 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeferMem: Query-Time Evidence Distillation via Reinforcement Learning for Long-Term Memory QA
May 21, 2026Large language model (LLM) agents still struggle with long-term memory question answering, where answer-supporting evidence is often scattered across long conversational histories and buried in substantial irrelevant content. Existing memory systems typically process memory before future queries are known, then retrieve the resulting units based on similarity rather than their utility for answering the query. This workflow leaves downstream answerers to denoise retrieved candidates and reconstruct query-specific evidence. We present DeferMem, a long-term memory framework that decouples this problem into high-recall candidate retrieval and query-conditioned evidence distillation. DeferMem uses a lightweight segment-link structure to organize raw history and retrieve broad candidates at query time. It then applies a memory distiller trained with DistillPO, our reinforcement learning algorithm for distilling the high-recall but highly noisy candidates into a set of faithful, self-contained, and query-conditioned evidence. DistillPO formulates post-retrieval evidence distillation as a structured action comprising message selection and evidence rewriting. It optimizes this action with a decomposed-and-gated reward pipeline and structure-aligned advantage assignment, gating reward components from validity to quality checks while exposing task-level correctness feedback early and assigning each reward to its responsible output span. On LoCoMo and LongMemEval-S, DeferMem surpasses strong baselines in QA accuracy and memory-system efficiency, achieving the highest QA accuracy with the fastest runtime and zero commercial-API token cost for memory operations.
Shared-kernel Wavelet Neural Networks for Poisson Image Reconstruction
Apr 27, 2026The Laplacian operator transforms the image into its Laplacian field, which usually is sparse and satisfies a stable distribution. On the other hand, an image can be uniquely reconstructed from its Laplacian field via solving a Poisson equation with a proper boundary condition. Such uniqueness is mathematically guaranteed. Thanks to these properties, we propose to use the sparse Laplacian field to present the image. We first show that the Laplacian field is sparse and satisfies a stable distribution on hundreds images. Then, we show that the image can be accurately reconstruct from its Laplacian field. For the reconstruction task, we propose a shared-kernel wavelet neural network, which solves the Poisson equation and has three advantages. First, it has less than {\bf 0.0002M} parameters, which is compact enough for most of devices. Second, it has linear computation complexity, leading to a real-time reconstruction. Third, it achieves higher accuracy than previous methods. Several numerical experiments are conducted to show the effectiveness and efficiency of the sparse Laplacian field and the proposed Poisson solver. The proposed method can be applied in a large range of applications such as image compression, low light enhancement, object tracking, etc.
AtomEval: Atomic Evaluation of Adversarial Claims in Fact Verification
Apr 09, 2026Adversarial claim rewriting is widely used to test fact-checking systems, but standard metrics fail to capture truth-conditional consistency and often label semantically corrupted rewrites as successful. We introduce AtomEval, a validity-aware evaluation framework that decomposes claims into subject-relation-object-modifier (SROM) atoms and scores adversarial rewrites with Atomic Validity Scoring (AVS), enabling detection of factual corruption beyond surface similarity. Experiments on the FEVER dataset across representative attack strategies and LLM generators show that AtomEval provides more reliable evaluation signals in our experiments. Using AtomEval, we further analyze LLM-based adversarial generators and observe that stronger models do not necessarily produce more effective adversarial claims under validity-aware evaluation, highlighting previously overlooked limitations in current adversarial evaluation practices.
SARe: Structure-Aware Large-Scale 3D Fragment Reassembly
Mar 23, 20263D fragment reassembly aims to recover the rigid poses of unordered fragment point clouds or meshes in a common object coordinate system to reconstruct the complete shape. The problem becomes particularly challenging as the number of fragments grows, since the target shape is unknown and fragments provide weak semantic cues. Existing end-to-end approaches are prone to cascading failures due to unreliable contact reasoning, most notably inaccurate fragment adjacencies. To address this, we propose Structure-Aware Reassembly (SARe), a generative framework with SARe-Gen for Euclidean-space assembly generation and SARe-Refine for inference-time refinement, with explicit contact modeling. SARe-Gen jointly predicts fracture-surface token probabilities and an inter-fragment contact graph to localize contact regions and infer candidate adjacencies. It adopts a query-point-based conditioning scheme and extracts aligned local geometric tokens at query locations from a frozen geometry encoder, yielding queryable structural representations without additional structural pretraining. We further introduce an inference-time refinement stage, SARe-Refine. By verifying candidate contact edges with geometric-consistency checks, it selects reliable substructures and resamples the remaining uncertain regions while keeping verified parts fixed, leading to more stable and consistent assemblies in the many-fragment regime. We evaluate SARe across three settings, including synthetic fractures, simulated fractures from scanned real objects, and real physically fractured scans. The results demonstrate state-of-the-art performance, with more graceful degradation and higher success rates as the fragment count increases in challenging large-scale reassembly.
Real-Time Visual Analysis of High-Volume Social Media Posts
Aug 06, 2021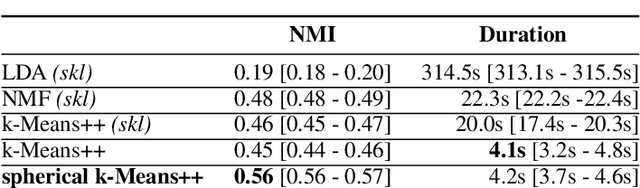

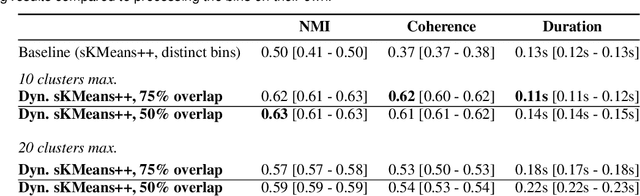

Breaking news and first-hand reports often trend on social media platforms before traditional news outlets cover them. The real-time analysis of posts on such platforms can reveal valuable and timely insights for journalists, politicians, business analysts, and first responders, but the high number and diversity of new posts pose a challenge. In this work, we present an interactive system that enables the visual analysis of streaming social media data on a large scale in real-time. We propose an efficient and explainable dynamic clustering algorithm that powers a continuously updated visualization of the current thematic landscape as well as detailed visual summaries of specific topics of interest. Our parallel clustering strategy provides an adaptive stream with a digestible but diverse selection of recent posts related to relevant topics. We also integrate familiar visual metaphors that are highly interlinked for enabling both explorative and more focused monitoring tasks. Analysts can gradually increase the resolution to dive deeper into particular topics. In contrast to previous work, our system also works with non-geolocated posts and avoids extensive preprocessing such as detecting events. We evaluated our dynamic clustering algorithm and discuss several use cases that show the utility of our system.
PlotThread: Creating Expressive Storyline Visualizations using Reinforcement Learning
Sep 01, 2020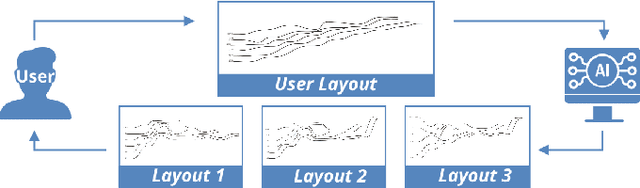
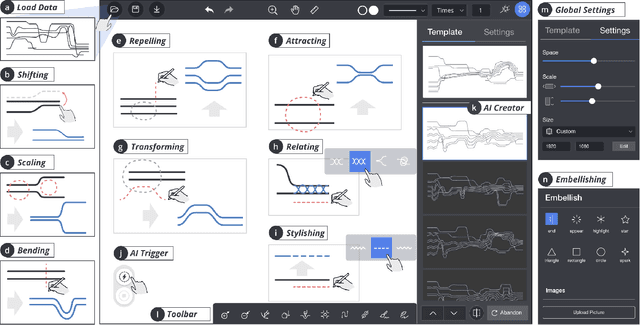
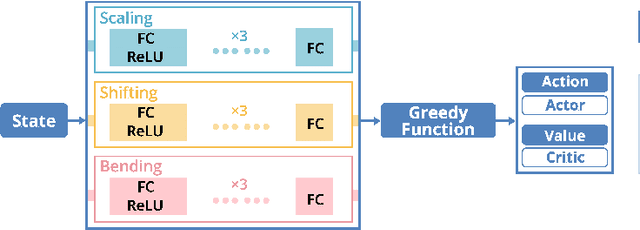
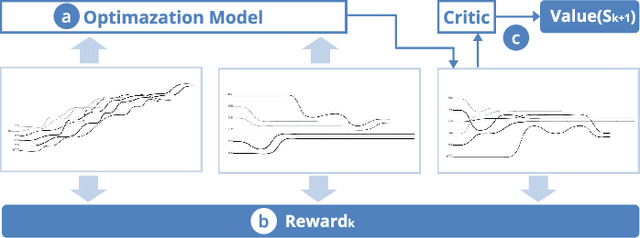
Storyline visualizations are an effective means to present the evolution of plots and reveal the scenic interactions among characters. However, the design of storyline visualizations is a difficult task as users need to balance between aesthetic goals and narrative constraints. Despite that the optimization-based methods have been improved significantly in terms of producing aesthetic and legible layouts, the existing (semi-) automatic methods are still limited regarding 1) efficient exploration of the storyline design space and 2) flexible customization of storyline layouts. In this work, we propose a reinforcement learning framework to train an AI agent that assists users in exploring the design space efficiently and generating well-optimized storylines. Based on the framework, we introduce PlotThread, an authoring tool that integrates a set of flexible interactions to support easy customization of storyline visualizations. To seamlessly integrate the AI agent into the authoring process, we employ a mixed-initiative approach where both the agent and designers work on the same canvas to boost the collaborative design of storylines. We evaluate the reinforcement learning model through qualitative and quantitative experiments and demonstrate the usage of PlotThread using a collection of use cases.