 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEAT: A Linear-Complexity Foundation Model for Extremely Large Structured Data
Mar 17, 2026Structured data is foundational to healthcare, finance, e-commerce, and scientific data management. Large structured-data models (LDMs) extend the foundation model paradigm to unify heterogeneous datasets for tasks such as classification, regression, and decision support. However, existing LDMs face major limitations. First, most rely on sample-wise self-attention, whose O(N^2) complexity limits the sample count. Second, linear sequence models often degrade representations due to hidden-state compression and artificial causal bias. Third, synthetic-only pre-training often fails to match real-world distributions. We propose FEAT, a linear-complexity foundation model for extremely large structured data. FEAT introduces a multi-layer dual-axis architecture that replaces quadratic attention with hybrid linear encoding. The architecture combines adaptive-fusion bi-Mamba-2 (AFBM) for local sample dependencies and convolutional gated linear attention (Conv-GLA) for global memory. This design enables linear-complexity cross-sample modeling while preserving expressive representations. To improve robustness, FEAT adopts a hybrid structural causal model pipeline and a stable reconstruction objective. Experiments on 11 real-world datasets show that FEAT consistently outperforms baselines in zero-shot performance, while scaling linearly and achieving up to 40x faster inference.
Spatio-Temporal Latent Graph Structure Learning for Traffic Forecasting
Feb 25, 2022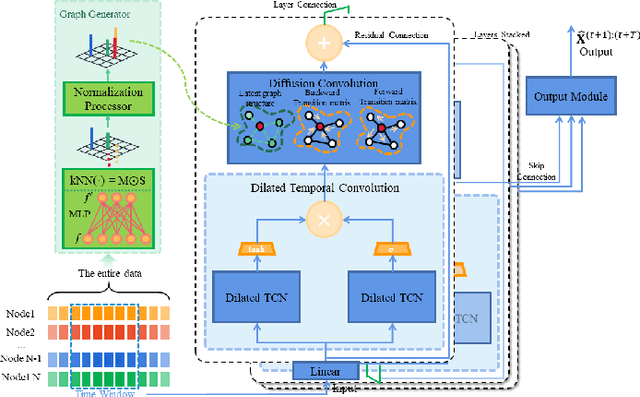
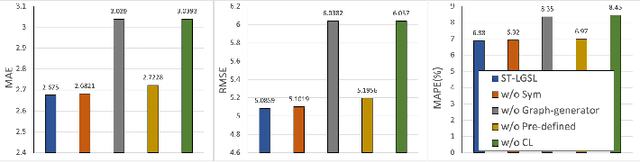
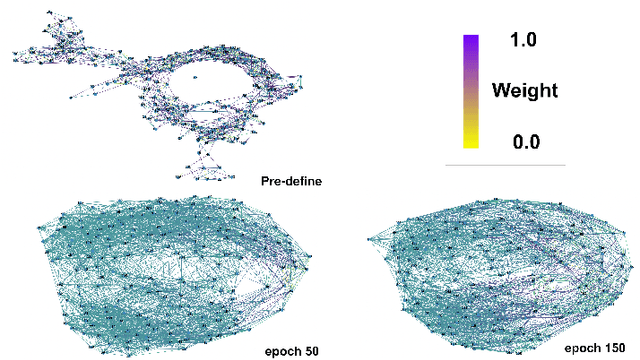

Accurate traffic forecasting, the foundation of intelligent transportation systems (ITS), has never been more significant than nowadays due to the prosperity of the smart cities and urban computing. Recently, Graph Neural Network truly outperforms the traditional methods. Nevertheless, the most conventional GNN based model works well while given a pre-defined graph structure. And the existing methods of defining the graph structures focus purely on spatial dependencies and ignored the temporal correlation. Besides, the semantics of the static pre-defined graph adjacency applied during the whole training progress is always incomplete, thus overlooking the latent topologies that may fine-tune the model. To tackle these challenges, we proposed a new traffic forecasting framework--Spatio-Temporal Latent Graph Structure Learning networks (ST-LGSL). More specifically, the model employed a graph generator based on Multilayer perceptron and K-Nearest Neighbor, which learns the latent graph topological information from the entire data considering both spatial and temporal dynamics. Furthermore, with the initialization of MLP-kNN based on ground-truth adjacency matrix and similarity metric in kNN, ST-LGSL aggregates the topologies focusing on geography and node similarity. Additionally, the generated graphs act as the input of spatio-temporal prediction module combined with the Diffusion Graph Convolutions and Gated Temporal Convolutions Networks. Experimental results on two benchmarking datasets in real world demonstrate that ST-LGSL outperforms various types of state-of-art baselines.