 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Contrast Stretching on Target Feature for Speech Enhancement
Apr 01, 2022
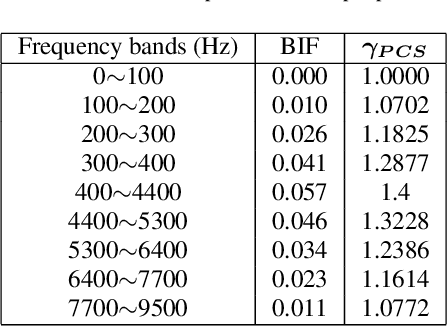
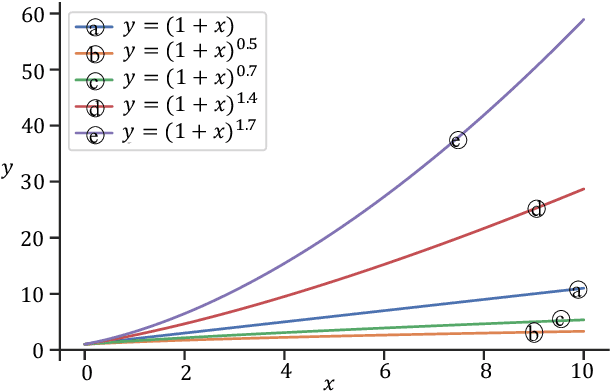
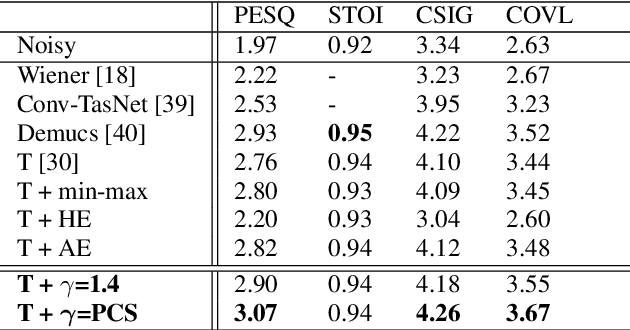
Speech enhancement (SE) performance has improved considerably since the use of deep learning (DL) models as a base function. In this study, we propose a perceptual contrast stretching (PCS) approach to further improve SE performance. PCS is derived based on the critical band importance function and applied to modify the targets of the SE model. Specifically, PCS stretches the contract of target features according to perceptual importance, thereby improving the overall SE performance. Compared to post-processing based implementations, incorporating PCS into the training phase preserves performance and reduces online computation. It is also worth noting that PCS can be suitably combined with different SE model architectures and training criteria. Meanwhile, PCS does not affect the causality or convergence of the SE model training. Experimental results on the VoiceBank-DEMAND dataset showed that the proposed method can achieve state-of-the-art performance on both causal (PESQ=3.07) and non-causal (PESQ=3.35) SE tasks.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Dec 01, 2021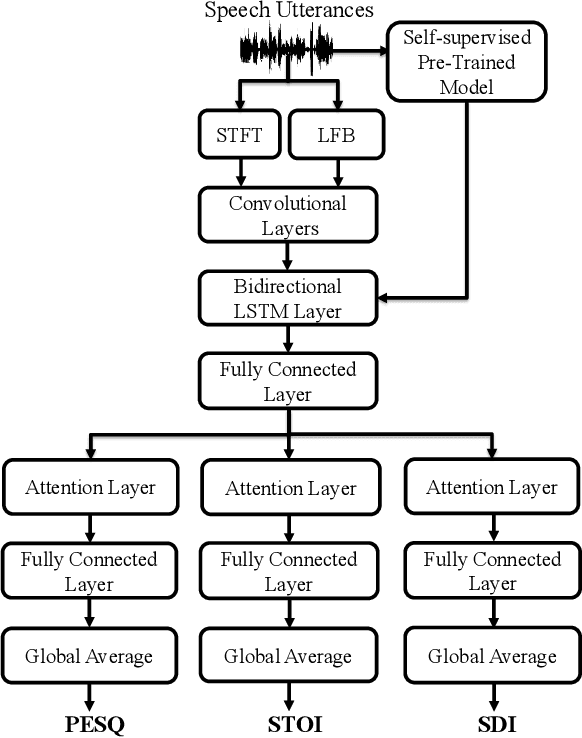
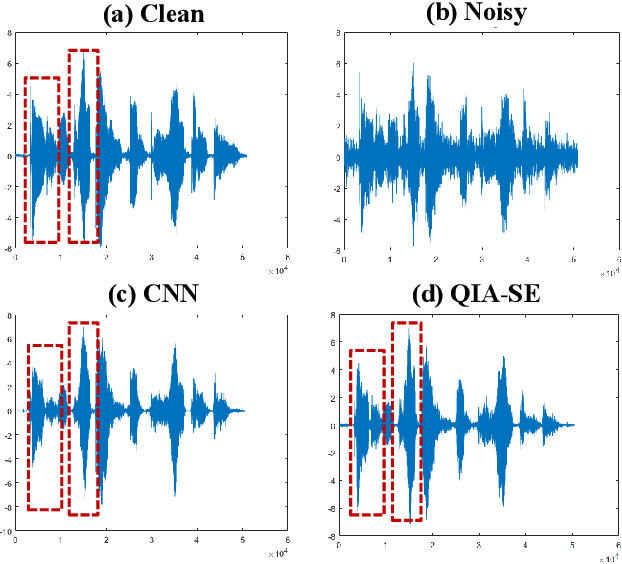
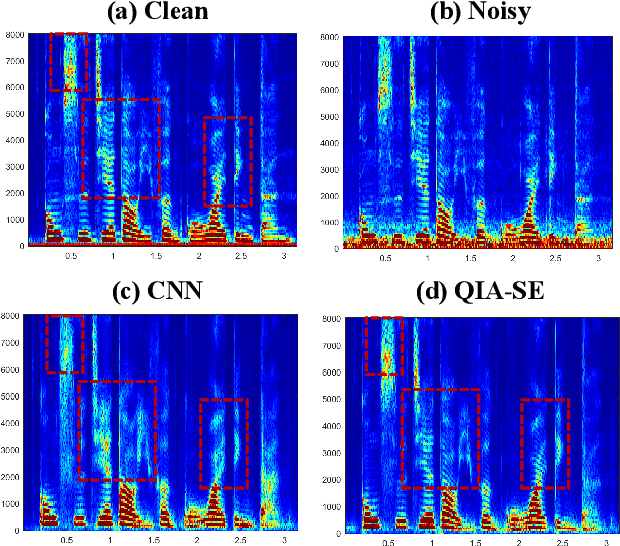
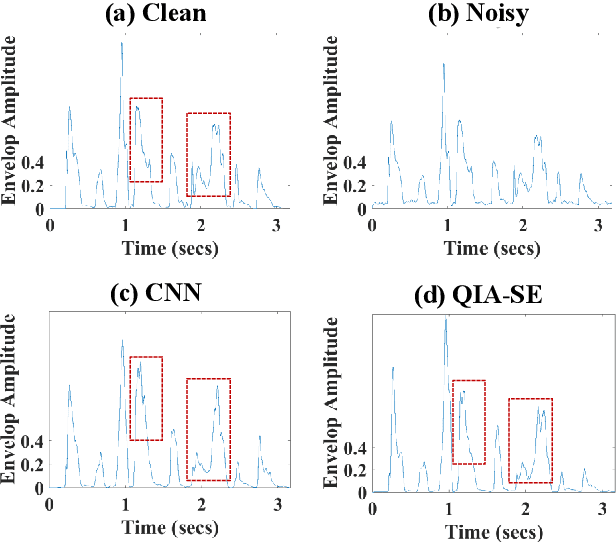
In this study, we propose a cross-domain multi-objective speech assessment model called MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, MOSA-Net is designed to estimate the speech quality, intelligibility, and distortion assessment scores of an input test speech signal. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, and a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results show that MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on noisy and enhanced speech utterances under either seen test conditions or unseen test conditions. Moreover, MOSA-Net, originally trained to assess objective scores, can be used as a pre-trained model to be effectively adapted to an assessment model for predicting subjective quality and intelligibility scores with a limited amount of training data. In light of the confirmed prediction capability, we further adopt the latent representations of MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.
OSSEM: one-shot speaker adaptive speech enhancement using meta learning
Nov 10, 2021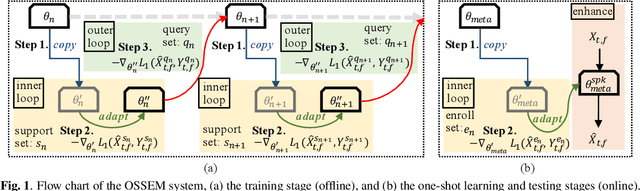
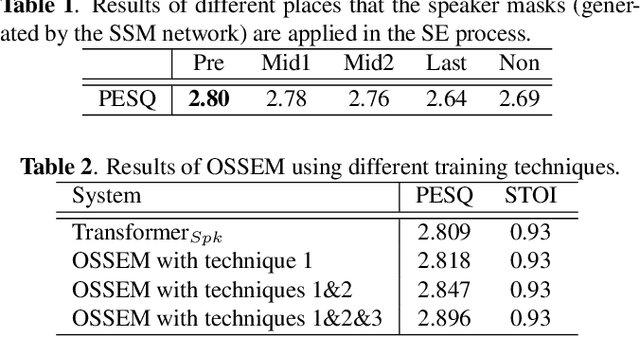
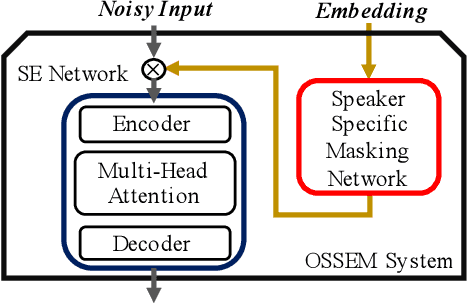
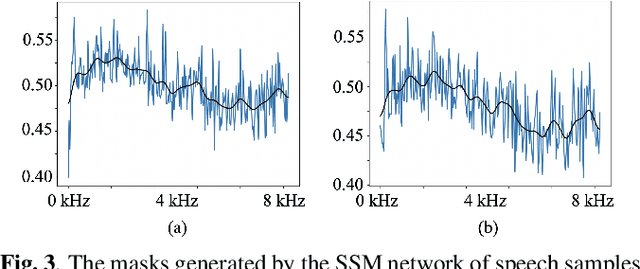
Although deep learning (DL) has achieved notable progress in speech enhancement (SE), further research is still required for a DL-based SE system to adapt effectively and efficiently to particular speakers. In this study, we propose a novel meta-learning-based speaker-adaptive SE approach (called OSSEM) that aims to achieve SE model adaptation in a one-shot manner. OSSEM consists of a modified transformer SE network and a speaker-specific masking (SSM) network. In practice, the SSM network takes an enrolled speaker embedding extracted using ECAPA-TDNN to adjust the input noisy feature through masking. To evaluate OSSEM, we designed a modified Voice Bank-DEMAND dataset, in which one utterance from the testing set was used for model adaptation, and the remaining utterances were used for testing the performance. Moreover, we set restrictions allowing the enhancement process to be conducted in real time, and thus designed OSSEM to be a causal SE system. Experimental results first show that OSSEM can effectively adapt a pretrained SE model to a particular speaker with only one utterance, thus yielding improved SE results. Meanwhile, OSSEM exhibits a competitive performance compared to state-of-the-art causal SE systems.
SEOFP-NET: Compression and Acceleration of Deep Neural Networks for Speech Enhancement Using Sign-Exponent-Only Floating-Points
Nov 08, 2021
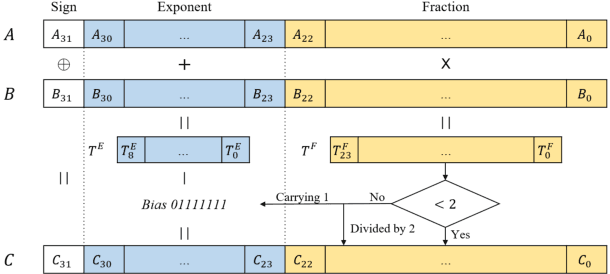
Numerous compression and acceleration strategies have achieved outstanding results on classification tasks in various fields, such as computer vision and speech signal processing. Nevertheless, the same strategies have yielded ungratified performance on regression tasks because the nature between these and classification tasks differs. In this paper, a novel sign-exponent-only floating-point network (SEOFP-NET) technique is proposed to compress the model size and accelerate the inference time for speech enhancement, a regression task of speech signal processing. The proposed method compressed the sizes of deep neural network (DNN)-based speech enhancement models by quantizing the fraction bits of single-precision floating-point parameters during training. Before inference implementation, all parameters in the trained SEOFP-NET model are slightly adjusted to accelerate the inference time by replacing the floating-point multiplier with an integer-adder. For generalization, the SEOFP-NET technique is introduced to different speech enhancement tasks in speech signal processing with different model architectures under various corpora. The experimental results indicate that the size of SEOFP-NET models can be significantly compressed by up to 81.249% without noticeably downgrading their speech enhancement performance, and the inference time can be accelerated to 1.212x compared with the baseline models. The results also verify that the proposed SEOFP-NET can cooperate with other efficiency strategies to achieve a synergy effect for model compression. In addition, the just noticeable difference (JND) was applied to the user study experiment to statistically analyze the effect of speech enhancement on listening. The results indicate that the listeners cannot facilely differentiate between the enhanced speech signals processed by the baseline model and the proposed SEOFP-NET.
MetricGAN-U: Unsupervised speech enhancement/ dereverberation based only on noisy/ reverberated speech
Oct 12, 2021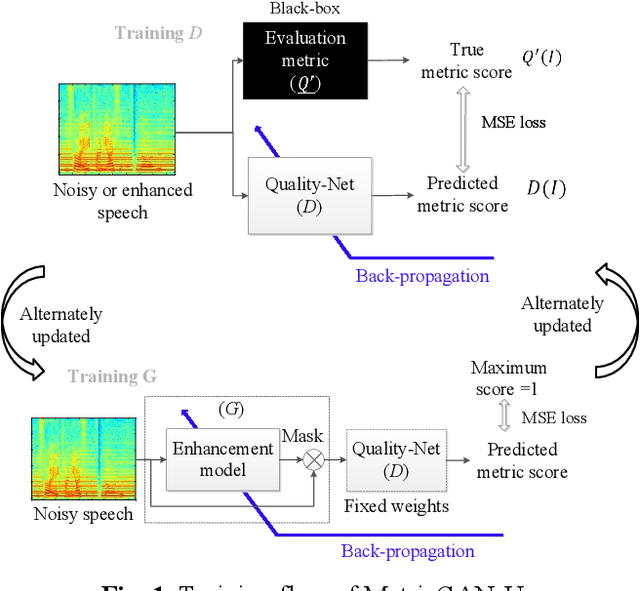
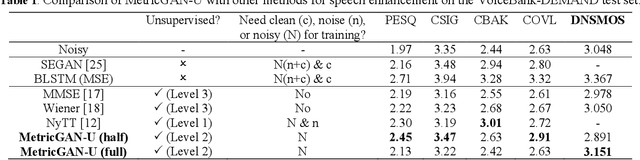
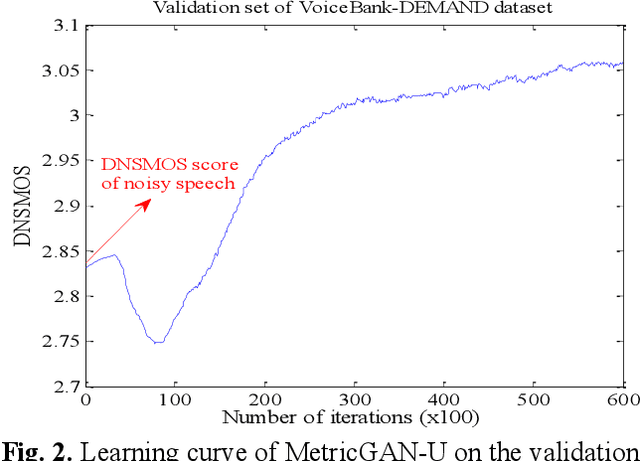
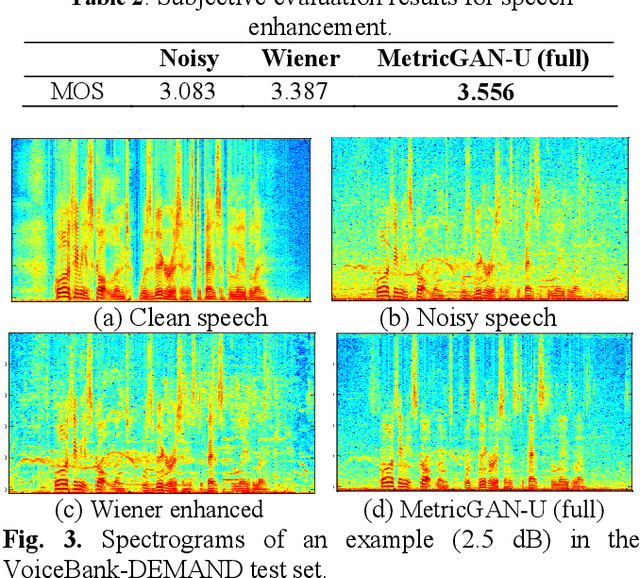
Most of the deep learning-based speech enhancement models are learned in a supervised manner, which implies that pairs of noisy and clean speech are required during training. Consequently, several noisy speeches recorded in daily life cannot be used to train the model. Although certain unsupervised learning frameworks have also been proposed to solve the pair constraint, they still require clean speech or noise for training. Therefore, in this paper, we propose MetricGAN-U, which stands for MetricGAN-unsupervised, to further release the constraint from conventional unsupervised learning. In MetricGAN-U, only noisy speech is required to train the model by optimizing non-intrusive speech quality metrics. The experimental results verified that MetricGAN-U outperforms baselines in both objective and subjective metrics.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021
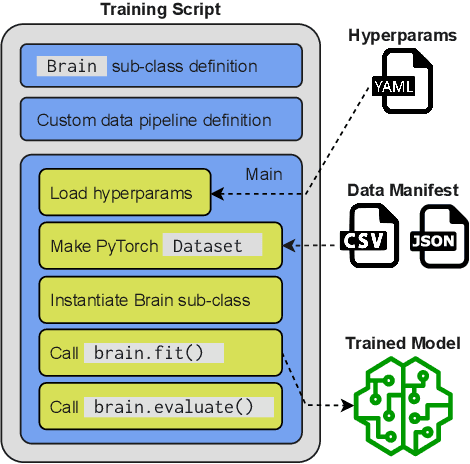

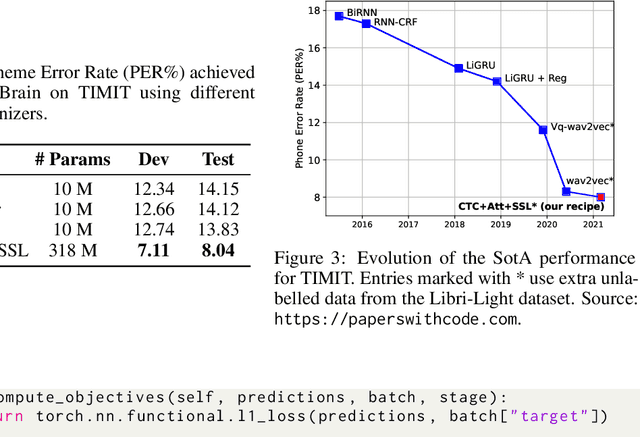
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement
Apr 08, 2021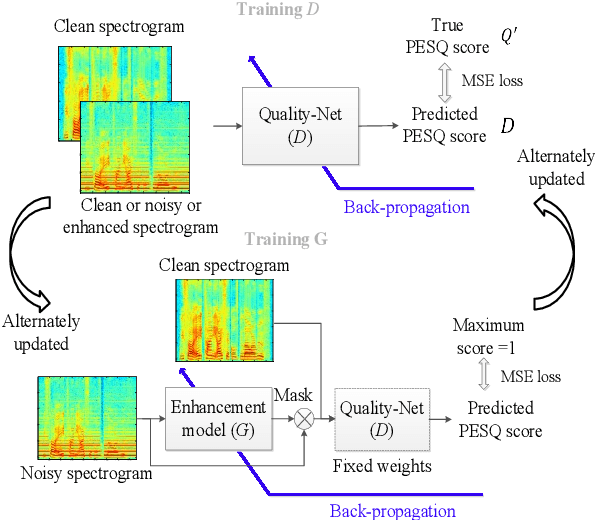
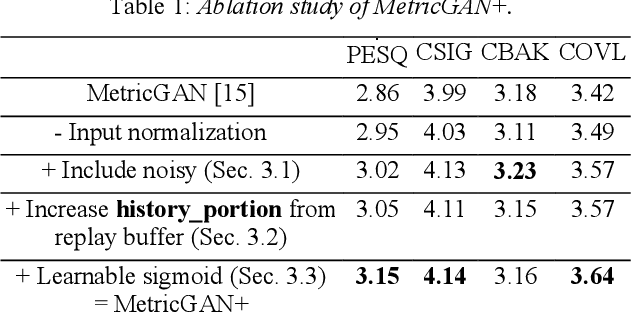
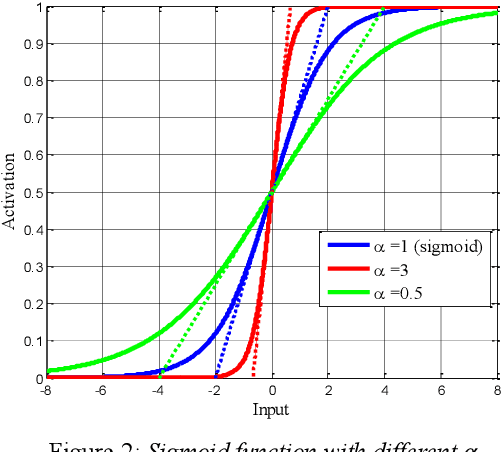

The discrepancy between the cost function used for training a speech enhancement model and human auditory perception usually makes the quality of enhanced speech unsatisfactory. Objective evaluation metrics which consider human perception can hence serve as a bridge to reduce the gap. Our previously proposed MetricGAN was designed to optimize objective metrics by connecting the metric with a discriminator. Because only the scores of the target evaluation functions are needed during training, the metrics can even be non-differentiable. In this study, we propose a MetricGAN+ in which three training techniques incorporating domain-knowledge of speech processing are proposed. With these techniques, experimental results on the VoiceBank-DEMAND dataset show that MetricGAN+ can increase PESQ score by 0.3 compared to the previous MetricGAN and achieve state-of-the-art results (PESQ score = 3.15).
STOI-Net: A Deep Learning based Non-Intrusive Speech Intelligibility Assessment Model
Nov 09, 2020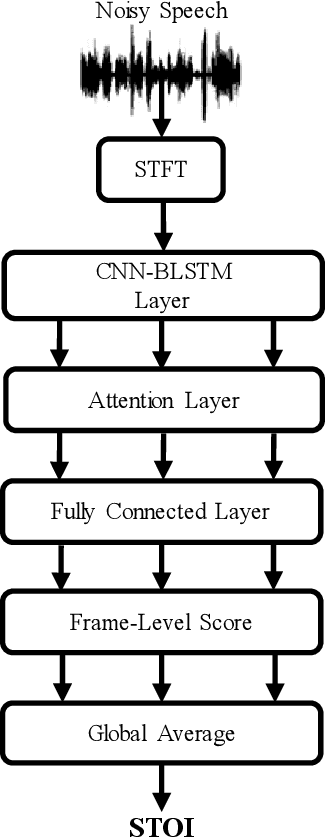
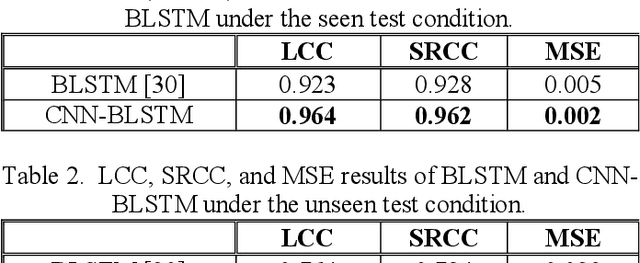
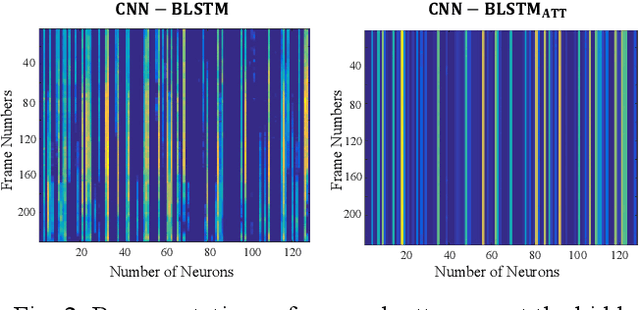
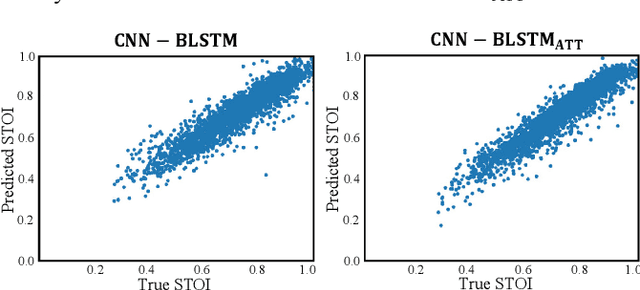
The calculation of most objective speech intelligibility assessment metrics requires clean speech as a reference. Such a requirement may limit the applicability of these metrics in real-world scenarios. To overcome this limitation, we propose a deep learning-based non-intrusive speech intelligibility assessment model, namely STOI-Net. The input and output of STOI-Net are speech spectral features and predicted STOI scores, respectively. The model is formed by the combination of a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture with a multiplicative attention mechanism. Experimental results show that the STOI score estimated by STOI-Net has a good correlation with the actual STOI score when tested with noisy and enhanced speech utterances. The correlation values are 0.97 and 0.83, respectively, for the seen test condition (the test speakers and noise types are involved in the training set) and the unseen test condition (the test speakers and noise types are not involved in the training set). The results confirm the capability of STOI-Net to accurately predict the STOI scores without referring to clean speech.
Improving Perceptual Quality by Phone-Fortified Perceptual Loss for Speech Enhancement
Oct 30, 2020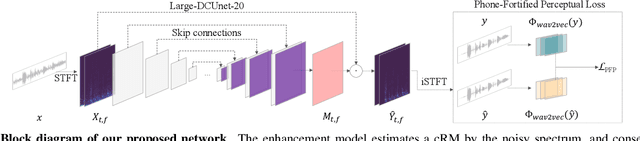
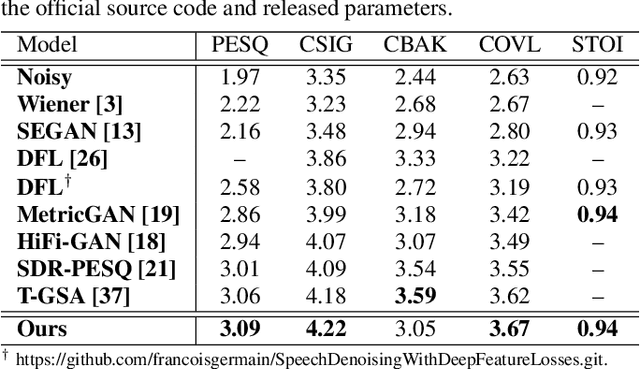
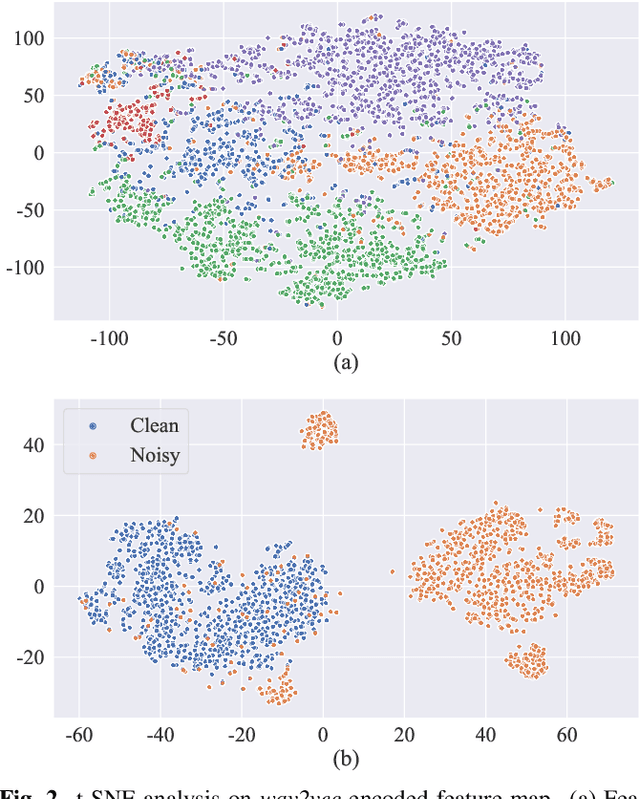
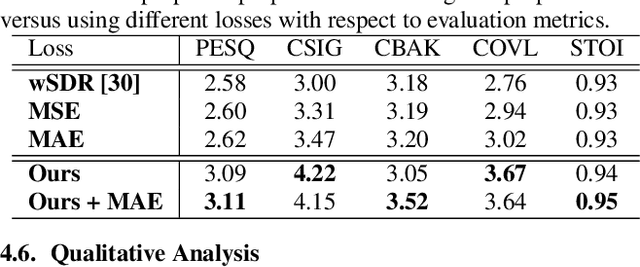
Speech enhancement (SE) aims to improve speech quality and intelligibility, which are both related to a smooth transition in speech segments that may carry linguistic information, e.g. phones and syllables. In this study, we took phonetic characteristics into account in the SE training process. Hence, we designed a phone-fortified perceptual (PFP) loss, and the training of our SE model was guided by PFP loss. In PFP loss, phonetic characteristics are extracted by wav2vec, an unsupervised learning model based on the contrastive predictive coding (CPC) criterion. Different from previous deep-feature-based approaches, the proposed approach explicitly uses the phonetic information in the deep feature extraction process to guide the SE model training. To test the proposed approach, we first confirmed that the wav2vec representations carried clear phonetic information using a t-distributed stochastic neighbor embedding (t-SNE) analysis. Next, we observed that the proposed PFP loss was more strongly correlated with the perceptual evaluation metrics than point-wise and signal-level losses, thus achieving higher scores for standardized quality and intelligibility evaluation metrics in the Voice Bank-DEMAND dataset.
Boosting Objective Scores of Speech Enhancement Model through MetricGAN Post-Processing
Jun 18, 2020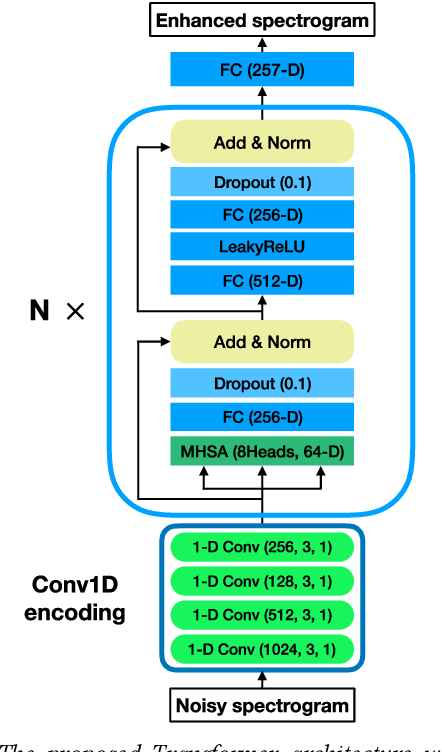
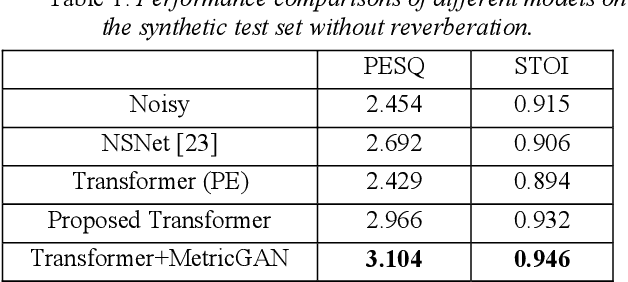
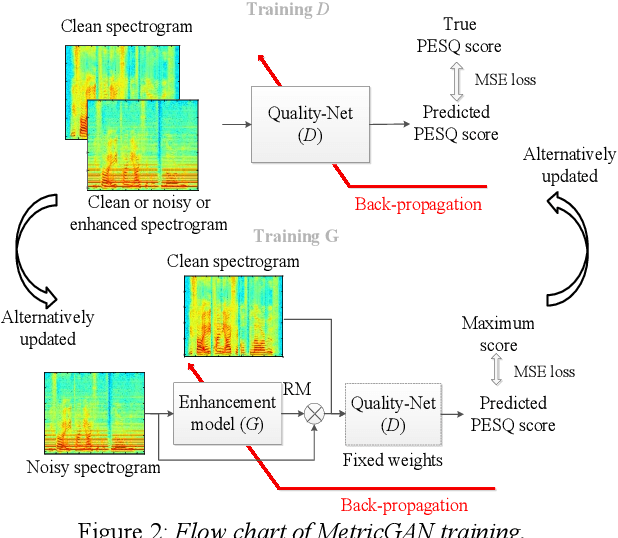

The Transformer architecture has shown its superior ability than recurrent neural networks on many different natural language processing applications. Therefore, this study applies a modified Transformer on the speech enhancement task. Specifically, the positional encoding may not be necessary and hence is replaced by convolutional layers. To further improve PESQ scores of enhanced speech, the L_1 pre-trained Transformer is fine-tuned by MetricGAN framework. The proposed MetricGAN can be treated as a general post-processing module to further boost interested objective scores. The experiments are conducted using the data sets provided by the organizer of the Deep Noise Suppression (DNS) challenge. Experimental results demonstrate that the proposed system outperforms the challenge baseline in both subjective and objective evaluation with a large margin.