 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Refer?
Aug 10, 2023What do language models (LMs) do with language? Everyone agrees that they produce sequences of (mostly) coherent sentences. But are they saying anything with those strings or simply babbling in a convincing simulacrum of language use? This is a vague question, and there are many ways of making it precise. Here we will address one aspect of the question, namely, whether LMs' words refer: that is, whether the outputs of LMs achieve "word-to-world" connections. There is prima facie reason to think they do not since LMs do not interact with the world in the way that ordinary language users do. Drawing on insights from the externalist tradition in philosophy of language, we argue that appearances are misleading and that there is good reason to think that LMs can refer.
Language Models Can Learn Exceptions to Syntactic Rules
Jun 09, 2023Artificial neural networks can generalize productively to novel contexts. Can they also learn exceptions to those productive rules? We explore this question using the case of restrictions on English passivization (e.g., the fact that "The vacation lasted five days" is grammatical, but "*Five days was lasted by the vacation" is not). We collect human acceptability judgments for passive sentences with a range of verbs, and show that the probability distribution defined by GPT-2, a language model, matches the human judgments with high correlation. We also show that the relative acceptability of a verb in the active vs. passive voice is positively correlated with the relative frequency of its occurrence in those voices. These results provide preliminary support for the entrenchment hypothesis, according to which learners track and uses the distributional properties of their input to learn negative exceptions to rules. At the same time, this hypothesis fails to explain the magnitude of unpassivizability demonstrated by certain individual verbs, suggesting that other cues to exceptionality are available in the linguistic input.
How to Plant Trees in Language Models: Data and Architectural Effects on the Emergence of Syntactic Inductive Biases
May 31, 2023Accurate syntactic representations are essential for robust generalization in natural language. Recent work has found that pre-training can teach language models to rely on hierarchical syntactic features - as opposed to incorrect linear features - when performing tasks after fine-tuning. We test what aspects of pre-training are important for endowing encoder-decoder Transformers with an inductive bias that favors hierarchical syntactic generalizations. We focus on architectural features (depth, width, and number of parameters), as well as the genre and size of the pre-training corpus, diagnosing inductive biases using two syntactic transformation tasks: question formation and passivization, both in English. We find that the number of parameters alone does not explain hierarchical generalization: model depth plays greater role than model width. We also find that pre-training on simpler language, such as child-directed speech, induces a hierarchical bias using an order-of-magnitude less data than pre-training on more typical datasets based on web text or Wikipedia; this suggests that in cognitively plausible language acquisition settings, neural language models may be more data-efficient than previously thought.
How poor is the stimulus? Evaluating hierarchical generalization in neural networks trained on child-directed speech
Jan 26, 2023When acquiring syntax, children consistently choose hierarchical rules over competing non-hierarchical possibilities. Is this preference due to a learning bias for hierarchical structure, or due to more general biases that interact with hierarchical cues in children's linguistic input? We explore these possibilities by training LSTMs and Transformers - two types of neural networks without a hierarchical bias - on data similar in quantity and content to children's linguistic input: text from the CHILDES corpus. We then evaluate what these models have learned about English yes/no questions, a phenomenon for which hierarchical structure is crucial. We find that, though they perform well at capturing the surface statistics of child-directed speech (as measured by perplexity), both model types generalize in a way more consistent with an incorrect linear rule than the correct hierarchical rule. These results suggest that human-like generalization from text alone requires stronger biases than the general sequence-processing biases of standard neural network architectures.
Uncontrolled Lexical Exposure Leads to Overestimation of Compositional Generalization in Pretrained Models
Dec 21, 2022



Human linguistic capacity is often characterized by compositionality and the generalization it enables -- human learners can produce and comprehend novel complex expressions by composing known parts. Several benchmarks exploit distributional control across training and test to gauge compositional generalization, where certain lexical items only occur in limited contexts during training. While recent work using these benchmarks suggests that pretrained models achieve impressive generalization performance, we argue that exposure to pretraining data may break the aforementioned distributional control. Using the COGS benchmark of Kim and Linzen (2020), we test two modified evaluation setups that control for this issue: (1) substituting context-controlled lexical items with novel character sequences, and (2) substituting them with special tokens represented by novel embeddings. We find that both of these setups lead to lower generalization performance in T5 (Raffel et al., 2020), suggesting that previously reported results have been overestimated due to uncontrolled lexical exposure during pretraining. The performance degradation is more extreme with novel embeddings, and the degradation increases with the amount of pretraining data, highlighting an interesting case of inverse scaling.
Causal Analysis of Syntactic Agreement Neurons in Multilingual Language Models
Oct 25, 2022Structural probing work has found evidence for latent syntactic information in pre-trained language models. However, much of this analysis has focused on monolingual models, and analyses of multilingual models have employed correlational methods that are confounded by the choice of probing tasks. In this study, we causally probe multilingual language models (XGLM and multilingual BERT) as well as monolingual BERT-based models across various languages; we do this by performing counterfactual perturbations on neuron activations and observing the effect on models' subject-verb agreement probabilities. We observe where in the model and to what extent syntactic agreement is encoded in each language. We find significant neuron overlap across languages in autoregressive multilingual language models, but not masked language models. We also find two distinct layer-wise effect patterns and two distinct sets of neurons used for syntactic agreement, depending on whether the subject and verb are separated by other tokens. Finally, we find that behavioral analyses of language models are likely underestimating how sensitive masked language models are to syntactic information.
Characterizing Verbatim Short-Term Memory in Neural Language Models
Oct 24, 2022



When a language model is trained to predict natural language sequences, its prediction at each moment depends on a representation of prior context. What kind of information about the prior context can language models retrieve? We tested whether language models could retrieve the exact words that occurred previously in a text. In our paradigm, language models (transformers and an LSTM) processed English text in which a list of nouns occurred twice. We operationalized retrieval as the reduction in surprisal from the first to the second list. We found that the transformers retrieved both the identity and ordering of nouns from the first list. Further, the transformers' retrieval was markedly enhanced when they were trained on a larger corpus and with greater model depth. Lastly, their ability to index prior tokens was dependent on learned attention patterns. In contrast, the LSTM exhibited less precise retrieval, which was limited to list-initial tokens and to short intervening texts. The LSTM's retrieval was not sensitive to the order of nouns and it improved when the list was semantically coherent. We conclude that transformers implemented something akin to a working memory system that could flexibly retrieve individual token representations across arbitrary delays; conversely, the LSTM maintained a coarser and more rapidly-decaying semantic gist of prior tokens, weighted toward the earliest items.
Entailment Semantics Can Be Extracted from an Ideal Language Model
Sep 26, 2022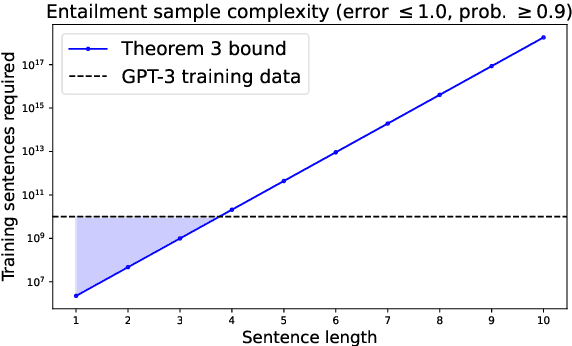
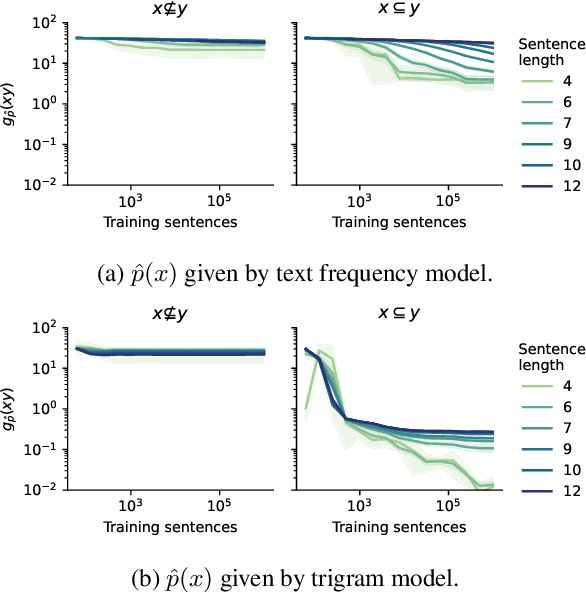
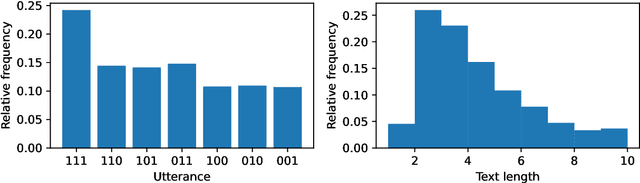
Language models are often trained on text alone, without additional grounding. There is debate as to how much of natural language semantics can be inferred from such a procedure. We prove that entailment judgments between sentences can be extracted from an ideal language model that has perfectly learned its target distribution, assuming the training sentences are generated by Gricean agents, i.e., agents who follow fundamental principles of communication from the linguistic theory of pragmatics. We also show entailment judgments can be decoded from the predictions of a language model trained on such Gricean data. Our results reveal a pathway for understanding the semantic information encoded in unlabeled linguistic data and a potential framework for extracting semantics from language models.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
When a sentence does not introduce a discourse entity, Transformer-based models still sometimes refer to it
May 06, 2022
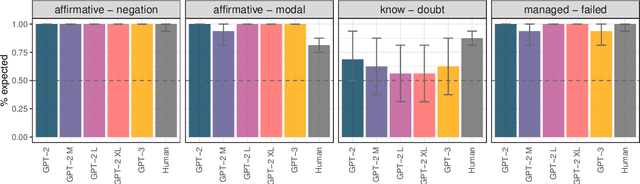
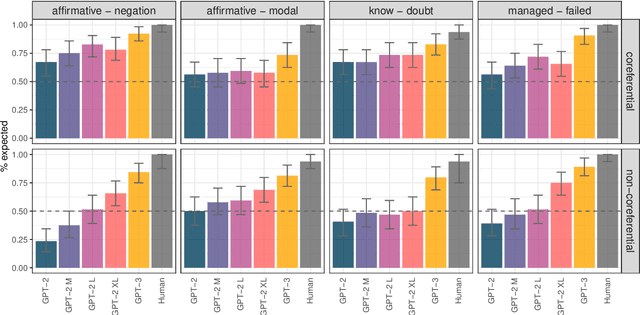

Understanding longer narratives or participating in conversations requires tracking of discourse entities that have been mentioned. Indefinite noun phrases (NPs), such as 'a dog', frequently introduce discourse entities but this behavior is modulated by sentential operators such as negation. For example, 'a dog' in 'Arthur doesn't own a dog' does not introduce a discourse entity due to the presence of negation. In this work, we adapt the psycholinguistic assessment of language models paradigm to higher-level linguistic phenomena and introduce an English evaluation suite that targets the knowledge of the interactions between sentential operators and indefinite NPs. We use this evaluation suite for a fine-grained investigation of the entity tracking abilities of the Transformer-based models GPT-2 and GPT-3. We find that while the models are to a certain extent sensitive to the interactions we investigate, they are all challenged by the presence of multiple NPs and their behavior is not systematic, which suggests that even models at the scale of GPT-3 do not fully acquire basic entity tracking abilities.