 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech
Nov 19, 2021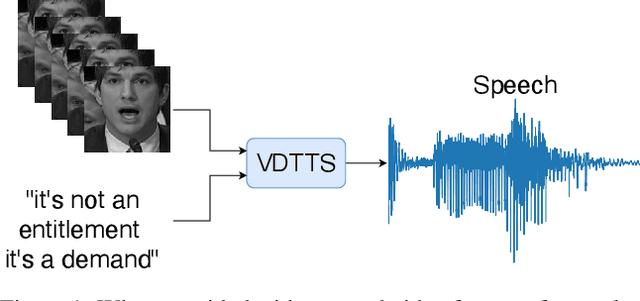
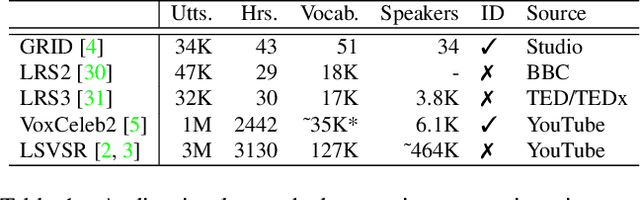
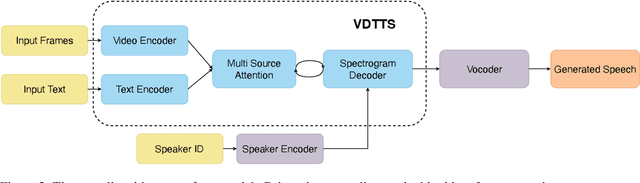
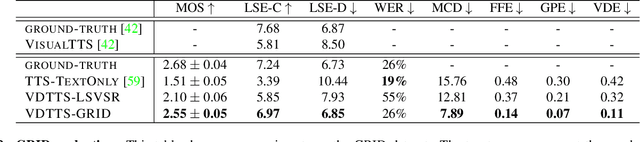
In this paper we present VDTTS, a Visually-Driven Text-to-Speech model. Motivated by dubbing, VDTTS takes advantage of video frames as an additional input alongside text, and generates speech that matches the video signal. We demonstrate how this allows VDTTS to, unlike plain TTS models, generate speech that not only has prosodic variations like natural pauses and pitch, but is also synchronized to the input video. Experimentally, we show our model produces well synchronized outputs, approaching the video-speech synchronization quality of the ground-truth, on several challenging benchmarks including "in-the-wild" content from VoxCeleb2. We encourage the reader to view the demo videos demonstrating video-speech synchronization, robustness to speaker ID swapping, and prosody.
Translatotron 2: Robust direct speech-to-speech translation
Jul 29, 2021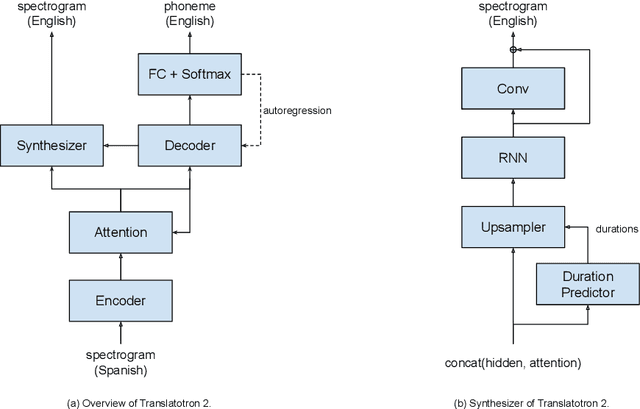
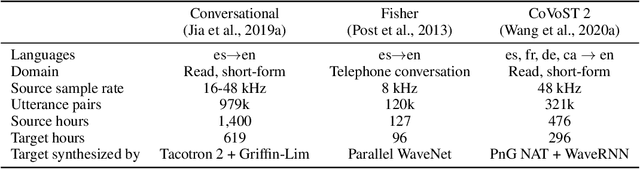
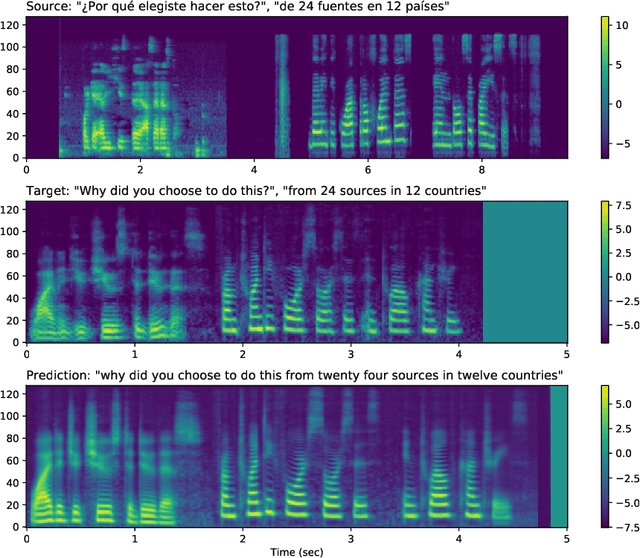
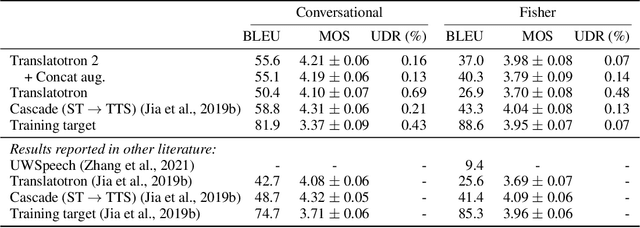
We present Translatotron 2, a neural direct speech-to-speech translation model that can be trained end-to-end. Translatotron 2 consists of a speech encoder, a phoneme decoder, a mel-spectrogram synthesizer, and an attention module that connects all the previous three components. Experimental results suggest that Translatotron 2 outperforms the original Translatotron by a large margin in terms of translation quality and predicted speech naturalness, and drastically improves the robustness of the predicted speech by mitigating over-generation, such as babbling or long pause. We also propose a new method for retaining the source speaker's voice in the translated speech. The trained model is restricted to retain the source speaker's voice, and unlike the original Translatotron, it is not able to generate speech in a different speaker's voice, making the model more robust for production deployment, by mitigating potential misuse for creating spoofing audio artifacts. When the new method is used together with a simple concatenation-based data augmentation, the trained Translatotron 2 model is able to retain each speaker's voice for input with speaker turns.
Improving On-Screen Sound Separation for Open Domain Videos with Audio-Visual Self-attention
Jun 17, 2021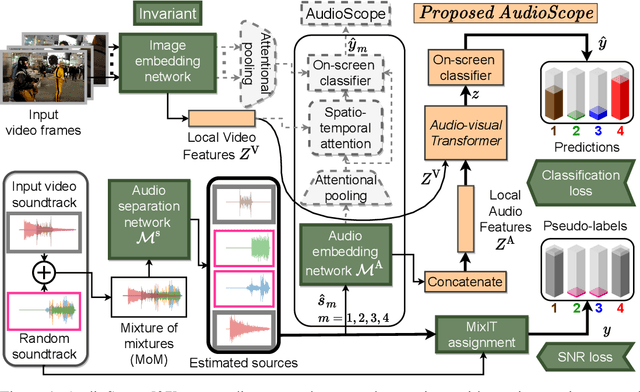
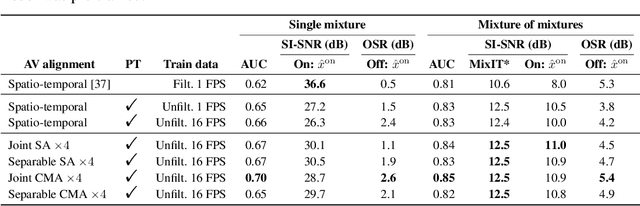
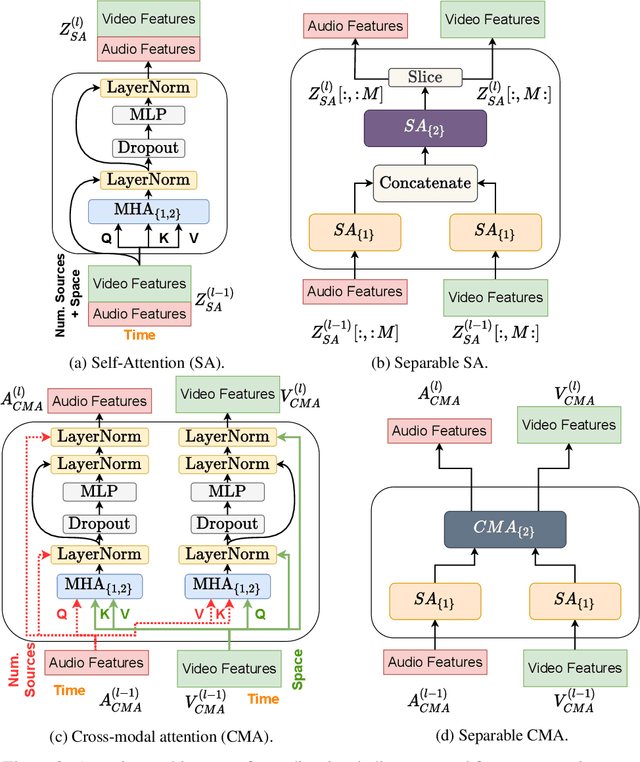
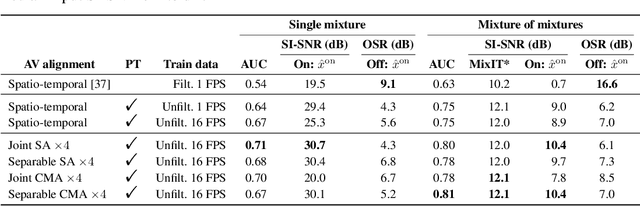
We introduce a state-of-the-art audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify limitations of previous work on audiovisual on-screen sound separation, including the simplicity and coarse resolution of spatio-temporal attention, and poor convergence of the audio separation model. Our proposed model addresses these issues using cross-modal and self-attention modules that capture audio-visual dependencies at a finer resolution over time, and by unsupervised pre-training of audio separation model. These improvements allow the model to generalize to a much wider set of unseen videos. For evaluation and semi-supervised training, we collected human annotations of on-screen audio from a large database of in-the-wild videos (YFCC100M). Our results show marked improvements in on-screen separation performance, in more general conditions than previous methods.
Into the Wild with AudioScope: Unsupervised Audio-Visual Separation of On-Screen Sounds
Nov 02, 2020
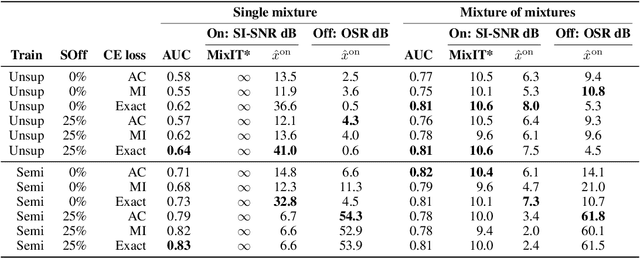
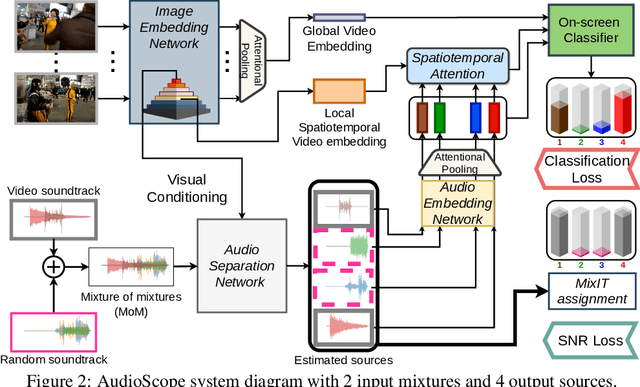
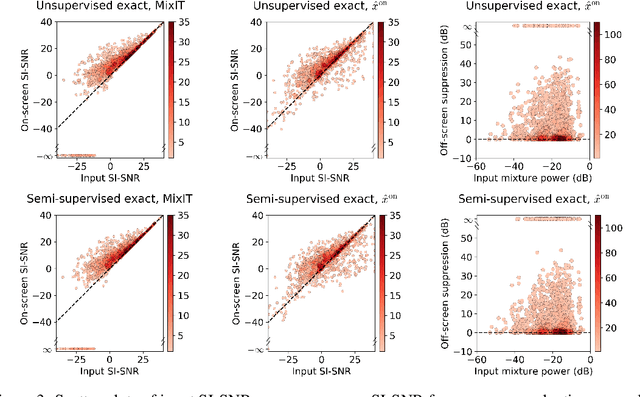
Recent progress in deep learning has enabled many advances in sound separation and visual scene understanding. However, extracting sound sources which are apparent in natural videos remains an open problem. In this work, we present AudioScope, a novel audio-visual sound separation framework that can be trained without supervision to isolate on-screen sound sources from real in-the-wild videos. Prior audio-visual separation work assumed artificial limitations on the domain of sound classes (e.g., to speech or music), constrained the number of sources, and required strong sound separation or visual segmentation labels. AudioScope overcomes these limitations, operating on an open domain of sounds, with variable numbers of sources, and without labels or prior visual segmentation. The training procedure for AudioScope uses mixture invariant training (MixIT) to separate synthetic mixtures of mixtures (MoMs) into individual sources, where noisy labels for mixtures are provided by an unsupervised audio-visual coincidence model. Using the noisy labels, along with attention between video and audio features, AudioScope learns to identify audio-visual similarity and to suppress off-screen sounds. We demonstrate the effectiveness of our approach using a dataset of video clips extracted from open-domain YFCC100m video data. This dataset contains a wide diversity of sound classes recorded in unconstrained conditions, making the application of previous methods unsuitable. For evaluation and semi-supervised experiments, we collected human labels for presence of on-screen and off-screen sounds on a small subset of clips.
Class-Aware Fully-Convolutional Gaussian and Poisson Denoising
Aug 20, 2018
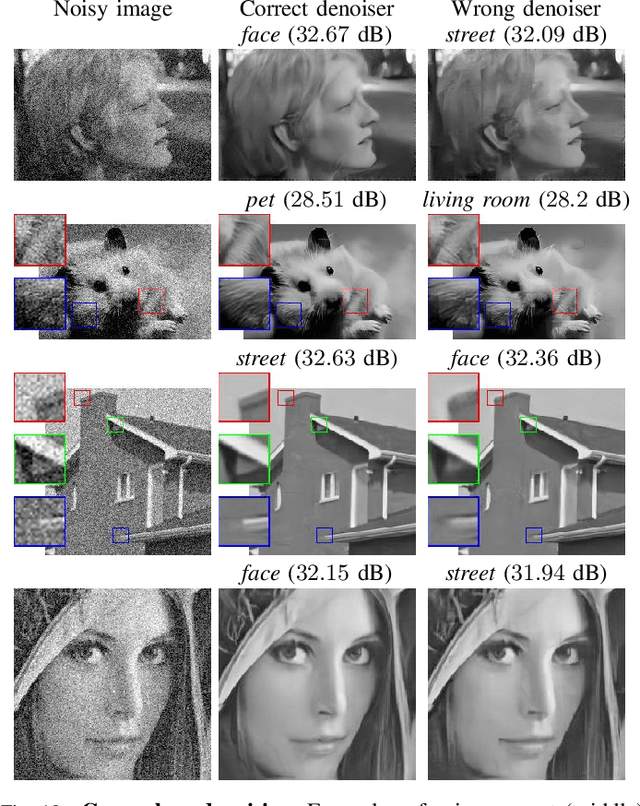
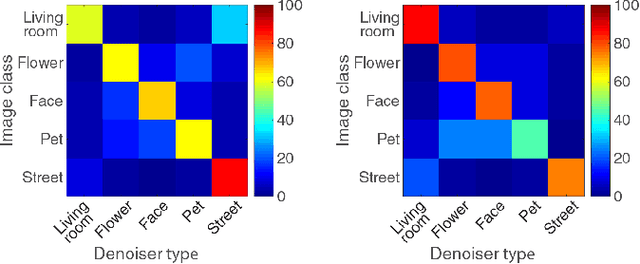

We propose a fully-convolutional neural-network architecture for image denoising which is simple yet powerful. Its structure allows to exploit the gradual nature of the denoising process, in which shallow layers handle local noise statistics, while deeper layers recover edges and enhance textures. Our method advances the state-of-the-art when trained for different noise levels and distributions (both Gaussian and Poisson). In addition, we show that making the denoiser class-aware by exploiting semantic class information boosts performance, enhances textures and reduces artifacts.
Learning to Segment via Cut-and-Paste
Mar 16, 2018
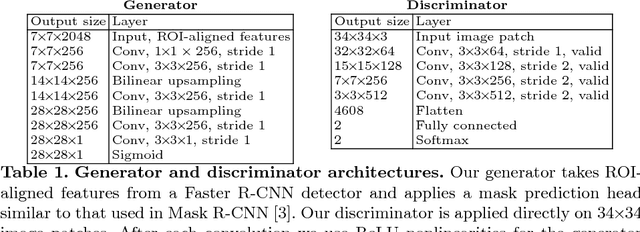
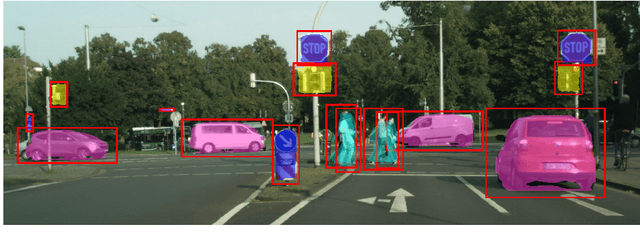
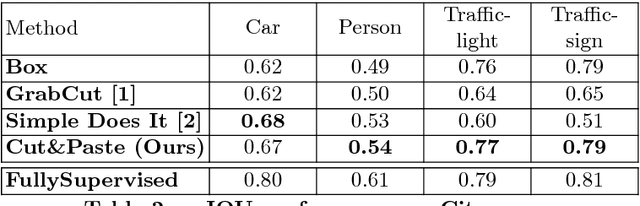
This paper presents a weakly-supervised approach to object instance segmentation. Starting with known or predicted object bounding boxes, we learn object masks by playing a game of cut-and-paste in an adversarial learning setup. A mask generator takes a detection box and Faster R-CNN features, and constructs a segmentation mask that is used to cut-and-paste the object into a new image location. The discriminator tries to distinguish between real objects, and those cut and pasted via the generator, giving a learning signal that leads to improved object masks. We verify our method experimentally using Cityscapes, COCO, and aerial image datasets, learning to segment objects without ever having seen a mask in training. Our method exceeds the performance of existing weakly supervised methods, without requiring hand-tuned segment proposals, and reaches 90% of supervised performance.
Efficient Deformable Shape Correspondence via Kernel Matching
Sep 15, 2017
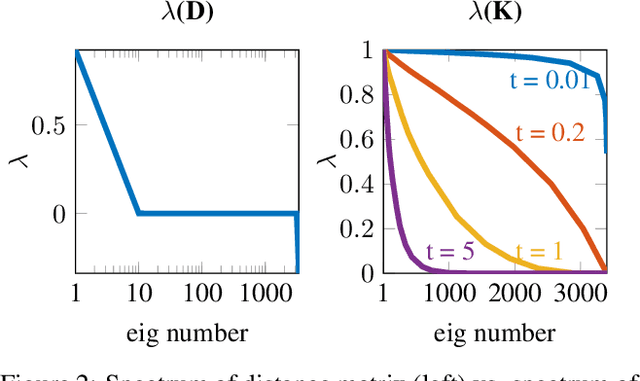
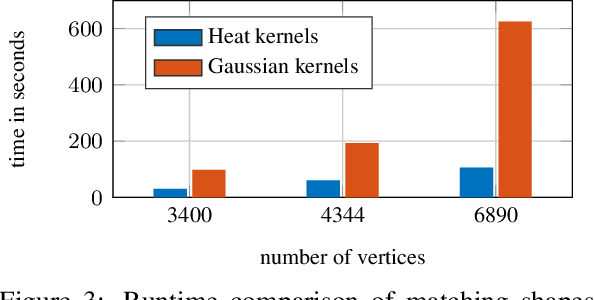
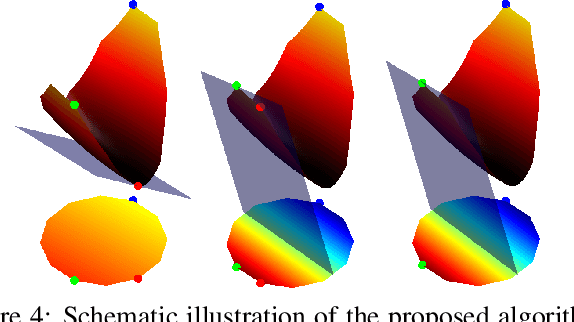
We present a method to match three dimensional shapes under non-isometric deformations, topology changes and partiality. We formulate the problem as matching between a set of pair-wise and point-wise descriptors, imposing a continuity prior on the mapping, and propose a projected descent optimization procedure inspired by difference of convex functions (DC) programming. Surprisingly, in spite of the highly non-convex nature of the resulting quadratic assignment problem, our method converges to a semantically meaningful and continuous mapping in most of our experiments, and scales well. We provide preliminary theoretical analysis and several interpretations of the method.
Deep Functional Maps: Structured Prediction for Dense Shape Correspondence
Jul 30, 2017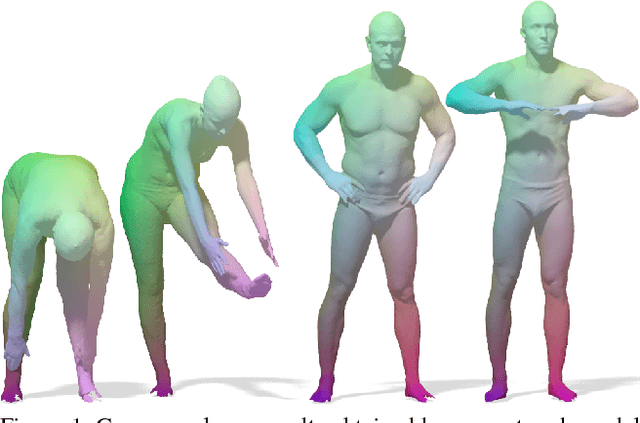
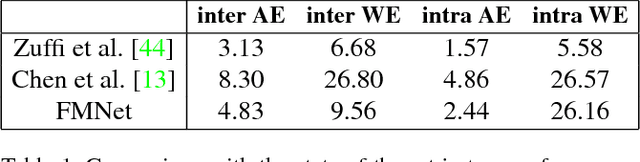
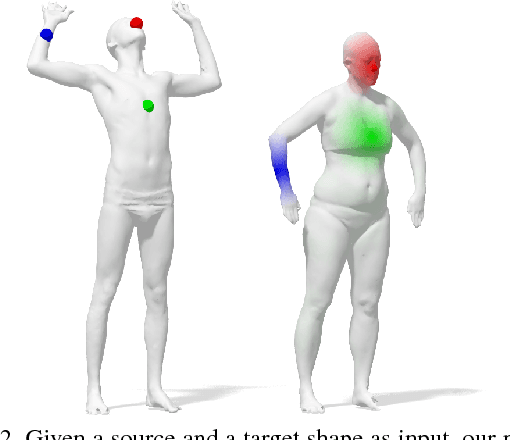
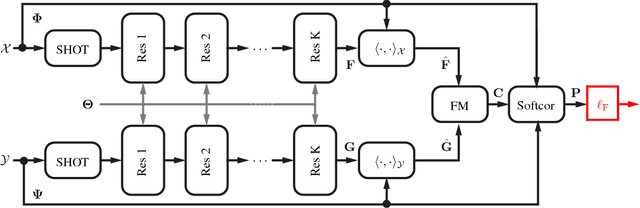
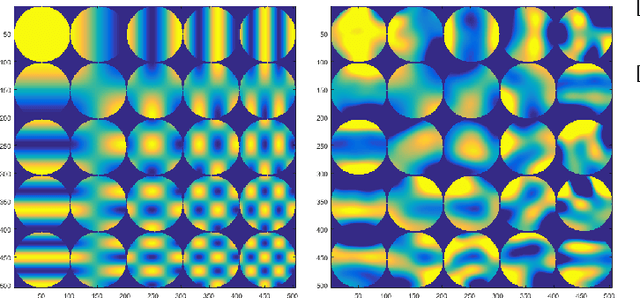
We introduce a new framework for learning dense correspondence between deformable 3D shapes. Existing learning based approaches model shape correspondence as a labelling problem, where each point of a query shape receives a label identifying a point on some reference domain; the correspondence is then constructed a posteriori by composing the label predictions of two input shapes. We propose a paradigm shift and design a structured prediction model in the space of functional maps, linear operators that provide a compact representation of the correspondence. We model the learning process via a deep residual network which takes dense descriptor fields defined on two shapes as input, and outputs a soft map between the two given objects. The resulting correspondence is shown to be accurate on several challenging benchmarks comprising multiple categories, synthetic models, real scans with acquisition artifacts, topological noise, and partiality.
Cloud Dictionary: Sparse Coding and Modeling for Point Clouds
Mar 20, 2017

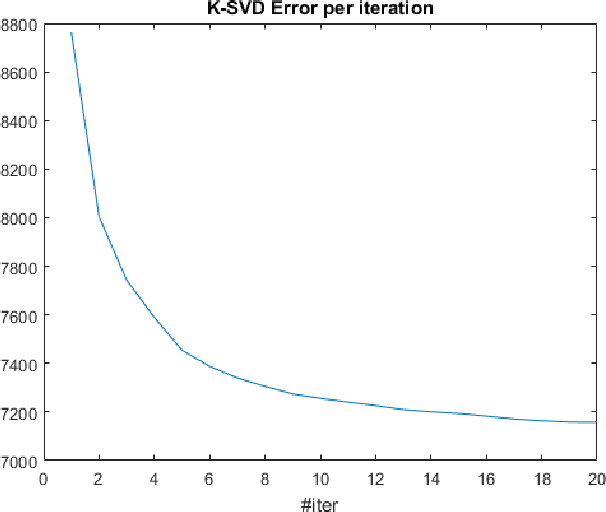
With the development of range sensors such as LIDAR and time-of-flight cameras, 3D point cloud scans have become ubiquitous in computer vision applications, the most prominent ones being gesture recognition and autonomous driving. Parsimony-based algorithms have shown great success on images and videos where data points are sampled on a regular Cartesian grid. We propose an adaptation of these techniques to irregularly sampled signals by using continuous dictionaries. We present an example application in the form of point cloud denoising.
Deep Class Aware Denoising
Feb 27, 2017
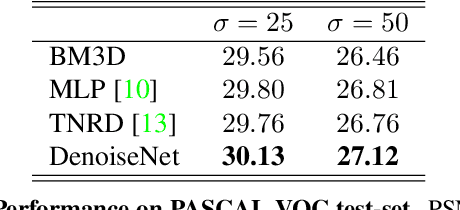
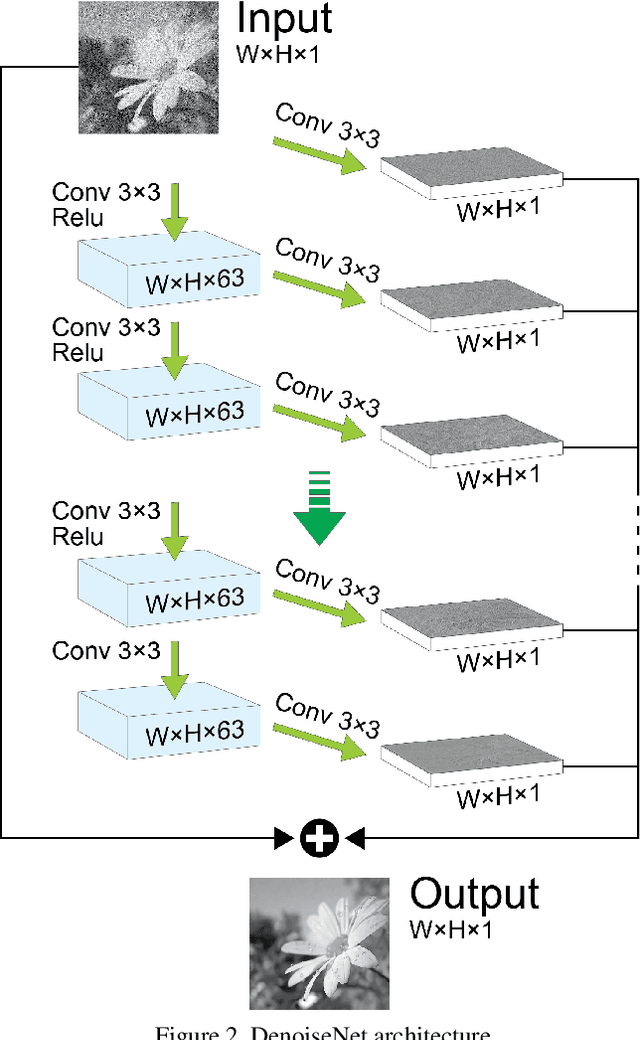

The increasing demand for high image quality in mobile devices brings forth the need for better computational enhancement techniques, and image denoising in particular. At the same time, the images captured by these devices can be categorized into a small set of semantic classes. However simple, this observation has not been exploited in image denoising until now. In this paper, we demonstrate how the reconstruction quality improves when a denoiser is aware of the type of content in the image. To this end, we first propose a new fully convolutional deep neural network architecture which is simple yet powerful as it achieves state-of-the-art performance even without being class-aware. We further show that a significant boost in performance of up to $0.4$ dB PSNR can be achieved by making our network class-aware, namely, by fine-tuning it for images belonging to a specific semantic class. Relying on the hugely successful existing image classifiers, this research advocates for using a class-aware approach in all image enhancement tasks.