 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of Pretrained Transformer Language Models for Russian
Sep 19, 2023



Nowadays, Transformer language models (LMs) represent a fundamental component of the NLP research methodologies and applications. However, the development of such models specifically for the Russian language has received little attention. This paper presents a collection of 13 Russian Transformer LMs based on the encoder (ruBERT, ruRoBERTa, ruELECTRA), decoder (ruGPT-3), and encoder-decoder (ruT5, FRED-T5) models in multiple sizes. Access to these models is readily available via the HuggingFace platform. We provide a report of the model architecture design and pretraining, and the results of evaluating their generalization abilities on Russian natural language understanding and generation datasets and benchmarks. By pretraining and releasing these specialized Transformer LMs, we hope to broaden the scope of the NLP research directions and enable the development of industrial solutions for the Russian language.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Universal and Independent: Multilingual Probing Framework for Exhaustive Model Interpretation and Evaluation
Oct 24, 2022



Linguistic analysis of language models is one of the ways to explain and describe their reasoning, weaknesses, and limitations. In the probing part of the model interpretability research, studies concern individual languages as well as individual linguistic structures. The question arises: are the detected regularities linguistically coherent, or on the contrary, do they dissonate at the typological scale? Moreover, the majority of studies address the inherent set of languages and linguistic structures, leaving the actual typological diversity knowledge out of scope. In this paper, we present and apply the GUI-assisted framework allowing us to easily probe a massive number of languages for all the morphosyntactic features present in the Universal Dependencies data. We show that reflecting the anglo-centric trend in NLP over the past years, most of the regularities revealed in the mBERT model are typical for the western-European languages. Our framework can be integrated with the existing probing toolboxes, model cards, and leaderboards, allowing practitioners to use and share their standard probing methods to interpret multilingual models. Thus we propose a toolkit to systematize the multilingual flaws in multilingual models, providing a reproducible experimental setup for 104 languages and 80 morphosyntactic features. https://github.com/AIRI-Institute/Probing_framework
TAPE: Assessing Few-shot Russian Language Understanding
Oct 23, 2022Recent advances in zero-shot and few-shot learning have shown promise for a scope of research and practical purposes. However, this fast-growing area lacks standardized evaluation suites for non-English languages, hindering progress outside the Anglo-centric paradigm. To address this line of research, we propose TAPE (Text Attack and Perturbation Evaluation), a novel benchmark that includes six more complex NLU tasks for Russian, covering multi-hop reasoning, ethical concepts, logic and commonsense knowledge. The TAPE's design focuses on systematic zero-shot and few-shot NLU evaluation: (i) linguistic-oriented adversarial attacks and perturbations for analyzing robustness, and (ii) subpopulations for nuanced interpretation. The detailed analysis of testing the autoregressive baselines indicates that simple spelling-based perturbations affect the performance the most, while paraphrasing the input has a more negligible effect. At the same time, the results demonstrate a significant gap between the neural and human baselines for most tasks. We publicly release TAPE (tape-benchmark.com) to foster research on robust LMs that can generalize to new tasks when little to no supervision is available.
Vote'n'Rank: Revision of Benchmarking with Social Choice Theory
Oct 13, 2022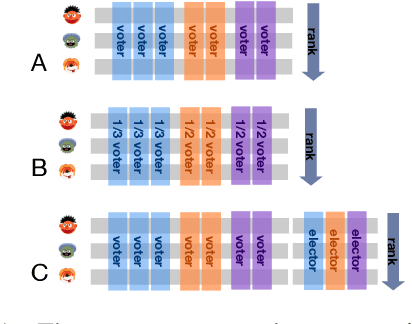
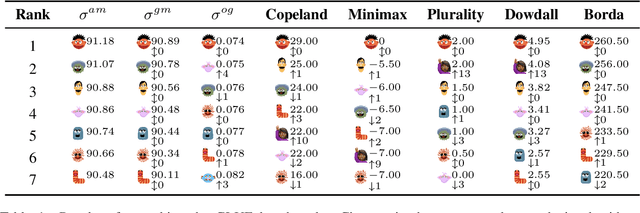
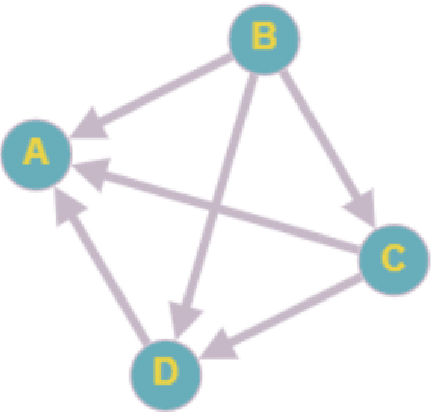
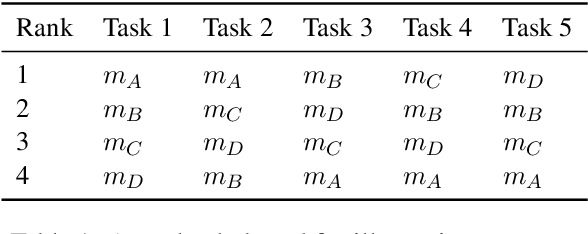
The development of state-of-the-art systems in different applied areas of machine learning (ML) is driven by benchmarks, which have shaped the paradigm of evaluating generalisation capabilities from multiple perspectives. Although the paradigm is shifting towards more fine-grained evaluation across diverse tasks, the delicate question of how to aggregate the performances has received particular interest in the community. In general, benchmarks follow the unspoken utilitarian principles, where the systems are ranked based on their mean average score over task-specific metrics. Such aggregation procedure has been viewed as a sub-optimal evaluation protocol, which may have created the illusion of progress. This paper proposes Vote'n'Rank, a framework for ranking systems in multi-task benchmarks under the principles of the social choice theory. We demonstrate that our approach can be efficiently utilised to draw new insights on benchmarking in several ML sub-fields and identify the best-performing systems in research and development case studies. The Vote'n'Rank's procedures are more robust than the mean average while being able to handle missing performance scores and determine conditions under which the system becomes the winner.
Is neural language acquisition similar to natural? A chronological probing study
Jul 01, 2022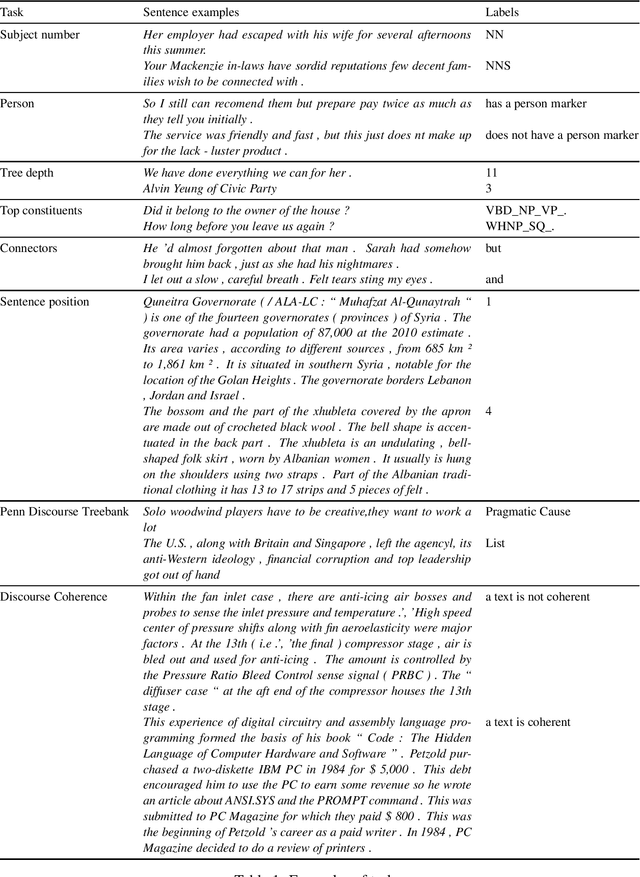
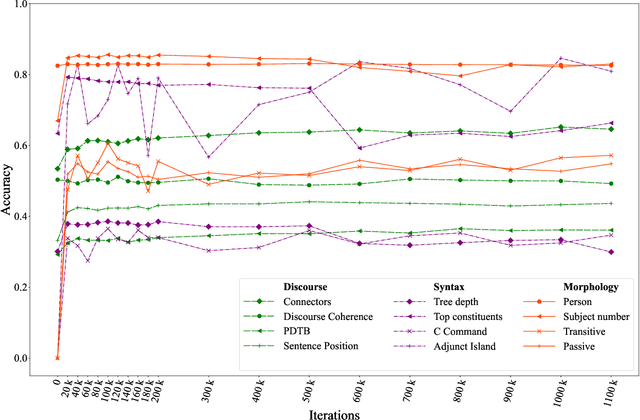

The probing methodology allows one to obtain a partial representation of linguistic phenomena stored in the inner layers of the neural network, using external classifiers and statistical analysis. Pre-trained transformer-based language models are widely used both for natural language understanding (NLU) and natural language generation (NLG) tasks making them most commonly used for downstream applications. However, little analysis was carried out, whether the models were pre-trained enough or contained knowledge correlated with linguistic theory. We are presenting the chronological probing study of transformer English models such as MultiBERT and T5. We sequentially compare the information about the language learned by the models in the process of training on corpora. The results show that 1) linguistic information is acquired in the early stages of training 2) both language models demonstrate capabilities to capture various features from various levels of language, including morphology, syntax, and even discourse, while they also can inconsistently fail on tasks that are perceived as easy. We also introduce the open-source framework for chronological probing research, compatible with other transformer-based models. https://github.com/EkaterinaVoloshina/chronological_probing
Findings of the The RuATD Shared Task 2022 on Artificial Text Detection in Russian
Jun 03, 2022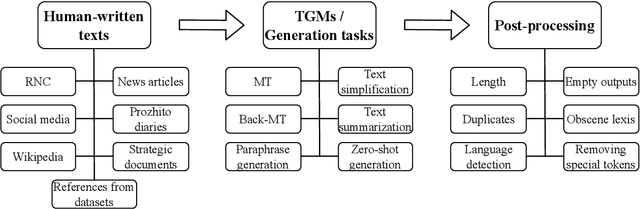
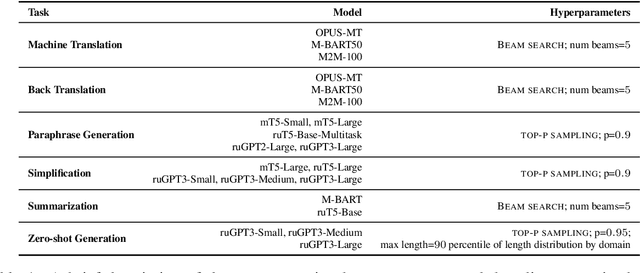
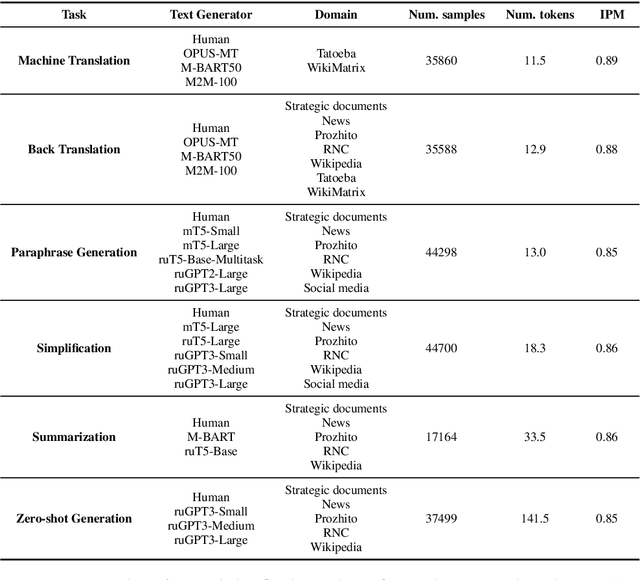
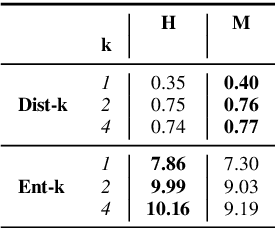
We present the shared task on artificial text detection in Russian, which is organized as a part of the Dialogue Evaluation initiative, held in 2022. The shared task dataset includes texts from 14 text generators, i.e., one human writer and 13 text generative models fine-tuned for one or more of the following generation tasks: machine translation, paraphrase generation, text summarization, text simplification. We also consider back-translation and zero-shot generation approaches. The human-written texts are collected from publicly available resources across multiple domains. The shared task consists of two sub-tasks: (i) to determine if a given text is automatically generated or written by a human; (ii) to identify the author of a given text. The first task is framed as a binary classification problem. The second task is a multi-class classification problem. We provide count-based and BERT-based baselines, along with the human evaluation on the first sub-task. A total of 30 and 8 systems have been submitted to the binary and multi-class sub-tasks, correspondingly. Most teams outperform the baselines by a wide margin. We publicly release our codebase, human evaluation results, and other materials in our GitHub repository (https://github.com/dialogue-evaluation/RuATD).
WikiOmnia: generative QA corpus on the whole Russian Wikipedia
Apr 29, 2022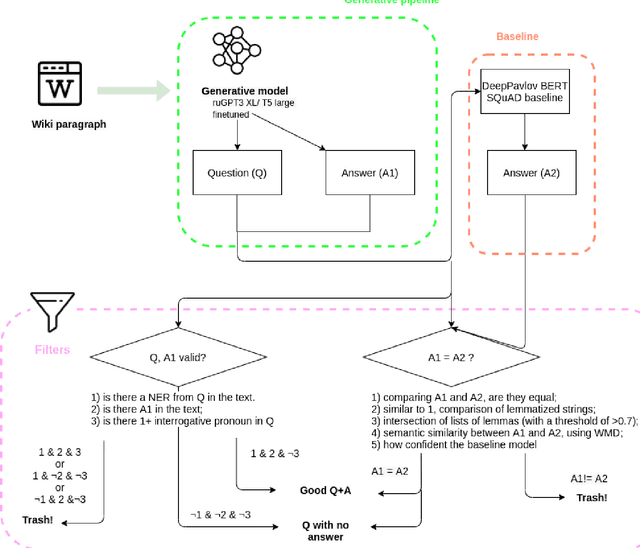
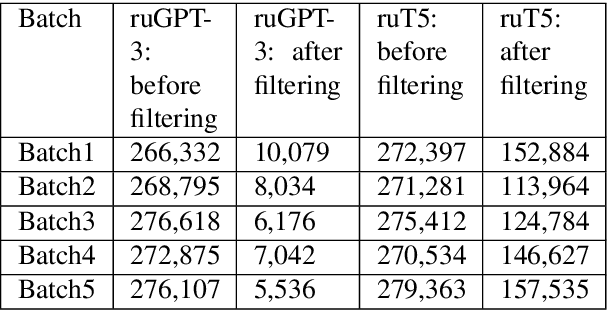
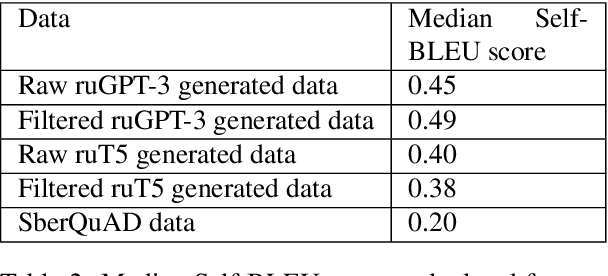
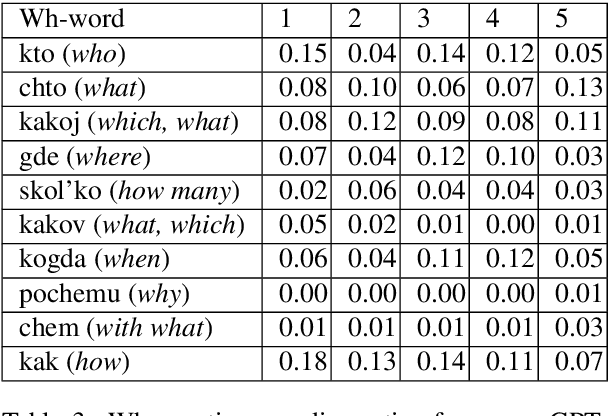
The General QA field has been developing the methodology referencing the Stanford Question answering dataset (SQuAD) as the significant benchmark. However, compiling factual questions is accompanied by time- and labour-consuming annotation, limiting the training data's potential size. We present the WikiOmnia dataset, a new publicly available set of QA-pairs and corresponding Russian Wikipedia article summary sections, composed with a fully automated generative pipeline. The dataset includes every available article from Wikipedia for the Russian language. The WikiOmnia pipeline is available open-source and is also tested for creating SQuAD-formatted QA on other domains, like news texts, fiction, and social media. The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).
mGPT: Few-Shot Learners Go Multilingual
Apr 15, 2022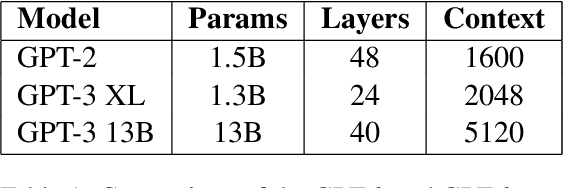
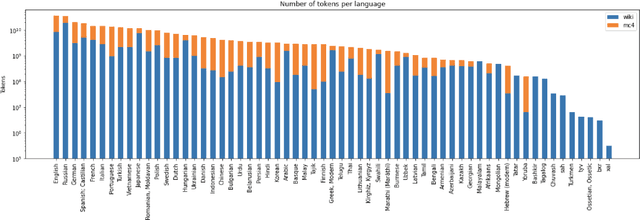
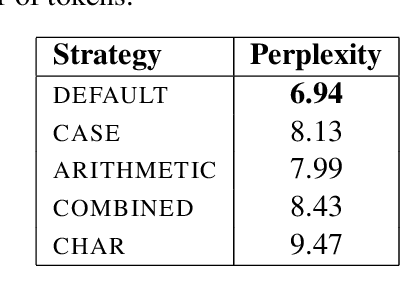
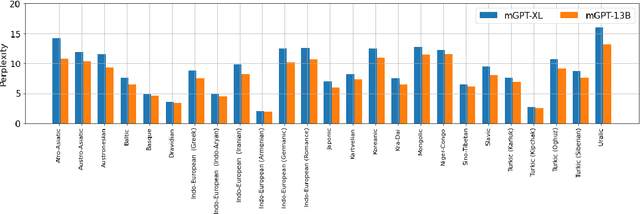
Recent studies report that autoregressive language models can successfully solve many NLP tasks via zero- and few-shot learning paradigms, which opens up new possibilities for using the pre-trained language models. This paper introduces two autoregressive GPT-like models with 1.3 billion and 13 billion parameters trained on 60 languages from 25 language families using Wikipedia and Colossal Clean Crawled Corpus. We reproduce the GPT-3 architecture using GPT-2 sources and the sparse attention mechanism; Deepspeed and Megatron frameworks allow us to parallelize the training and inference steps effectively. The resulting models show performance on par with the recently released XGLM models by Facebook, covering more languages and enhancing NLP possibilities for low resource languages of CIS countries and Russian small nations. We detail the motivation for the choices of the architecture design, thoroughly describe the data preparation pipeline, and train five small versions of the model to choose the most optimal multilingual tokenization strategy. We measure the model perplexity in all covered languages and evaluate it on the wide spectre of multilingual tasks, including classification, generative, sequence labeling and knowledge probing. The models were evaluated with the zero-shot and few-shot methods. Furthermore, we compared the classification tasks with the state-of-the-art multilingual model XGLM. source code and the mGPT XL model are publicly released.
Russian SuperGLUE 1.1: Revising the Lessons not Learned by Russian NLP models
Feb 15, 2022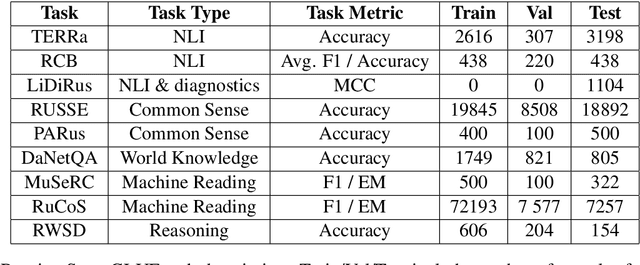
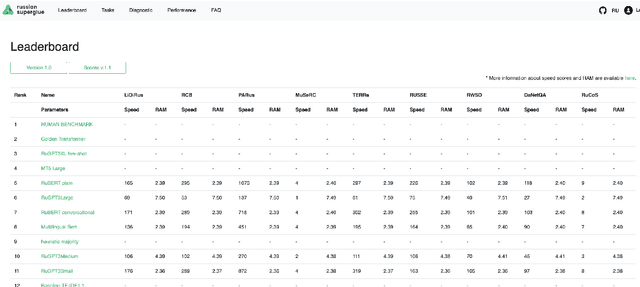
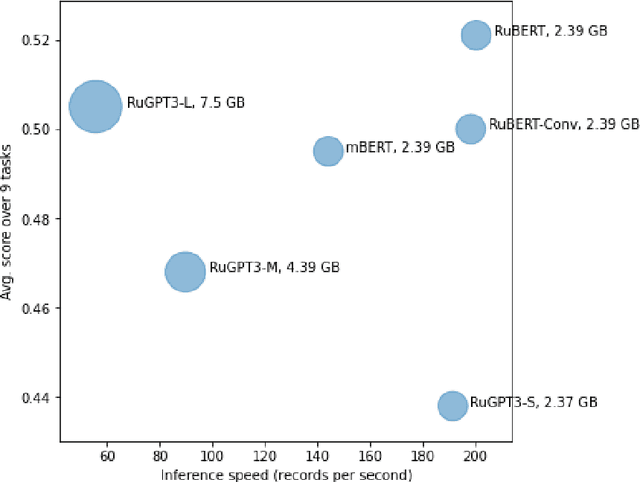
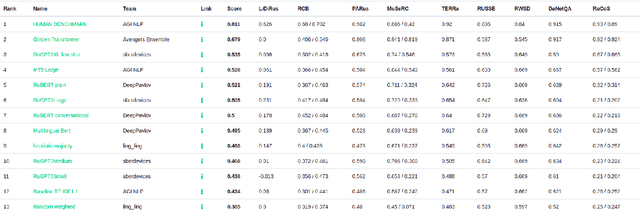
In the last year, new neural architectures and multilingual pre-trained models have been released for Russian, which led to performance evaluation problems across a range of language understanding tasks. This paper presents Russian SuperGLUE 1.1, an updated benchmark styled after GLUE for Russian NLP models. The new version includes a number of technical, user experience and methodological improvements, including fixes of the benchmark vulnerabilities unresolved in the previous version: novel and improved tests for understanding the meaning of a word in context (RUSSE) along with reading comprehension and common sense reasoning (DaNetQA, RuCoS, MuSeRC). Together with the release of the updated datasets, we improve the benchmark toolkit based on \texttt{jiant} framework for consistent training and evaluation of NLP-models of various architectures which now supports the most recent models for Russian. Finally, we provide the integration of Russian SuperGLUE with a framework for industrial evaluation of the open-source models, MOROCCO (MOdel ResOurCe COmparison), in which the models are evaluated according to the weighted average metric over all tasks, the inference speed, and the occupied amount of RAM. Russian SuperGLUE is publicly available at https://russiansuperglue.com/.