 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pose-Aware Part Decomposition for 3D Articulated Objects
Oct 08, 2021


Articulated objects exist widely in the real world. However, previous 3D generative methods for unsupervised part decomposition are unsuitable for such objects, because they assume a spatially fixed part location, resulting in inconsistent part parsing. In this paper, we propose PPD (unsupervised Pose-aware Part Decomposition) to address a novel setting that explicitly targets man-made articulated objects with mechanical joints, considering the part poses. We show that category-common prior learning for both part shapes and poses facilitates the unsupervised learning of (1) part decomposition with non-primitive-based implicit representation, and (2) part pose as joint parameters under single-frame shape supervision. We evaluate our method on synthetic and real datasets, and we show that it outperforms previous works in consistent part parsing of the articulated objects based on comparable part pose estimation performance to the supervised baseline.
Fully Spiking Variational Autoencoder
Oct 05, 2021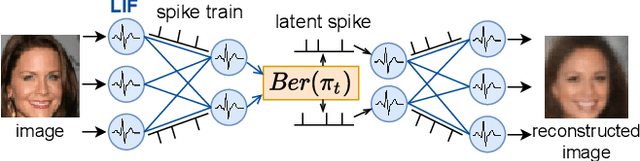
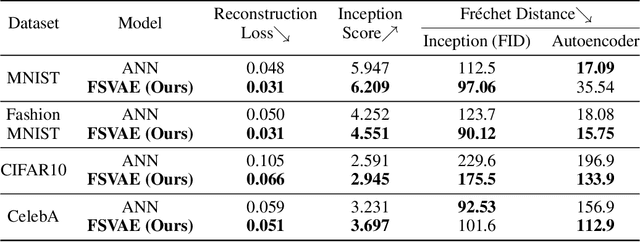
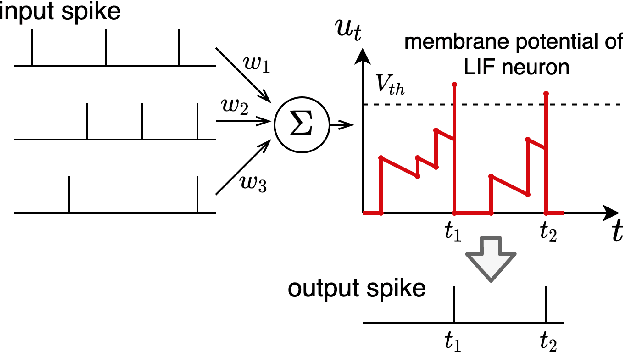

Spiking neural networks (SNNs) can be run on neuromorphic devices with ultra-high speed and ultra-low energy consumption because of their binary and event-driven nature. Therefore, SNNs are expected to have various applications, including as generative models being running on edge devices to create high-quality images. In this study, we build a variational autoencoder (VAE) with SNN to enable image generation. VAE is known for its stability among generative models; recently, its quality advanced. In vanilla VAE, the latent space is represented as a normal distribution, and floating-point calculations are required in sampling. However, this is not possible in SNNs because all features must be binary time series data. Therefore, we constructed the latent space with an autoregressive SNN model, and randomly selected samples from its output to sample the latent variables. This allows the latent variables to follow the Bernoulli process and allows variational learning. Thus, we build the Fully Spiking Variational Autoencoder where all modules are constructed with SNN. To the best of our knowledge, we are the first to build a VAE only with SNN layers. We experimented with several datasets, and confirmed that it can generate images with the same or better quality compared to conventional ANNs. The code is available at https://github.com/kamata1729/FullySpikingVAE
Video Moment Retrieval with Text Query Considering Many-to-Many Correspondence Using Potentially Relevant Pair
Jun 25, 2021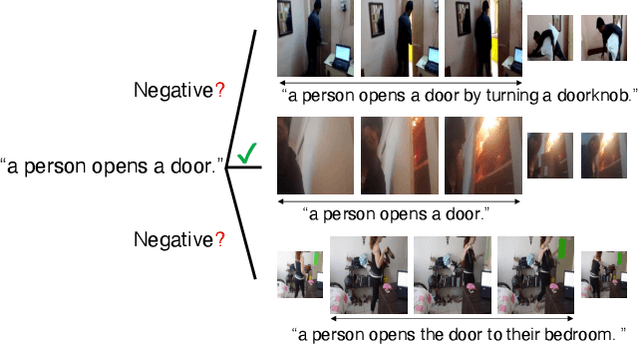
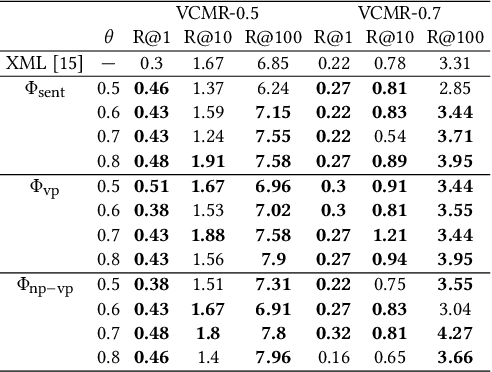
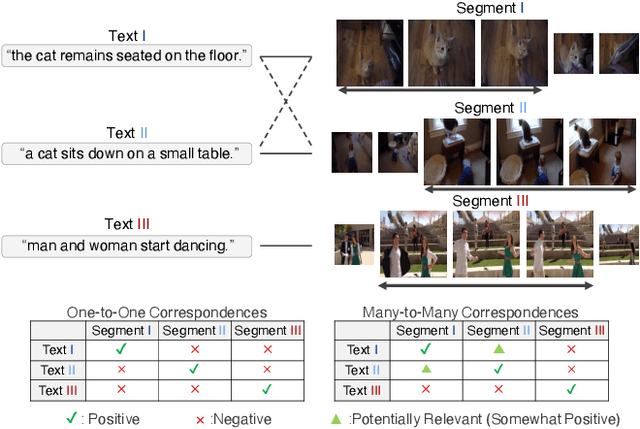
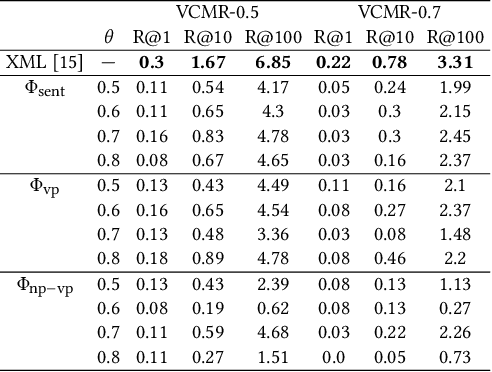
In this paper we undertake the task of text-based video moment retrieval from a corpus of videos. To train the model, text-moment paired datasets were used to learn the correct correspondences. In typical training methods, ground-truth text-moment pairs are used as positive pairs, whereas other pairs are regarded as negative pairs. However, aside from the ground-truth pairs, some text-moment pairs should be regarded as positive. In this case, one text annotation can be positive for many video moments. Conversely, one video moment can be corresponded to many text annotations. Thus, there are many-to-many correspondences between the text annotations and video moments. Based on these correspondences, we can form potentially relevant pairs, which are not given as ground truth yet are not negative; effectively incorporating such relevant pairs into training can improve the retrieval performance. The text query should describe what is happening in a video moment. Hence, different video moments annotated with similar texts, which contain a similar action, are likely to hold the similar action, thus these pairs can be considered as potentially relevant pairs. In this paper, we propose a novel training method that takes advantage of potentially relevant pairs, which are detected based on linguistic analysis about text annotation. Experiments on two benchmark datasets revealed that our method improves the retrieval performance both quantitatively and qualitatively.
Efficient training for future video generation based on hierarchical disentangled representation of latent variables
Jun 08, 2021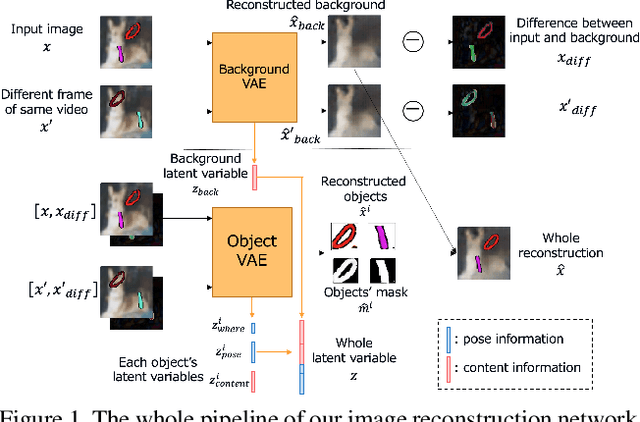
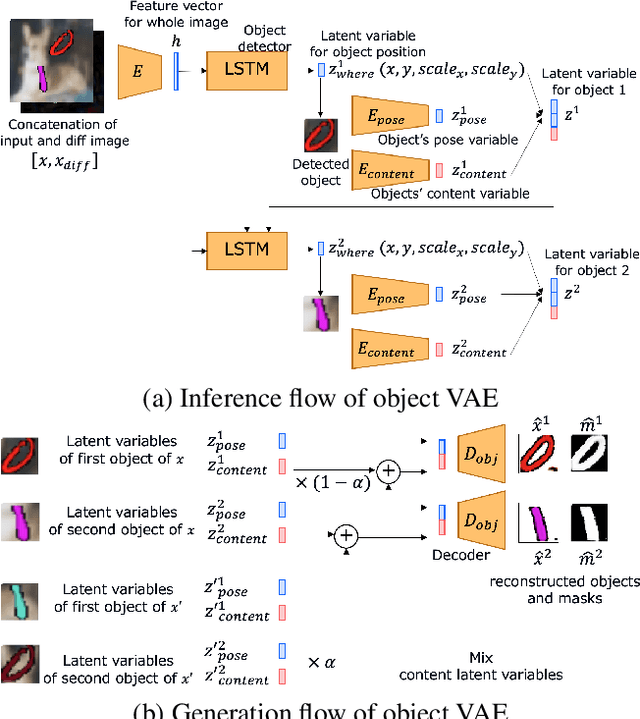


Generating videos predicting the future of a given sequence has been an area of active research in recent years. However, an essential problem remains unsolved: most of the methods require large computational cost and memory usage for training. In this paper, we propose a novel method for generating future prediction videos with less memory usage than the conventional methods. This is a critical stepping stone in the path towards generating videos with high image quality, similar to that of generated images in the latest works in the field of image generation. We achieve high-efficiency by training our method in two stages: (1) image reconstruction to encode video frames into latent variables, and (2) latent variable prediction to generate the future sequence. Our method achieves an efficient compression of video into low-dimensional latent variables by decomposing each frame according to its hierarchical structure. That is, we consider that video can be separated into background and foreground objects, and that each object holds time-varying and time-independent information independently. Our experiments show that the proposed method can efficiently generate future prediction videos, even for complex datasets that cannot be handled by previous methods.
Neural Articulated Radiance Field
Apr 07, 2021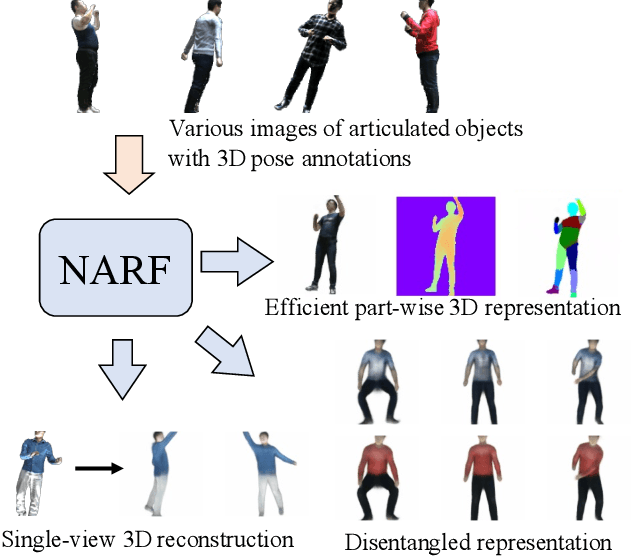
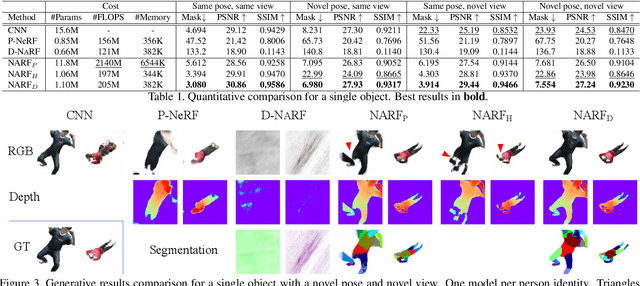
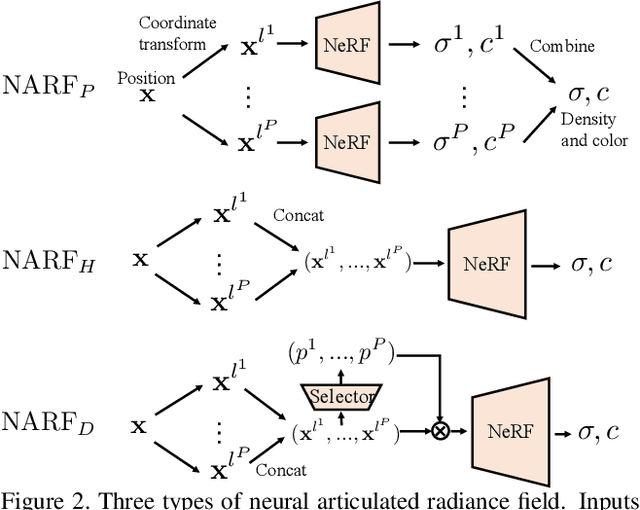
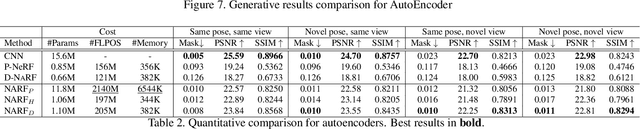
We present Neural Articulated Radiance Field (NARF), a novel deformable 3D representation for articulated objects learned from images. While recent advances in 3D implicit representation have made it possible to learn models of complex objects, learning pose-controllable representations of articulated objects remains a challenge, as current methods require 3D shape supervision and are unable to render appearance. In formulating an implicit representation of 3D articulated objects, our method considers only the rigid transformation of the most relevant object part in solving for the radiance field at each 3D location. In this way, the proposed method represents pose-dependent changes without significantly increasing the computational complexity. NARF is fully differentiable and can be trained from images with pose annotations. Moreover, through the use of an autoencoder, it can learn appearance variations over multiple instances of an object class. Experiments show that the proposed method is efficient and can generalize well to novel poses. We make the code, model and demo available for research purposes at https://github.com/nogu-atsu/NARF
Decomposing Normal and Abnormal Features of Medical Images into Discrete Latent Codes for Content-Based Image Retrieval
Mar 23, 2021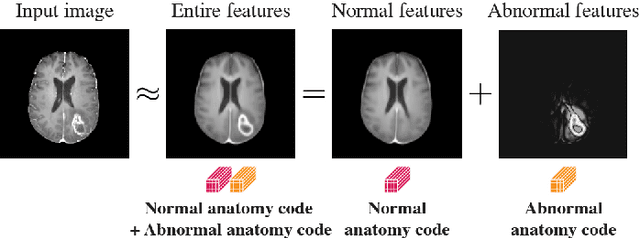
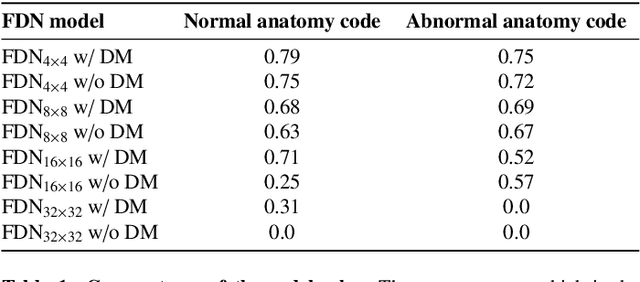
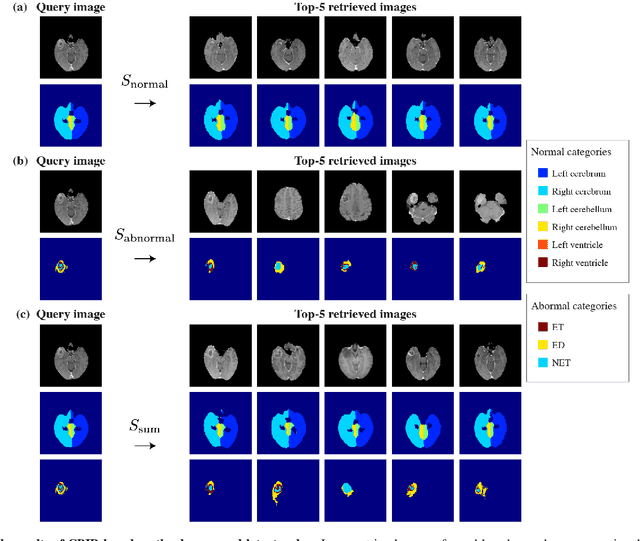
In medical imaging, the characteristics purely derived from a disease should reflect the extent to which abnormal findings deviate from the normal features. Indeed, physicians often need corresponding images without abnormal findings of interest or, conversely, images that contain similar abnormal findings regardless of normal anatomical context. This is called comparative diagnostic reading of medical images, which is essential for a correct diagnosis. To support comparative diagnostic reading, content-based image retrieval (CBIR), which can selectively utilize normal and abnormal features in medical images as two separable semantic components, will be useful. Therefore, we propose a neural network architecture to decompose the semantic components of medical images into two latent codes: normal anatomy code and abnormal anatomy code. The normal anatomy code represents normal anatomies that should have existed if the sample is healthy, whereas the abnormal anatomy code attributes to abnormal changes that reflect deviation from the normal baseline. These latent codes are discretized through vector quantization to enable binary hashing, which can reduce the computational burden at the time of similarity search. By calculating the similarity based on either normal or abnormal anatomy codes or the combination of the two codes, our algorithm can retrieve images according to the selected semantic component from a dataset consisting of brain magnetic resonance images of gliomas. Our CBIR system qualitatively and quantitatively achieves remarkable results.
Estimating and Improving Fairness with Adversarial Learning
Mar 07, 2021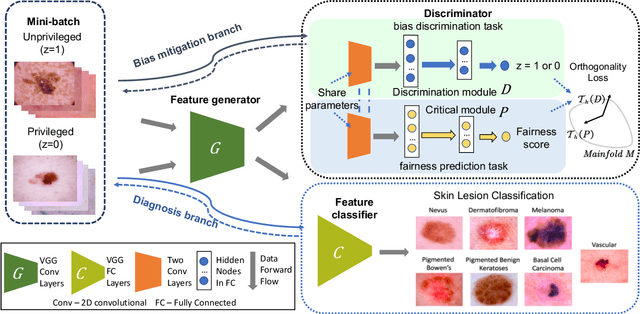
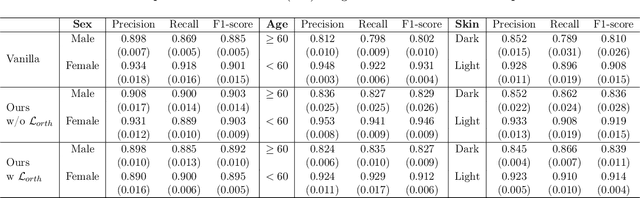
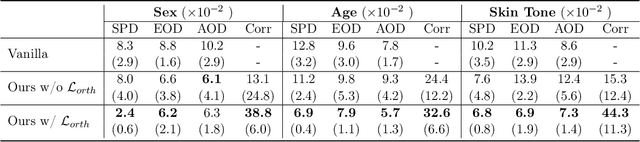
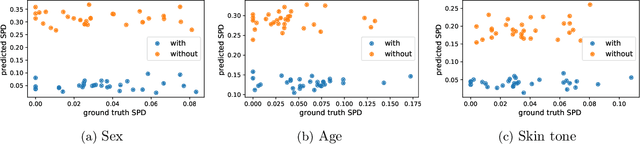
Fairness and accountability are two essential pillars for trustworthy Artificial Intelligence (AI) in healthcare. However, the existing AI model may be biased in its decision marking. To tackle this issue, we propose an adversarial multi-task training strategy to simultaneously mitigate and detect bias in the deep learning-based medical image analysis system. Specifically, we propose to add a discrimination module against bias and a critical module that predicts unfairness within the base classification model. We further impose an orthogonality regularization to force the two modules to be independent during training. Hence, we can keep these deep learning tasks distinct from one another, and avoid collapsing them into a singular point on the manifold. Through this adversarial training method, the data from the underprivileged group, which is vulnerable to bias because of attributes such as sex and skin tone, are transferred into a domain that is neutral relative to these attributes. Furthermore, the critical module can predict fairness scores for the data with unknown sensitive attributes. We evaluate our framework on a large-scale public-available skin lesion dataset under various fairness evaluation metrics. The experiments demonstrate the effectiveness of our proposed method for estimating and improving fairness in the deep learning-based medical image analysis system.
Goal-Oriented Gaze Estimation for Zero-Shot Learning
Mar 05, 2021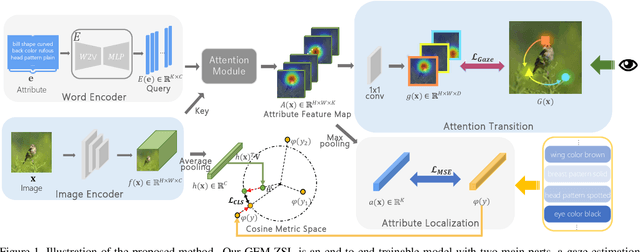
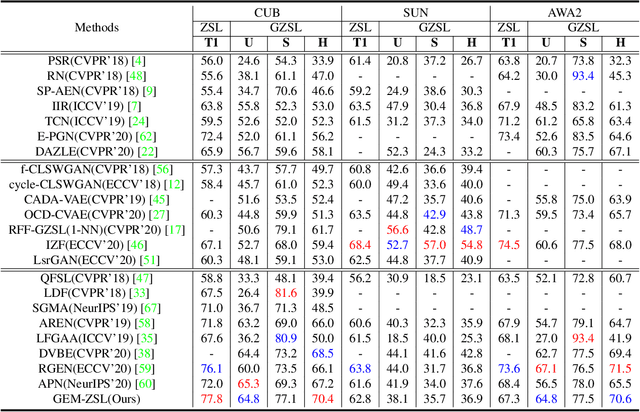
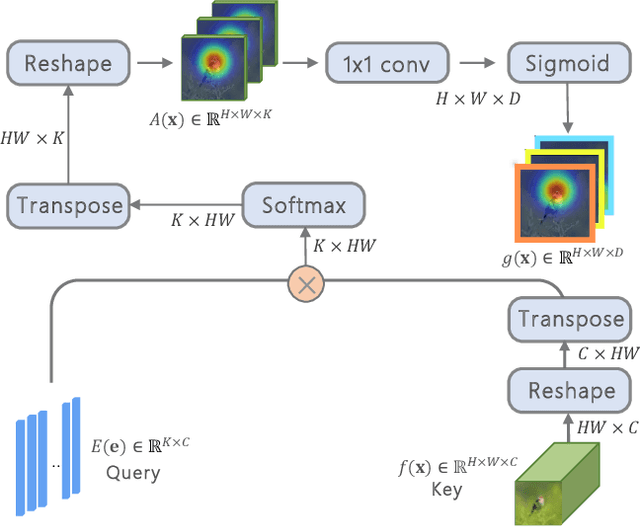
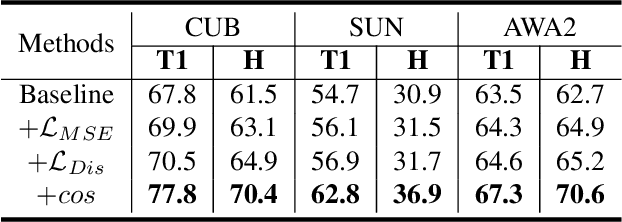
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen classes. Since semantic knowledge is built on attributes shared between different classes, which are highly local, strong prior for localization of object attribute is beneficial for visual-semantic embedding. Interestingly, when recognizing unseen images, human would also automatically gaze at regions with certain semantic clue. Therefore, we introduce a novel goal-oriented gaze estimation module (GEM) to improve the discriminative attribute localization based on the class-level attributes for ZSL. We aim to predict the actual human gaze location to get the visual attention regions for recognizing a novel object guided by attribute description. Specifically, the task-dependent attention is learned with the goal-oriented GEM, and the global image features are simultaneously optimized with the regression of local attribute features. Experiments on three ZSL benchmarks, i.e., CUB, SUN and AWA2, show the superiority or competitiveness of our proposed method against the state-of-the-art ZSL methods. The ablation analysis on real gaze data CUB-VWSW also validates the benefits and accuracy of our gaze estimation module. This work implies the promising benefits of collecting human gaze dataset and automatic gaze estimation algorithms on high-level computer vision tasks. The code is available at https://github.com/osierboy/GEM-ZSL.
Neural Star Domain as Primitive Representation
Nov 12, 2020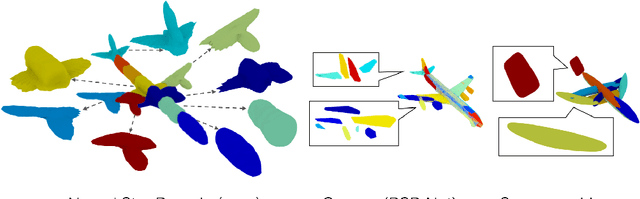

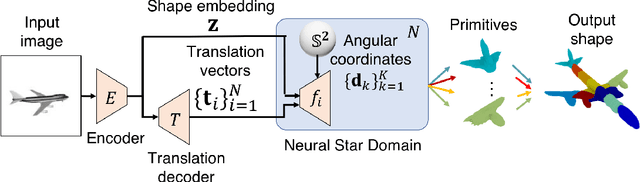
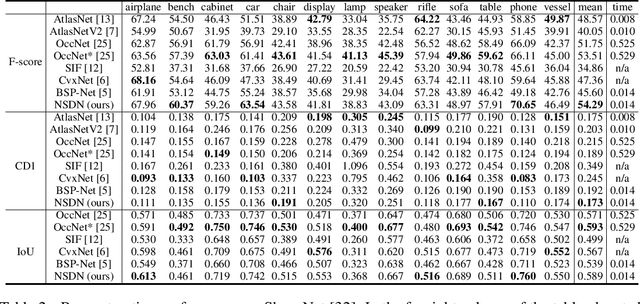
Reconstructing 3D objects from 2D images is a fundamental task in computer vision. Accurate structured reconstruction by parsimonious and semantic primitive representation further broadens its application. When reconstructing a target shape with multiple primitives, it is preferable that one can instantly access the union of basic properties of the shape such as collective volume and surface, treating the primitives as if they are one single shape. This becomes possible by primitive representation with unified implicit and explicit representations. However, primitive representations in current approaches do not satisfy all of the above requirements at the same time. To solve this problem, we propose a novel primitive representation named neural star domain (NSD) that learns primitive shapes in the star domain. We show that NSD is a universal approximator of the star domain and is not only parsimonious and semantic but also an implicit and explicit shape representation. We demonstrate that our approach outperforms existing methods in image reconstruction tasks, semantic capabilities, and speed and quality of sampling high-resolution meshes.
Decomposing Normal and Abnormal Features of Medical Images for Content-based Image Retrieval
Nov 12, 2020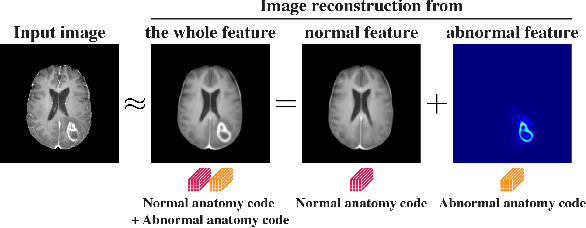
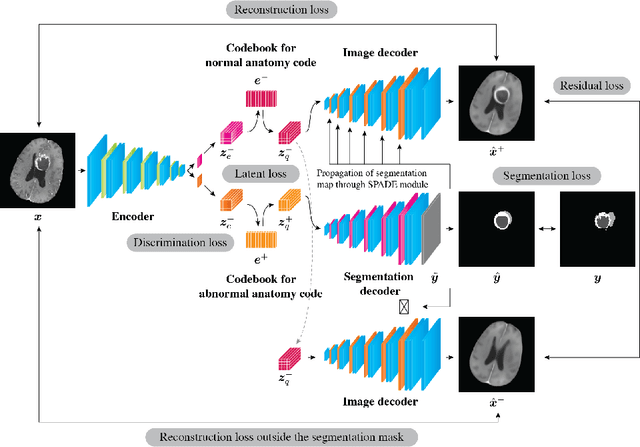
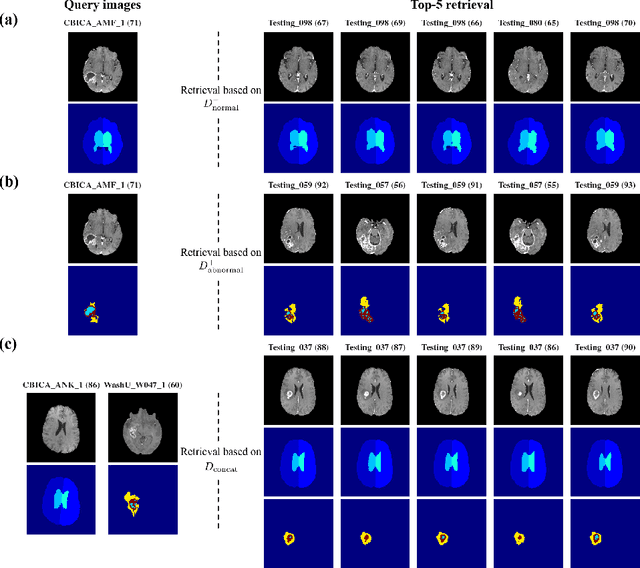
Medical images can be decomposed into normal and abnormal features, which is considered as the compositionality. Based on this idea, we propose an encoder-decoder network to decompose a medical image into two discrete latent codes: a normal anatomy code and an abnormal anatomy code. Using these latent codes, we demonstrate a similarity retrieval by focusing on either normal or abnormal features of medical images.