
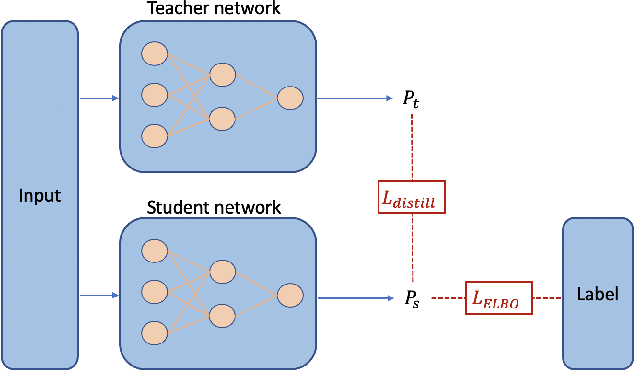
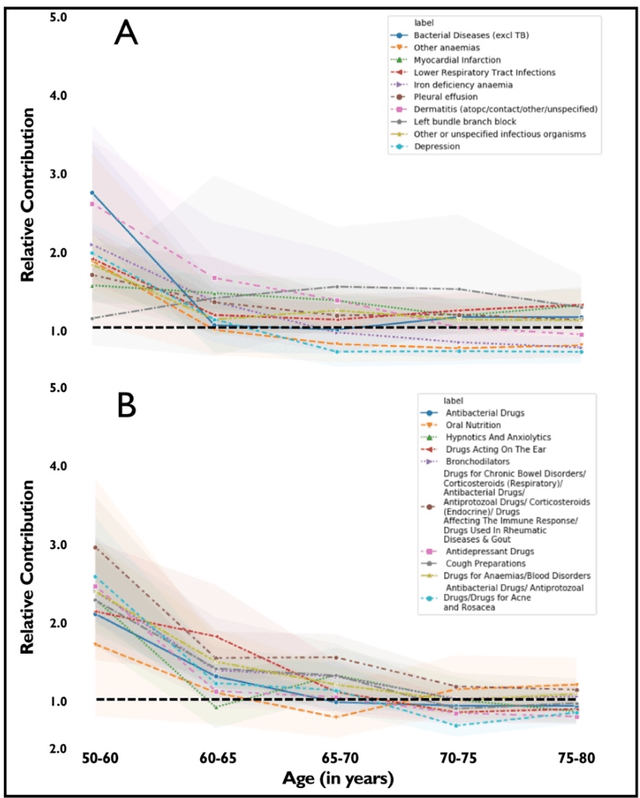
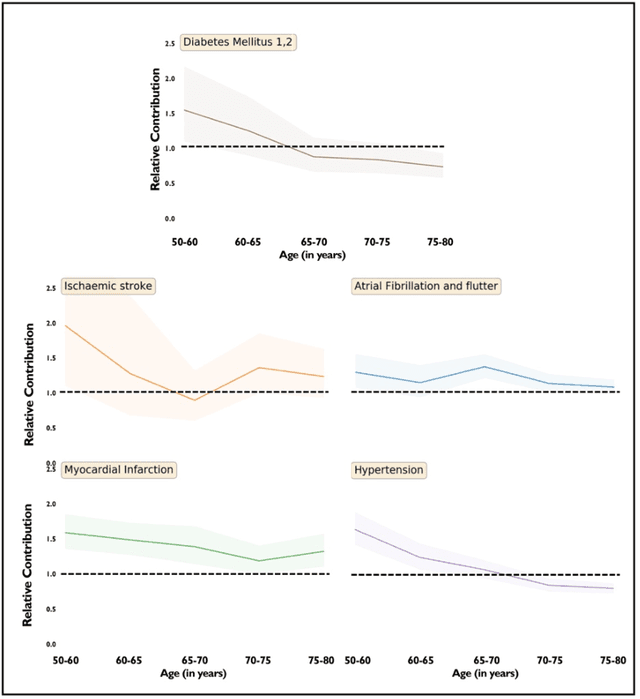
Recent evidence shows that deep learning models trained on electronic health records from millions of patients can deliver substantially more accurate predictions of risk compared to their statistical counterparts. While this provides an important opportunity for improving clinical decision-making, the lack of interpretability is a major barrier to the incorporation of these black-box models in routine care, limiting their trustworthiness and preventing further hypothesis-testing investigations. In this study, we propose two methods, namely, model distillation and variable selection, to untangle hidden patterns learned by an established deep learning model (BEHRT) for risk association identification. Due to the clinical importance and diversity of heart failure as a phenotype, it was used to showcase the merits of the proposed methods. A cohort with 788,880 (8.3% incident heart failure) patients was considered for the study. Model distillation identified 598 and 379 diseases that were associated and dissociated with heart failure at the population level, respectively. While the associations were broadly consistent with prior knowledge, our method also highlighted several less appreciated links that are worth further investigation. In addition to these important population-level insights, we developed an approach to individual-level interpretation to take account of varying manifestation of heart failure in clinical practice. This was achieved through variable selection by detecting a minimal set of encounters that can maximally preserve the accuracy of prediction for individuals. Our proposed work provides a discovery-enabling tool to identify risk factors in both population and individual levels from a data-driven perspective. This helps to generate new hypotheses and guides further investigations on causal links.
An explainable Transformer-based deep learning model for the prediction of incident heart failure
Jan 27, 2021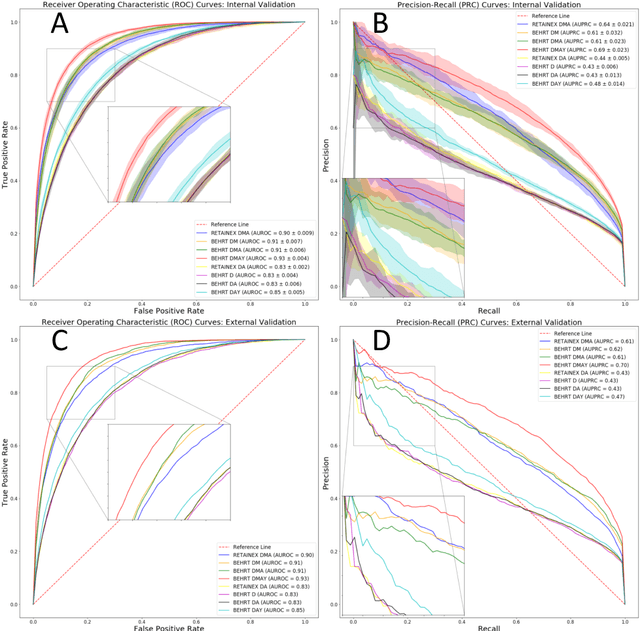
Predicting the incidence of complex chronic conditions such as heart failure is challenging. Deep learning models applied to rich electronic health records may improve prediction but remain unexplainable hampering their wider use in medical practice. We developed a novel Transformer deep-learning model for more accurate and yet explainable prediction of incident heart failure involving 100,071 patients from longitudinal linked electronic health records across the UK. On internal 5-fold cross validation and held-out external validation, our model achieved 0.93 and 0.93 area under the receiver operator curve and 0.69 and 0.70 area under the precision-recall curve, respectively and outperformed existing deep learning models. Predictor groups included all community and hospital diagnoses and medications contextualised within the age and calendar year for each patient's clinical encounter. The importance of contextualised medical information was revealed in a number of sensitivity analyses, and our perturbation method provided a way of identifying factors contributing to risk. Many of the identified risk factors were consistent with existing knowledge from clinical and epidemiological research but several new associations were revealed which had not been considered in expert-driven risk prediction models.
Learning from the Best: Rationalizing Prediction by Adversarial Information Calibration
Dec 18, 2020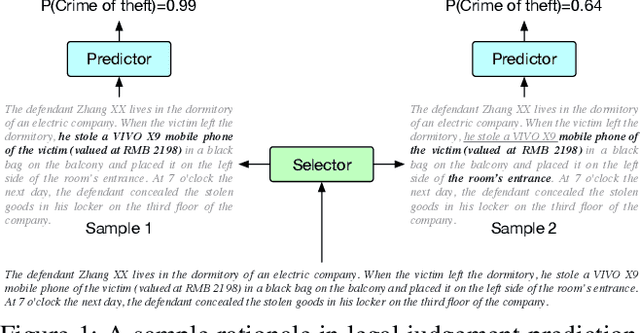
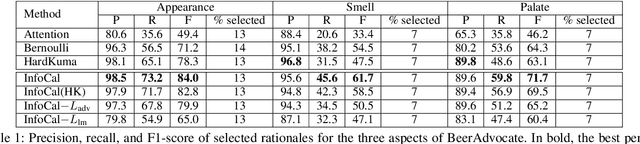
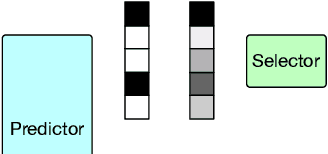

Explaining the predictions of AI models is paramount in safety-critical applications, such as in legal or medical domains. One form of explanation for a prediction is an extractive rationale, i.e., a subset of features of an instance that lead the model to give its prediction on the instance. Previous works on generating extractive rationales usually employ a two-phase model: a selector that selects the most important features (i.e., the rationale) followed by a predictor that makes the prediction based exclusively on the selected features. One disadvantage of these works is that the main signal for learning to select features comes from the comparison of the answers given by the predictor and the ground-truth answers. In this work, we propose to squeeze more information from the predictor via an information calibration method. More precisely, we train two models jointly: one is a typical neural model that solves the task at hand in an accurate but black-box manner, and the other is a selector-predictor model that additionally produces a rationale for its prediction. The first model is used as a guide to the second model. We use an adversarial-based technique to calibrate the information extracted by the two models such that the difference between them is an indicator of the missed or over-selected features. In addition, for natural language tasks, we propose to use a language-model-based regularizer to encourage the extraction of fluent rationales. Experimental results on a sentiment analysis task as well as on three tasks from the legal domain show the effectiveness of our approach to rationale extraction.