 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Input Benchmark for Russian Analysis
Aug 05, 2024



Recent advancements in Natural Language Processing (NLP) have fostered the development of Large Language Models (LLMs) that can solve an immense variety of tasks. One of the key aspects of their application is their ability to work with long text documents and to process long sequences of tokens. This has created a demand for proper evaluation of long-context understanding. To address this need for the Russian language, we propose LIBRA (Long Input Benchmark for Russian Analysis), which comprises 21 adapted datasets to study the LLM's abilities to understand long texts thoroughly. The tests are divided into four complexity groups and allow the evaluation of models across various context lengths ranging from 4k up to 128k tokens. We provide the open-source datasets, codebase, and public leaderboard for LIBRA to guide forthcoming research.
MERA: A Comprehensive LLM Evaluation in Russian
Jan 12, 2024



Over the past few years, one of the most notable advancements in AI research has been in foundation models (FMs), headlined by the rise of language models (LMs). As the models' size increases, LMs demonstrate enhancements in measurable aspects and the development of new qualitative features. However, despite researchers' attention and the rapid growth in LM application, the capabilities, limitations, and associated risks still need to be better understood. To address these issues, we introduce an open Multimodal Evaluation of Russian-language Architectures (MERA), a new instruction benchmark for evaluating foundation models oriented towards the Russian language. The benchmark encompasses 21 evaluation tasks for generative models in 11 skill domains and is designed as a black-box test to ensure the exclusion of data leakage. The paper introduces a methodology to evaluate FMs and LMs in zero- and few-shot fixed instruction settings that can be extended to other modalities. We propose an evaluation methodology, an open-source code base for the MERA assessment, and a leaderboard with a submission system. We evaluate open LMs as baselines and find that they are still far behind the human level. We publicly release MERA to guide forthcoming research, anticipate groundbreaking model features, standardize the evaluation procedure, and address potential societal drawbacks.
TAPE: Assessing Few-shot Russian Language Understanding
Oct 23, 2022Recent advances in zero-shot and few-shot learning have shown promise for a scope of research and practical purposes. However, this fast-growing area lacks standardized evaluation suites for non-English languages, hindering progress outside the Anglo-centric paradigm. To address this line of research, we propose TAPE (Text Attack and Perturbation Evaluation), a novel benchmark that includes six more complex NLU tasks for Russian, covering multi-hop reasoning, ethical concepts, logic and commonsense knowledge. The TAPE's design focuses on systematic zero-shot and few-shot NLU evaluation: (i) linguistic-oriented adversarial attacks and perturbations for analyzing robustness, and (ii) subpopulations for nuanced interpretation. The detailed analysis of testing the autoregressive baselines indicates that simple spelling-based perturbations affect the performance the most, while paraphrasing the input has a more negligible effect. At the same time, the results demonstrate a significant gap between the neural and human baselines for most tasks. We publicly release TAPE (tape-benchmark.com) to foster research on robust LMs that can generalize to new tasks when little to no supervision is available.
Russian SuperGLUE 1.1: Revising the Lessons not Learned by Russian NLP models
Feb 15, 2022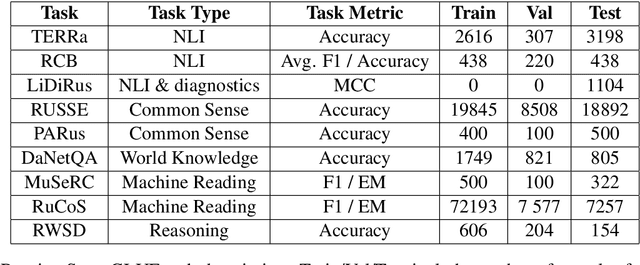
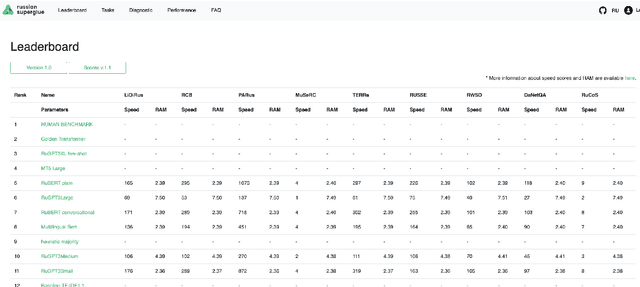
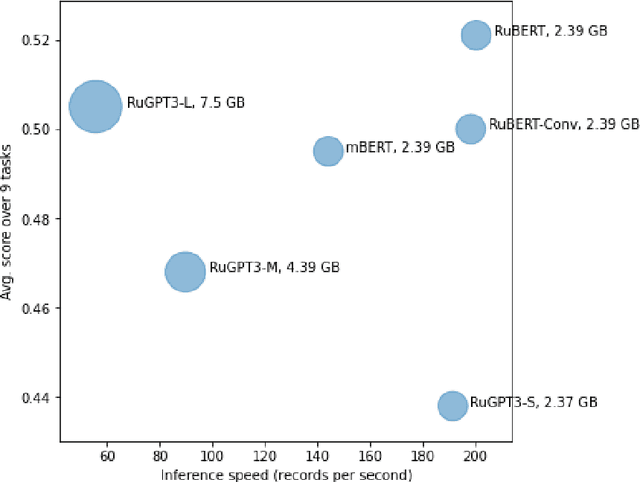
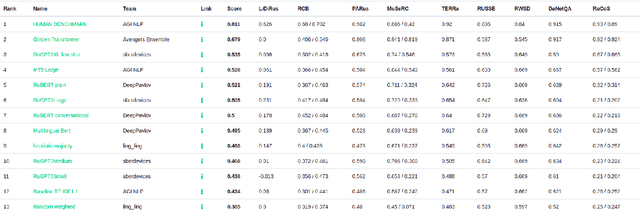
In the last year, new neural architectures and multilingual pre-trained models have been released for Russian, which led to performance evaluation problems across a range of language understanding tasks. This paper presents Russian SuperGLUE 1.1, an updated benchmark styled after GLUE for Russian NLP models. The new version includes a number of technical, user experience and methodological improvements, including fixes of the benchmark vulnerabilities unresolved in the previous version: novel and improved tests for understanding the meaning of a word in context (RUSSE) along with reading comprehension and common sense reasoning (DaNetQA, RuCoS, MuSeRC). Together with the release of the updated datasets, we improve the benchmark toolkit based on \texttt{jiant} framework for consistent training and evaluation of NLP-models of various architectures which now supports the most recent models for Russian. Finally, we provide the integration of Russian SuperGLUE with a framework for industrial evaluation of the open-source models, MOROCCO (MOdel ResOurCe COmparison), in which the models are evaluated according to the weighted average metric over all tasks, the inference speed, and the occupied amount of RAM. Russian SuperGLUE is publicly available at https://russiansuperglue.com/.
RussianSuperGLUE: A Russian Language Understanding Evaluation Benchmark
Nov 02, 2020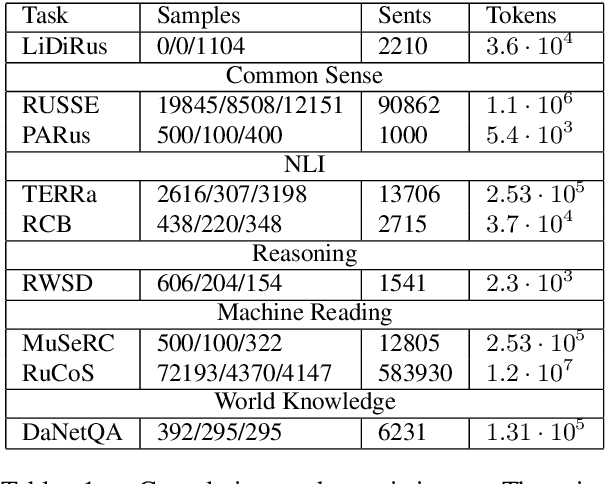

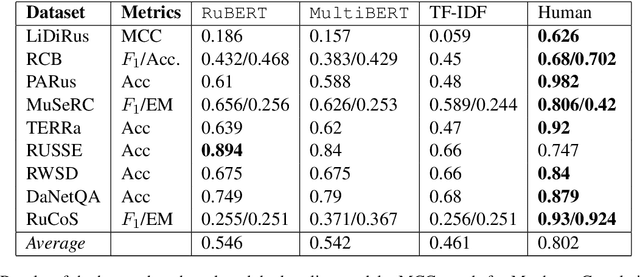

In this paper, we introduce an advanced Russian general language understanding evaluation benchmark -- RussianGLUE. Recent advances in the field of universal language models and transformers require the development of a methodology for their broad diagnostics and testing for general intellectual skills - detection of natural language inference, commonsense reasoning, ability to perform simple logical operations regardless of text subject or lexicon. For the first time, a benchmark of nine tasks, collected and organized analogically to the SuperGLUE methodology, was developed from scratch for the Russian language. We provide baselines, human level evaluation, an open-source framework for evaluating models (https://github.com/RussianNLP/RussianSuperGLUE), and an overall leaderboard of transformer models for the Russian language. Besides, we present the first results of comparing multilingual models in the adapted diagnostic test set and offer the first steps to further expanding or assessing state-of-the-art models independently of language.