 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Single Frame Bias for Video-and-Language Learning
Jun 07, 2022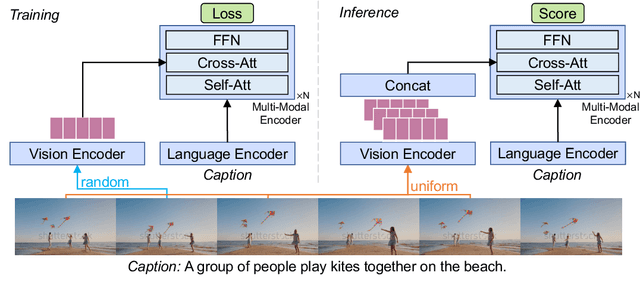
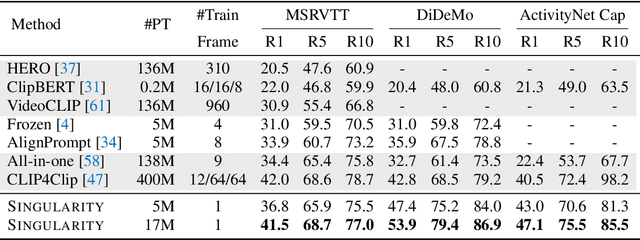
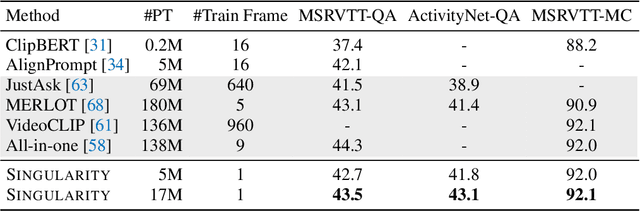

Training an effective video-and-language model intuitively requires multiple frames as model inputs. However, it is unclear whether using multiple frames is beneficial to downstream tasks, and if yes, whether the performance gain is worth the drastically-increased computation and memory costs resulting from using more frames. In this work, we explore single-frame models for video-and-language learning. On a diverse set of video-and-language tasks (including text-to-video retrieval and video question answering), we show the surprising result that, with large-scale pre-training and a proper frame ensemble strategy at inference time, a single-frame trained model that does not consider temporal information can achieve better performance than existing methods that use multiple frames for training. This result reveals the existence of a strong "static appearance bias" in popular video-and-language datasets. Therefore, to allow for a more comprehensive evaluation of video-and-language models, we propose two new retrieval tasks based on existing fine-grained action recognition datasets that encourage temporal modeling. Our code is available at https://github.com/jayleicn/singularity
End-to-End Visual Editing with a Generatively Pre-Trained Artist
May 03, 2022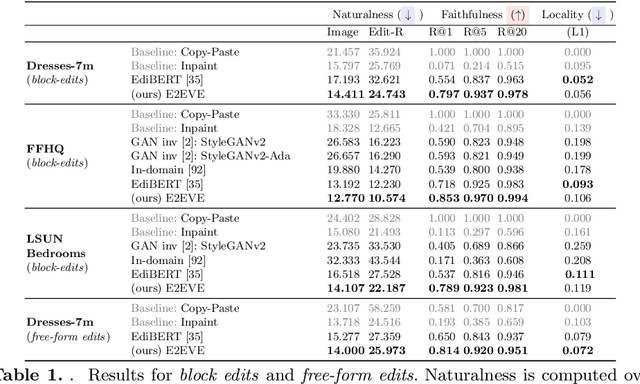

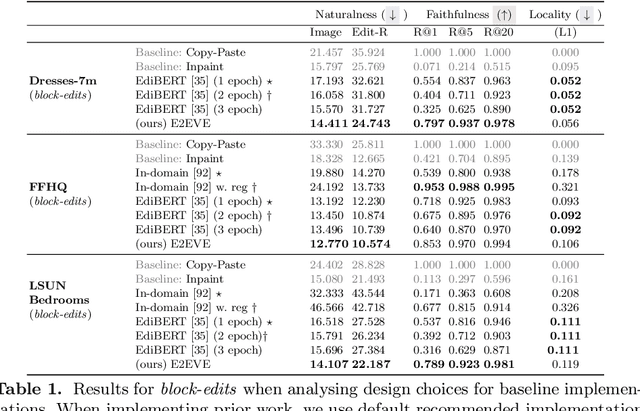
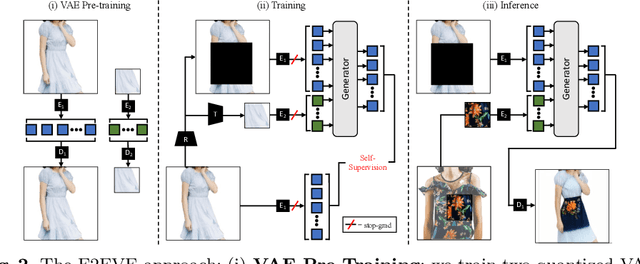
We consider the targeted image editing problem: blending a region in a source image with a driver image that specifies the desired change. Differently from prior works, we solve this problem by learning a conditional probability distribution of the edits, end-to-end. Training such a model requires addressing a fundamental technical challenge: the lack of example edits for training. To this end, we propose a self-supervised approach that simulates edits by augmenting off-the-shelf images in a target domain. The benefits are remarkable: implemented as a state-of-the-art auto-regressive transformer, our approach is simple, sidesteps difficulties with previous methods based on GAN-like priors, obtains significantly better edits, and is efficient. Furthermore, we show that different blending effects can be learned by an intuitive control of the augmentation process, with no other changes required to the model architecture. We demonstrate the superiority of this approach across several datasets in extensive quantitative and qualitative experiments, including human studies, significantly outperforming prior work.
LoopITR: Combining Dual and Cross Encoder Architectures for Image-Text Retrieval
Mar 10, 2022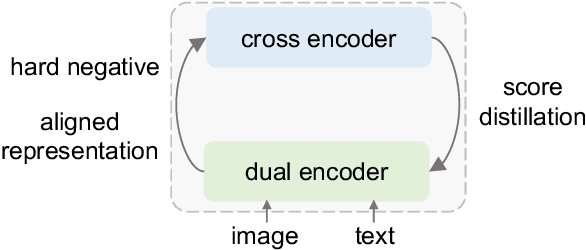
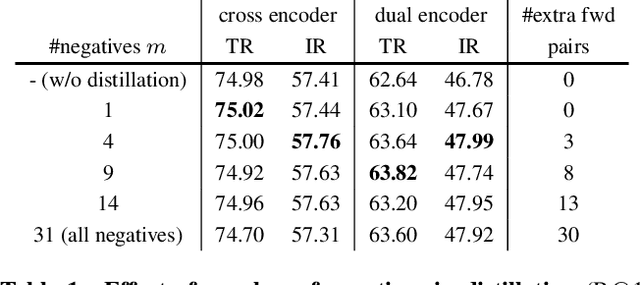

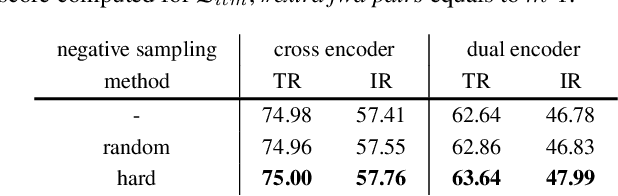
Dual encoders and cross encoders have been widely used for image-text retrieval. Between the two, the dual encoder encodes the image and text independently followed by a dot product, while the cross encoder jointly feeds image and text as the input and performs dense multi-modal fusion. These two architectures are typically modeled separately without interaction. In this work, we propose LoopITR, which combines them in the same network for joint learning. Specifically, we let the dual encoder provide hard negatives to the cross encoder, and use the more discriminative cross encoder to distill its predictions back to the dual encoder. Both steps are efficiently performed together in the same model. Our work centers on empirical analyses of this combined architecture, putting the main focus on the design of the distillation objective. Our experimental results highlight the benefits of training the two encoders in the same network, and demonstrate that distillation can be quite effective with just a few hard negative examples. Experiments on two standard datasets (Flickr30K and COCO) show our approach achieves state-of-the-art dual encoder performance when compared with approaches using a similar amount of data.
CommerceMM: Large-Scale Commerce MultiModal Representation Learning with Omni Retrieval
Feb 15, 2022
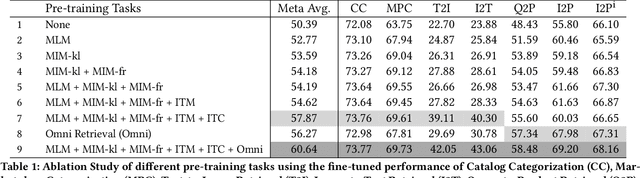
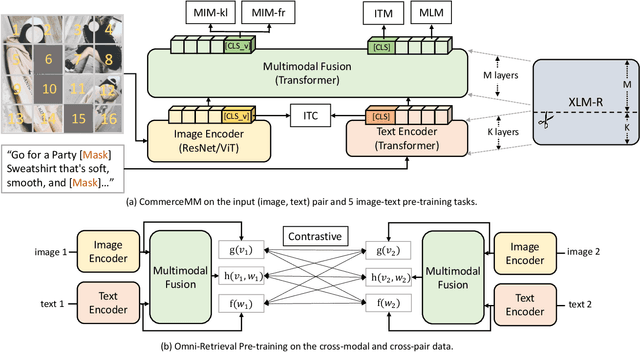

We introduce CommerceMM - a multimodal model capable of providing a diverse and granular understanding of commerce topics associated to the given piece of content (image, text, image+text), and having the capability to generalize to a wide range of tasks, including Multimodal Categorization, Image-Text Retrieval, Query-to-Product Retrieval, Image-to-Product Retrieval, etc. We follow the pre-training + fine-tuning training regime and present 5 effective pre-training tasks on image-text pairs. To embrace more common and diverse commerce data with text-to-multimodal, image-to-multimodal, and multimodal-to-multimodal mapping, we propose another 9 novel cross-modal and cross-pair retrieval tasks, called Omni-Retrieval pre-training. The pre-training is conducted in an efficient manner with only two forward/backward updates for the combined 14 tasks. Extensive experiments and analysis show the effectiveness of each task. When combining all pre-training tasks, our model achieves state-of-the-art performance on 7 commerce-related downstream tasks after fine-tuning. Additionally, we propose a novel approach of modality randomization to dynamically adjust our model under different efficiency constraints.
MTVR: Multilingual Moment Retrieval in Videos
Jul 30, 2021

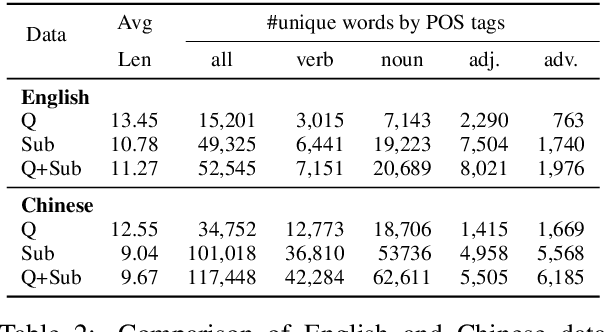
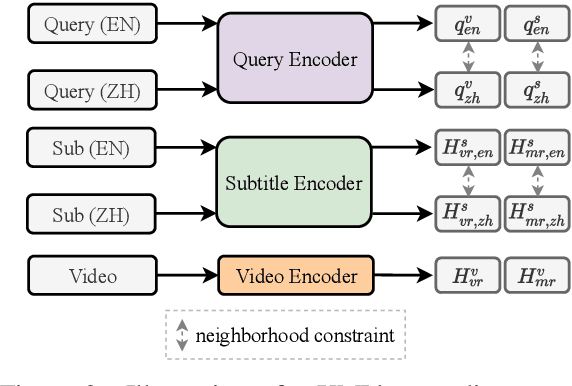
We introduce mTVR, a large-scale multilingual video moment retrieval dataset, containing 218K English and Chinese queries from 21.8K TV show video clips. The dataset is collected by extending the popular TVR dataset (in English) with paired Chinese queries and subtitles. Compared to existing moment retrieval datasets, mTVR is multilingual, larger, and comes with diverse annotations. We further propose mXML, a multilingual moment retrieval model that learns and operates on data from both languages, via encoder parameter sharing and language neighborhood constraints. We demonstrate the effectiveness of mXML on the newly collected MTVR dataset, where mXML outperforms strong monolingual baselines while using fewer parameters. In addition, we also provide detailed dataset analyses and model ablations. Data and code are publicly available at https://github.com/jayleicn/mTVRetrieval
QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries
Jul 20, 2021
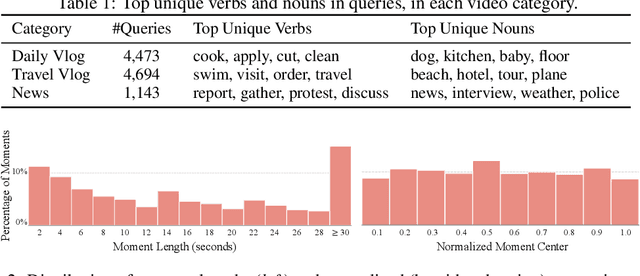
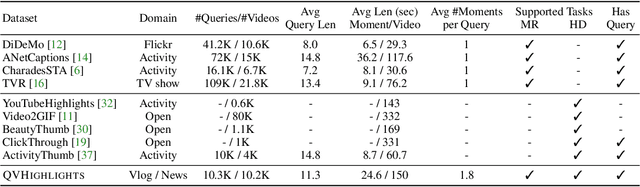
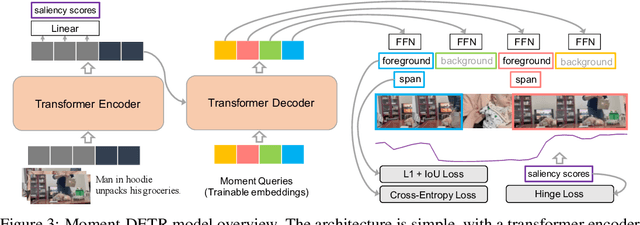
Detecting customized moments and highlights from videos given natural language (NL) user queries is an important but under-studied topic. One of the challenges in pursuing this direction is the lack of annotated data. To address this issue, we present the Query-based Video Highlights (QVHighlights) dataset. It consists of over 10,000 YouTube videos, covering a wide range of topics, from everyday activities and travel in lifestyle vlog videos to social and political activities in news videos. Each video in the dataset is annotated with: (1) a human-written free-form NL query, (2) relevant moments in the video w.r.t. the query, and (3) five-point scale saliency scores for all query-relevant clips. This comprehensive annotation enables us to develop and evaluate systems that detect relevant moments as well as salient highlights for diverse, flexible user queries. We also present a strong baseline for this task, Moment-DETR, a transformer encoder-decoder model that views moment retrieval as a direct set prediction problem, taking extracted video and query representations as inputs and predicting moment coordinates and saliency scores end-to-end. While our model does not utilize any human prior, we show that it performs competitively when compared to well-engineered architectures. With weakly supervised pretraining using ASR captions, Moment-DETR substantially outperforms previous methods. Lastly, we present several ablations and visualizations of Moment-DETR. Data and code is publicly available at https://github.com/jayleicn/moment_detr
Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling
Feb 11, 2021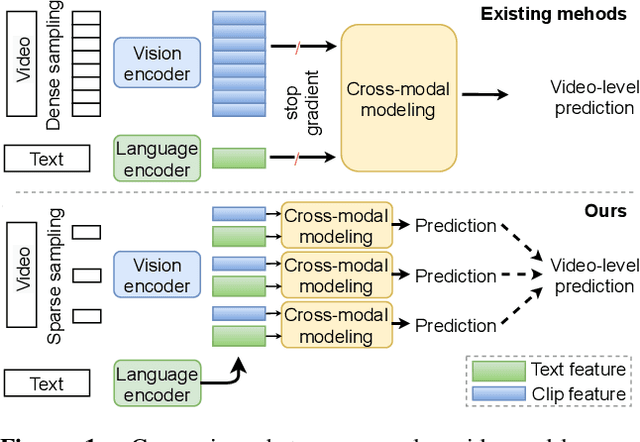
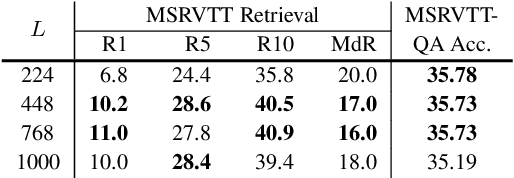
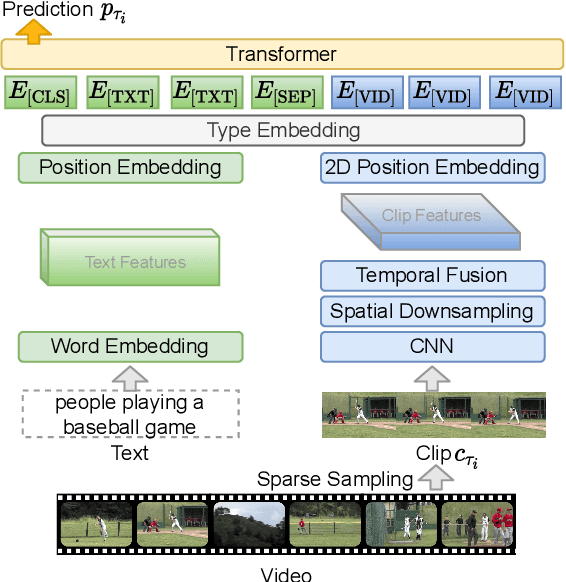
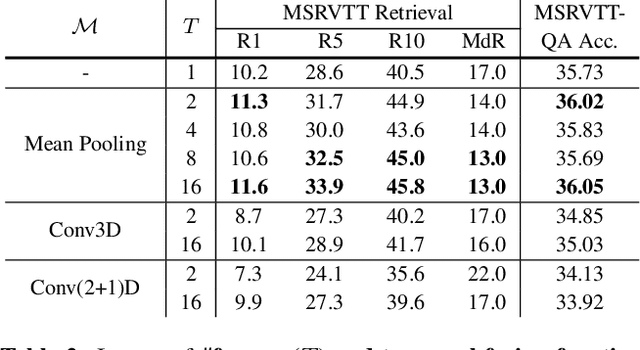
The canonical approach to video-and-language learning (e.g., video question answering) dictates a neural model to learn from offline-extracted dense video features from vision models and text features from language models. These feature extractors are trained independently and usually on tasks different from the target domains, rendering these fixed features sub-optimal for downstream tasks. Moreover, due to the high computational overload of dense video features, it is often difficult (or infeasible) to plug feature extractors directly into existing approaches for easy finetuning. To provide a remedy to this dilemma, we propose a generic framework ClipBERT that enables affordable end-to-end learning for video-and-language tasks, by employing sparse sampling, where only a single or a few sparsely sampled short clips from a video are used at each training step. Experiments on text-to-video retrieval and video question answering on six datasets demonstrate that ClipBERT outperforms (or is on par with) existing methods that exploit full-length videos, suggesting that end-to-end learning with just a few sparsely sampled clips is often more accurate than using densely extracted offline features from full-length videos, proving the proverbial less-is-more principle. Videos in the datasets are from considerably different domains and lengths, ranging from 3-second generic domain GIF videos to 180-second YouTube human activity videos, showing the generalization ability of our approach. Comprehensive ablation studies and thorough analyses are provided to dissect what factors lead to this success. Our code is publicly available at https://github.com/jayleicn/ClipBERT
What is More Likely to Happen Next? Video-and-Language Future Event Prediction
Oct 15, 2020

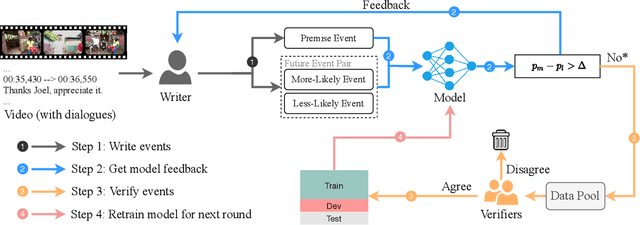
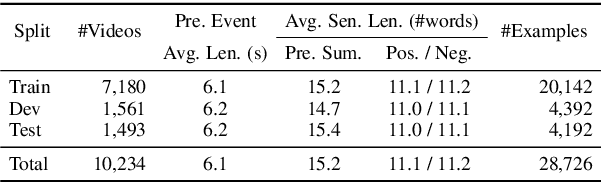
Given a video with aligned dialogue, people can often infer what is more likely to happen next. Making such predictions requires not only a deep understanding of the rich dynamics underlying the video and dialogue, but also a significant amount of commonsense knowledge. In this work, we explore whether AI models are able to learn to make such multimodal commonsense next-event predictions. To support research in this direction, we collect a new dataset, named Video-and-Language Event Prediction (VLEP), with 28,726 future event prediction examples (along with their rationales) from 10,234 diverse TV Show and YouTube Lifestyle Vlog video clips. In order to promote the collection of non-trivial challenging examples, we employ an adversarial human-and-model-in-the-loop data collection procedure. We also present a strong baseline incorporating information from video, dialogue, and commonsense knowledge. Experiments show that each type of information is useful for this challenging task, and that compared to the high human performance on VLEP, our model provides a good starting point but leaves large room for future work. Our dataset and code are available at: https://github.com/jayleicn/VideoLanguageFuturePred
MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
May 11, 2020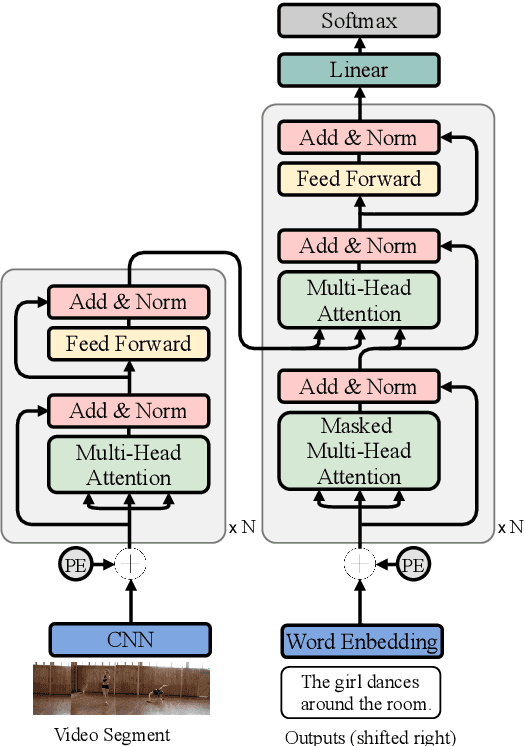
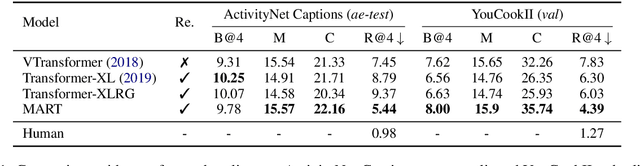
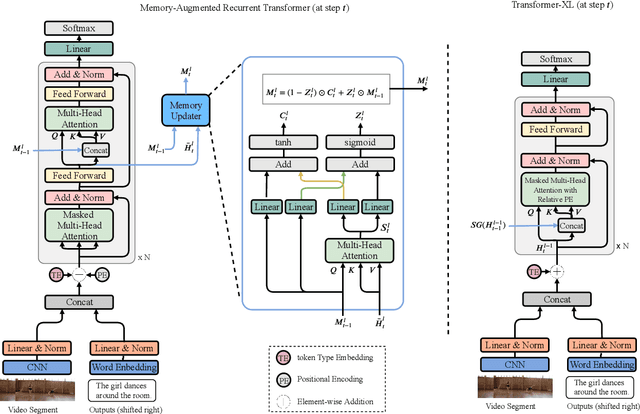
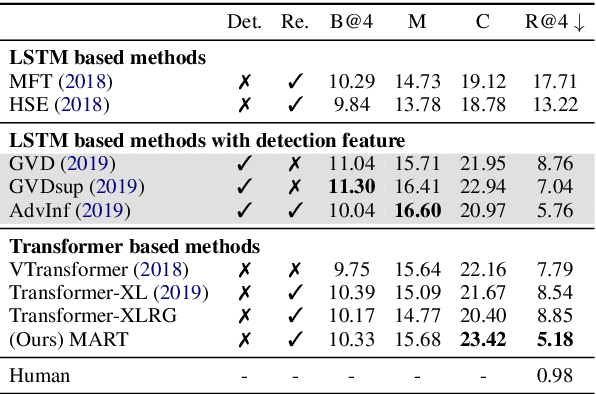
Generating multi-sentence descriptions for videos is one of the most challenging captioning tasks due to its high requirements for not only visual relevance but also discourse-based coherence across the sentences in the paragraph. Towards this goal, we propose a new approach called Memory-Augmented Recurrent Transformer (MART), which uses a memory module to augment the transformer architecture. The memory module generates a highly summarized memory state from the video segments and the sentence history so as to help better prediction of the next sentence (w.r.t. coreference and repetition aspects), thus encouraging coherent paragraph generation. Extensive experiments, human evaluations, and qualitative analyses on two popular datasets ActivityNet Captions and YouCookII show that MART generates more coherent and less repetitive paragraph captions than baseline methods, while maintaining relevance to the input video events. All code is available open-source at: https://github.com/jayleicn/recurrent-transformer
TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
Jan 24, 2020

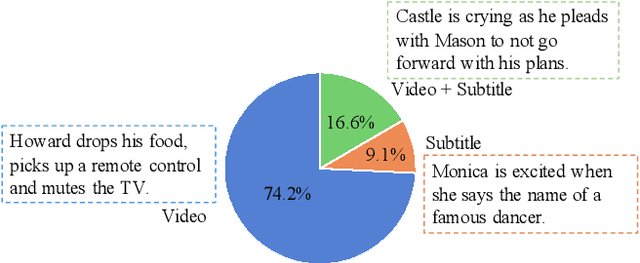

We introduce a new multimodal retrieval task - TV show Retrieval (TVR), in which a short video moment has to be localized from a large video (with subtitle) corpus, given a natural language query. Different from previous moment retrieval tasks dealing with videos only, TVR requires the system to understand both the video and the associated subtitle text, making it a more realistic task. To support the study of this new task, we have collected a large-scale, high-quality dataset consisting of 108,965 queries on 21,793 videos from 6 TV shows of diverse genres, where each query is associated with a tight temporal alignment. Strict qualification and post-annotation verification tests are applied to ensure the quality of the collected data. We present several baselines and a novel Cross-modal Moment Localization (XML) modular network for this new dataset and task. The proposed XML model surpasses all presented baselines by a large margin and with better efficiency, providing a strong starting point for future work. Extensive analysis experiments also show that incorporating both video and subtitle modules yields better performance than either alone. Lastly, we have also collected additional descriptions for each annotated moment in TVR to form a new multimodal captioning dataset with 262K captions, named the TV show Caption dataset (TVC). Here models need to jointly use the video and subtitle to generate a caption description. Both datasets are publicly available at https://tvr.cs.unc.edu