 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective, Controlled and Domain-Agnostic Unlearning in Pretrained CLIP: A Training- and Data-Free Approach
Dec 16, 2025



Pretrained models like CLIP have demonstrated impressive zero-shot classification capabilities across diverse visual domains, spanning natural images, artistic renderings, and abstract representations. However, real-world applications often demand the removal (or "unlearning") of specific object classes without requiring additional data or retraining, or affecting the model's performance on unrelated tasks. In this paper, we propose a novel training- and data-free unlearning framework that enables three distinct forgetting paradigms: (1) global unlearning of selected objects across all domains, (2) domain-specific knowledge removal (e.g., eliminating sketch representations while preserving photo recognition), and (3) complete unlearning in selective domains. By leveraging a multimodal nullspace through synergistic integration of text prompts and synthesized visual prototypes derived from CLIP's joint embedding space, our method efficiently removes undesired class information while preserving the remaining knowledge. This approach overcomes the limitations of existing retraining-based methods and offers a flexible and computationally efficient solution for controlled model forgetting.
Erasing CLIP Memories: Non-Destructive, Data-Free Zero-Shot class Unlearning in CLIP Models
Dec 16, 2025We introduce a novel, closed-form approach for selective unlearning in multimodal models, specifically targeting pretrained models such as CLIP. Our method leverages nullspace projection to erase the target class information embedded in the final projection layer, without requiring any retraining or the use of images from the forget set. By computing an orthonormal basis for the subspace spanned by target text embeddings and projecting these directions, we dramatically reduce the alignment between image features and undesired classes. Unlike traditional unlearning techniques that rely on iterative fine-tuning and extensive data curation, our approach is both computationally efficient and surgically precise. This leads to a pronounced drop in zero-shot performance for the target classes while preserving the overall multimodal knowledge of the model. Our experiments demonstrate that even a partial projection can balance between complete unlearning and retaining useful information, addressing key challenges in model decontamination and privacy preservation.
Data Efficient Evaluation of Large Language Models and Text-to-Image Models via Adaptive Sampling
Jun 21, 2024Evaluating LLMs and text-to-image models is a computationally intensive task often overlooked. Efficient evaluation is crucial for understanding the diverse capabilities of these models and enabling comparisons across a growing number of new models and benchmarks. To address this, we introduce SubLIME, a data-efficient evaluation framework that employs adaptive sampling techniques, such as clustering and quality-based methods, to create representative subsets of benchmarks. Our approach ensures statistically aligned model rankings compared to full datasets, evidenced by high Pearson correlation coefficients. Empirical analysis across six NLP benchmarks reveals that: (1) quality-based sampling consistently achieves strong correlations (0.85 to 0.95) with full datasets at a 10\% sampling rate such as Quality SE and Quality CPD (2) clustering methods excel in specific benchmarks such as MMLU (3) no single method universally outperforms others across all metrics. Extending this framework, we leverage the HEIM leaderboard to cover 25 text-to-image models on 17 different benchmarks. SubLIME dynamically selects the optimal technique for each benchmark, significantly reducing evaluation costs while preserving ranking integrity and score distribution. Notably, a minimal sampling rate of 1% proves effective for benchmarks like MMLU. Additionally, we demonstrate that employing difficulty-based sampling to target more challenging benchmark segments enhances model differentiation with broader score distributions. We also combine semantic search, tool use, and GPT-4 review to identify redundancy across benchmarks within specific LLM categories, such as coding benchmarks. This allows us to further reduce the number of samples needed to maintain targeted rank preservation. Overall, SubLIME offers a versatile and cost-effective solution for the robust evaluation of LLMs and text-to-image models.
Introducing Astrocytes on a Neuromorphic Processor: Synchronization, Local Plasticity and Edge of Chaos
Jul 02, 2019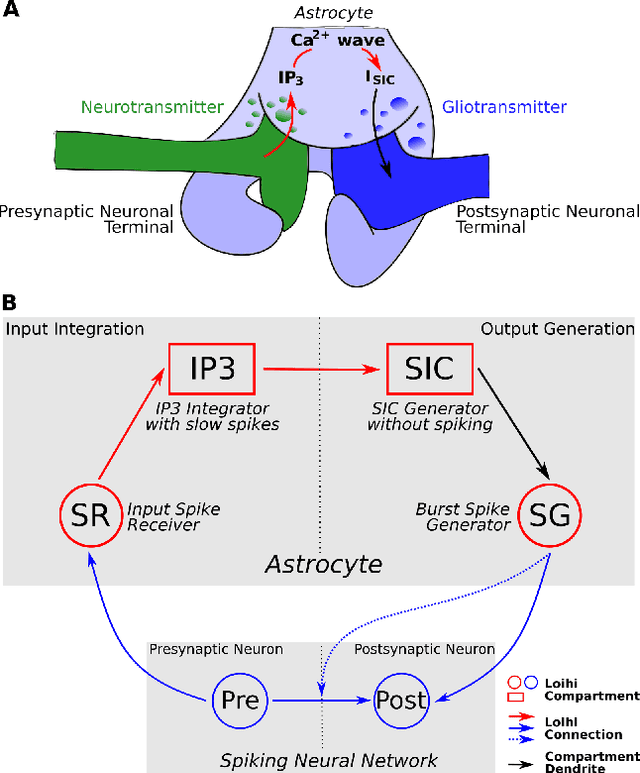
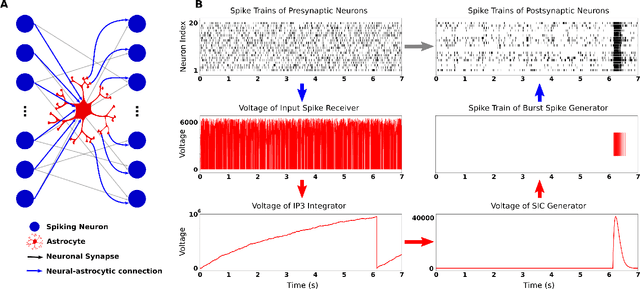
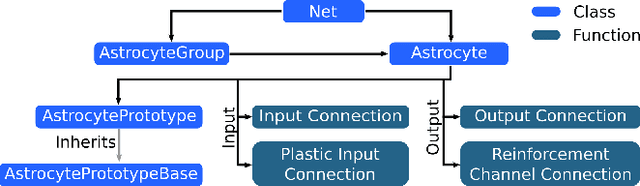

While there is still a lot to learn about astrocytes and their neuromodulatory role associated with their spatial and temporal integration of synaptic activity, the introduction of an additional to neurons processing unit into neuromorphic hardware is timely, facilitating their computational exploration in basic science questions and their exploitation in real-world applications. Here, we present an astrocytic module that enables the development of a spiking Neuronal-Astrocytic Network (SNAN) into Intel's Loihi neuromorphic chip. The basis of our module is an end-to-end biophysically plausible compartmental model of an astrocyte that simulates how intracellular activity may encode synaptic activity in space and time. To demonstrate the functional role of astrocytes in SNANs, we describe how an astrocyte may sense and induce activity-dependent neuronal synchronization, can endow single-shot learning capabilities in spike-time-dependent plasticity (STDP), and sense the transition between ordered and chaotic activity in the neuronal component of an SNAN. Our astrocytic module may serve as a natural extension for neuromorphic hardware by mimicking the distinct computational roles of its biological counterpart.
Spiking Neural Network on Neuromorphic Hardware for Energy-Efficient Unidimensional SLAM
Mar 06, 2019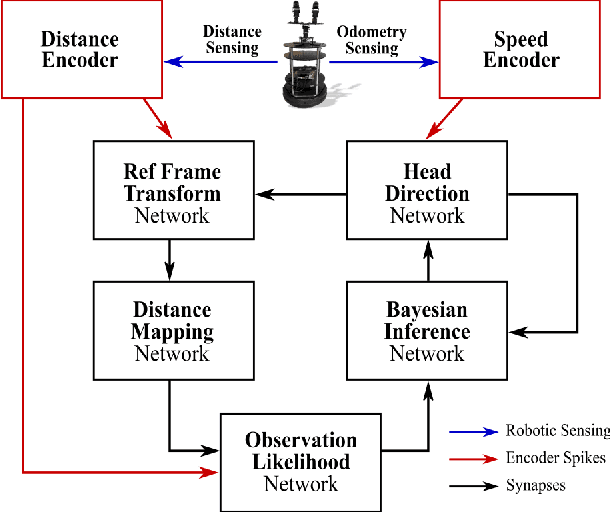
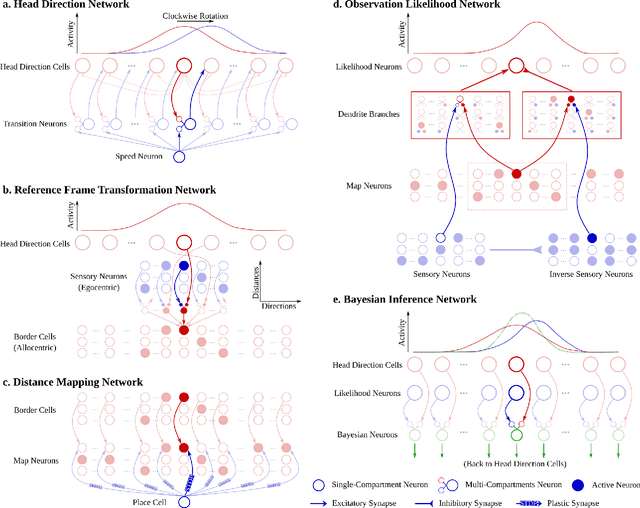

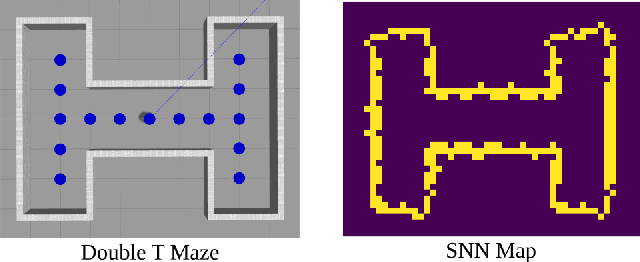
Energy-efficient simultaneous localization and mapping (SLAM) is crucial for mobile robots exploring unknown environments. The mammalian brain solves SLAM via a network of specialized neurons, exhibiting asynchronous computations and event-based communications, with very low energy consumption. We propose a brain-inspired spiking neural network (SNN) architecture that solves the unidimensional SLAM by introducing spike-based reference frame transformation, visual likelihood computation, and Bayesian inference. Our proposed SNN is seamlessly integrated into Intel's Loihi neuromorphic processor, a non-Von Neumann hardware that mimics the brain's computing paradigms. We performed comparative analyses for accuracy and energy-efficiency between our method and the GMapping algorithm, which is widely used in small environments. Our Loihi-based SNN architecture consumes 100 times less energy than GMapping run on a CPU while having comparable accuracy in head direction localization and map-generation. These results pave the way for extending our approach towards an energy-efficient SLAM that is applicable to Loihi-controlled mobile robots.