 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Neural Radiance Fields
May 02, 2023The ability of neural radiance fields or NeRFs to conduct accurate 3D modelling has motivated application of the technique to scene representation. Previous approaches have mainly followed a centralised learning paradigm, which assumes that all training images are available on one compute node for training. In this paper, we consider training NeRFs in a federated manner, whereby multiple compute nodes, each having acquired a distinct set of observations of the overall scene, learn a common NeRF in parallel. This supports the scenario of cooperatively modelling a scene using multiple agents. Our contribution is the first federated learning algorithm for NeRF, which splits the training effort across multiple compute nodes and obviates the need to pool the images at a central node. A technique based on low-rank decomposition of NeRF layers is introduced to reduce bandwidth consumption to transmit the model parameters for aggregation. Transferring compressed models instead of the raw data also contributes to the privacy of the data collecting agents.
Training Multilayer Perceptrons by Sampling with Quantum Annealers
Mar 22, 2023



A successful application of quantum annealing to machine learning is training restricted Boltzmann machines (RBM). However, many neural networks for vision applications are feedforward structures, such as multilayer perceptrons (MLP). Backpropagation is currently the most effective technique to train MLPs for supervised learning. This paper aims to be forward-looking by exploring the training of MLPs using quantum annealers. We exploit an equivalence between MLPs and energy-based models (EBM), which are a variation of RBMs with a maximum conditional likelihood objective. This leads to a strategy to train MLPs with quantum annealers as a sampling engine. We prove our setup for MLPs with sigmoid activation functions and one hidden layer, and demonstrated training of binary image classifiers on small subsets of the MNIST and Fashion-MNIST datasets using the D-Wave quantum annealer. Although problem sizes that are feasible on current annealers are limited, we obtained comprehensive results on feasible instances that validate our ideas. Our work establishes the potential of quantum computing for training MLPs.
Assessing Domain Gap for Continual Domain Adaptation in Object Detection
Feb 21, 2023



To ensure reliable object detection in autonomous systems, the detector must be able to adapt to changes in appearance caused by environmental factors such as time of day, weather, and seasons. Continually adapting the detector to incorporate these changes is a promising solution, but it can be computationally costly. Our proposed approach is to selectively adapt the detector only when necessary, using new data that does not have the same distribution as the current training data. To this end, we investigate three popular metrics for domain gap evaluation and find that there is a correlation between the domain gap and detection accuracy. Therefore, we apply the domain gap as a criterion to decide when to adapt the detector. Our experiments show that our approach has the potential to improve the efficiency of the detector's operation in real-world scenarios, where environmental conditions change in a cyclical manner, without sacrificing the overall performance of the detector. Our code is publicly available at https://github.com/dadung/DGE-CDA.
ROSIA: Rotation-Search-Based Star Identification Algorithm
Oct 02, 2022
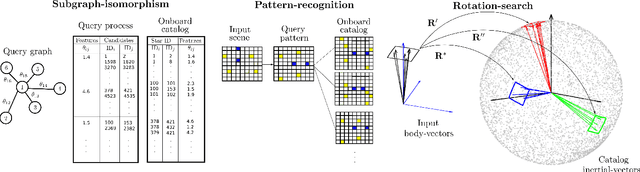
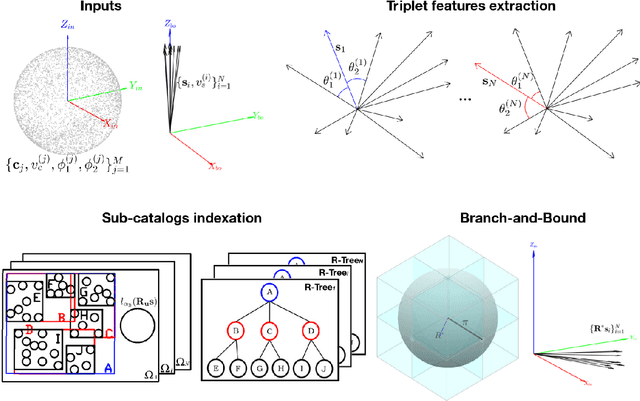
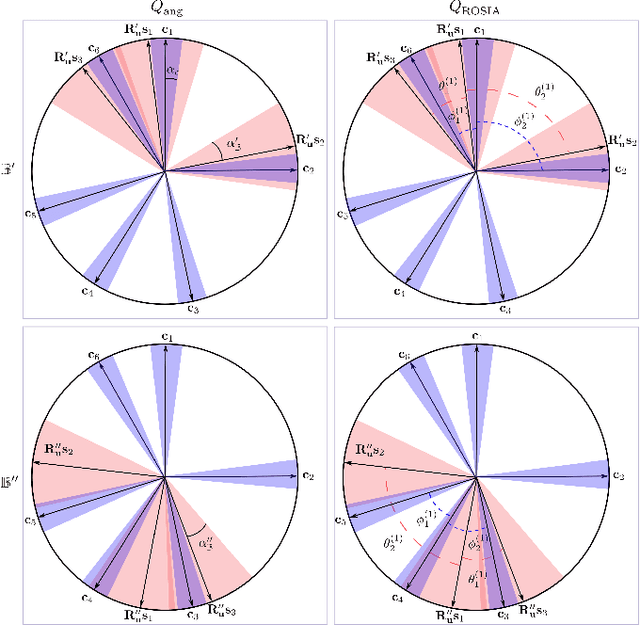
Solving the star identification (Star-ID) problem with a rotation-search-based approach eliminates the conventional heuristics in the established paradigms, i.e., the subgraph-isomorphic-based and pattern-recognition-based methods. However, it is not trivial to execute such an approach efficiently. Here, we present ROSIA, which seeks the optimal rotation alignment that maximally matches the input and catalog stars in their respective coordinates. ROSIA searches the rotation space systematically with the Branch-and-Bound (BnB) method. Crucially affecting the runtime feasibility of ROSIA is the upper bound function that prioritizes the search space. In this paper, we make a theoretical contribution by proposing a tight (provable) upper bound function that allows a 400x speed up compared to an existing formulation. Coupling the bounding function with an efficient evaluation scheme that leverages stereographic projection and the R-tree data structure, ROSIA achieves real-time operational speed with state-of-the-art performances under different sources of noise.
Globally Optimal Event-Based Divergence Estimation for Ventral Landing
Sep 27, 2022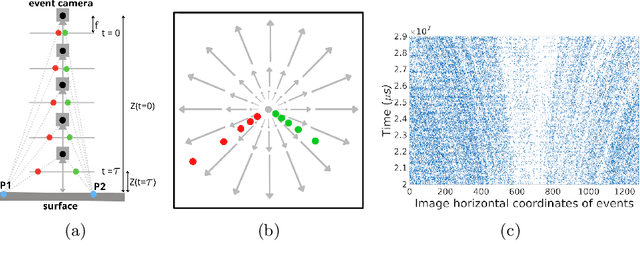

Event sensing is a major component in bio-inspired flight guidance and control systems. We explore the usage of event cameras for predicting time-to-contact (TTC) with the surface during ventral landing. This is achieved by estimating divergence (inverse TTC), which is the rate of radial optic flow, from the event stream generated during landing. Our core contributions are a novel contrast maximisation formulation for event-based divergence estimation, and a branch-and-bound algorithm to exactly maximise contrast and find the optimal divergence value. GPU acceleration is conducted to speed up the global algorithm. Another contribution is a new dataset containing real event streams from ventral landing that was employed to test and benchmark our method. Owing to global optimisation, our algorithm is much more capable at recovering the true divergence, compared to other heuristic divergence estimators or event-based optic flow methods. With GPU acceleration, our method also achieves competitive runtimes.
Towards Bridging the Space Domain Gap for Satellite Pose Estimation using Event Sensing
Sep 24, 2022
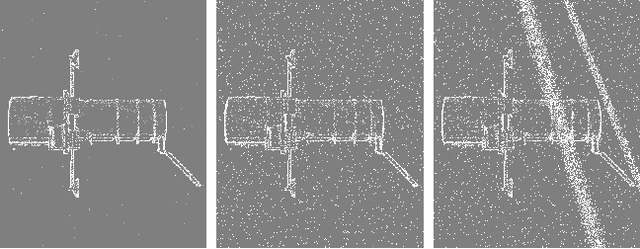
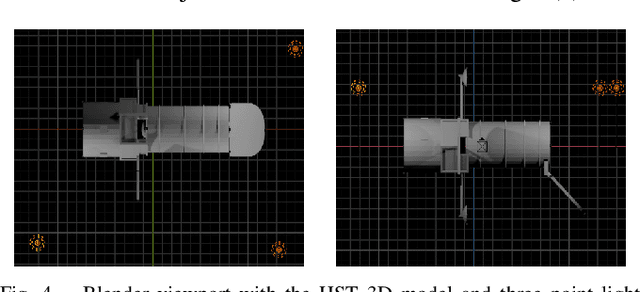
Deep models trained using synthetic data require domain adaptation to bridge the gap between the simulation and target environments. State-of-the-art domain adaptation methods often demand sufficient amounts of (unlabelled) data from the target domain. However, this need is difficult to fulfil when the target domain is an extreme environment, such as space. In this paper, our target problem is close proximity satellite pose estimation, where it is costly to obtain images of satellites from actual rendezvous missions. We demonstrate that event sensing offers a promising solution to generalise from the simulation to the target domain under stark illumination differences. Our main contribution is an event-based satellite pose estimation technique, trained purely on synthetic event data with basic data augmentation to improve robustness against practical (noisy) event sensors. Underpinning our method is a novel dataset with carefully calibrated ground truth, comprising of real event data obtained by emulating satellite rendezvous scenarios in the lab under drastic lighting conditions. Results on the dataset showed that our event-based satellite pose estimation method, trained only on synthetic data without adaptation, could generalise to the target domain effectively.
Update Compression for Deep Neural Networks on the Edge
Mar 09, 2022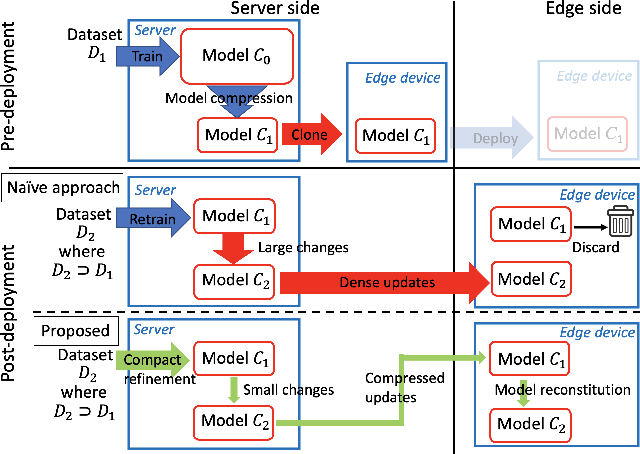
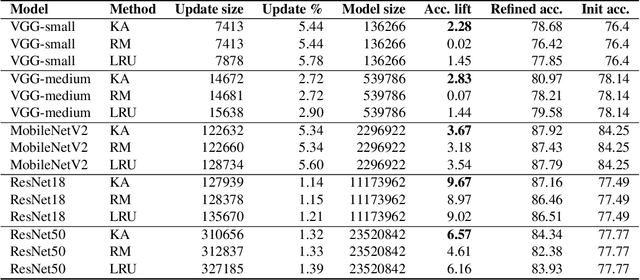
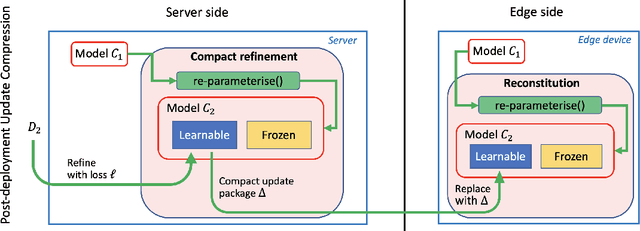
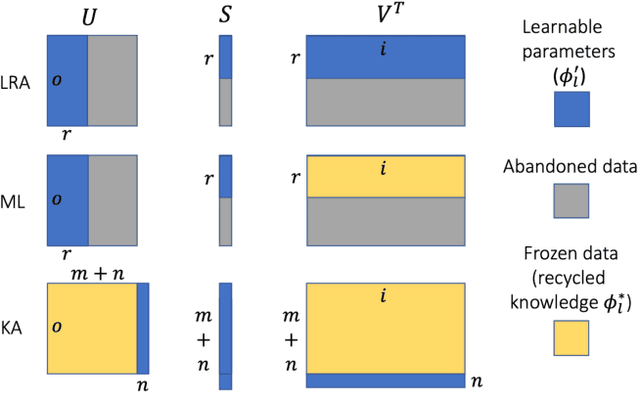
An increasing number of artificial intelligence (AI) applications involve the execution of deep neural networks (DNNs) on edge devices. Many practical reasons motivate the need to update the DNN model on the edge device post-deployment, such as refining the model, concept drift, or outright change in the learning task. In this paper, we consider the scenario where retraining can be done on the server side based on a copy of the DNN model, with only the necessary data transmitted to the edge to update the deployed model. However, due to bandwidth constraints, we want to minimise the transmission required to achieve the update. We develop a simple approach based on matrix factorisation to compress the model update -- this differs from compressing the model itself. The key idea is to preserve existing knowledge in the current model and optimise only small additional parameters for the update which can be used to reconstitute the model on the edge. We compared our method to similar techniques used in federated learning; our method usually requires less than half of the update size of existing methods to achieve the same accuracy.
Asynchronous Optimisation for Event-based Visual Odometry
Mar 02, 2022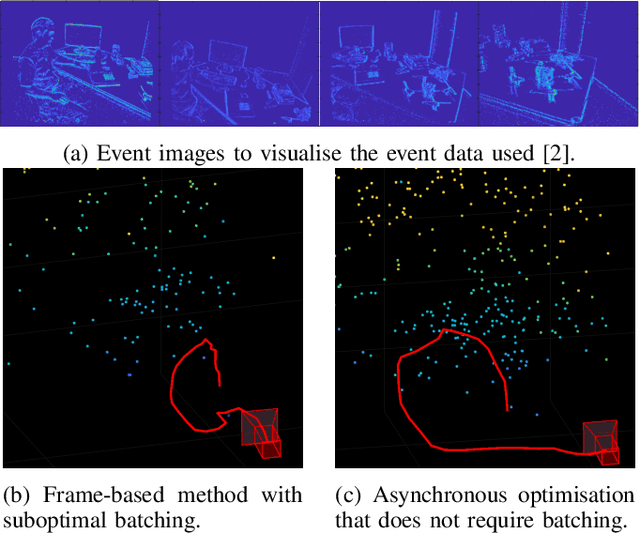

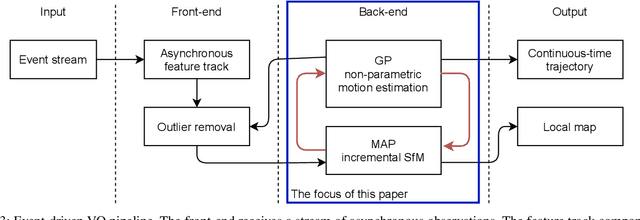
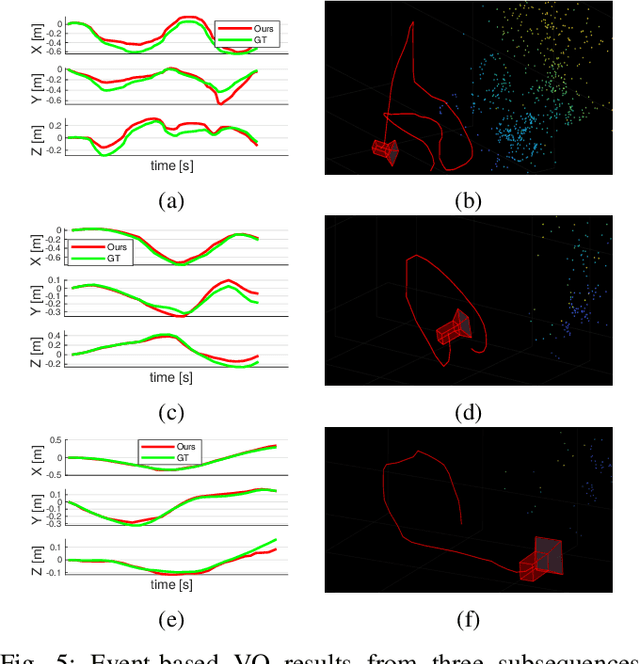
Event cameras open up new possibilities for robotic perception due to their low latency and high dynamic range. On the other hand, developing effective event-based vision algorithms that fully exploit the beneficial properties of event cameras remains work in progress. In this paper, we focus on event-based visual odometry (VO). While existing event-driven VO pipelines have adopted continuous-time representations to asynchronously process event data, they either assume a known map, restrict the camera to planar trajectories, or integrate other sensors into the system. Towards map-free event-only monocular VO in SE(3), we propose an asynchronous structure-from-motion optimisation back-end. Our formulation is underpinned by a principled joint optimisation problem involving non-parametric Gaussian Process motion modelling and incremental maximum a posteriori inference. A high-performance incremental computation engine is employed to reason about the camera trajectory with every incoming event. We demonstrate the robustness of our asynchronous back-end in comparison to frame-based methods which depend on accurate temporal accumulation of measurements.
A Hybrid Quantum-Classical Algorithm for Robust Fitting
Jan 31, 2022



Fitting geometric models onto outlier contaminated data is provably intractable. Many computer vision systems rely on random sampling heuristics to solve robust fitting, which do not provide optimality guarantees and error bounds. It is therefore critical to develop novel approaches that can bridge the gap between exact solutions that are costly, and fast heuristics that offer no quality assurances. In this paper, we propose a hybrid quantum-classical algorithm for robust fitting. Our core contribution is a novel robust fitting formulation that solves a sequence of integer programs and terminates with a global solution or an error bound. The combinatorial subproblems are amenable to a quantum annealer, which helps to tighten the bound efficiently. While our usage of quantum computing does not surmount the fundamental intractability of robust fitting, by providing error bounds our algorithm is a practical improvement over randomised heuristics. Moreover, our work represents a concrete application of quantum computing in computer vision. We present results obtained using an actual quantum computer (D-Wave Advantage) and via simulation. Source code: https://github.com/dadung/HQC-robust-fitting
Maximum Consensus by Weighted Influences of Monotone Boolean Functions
Dec 10, 2021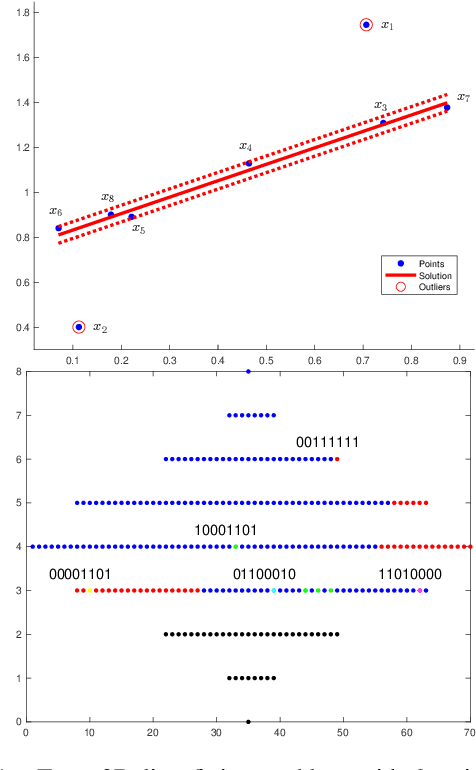
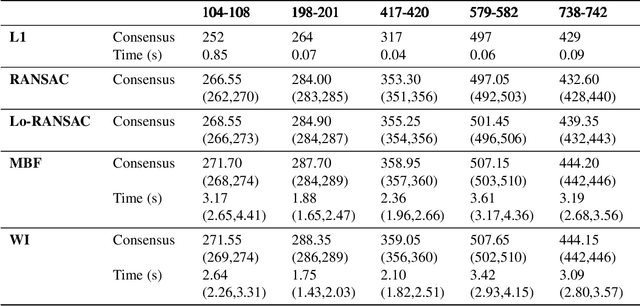
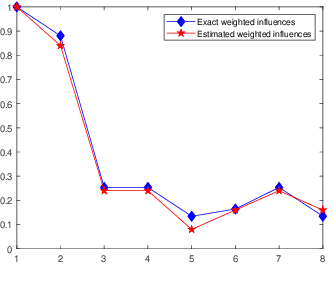
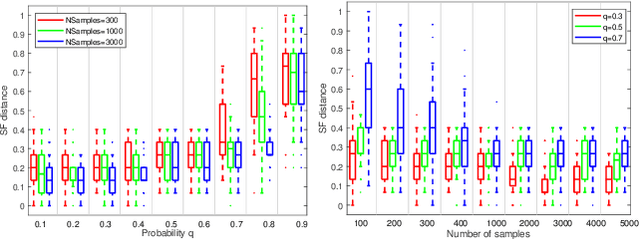
Robust model fitting is a fundamental problem in computer vision: used to pre-process raw data in the presence of outliers. Maximisation of Consensus (MaxCon) is one of the most popular robust criteria and widely used. Recently (Tennakoon et al. CVPR2021), a connection has been made between MaxCon and estimation of influences of a Monotone Boolean function. Equipping the Boolean cube with different measures and adopting different sampling strategies (two sides of the same coin) can have differing effects: which leads to the current study. This paper studies the concept of weighted influences for solving MaxCon. In particular, we study endowing the Boolean cube with the Bernoulli measure and performing biased (as opposed to uniform) sampling. Theoretically, we prove the weighted influences, under this measure, of points belonging to larger structures are smaller than those of points belonging to smaller structures in general. We also consider another "natural" family of sampling/weighting strategies, sampling with uniform measure concentrated on a particular (Hamming) level of the cube. Based on weighted sampling, we modify the algorithm of Tennakoon et al., and test on both synthetic and real datasets. This paper is not promoting a new approach per se, but rather studying the issue of weighted sampling. Accordingly, we are not claiming to have produced a superior algorithm: rather we show some modest gains of Bernoulli sampling, and we illuminate some of the interactions between structure in data and weighted sampling.