 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPSep: Learning Text-queried Sound Separation with Noisy Unlabeled Videos
Dec 14, 2022



Recent years have seen progress beyond domain-specific sound separation for speech or music towards universal sound separation for arbitrary sounds. Prior work on universal sound separation has investigated separating a target sound out of an audio mixture given a text query. Such text-queried sound separation systems provide a natural and scalable interface for specifying arbitrary target sounds. However, supervised text-queried sound separation systems require costly labeled audio-text pairs for training. Moreover, the audio provided in existing datasets is often recorded in a controlled environment, causing a considerable generalization gap to noisy audio in the wild. In this work, we aim to approach text-queried universal sound separation by using only unlabeled data. We propose to leverage the visual modality as a bridge to learn the desired audio-textual correspondence. The proposed CLIPSep model first encodes the input query into a query vector using the contrastive language-image pretraining (CLIP) model, and the query vector is then used to condition an audio separation model to separate out the target sound. While the model is trained on image-audio pairs extracted from unlabeled videos, at test time we can instead query the model with text inputs in a zero-shot setting, thanks to the joint language-image embedding learned by the CLIP model. Further, videos in the wild often contain off-screen sounds and background noise that may hinder the model from learning the desired audio-textual correspondence. To address this problem, we further propose an approach called noise invariant training for training a query-based sound separation model on noisy data. Experimental results show that the proposed models successfully learn text-queried universal sound separation using only noisy unlabeled videos, even achieving competitive performance against a supervised model in some settings.
Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
Nov 12, 2022Contrastive learning has shown remarkable success in the field of multimodal representation learning. In this paper, we propose a pipeline of contrastive language-audio pretraining to develop an audio representation by combining audio data with natural language descriptions. To accomplish this target, we first release LAION-Audio-630K, a large collection of 633,526 audio-text pairs from different data sources. Second, we construct a contrastive language-audio pretraining model by considering different audio encoders and text encoders. We incorporate the feature fusion mechanism and keyword-to-caption augmentation into the model design to further enable the model to process audio inputs of variable lengths and enhance the performance. Third, we perform comprehensive experiments to evaluate our model across three tasks: text-to-audio retrieval, zero-shot audio classification, and supervised audio classification. The results demonstrate that our model achieves superior performance in text-to-audio retrieval task. In audio classification tasks, the model achieves state-of-the-art performance in the zero-shot setting and is able to obtain performance comparable to models' results in the non-zero-shot setting. LAION-Audio-630K and the proposed model are both available to the public.
Non-Parametric Temporal Adaptation for Social Media Topic Classification
Sep 13, 2022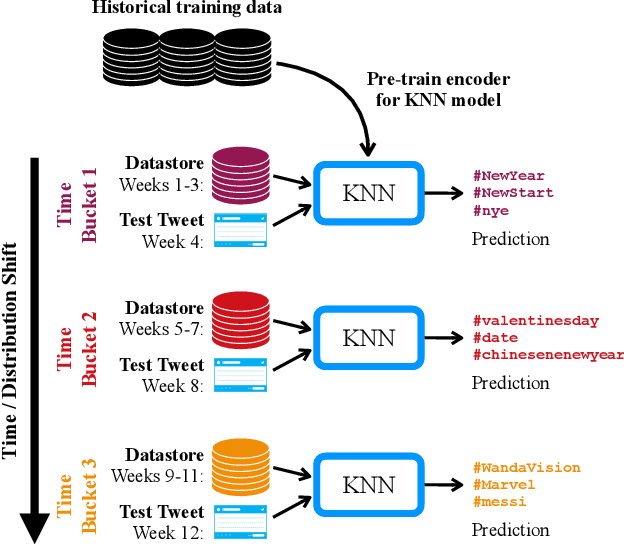
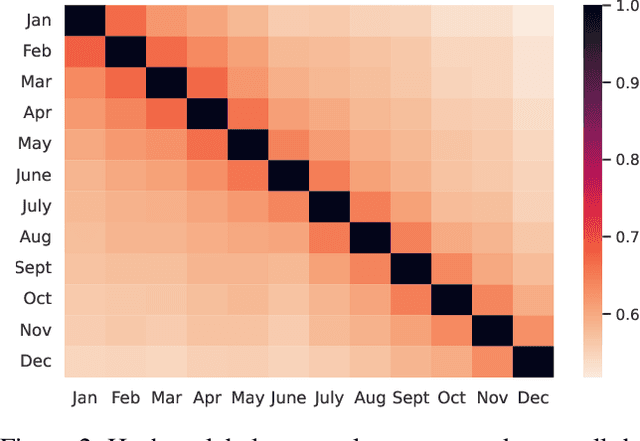
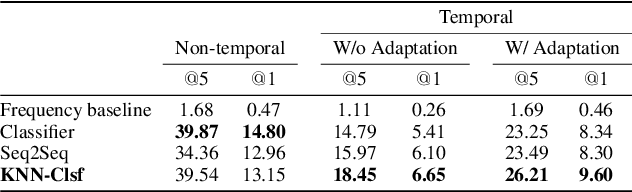
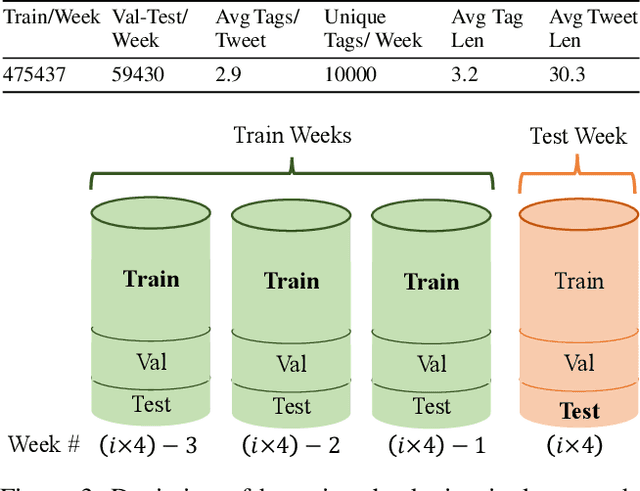
User-generated social media data is constantly changing as new trends influence online discussion, causing distribution shift in test data for social media NLP applications. In addition, training data is often subject to change as user data is deleted. Most current NLP systems are static and rely on fixed training data. As a result, they are unable to adapt to temporal change -- both test distribution shift and deleted training data -- without frequent, costly re-training. In this paper, we study temporal adaptation through the task of longitudinal hashtag prediction and propose a non-parametric technique as a simple but effective solution: non-parametric classifiers use datastores which can be updated, either to adapt to test distribution shift or training data deletion, without re-training. We release a new benchmark dataset comprised of 7.13M Tweets from 2021, along with their hashtags, broken into consecutive temporal buckets. We compare parametric neural hashtag classification and hashtag generation models, which need re-training for adaptation, with a non-parametric, training-free dense retrieval method that returns the nearest neighbor's hashtags based on text embedding distance. In experiments on our longitudinal Twitter dataset we find that dense nearest neighbor retrieval has a relative performance gain of 64.12% over the best parametric baseline on test sets that exhibit distribution shift without requiring gradient-based re-training. Furthermore, we show that our datastore approach is particularly well-suited to dynamically deleted user data, with negligible computational cost and performance loss. Our novel benchmark dataset and empirical analysis can support future inquiry into the important challenges presented by temporality in the deployment of AI systems on real-world user data.
Checklist Models for Improved Output Fluency in Piano Fingering Prediction
Sep 12, 2022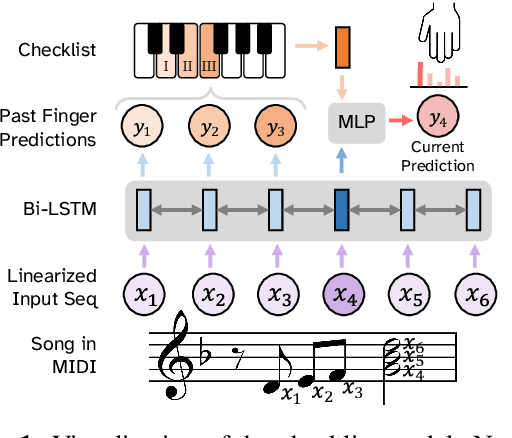
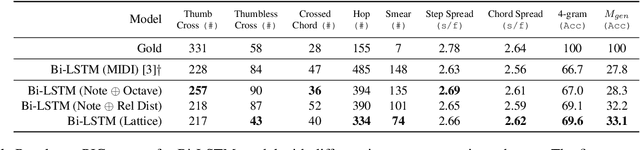
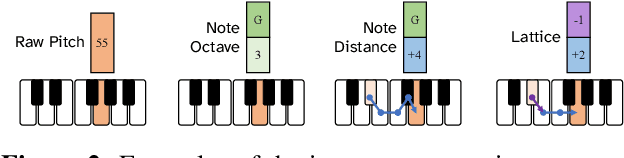
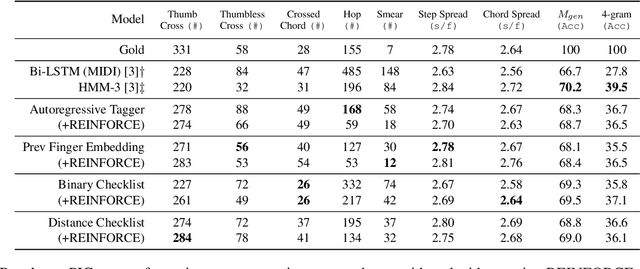
In this work we present a new approach for the task of predicting fingerings for piano music. While prior neural approaches have often treated this as a sequence tagging problem with independent predictions, we put forward a checklist system, trained via reinforcement learning, that maintains a representation of recent predictions in addition to a hidden state, allowing it to learn soft constraints on output structure. We also demonstrate that by modifying input representations -- which in prior work using neural models have often taken the form of one-hot encodings over individual keys on the piano -- to encode relative position on the keyboard to the prior note instead, we can achieve much better performance. Additionally, we reassess the use of raw per-note labeling precision as an evaluation metric, noting that it does not adequately measure the fluency, i.e. human playability, of a model's output. To this end, we compare methods across several statistics which track the frequency of adjacent finger predictions that while independently reasonable would be physically challenging to perform in sequence, and implement a reinforcement learning strategy to minimize these as part of our training loss. Finally through human expert evaluation, we demonstrate significant gains in performability directly attributable to improvements with respect to these metrics.
Improving Choral Music Separation through Expressive Synthesized Data from Sampled Instruments
Sep 07, 2022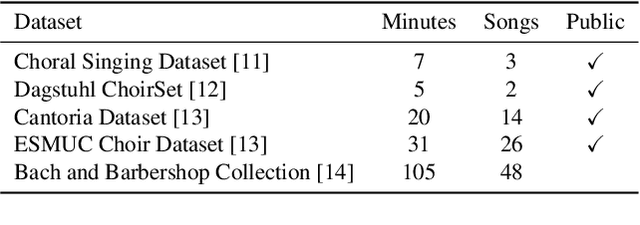
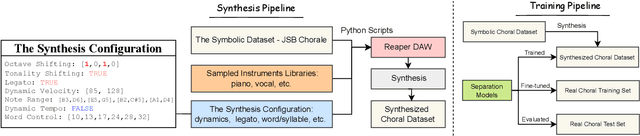
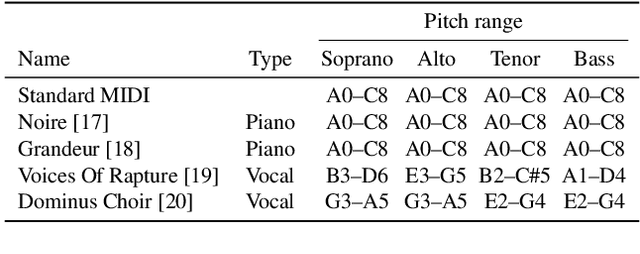

Choral music separation refers to the task of extracting tracks of voice parts (e.g., soprano, alto, tenor, and bass) from mixed audio. The lack of datasets has impeded research on this topic as previous work has only been able to train and evaluate models on a few minutes of choral music data due to copyright issues and dataset collection difficulties. In this paper, we investigate the use of synthesized training data for the source separation task on real choral music. We make three contributions: first, we provide an automated pipeline for synthesizing choral music data from sampled instrument plugins within controllable options for instrument expressiveness. This produces an 8.2-hour-long choral music dataset from the JSB Chorales Dataset and one can easily synthesize additional data. Second, we conduct an experiment to evaluate multiple separation models on available choral music separation datasets from previous work. To the best of our knowledge, this is the first experiment to comprehensively evaluate choral music separation. Third, experiments demonstrate that the synthesized choral data is of sufficient quality to improve the model's performance on real choral music datasets. This provides additional experimental statistics and data support for the choral music separation study.
* Camera Ready for Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022
Multitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments
Jul 14, 2022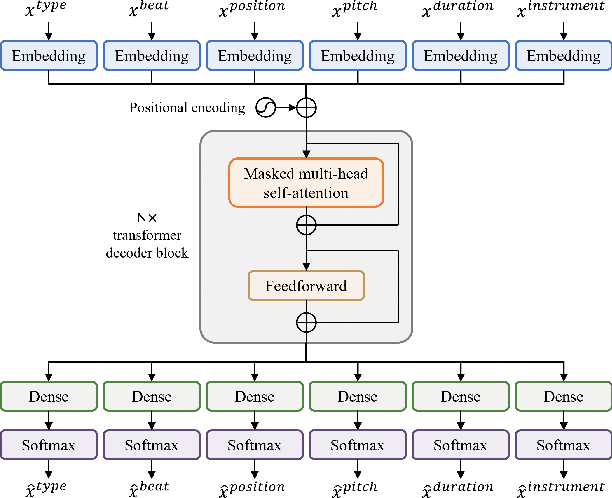
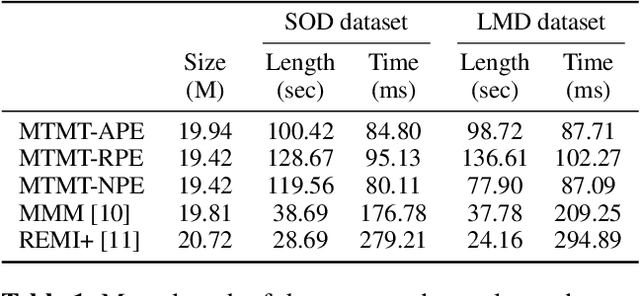
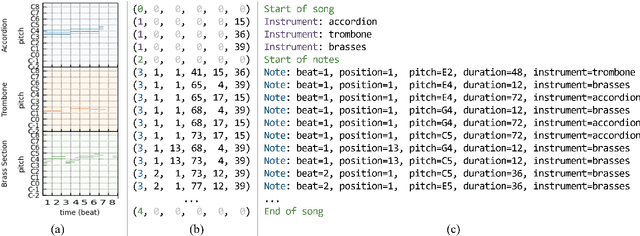
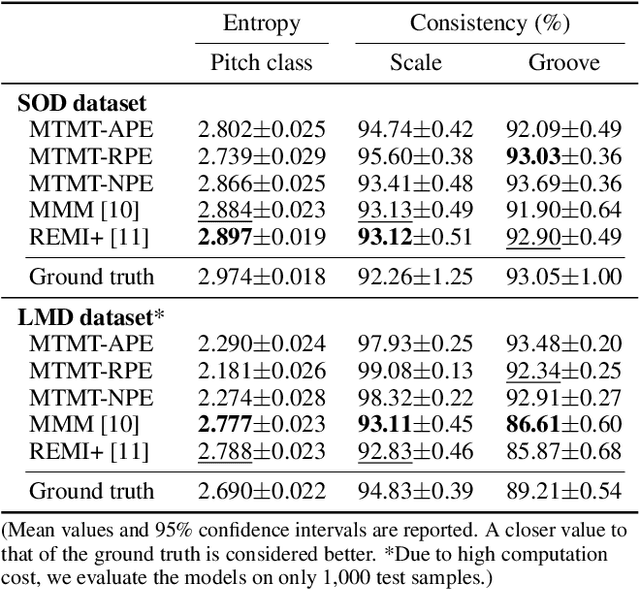
Existing approaches for generating multitrack music with transformer models have been limited to either a small set of instruments or short music segments. This is partly due to the memory requirements of the lengthy input sequences necessitated by existing representations for multitrack music. In this work, we propose a compact representation that allows a diverse set of instruments while keeping a short sequence length. Using our proposed representation, we present the Multitrack Music Transformer (MTMT) for learning long-term dependencies in multitrack music. In a subjective listening test, our proposed model achieves competitive quality on unconditioned generation against two baseline models. We also show that our proposed model can generate samples that are twice as long as those produced by the baseline models, and, further, can do so in half the inference time. Moreover, we propose a new measure for analyzing musical self-attentions and show that the trained model learns to pay less attention to notes that form a dissonant interval with the current note, yet attending more to notes that are 4N beats away from current. Finally, our findings provide a novel foundation for future work exploring longer-form multitrack music generation and improving self-attentions for music. All source code and audio samples can be found at https://salu133445.github.io/mtmt/ .
Memorization in NLP Fine-tuning Methods
May 25, 2022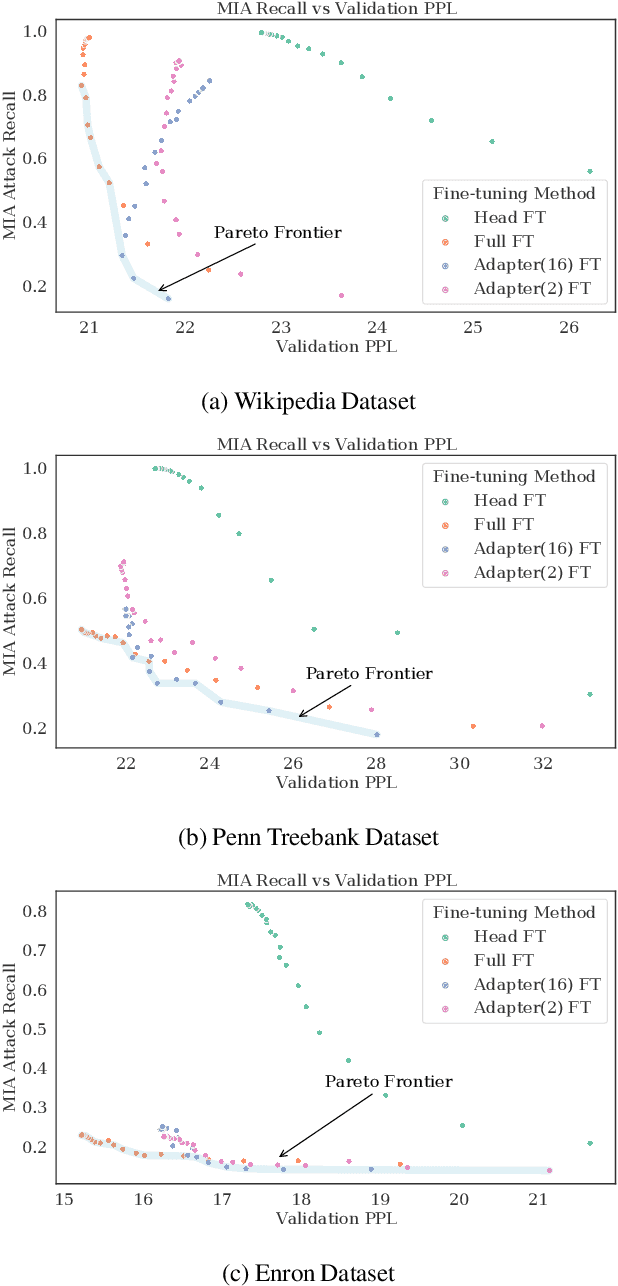
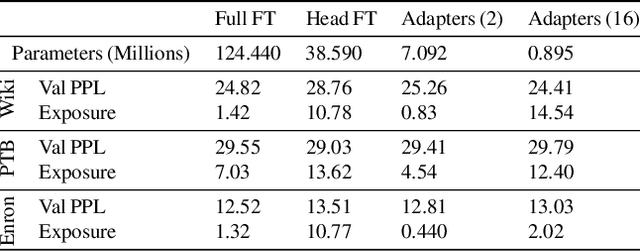
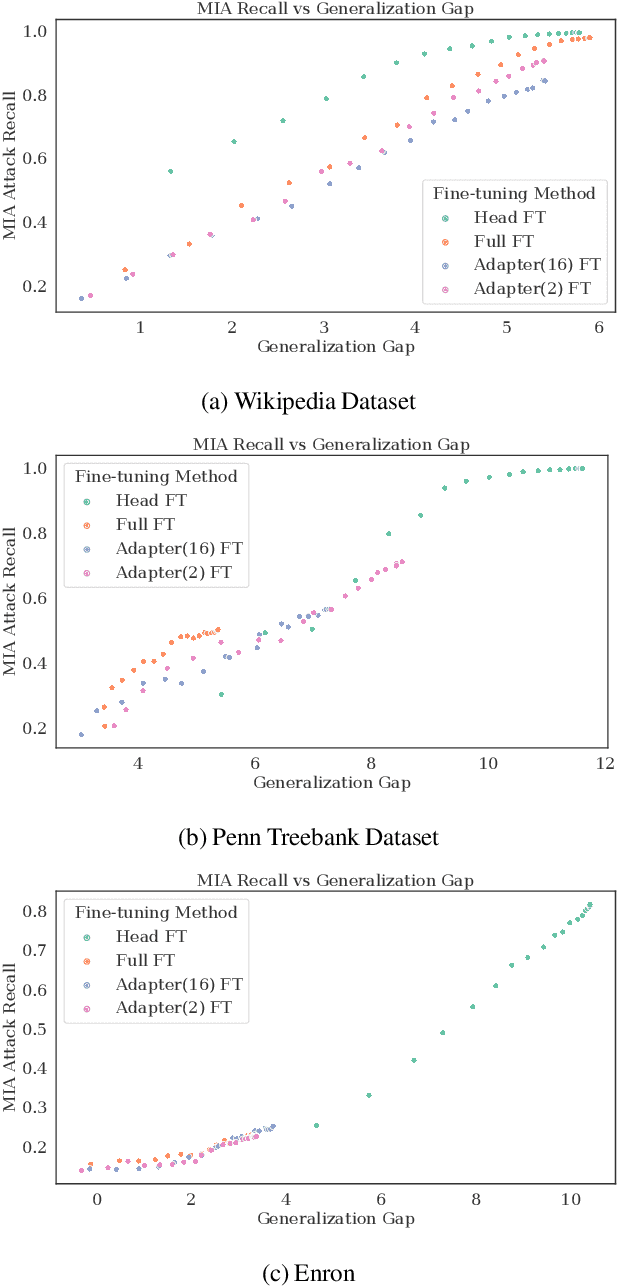

Large language models are shown to present privacy risks through memorization of training data, and several recent works have studied such risks for the pre-training phase. Little attention, however, has been given to the fine-tuning phase and it is not well understood how different fine-tuning methods (such as fine-tuning the full model, the model head, and adapter) compare in terms of memorization risk. This presents increasing concern as the "pre-train and fine-tune" paradigm proliferates. In this paper, we empirically study memorization of fine-tuning methods using membership inference and extraction attacks, and show that their susceptibility to attacks is very different. We observe that fine-tuning the head of the model has the highest susceptibility to attacks, whereas fine-tuning smaller adapters appears to be less vulnerable to known extraction attacks.
Prompt Consistency for Zero-Shot Task Generalization
Apr 29, 2022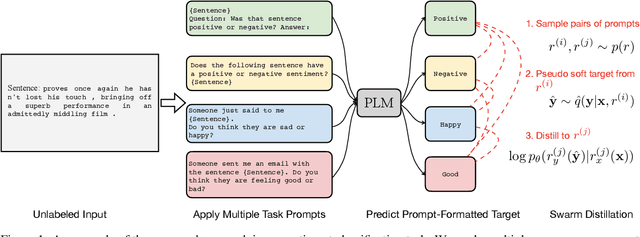
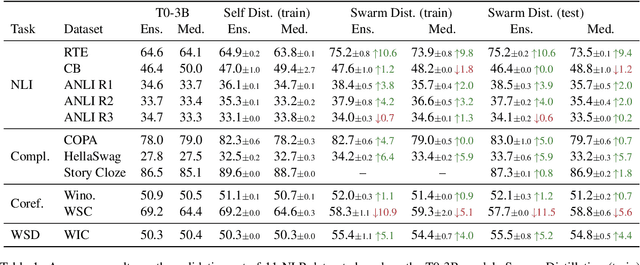
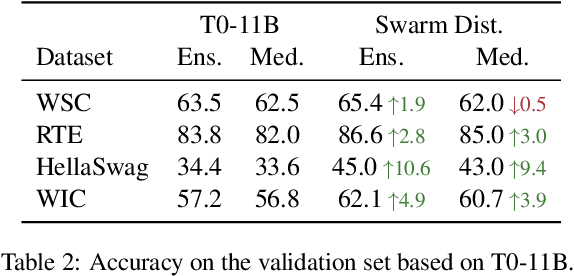
One of the most impressive results of recent NLP history is the ability of pre-trained language models to solve new tasks in a zero-shot setting. To achieve this, NLP tasks are framed as natural language prompts, generating a response indicating the predicted output. Nonetheless, the performance in such settings often lags far behind its supervised counterpart, suggesting a large space for potential improvement. In this paper, we explore methods to utilize unlabeled data to improve zero-shot performance. Specifically, we take advantage of the fact that multiple prompts can be used to specify a single task, and propose to regularize prompt consistency, encouraging consistent predictions over this diverse set of prompts. Our method makes it possible to fine-tune the model either with extra unlabeled training data, or directly on test input at inference time in an unsupervised manner. In experiments, our approach outperforms the state-of-the-art zero-shot learner, T0 (Sanh et al., 2022), on 9 out of 11 datasets across 4 NLP tasks by up to 10.6 absolute points in terms of accuracy. The gains are often attained with a small number of unlabeled examples.
Mix and Match: Learning-free Controllable Text Generation using Energy Language Models
Apr 04, 2022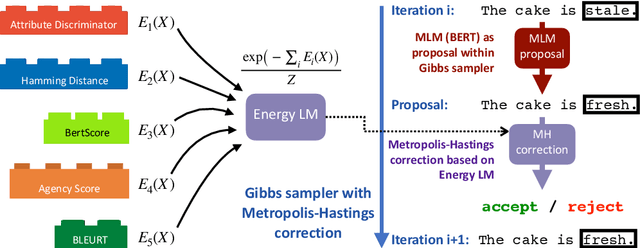

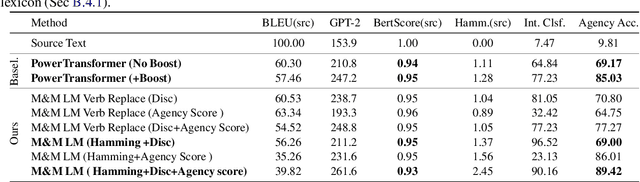
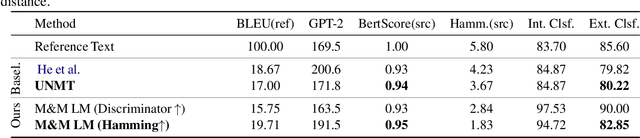
Recent work on controlled text generation has either required attribute-based fine-tuning of the base language model (LM), or has restricted the parameterization of the attribute discriminator to be compatible with the base autoregressive LM. In this work, we propose Mix and Match LM, a global score-based alternative for controllable text generation that combines arbitrary pre-trained black-box models for achieving the desired attributes in the generated text without involving any fine-tuning or structural assumptions about the black-box models. We interpret the task of controllable generation as drawing samples from an energy-based model whose energy values are a linear combination of scores from black-box models that are separately responsible for fluency, the control attribute, and faithfulness to any conditioning context. We use a Metropolis-Hastings sampling scheme to sample from this energy-based model using bidirectional context and global attribute features. We validate the effectiveness of our approach on various controlled generation and style-based text revision tasks by outperforming recently proposed methods that involve extra training, fine-tuning, or restrictive assumptions over the form of models.
Achieving Conversational Goals with Unsupervised Post-hoc Knowledge Injection
Mar 22, 2022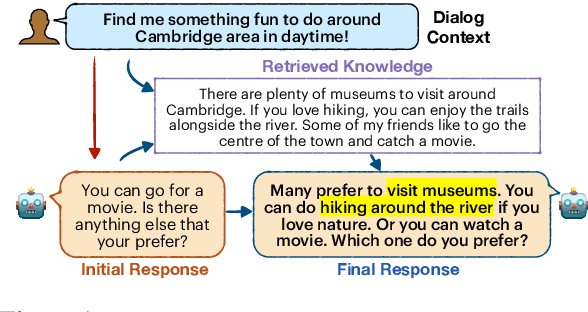
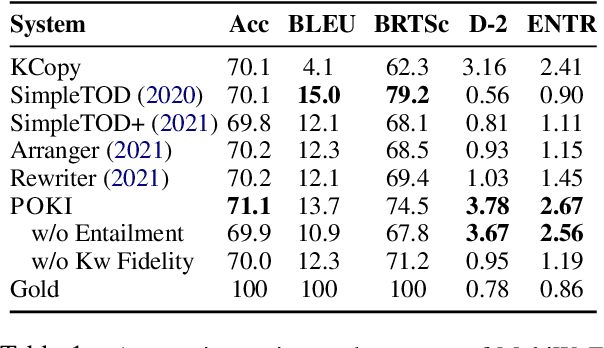
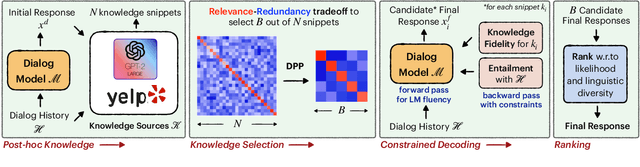
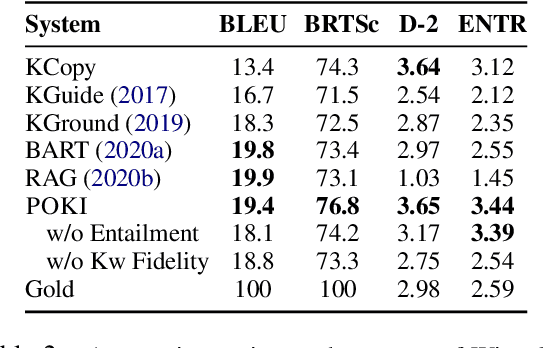
A limitation of current neural dialog models is that they tend to suffer from a lack of specificity and informativeness in generated responses, primarily due to dependence on training data that covers a limited variety of scenarios and conveys limited knowledge. One way to alleviate this issue is to extract relevant knowledge from external sources at decoding time and incorporate it into the dialog response. In this paper, we propose a post-hoc knowledge-injection technique where we first retrieve a diverse set of relevant knowledge snippets conditioned on both the dialog history and an initial response from an existing dialog model. We construct multiple candidate responses, individually injecting each retrieved snippet into the initial response using a gradient-based decoding method, and then select the final response with an unsupervised ranking step. Our experiments in goal-oriented and knowledge-grounded dialog settings demonstrate that human annotators judge the outputs from the proposed method to be more engaging and informative compared to responses from prior dialog systems. We further show that knowledge-augmentation promotes success in achieving conversational goals in both experimental settings.