 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Fast, Flexible, and Robust Low-Light Image Enhancement
Apr 21, 2022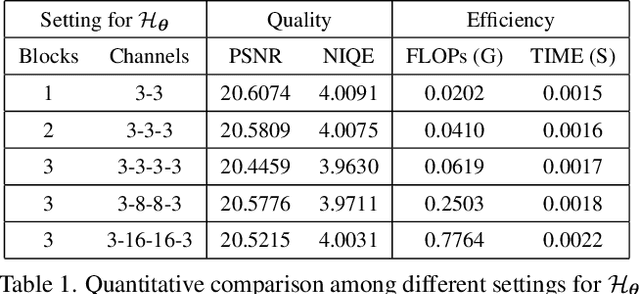
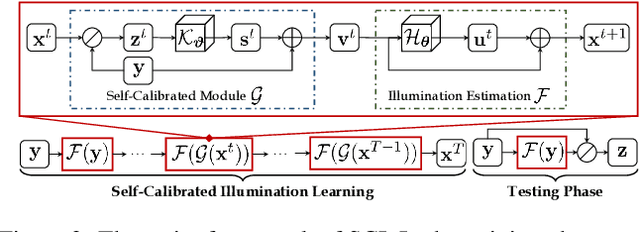
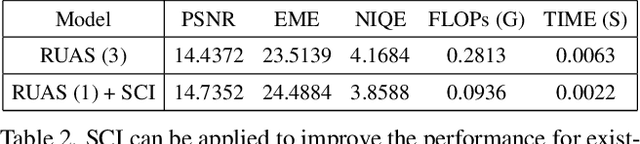

Existing low-light image enhancement techniques are mostly not only difficult to deal with both visual quality and computational efficiency but also commonly invalid in unknown complex scenarios. In this paper, we develop a new Self-Calibrated Illumination (SCI) learning framework for fast, flexible, and robust brightening images in real-world low-light scenarios. To be specific, we establish a cascaded illumination learning process with weight sharing to handle this task. Considering the computational burden of the cascaded pattern, we construct the self-calibrated module which realizes the convergence between results of each stage, producing the gains that only use the single basic block for inference (yet has not been exploited in previous works), which drastically diminishes computation cost. We then define the unsupervised training loss to elevate the model capability that can adapt to general scenes. Further, we make comprehensive explorations to excavate SCI's inherent properties (lacking in existing works) including operation-insensitive adaptability (acquiring stable performance under the settings of different simple operations) and model-irrelevant generality (can be applied to illumination-based existing works to improve performance). Finally, plenty of experiments and ablation studies fully indicate our superiority in both quality and efficiency. Applications on low-light face detection and nighttime semantic segmentation fully reveal the latent practical values for SCI. The source code is available at https://github.com/vis-opt-group/SCI.
Beyond Separability: Analyzing the Linear Transferability of Contrastive Representations to Related Subpopulations
Apr 06, 2022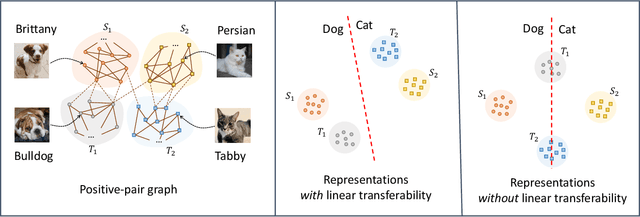

Contrastive learning is a highly effective method which uses unlabeled data to produce representations which are linearly separable for downstream classification tasks. Recent works have shown that contrastive representations are not only useful when data come from a single domain, but are also effective for transferring across domains. Concretely, when contrastive representations are trained on data from two domains (a source and target) and a linear classification head is trained to predict labels using only the labeled source data, the resulting classifier also exhibits good transfer to the target domain. In this work, we analyze this linear transferability phenomenon, building upon the framework proposed by HaoChen et al (2021) which relates contrastive learning to spectral clustering of a positive-pair graph on the data. We prove that contrastive representations capture relationships between subpopulations in the positive-pair graph: linear transferability can occur when data from the same class in different domains (e.g., photo dogs and cartoon dogs) are connected in the graph. Our analysis allows the source and target classes to have unbounded density ratios and be mapped to distant representations. Our proof is also built upon technical improvements over the main results of HaoChen et al (2021), which may be of independent interest.
Connect, Not Collapse: Explaining Contrastive Learning for Unsupervised Domain Adaptation
Apr 01, 2022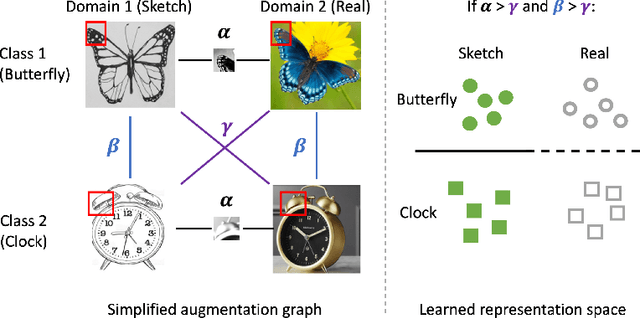
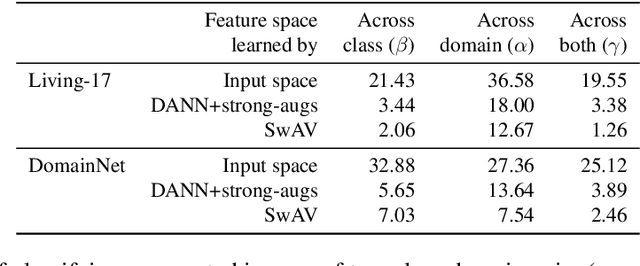
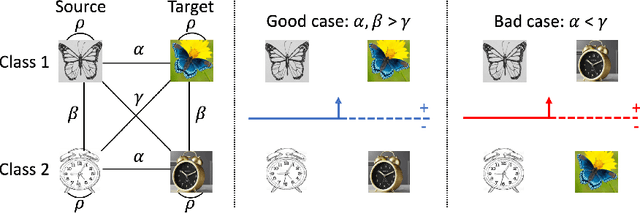

We consider unsupervised domain adaptation (UDA), where labeled data from a source domain (e.g., photographs) and unlabeled data from a target domain (e.g., sketches) are used to learn a classifier for the target domain. Conventional UDA methods (e.g., domain adversarial training) learn domain-invariant features to improve generalization to the target domain. In this paper, we show that contrastive pre-training, which learns features on unlabeled source and target data and then fine-tunes on labeled source data, is competitive with strong UDA methods. However, we find that contrastive pre-training does not learn domain-invariant features, diverging from conventional UDA intuitions. We show theoretically that contrastive pre-training can learn features that vary subtantially across domains but still generalize to the target domain, by disentangling domain and class information. Our results suggest that domain invariance is not necessary for UDA. We empirically validate our theory on benchmark vision datasets.
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
Feb 21, 2022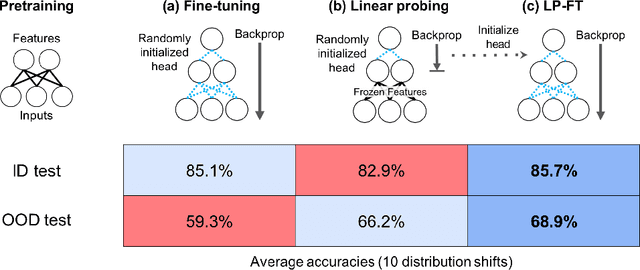

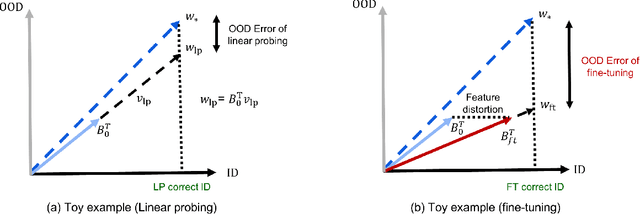
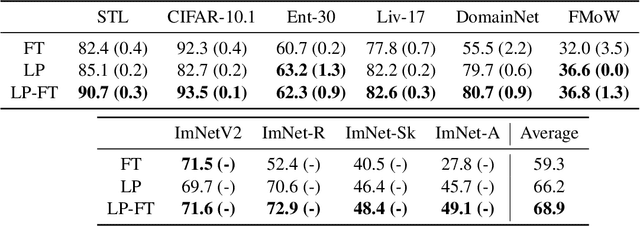
When transferring a pretrained model to a downstream task, two popular methods are full fine-tuning (updating all the model parameters) and linear probing (updating only the last linear layer -- the "head"). It is well known that fine-tuning leads to better accuracy in-distribution (ID). However, in this paper, we find that fine-tuning can achieve worse accuracy than linear probing out-of-distribution (OOD) when the pretrained features are good and the distribution shift is large. On 10 distribution shift datasets (Breeds-Living17, Breeds-Entity30, DomainNet, CIFAR $\to$ STL, CIFAR10.1, FMoW, ImageNetV2, ImageNet-R, ImageNet-A, ImageNet-Sketch), fine-tuning obtains on average 2% higher accuracy ID but 7% lower accuracy OOD than linear probing. We show theoretically that this tradeoff between ID and OOD accuracy arises even in a simple setting: fine-tuning overparameterized two-layer linear networks. We prove that the OOD error of fine-tuning is high when we initialize with a fixed or random head -- this is because while fine-tuning learns the head, the lower layers of the neural network change simultaneously and distort the pretrained features. Our analysis suggests that the easy two-step strategy of linear probing then full fine-tuning (LP-FT), sometimes used as a fine-tuning heuristic, combines the benefits of both fine-tuning and linear probing. Empirically, LP-FT outperforms both fine-tuning and linear probing on the above datasets (1% better ID, 10% better OOD than full fine-tuning).
Safe Reinforcement Learning by Imagining the Near Future
Feb 15, 2022
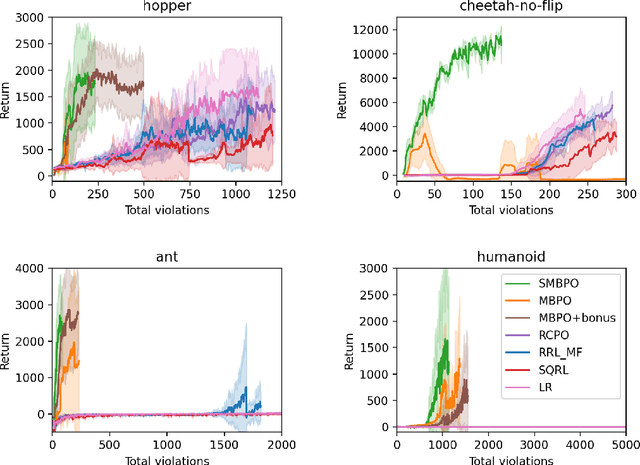
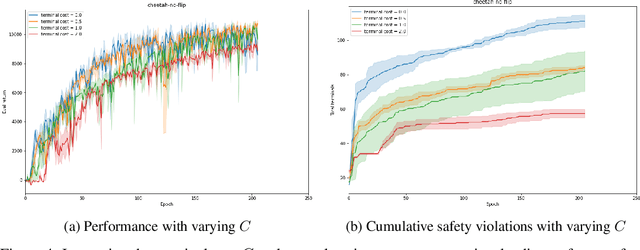
Safe reinforcement learning is a promising path toward applying reinforcement learning algorithms to real-world problems, where suboptimal behaviors may lead to actual negative consequences. In this work, we focus on the setting where unsafe states can be avoided by planning ahead a short time into the future. In this setting, a model-based agent with a sufficiently accurate model can avoid unsafe states. We devise a model-based algorithm that heavily penalizes unsafe trajectories, and derive guarantees that our algorithm can avoid unsafe states under certain assumptions. Experiments demonstrate that our algorithm can achieve competitive rewards with fewer safety violations in several continuous control tasks.
Learning with Nested Scene Modeling and Cooperative Architecture Search for Low-Light Vision
Dec 09, 2021
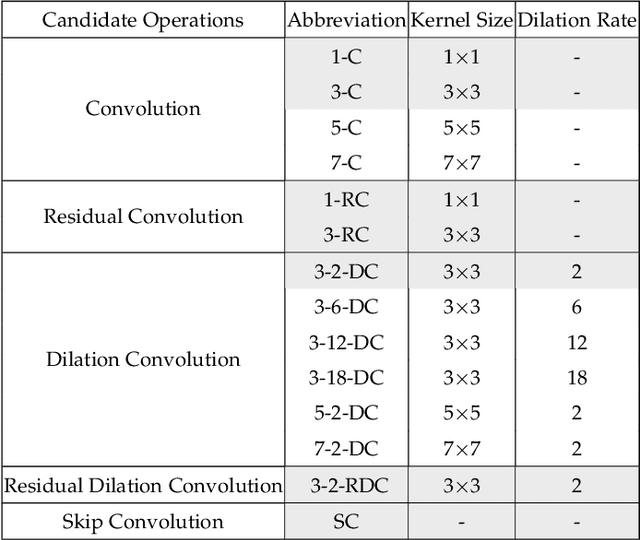
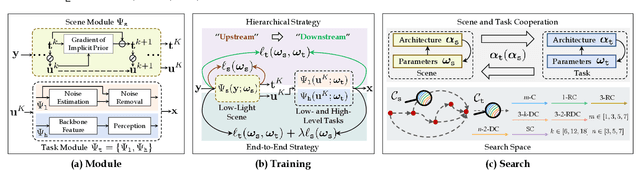
Images captured from low-light scenes often suffer from severe degradations, including low visibility, color cast and intensive noises, etc. These factors not only affect image qualities, but also degrade the performance of downstream Low-Light Vision (LLV) applications. A variety of deep learning methods have been proposed to enhance the visual quality of low-light images. However, these approaches mostly rely on significant architecture engineering to obtain proper low-light models and often suffer from high computational burden. Furthermore, it is still challenging to extend these enhancement techniques to handle other LLVs. To partially address above issues, we establish Retinex-inspired Unrolling with Architecture Search (RUAS), a general learning framework, which not only can address low-light enhancement task, but also has the flexibility to handle other more challenging downstream vision applications. Specifically, we first establish a nested optimization formulation, together with an unrolling strategy, to explore underlying principles of a series of LLV tasks. Furthermore, we construct a differentiable strategy to cooperatively search specific scene and task architectures for RUAS. Last but not least, we demonstrate how to apply RUAS for both low- and high-level LLV applications (e.g., enhancement, detection and segmentation). Extensive experiments verify the flexibility, effectiveness, and efficiency of RUAS.
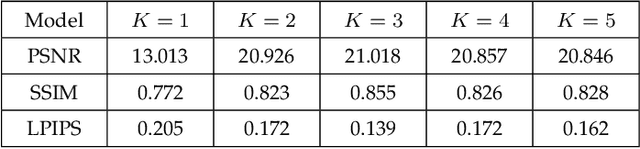
DR3: Value-Based Deep Reinforcement Learning Requires Explicit Regularization
Dec 09, 2021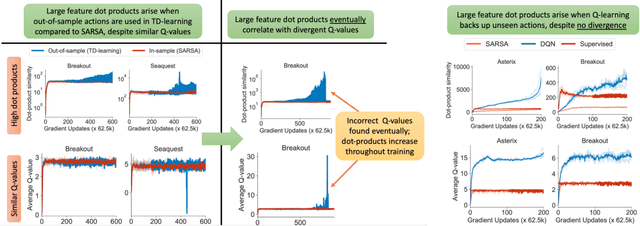
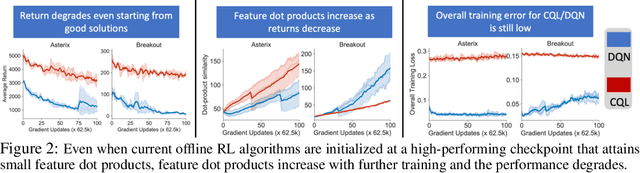

Despite overparameterization, deep networks trained via supervised learning are easy to optimize and exhibit excellent generalization. One hypothesis to explain this is that overparameterized deep networks enjoy the benefits of implicit regularization induced by stochastic gradient descent, which favors parsimonious solutions that generalize well on test inputs. It is reasonable to surmise that deep reinforcement learning (RL) methods could also benefit from this effect. In this paper, we discuss how the implicit regularization effect of SGD seen in supervised learning could in fact be harmful in the offline deep RL setting, leading to poor generalization and degenerate feature representations. Our theoretical analysis shows that when existing models of implicit regularization are applied to temporal difference learning, the resulting derived regularizer favors degenerate solutions with excessive "aliasing", in stark contrast to the supervised learning case. We back up these findings empirically, showing that feature representations learned by a deep network value function trained via bootstrapping can indeed become degenerate, aliasing the representations for state-action pairs that appear on either side of the Bellman backup. To address this issue, we derive the form of this implicit regularizer and, inspired by this derivation, propose a simple and effective explicit regularizer, called DR3, that counteracts the undesirable effects of this implicit regularizer. When combined with existing offline RL methods, DR3 substantially improves performance and stability, alleviating unlearning in Atari 2600 games, D4RL domains and robotic manipulation from images.
Plan Better Amid Conservatism: Offline Multi-Agent Reinforcement Learning with Actor Rectification
Nov 22, 2021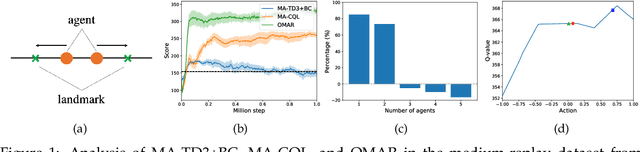
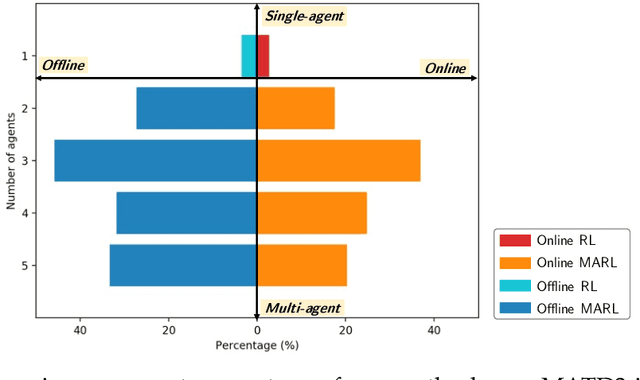
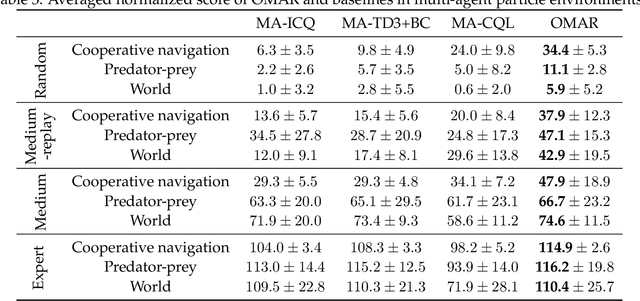
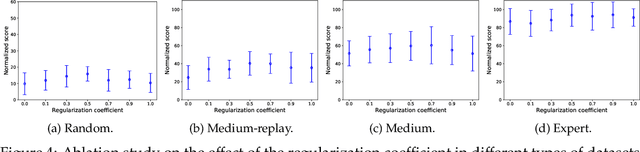
The idea of conservatism has led to significant progress in offline reinforcement learning (RL) where an agent learns from pre-collected datasets. However, it is still an open question to resolve offline RL in the more practical multi-agent setting as many real-world scenarios involve interaction among multiple agents. Given the recent success of transferring online RL algorithms to the multi-agent setting, one may expect that offline RL algorithms will also transfer to multi-agent settings directly. Surprisingly, when conservatism-based algorithms are applied to the multi-agent setting, the performance degrades significantly with an increasing number of agents. Towards mitigating the degradation, we identify that a key issue that the landscape of the value function can be non-concave and policy gradient improvements are prone to local optima. Multiple agents exacerbate the problem since the suboptimal policy by any agent could lead to uncoordinated global failure. Following this intuition, we propose a simple yet effective method, Offline Multi-Agent RL with Actor Rectification (OMAR), to tackle this critical challenge via an effective combination of first-order policy gradient and zeroth-order optimization methods for the actor to better optimize the conservative value function. Despite the simplicity, OMAR significantly outperforms strong baselines with state-of-the-art performance in multi-agent continuous control benchmarks.
An Explanation of In-context Learning as Implicit Bayesian Inference
Nov 14, 2021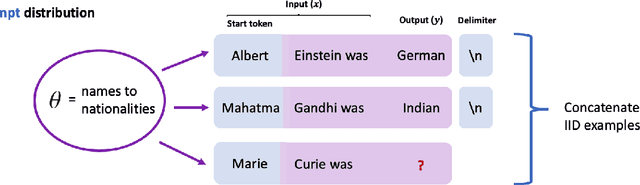
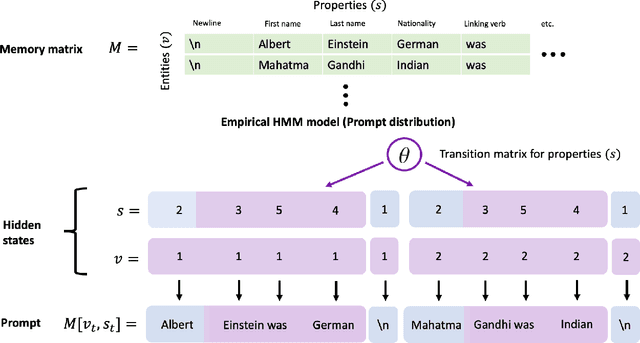
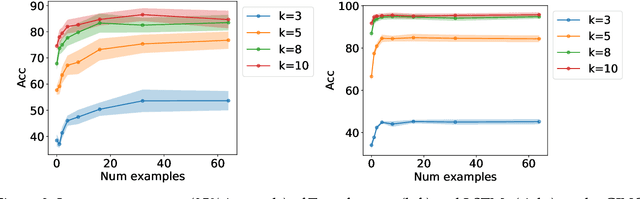

Large pretrained language models such as GPT-3 have the surprising ability to do in-context learning, where the model learns to do a downstream task simply by conditioning on a prompt consisting of input-output examples. Without being explicitly pretrained to do so, the language model learns from these examples during its forward pass without parameter updates on "out-of-distribution" prompts. Thus, it is unclear what mechanism enables in-context learning. In this paper, we study the role of the pretraining distribution on the emergence of in-context learning under a mathematical setting where the pretraining texts have long-range coherence. Here, language model pretraining requires inferring a latent document-level concept from the conditioning text to generate coherent next tokens. At test time, this mechanism enables in-context learning by inferring the shared latent concept between prompt examples and applying it to make a prediction on the test example. Concretely, we prove that in-context learning occurs implicitly via Bayesian inference of the latent concept when the pretraining distribution is a mixture of HMMs. This can occur despite the distribution mismatch between prompts and pretraining data. In contrast to messy large-scale pretraining datasets for in-context learning in natural language, we generate a family of small-scale synthetic datasets (GINC) where Transformer and LSTM language models both exhibit in-context learning. Beyond the theory which focuses on the effect of the pretraining distribution, we empirically find that scaling model size improves in-context accuracy even when the pretraining loss is the same.
Sharp Bounds for Federated Averaging (Local SGD) and Continuous Perspective
Nov 05, 2021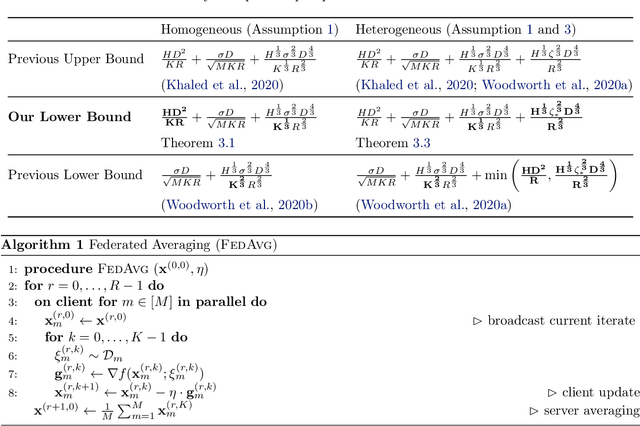
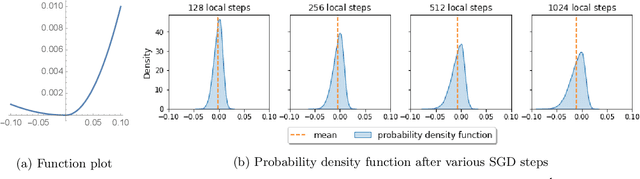
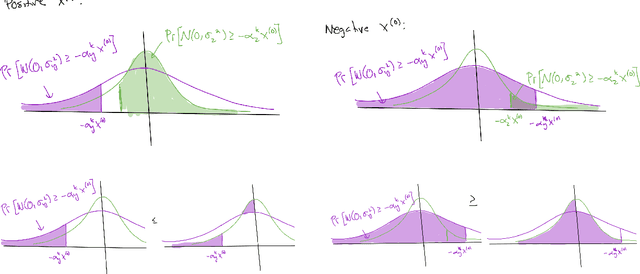
Federated Averaging (FedAvg), also known as Local SGD, is one of the most popular algorithms in Federated Learning (FL). Despite its simplicity and popularity, the convergence rate of FedAvg has thus far been undetermined. Even under the simplest assumptions (convex, smooth, homogeneous, and bounded covariance), the best-known upper and lower bounds do not match, and it is not clear whether the existing analysis captures the capacity of the algorithm. In this work, we first resolve this question by providing a lower bound for FedAvg that matches the existing upper bound, which shows the existing FedAvg upper bound analysis is not improvable. Additionally, we establish a lower bound in a heterogeneous setting that nearly matches the existing upper bound. While our lower bounds show the limitations of FedAvg, under an additional assumption of third-order smoothness, we prove more optimistic state-of-the-art convergence results in both convex and non-convex settings. Our analysis stems from a notion we call iterate bias, which is defined by the deviation of the expectation of the SGD trajectory from the noiseless gradient descent trajectory with the same initialization. We prove novel sharp bounds on this quantity, and show intuitively how to analyze this quantity from a Stochastic Differential Equation (SDE) perspective.