 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Distance: A New Metric for ASR Performance Analysis Towards Spoken Language Understanding
Apr 05, 2021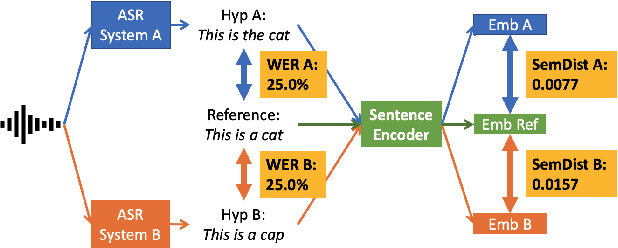


Word Error Rate (WER) has been the predominant metric used to evaluate the performance of automatic speech recognition (ASR) systems. However, WER is sometimes not a good indicator for downstream Natural Language Understanding (NLU) tasks, such as intent recognition, slot filling, and semantic parsing in task-oriented dialog systems. This is because WER takes into consideration only literal correctness instead of semantic correctness, the latter of which is typically more important for these downstream tasks. In this study, we propose a novel Semantic Distance (SemDist) measure as an alternative evaluation metric for ASR systems to address this issue. We define SemDist as the distance between a reference and hypothesis pair in a sentence-level embedding space. To represent the reference and hypothesis as a sentence embedding, we exploit RoBERTa, a state-of-the-art pre-trained deep contextualized language model based on the transformer architecture. We demonstrate the effectiveness of our proposed metric on various downstream tasks, including intent recognition, semantic parsing, and named entity recognition.
Improving RNN Transducer Based ASR with Auxiliary Tasks
Nov 09, 2020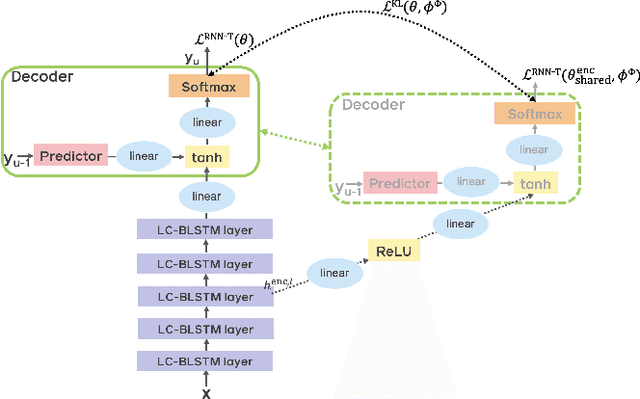

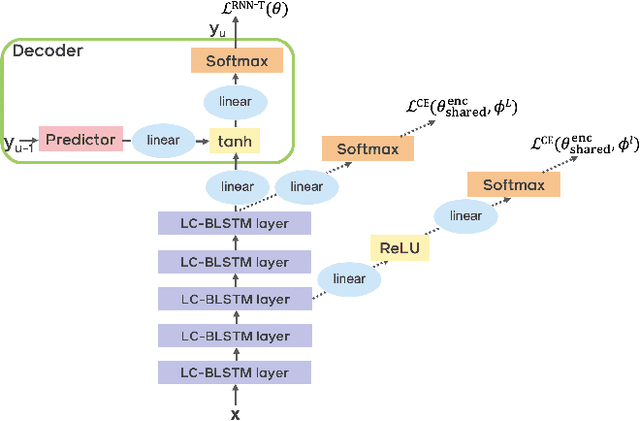
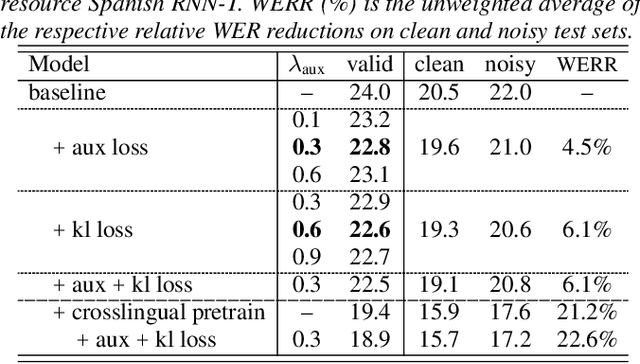
End-to-end automatic speech recognition (ASR) models with a single neural network have recently demonstrated state-of-the-art results compared to conventional hybrid speech recognizers. Specifically, recurrent neural network transducer (RNN-T) has shown competitive ASR performance on various benchmarks. In this work, we examine ways in which RNN-T can achieve better ASR accuracy via performing auxiliary tasks. We propose (i) using the same auxiliary task as primary RNN-T ASR task, and (ii) performing context-dependent graphemic state prediction as in conventional hybrid modeling. In transcribing social media videos with varying training data size, we first evaluate the streaming ASR performance on three languages: Romanian, Turkish and German. We find that both proposed methods provide consistent improvements. Next, we observe that both auxiliary tasks demonstrate efficacy in learning deep transformer encoders for RNN-T criterion, thus achieving competitive results - 2.0%/4.2% WER on LibriSpeech test-clean/other - as compared to prior top performing models.
Improved Neural Language Model Fusion for Streaming Recurrent Neural Network Transducer
Oct 26, 2020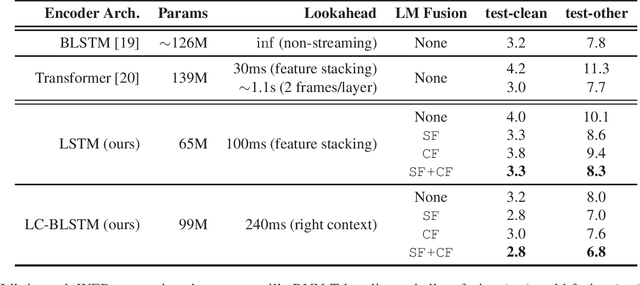
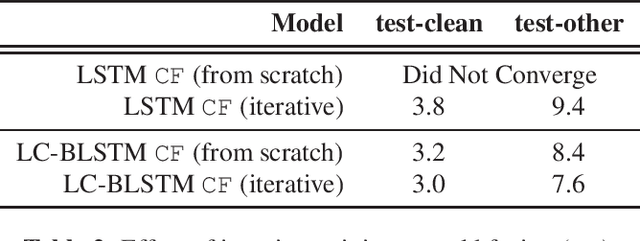
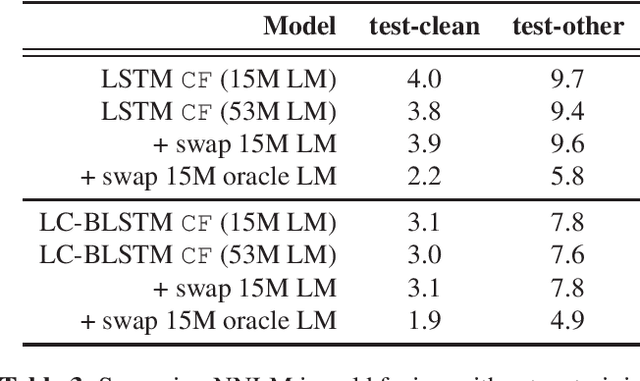
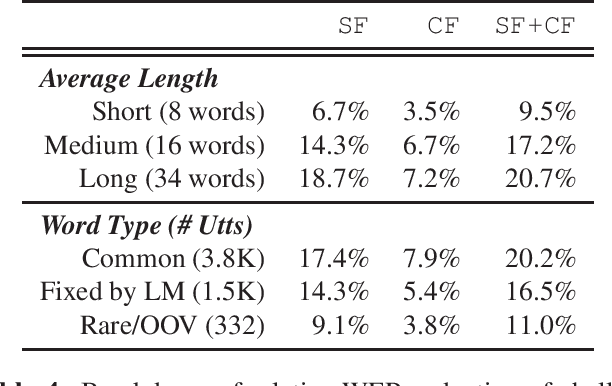
Recurrent Neural Network Transducer (RNN-T), like most end-to-end speech recognition model architectures, has an implicit neural network language model (NNLM) and cannot easily leverage unpaired text data during training. Previous work has proposed various fusion methods to incorporate external NNLMs into end-to-end ASR to address this weakness. In this paper, we propose extensions to these techniques that allow RNN-T to exploit external NNLMs during both training and inference time, resulting in 13-18% relative Word Error Rate improvement on Librispeech compared to strong baselines. Furthermore, our methods do not incur extra algorithmic latency and allow for flexible plug-and-play of different NNLMs without re-training. We also share in-depth analysis to better understand the benefits of the different NNLM fusion methods. Our work provides a reliable technique for leveraging unpaired text data to significantly improve RNN-T while keeping the system streamable, flexible, and lightweight.
Cross-Attention End-to-End ASR for Two-Party Conversations
Jul 24, 2019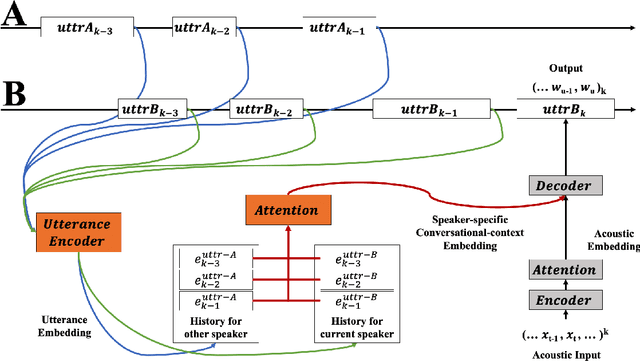
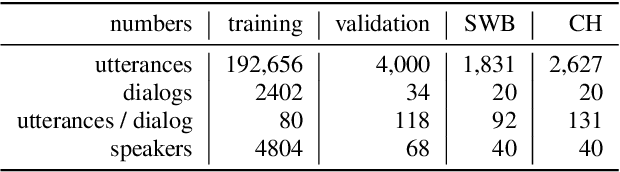
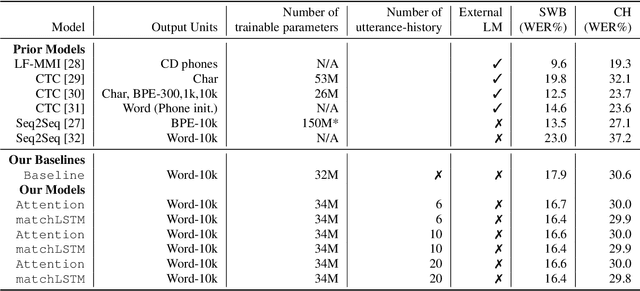
We present an end-to-end speech recognition model that learns interaction between two speakers based on the turn-changing information. Unlike conventional speech recognition models, our model exploits two speakers' history of conversational-context information that spans across multiple turns within an end-to-end framework. Specifically, we propose a speaker-specific cross-attention mechanism that can look at the output of the other speaker side as well as the one of the current speaker for better at recognizing long conversations. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
Gated Embeddings in End-to-End Speech Recognition for Conversational-Context Fusion
Jun 27, 2019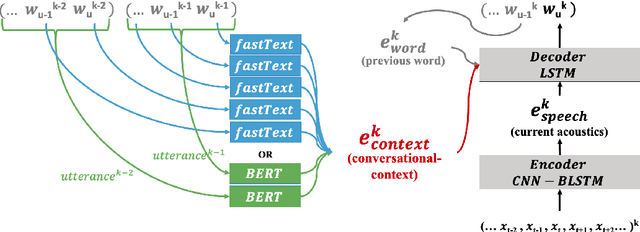
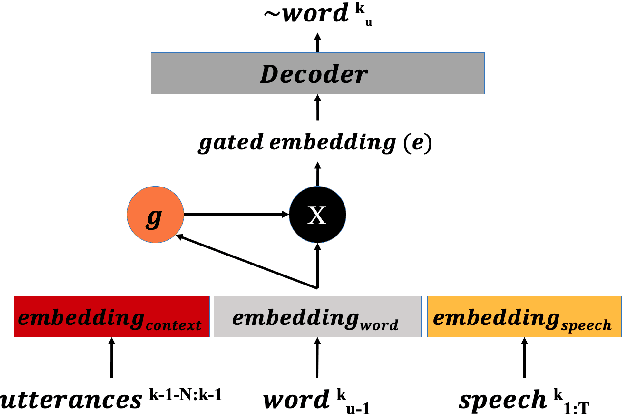
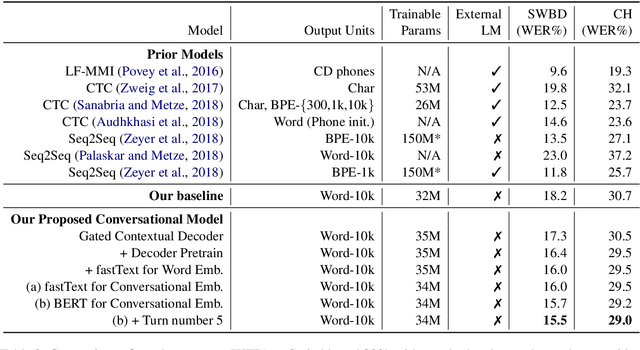
We present a novel conversational-context aware end-to-end speech recognizer based on a gated neural network that incorporates conversational-context/word/speech embeddings. Unlike conventional speech recognition models, our model learns longer conversational-context information that spans across sentences and is consequently better at recognizing long conversations. Specifically, we propose to use the text-based external word and/or sentence embeddings (i.e., fastText, BERT) within an end-to-end framework, yielding a significant improvement in word error rate with better conversational-context representation. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
Acoustic-to-Word Models with Conversational Context Information
May 21, 2019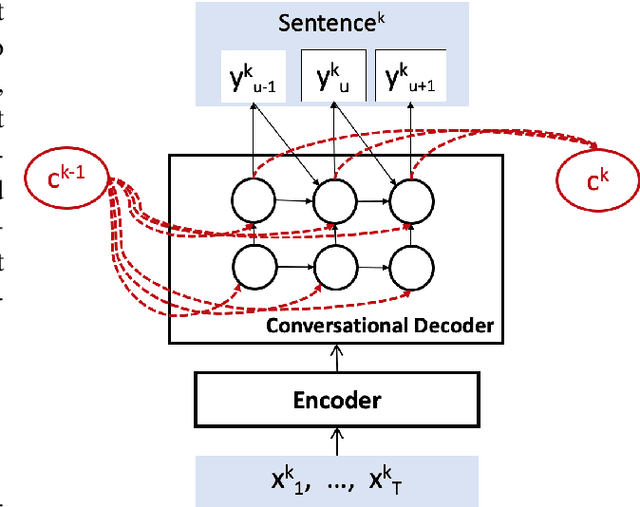
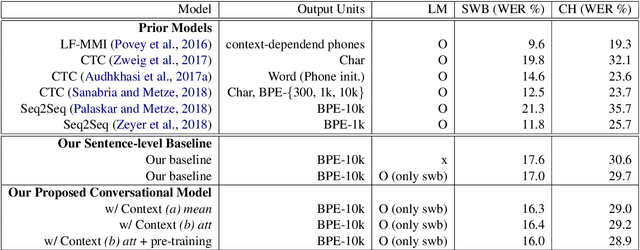
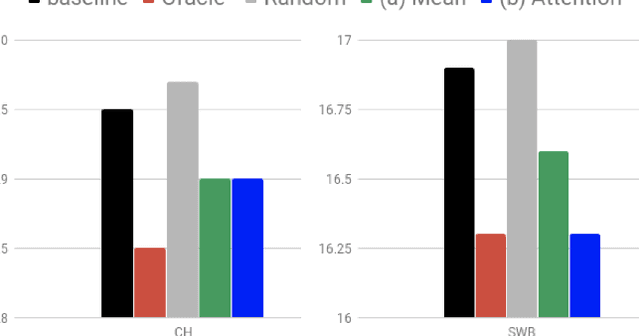
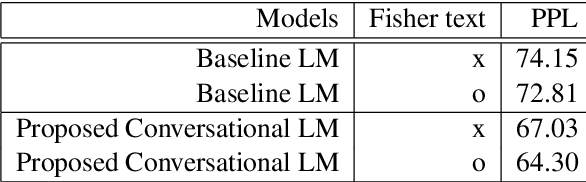
Conversational context information, higher-level knowledge that spans across sentences, can help to recognize a long conversation. However, existing speech recognition models are typically built at a sentence level, and thus it may not capture important conversational context information. The recent progress in end-to-end speech recognition enables integrating context with other available information (e.g., acoustic, linguistic resources) and directly recognizing words from speech. In this work, we present a direct acoustic-to-word, end-to-end speech recognition model capable of utilizing the conversational context to better process long conversations. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a standard end-to-end speech recognition system.
Improved training for online end-to-end speech recognition systems
Aug 30, 2018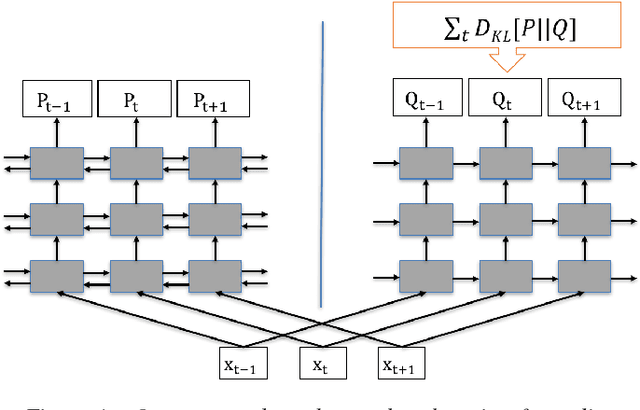
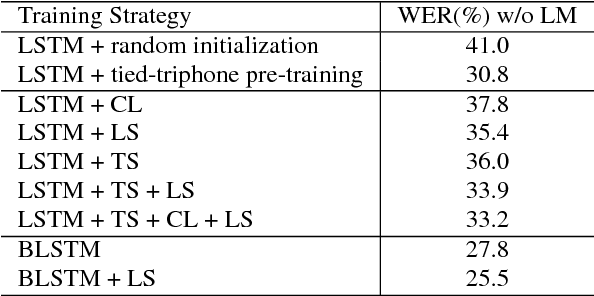
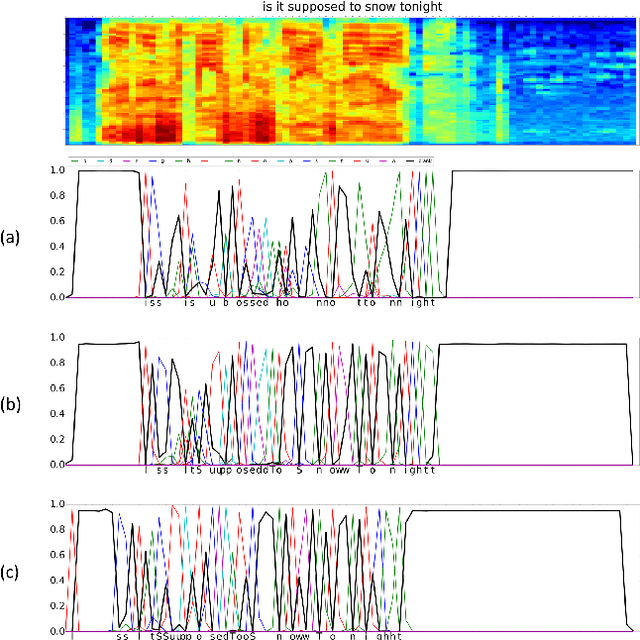
Achieving high accuracy with end-to-end speech recognizers requires careful parameter initialization prior to training. Otherwise, the networks may fail to find a good local optimum. This is particularly true for online networks, such as unidirectional LSTMs. Currently, the best strategy to train such systems is to bootstrap the training from a tied-triphone system. However, this is time consuming, and more importantly, is impossible for languages without a high-quality pronunciation lexicon. In this work, we propose an initialization strategy that uses teacher-student learning to transfer knowledge from a large, well-trained, offline end-to-end speech recognition model to an online end-to-end model, eliminating the need for a lexicon or any other linguistic resources. We also explore curriculum learning and label smoothing and show how they can be combined with the proposed teacher-student learning for further improvements. We evaluate our methods on a Microsoft Cortana personal assistant task and show that the proposed method results in a 19 % relative improvement in word error rate compared to a randomly-initialized baseline system.
Dialog-context aware end-to-end speech recognition
Aug 07, 2018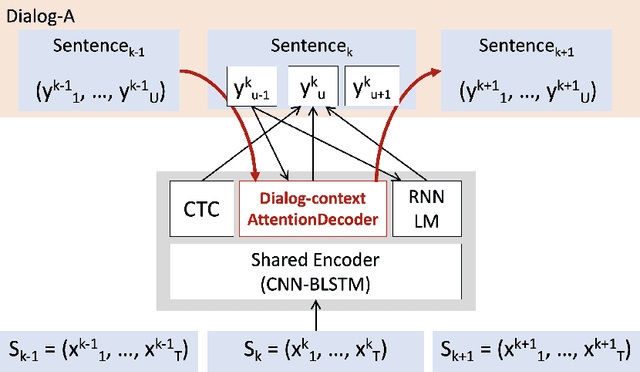

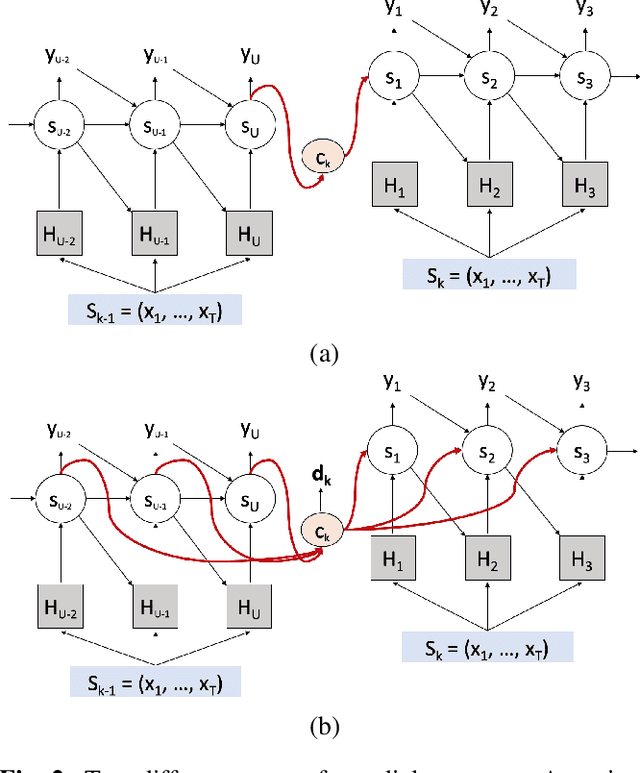

Existing speech recognition systems are typically built at the sentence level, although it is known that dialog context, e.g. higher-level knowledge that spans across sentences or speakers, can help the processing of long conversations. The recent progress in end-to-end speech recognition systems promises to integrate all available information (e.g. acoustic, language resources) into a single model, which is then jointly optimized. It seems natural that such dialog context information should thus also be integrated into the end-to-end models to improve further recognition accuracy. In this work, we present a dialog-context aware speech recognition model, which explicitly uses context information beyond sentence-level information, in an end-to-end fashion. Our dialog-context model captures a history of sentence-level context so that the whole system can be trained with dialog-context information in an end-to-end manner. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a comparable sentence-level end-to-end speech recognition system.
Towards Language-Universal End-to-End Speech Recognition
Nov 06, 2017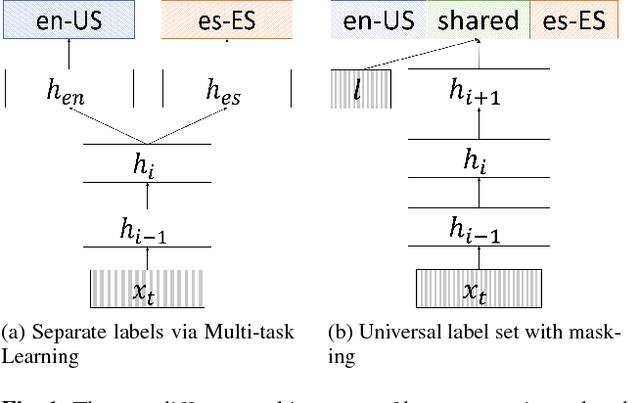
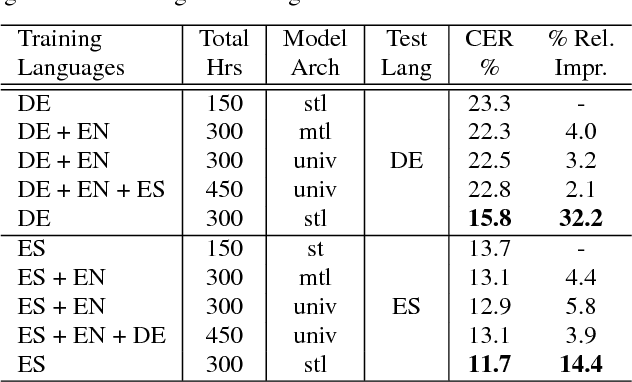
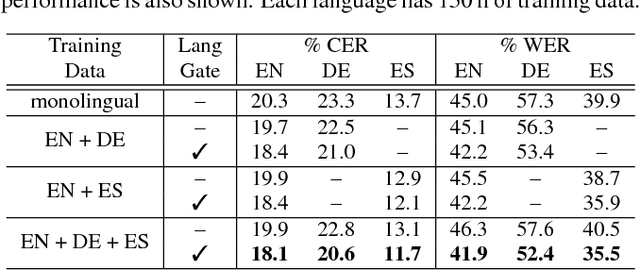
Building speech recognizers in multiple languages typically involves replicating a monolingual training recipe for each language, or utilizing a multi-task learning approach where models for different languages have separate output labels but share some internal parameters. In this work, we exploit recent progress in end-to-end speech recognition to create a single multilingual speech recognition system capable of recognizing any of the languages seen in training. To do so, we propose the use of a universal character set that is shared among all languages. We also create a language-specific gating mechanism within the network that can modulate the network's internal representations in a language-specific way. We evaluate our proposed approach on the Microsoft Cortana task across three languages and show that our system outperforms both the individual monolingual systems and systems built with a multi-task learning approach. We also show that this model can be used to initialize a monolingual speech recognizer, and can be used to create a bilingual model for use in code-switching scenarios.
Joint CTC-Attention based End-to-End Speech Recognition using Multi-task Learning
Jan 31, 2017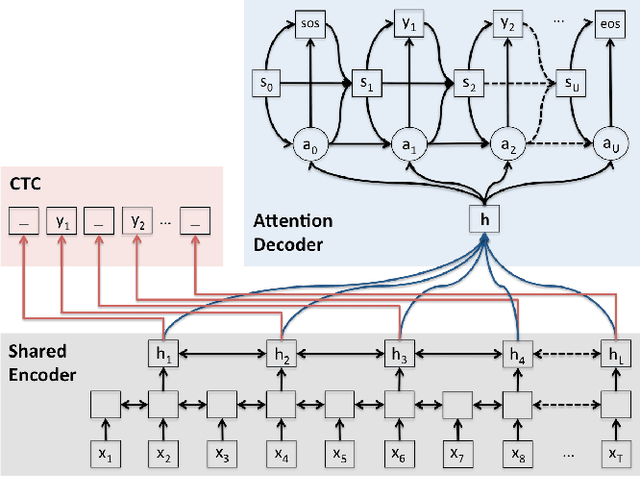
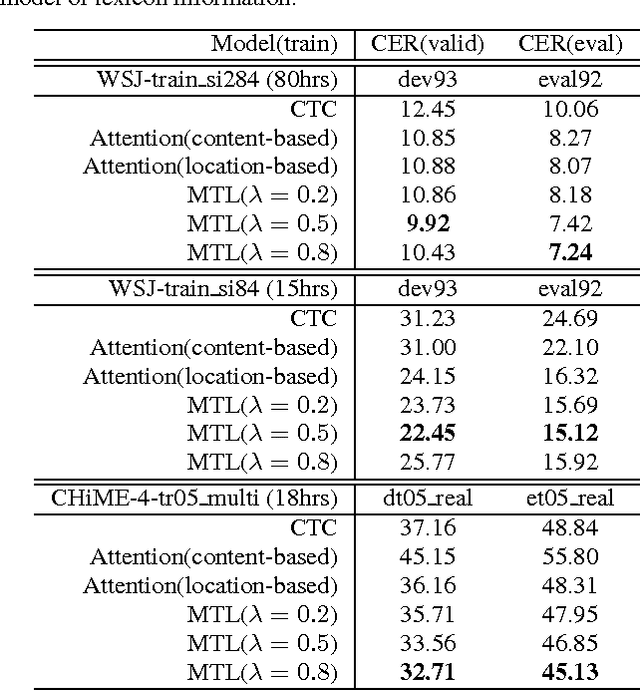
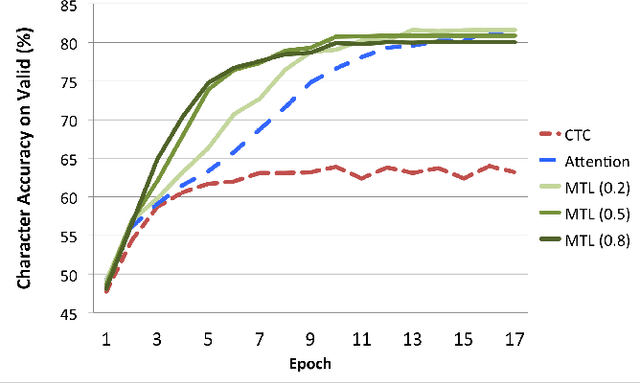
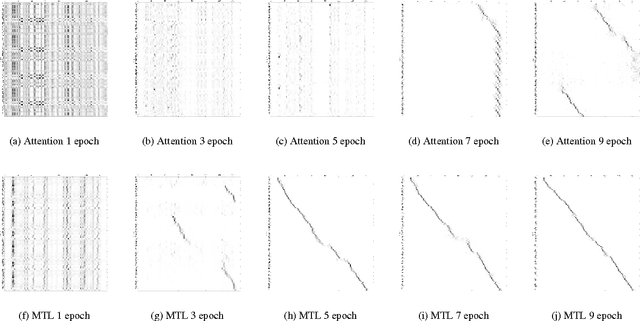
Recently, there has been an increasing interest in end-to-end speech recognition that directly transcribes speech to text without any predefined alignments. One approach is the attention-based encoder-decoder framework that learns a mapping between variable-length input and output sequences in one step using a purely data-driven method. The attention model has often been shown to improve the performance over another end-to-end approach, the Connectionist Temporal Classification (CTC), mainly because it explicitly uses the history of the target character without any conditional independence assumptions. However, we observed that the performance of the attention has shown poor results in noisy condition and is hard to learn in the initial training stage with long input sequences. This is because the attention model is too flexible to predict proper alignments in such cases due to the lack of left-to-right constraints as used in CTC. This paper presents a novel method for end-to-end speech recognition to improve robustness and achieve fast convergence by using a joint CTC-attention model within the multi-task learning framework, thereby mitigating the alignment issue. An experiment on the WSJ and CHiME-4 tasks demonstrates its advantages over both the CTC and attention-based encoder-decoder baselines, showing 5.4-14.6% relative improvements in Character Error Rate (CER).